Материал из CDTOwiki
Перейти к: навигация, поиск
Цикл работы с данными
этапы и виды работ, которые необходимо проделать, чтобы получить новую информацию на их основе
Сегмент
Рекомендовано
Сложность
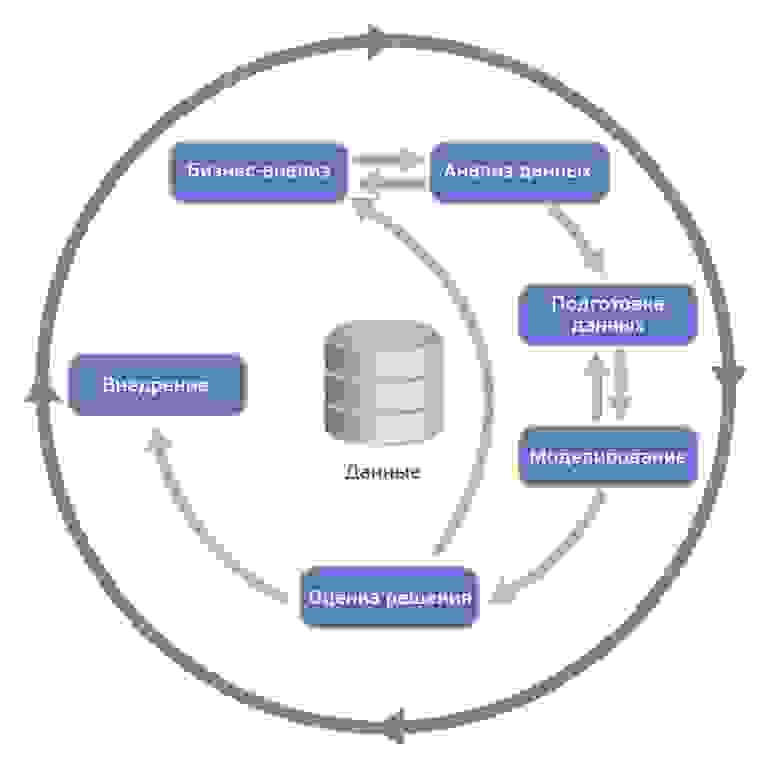
Один из подходов работы с данными – это методология исследования данных CRISP, которая включает в себя шесть этапов: понимание бизнеса, начальное изучение данных, подготовка данных, моделирование, оценка решения и внедрение.
Цикл работы с данными по методологии CRISP
CRISP-DM (Cross-Industry Standard Process for Data Mining — межотраслевой стандартный процесс для исследования данных) — это проверенная в промышленности и наиболее распространённая методология по исследованию данных.
Данная схема включает в себя шесть этапов
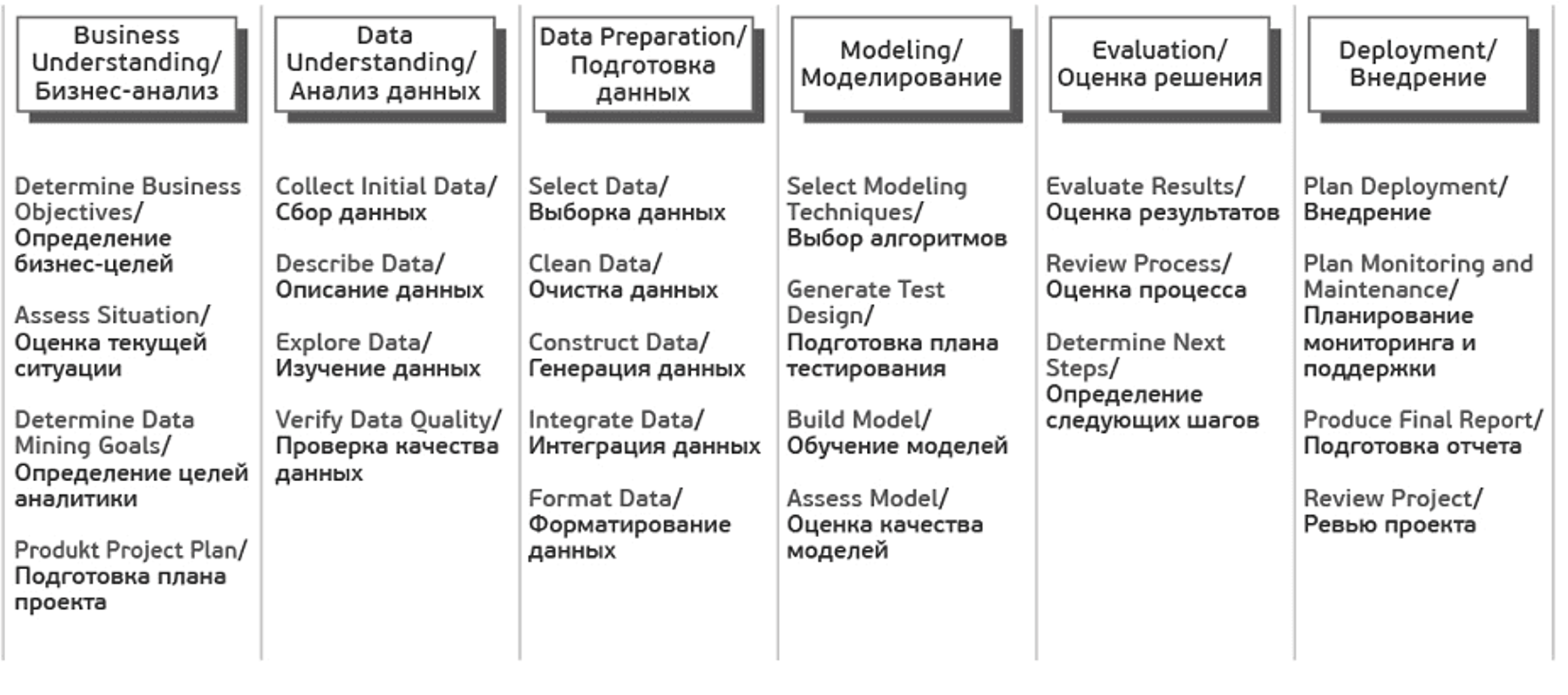
Понимание бизнеса (Business Understanding) – на первом этапе работы с данными вам нужно понять, зачем вам собирать и анализировать данные, а также какие данные вам необходимы. Определение целей и предварительные гипотезы на данных затем лягут в основу вашего проекта.
Задачи фазы Business Understanding:
- Определить цели вашей организации
- Оценить текущую ситуацию
- Определить цели анализа данных
- Составить план проекта
Начальное изучение данных (Data Understanding) – на втором этапе работы с данными вам нужно оценить качество ваших данных: насколько данные полные, есть ли в них ошибки, пробелы и пропуски. Нужно понять, какими сведениями вы обладаете, сформулировать к ним вопросы и итоговые гипотезы о скрытых закономерностях
Задачи фазы Data Understanding:
- Собрать исходные данные
- Описать данные
- Исследовать данные
- Проверить качество данных
Подготовка данных (Data Preparation) – на этом этапе вам нужно сформировать итоговый набор данных для анализа, “очистить” данные, привести их в единых формат из исходных разнородных и разноформатных данных.
Задачи фазы Data Preparation могут выполняться много раз без какого-то заранее определенного порядка:
- Отобрать данные (таблицы, записи и атрибуты)
- Очистить данные, в т.ч. выполнить их конвертацию и подготовку к моделированию
- Сделать производные данные
- Объединить данные
- Привести данные в нужный формат
Моделирование (Modeling) – на этом этапе вам нужно выбрать методику, каким образом анализировать данные, построить модель анализа. Модель должна отражать весь их процесс анализа (что вы хотите выяснить с помощью анализа данных, какие данные вы используете, как они организованы, как они обработаны, и так далее). У вас может возникнуть необходимость вернуться к фазе подготовки данных, так как разные методы анализа требуют различных форматов данных.
Задачи фазы Modeling:
- Выбрать методику моделирования
- Сделать тесты для модели
- Построить модель
- Оценить модель
Оценка (Evaluation) – определение, удалось ли достигнуть целей с помощью разработанной модели и полученных результатов анализа. Данный этап позволяет понять, действительно ли те шаги, которые вы запланировали, позволяют получить те результаты, которые вы хотели. На данном этапе могут быть выявлены более важные задачи организации, которые не были учтены.
Задачи фазы Evaluation:
- Оценить результаты
- Сделать ревью процесса
- Определить следующие шаги
Внедрение (Deployment) – этот этап может быть простым или сложным, в зависимости от целей организации. Обычно это — разработка и внедрение решений на основе анализа данных. Это может быть как составление отчета, так и автоматизация процессов для решения ваших целей.
Задачи фазы Deployment:
- Запланировать развертывание
- Запланировать поддержку и мониторинг развернутого решения
- Сделать финальный отчет
- Сделать ревью проекта
Рассмотрим подробнее некоторые аспекты этапов подготовки и моделирования данных, инструменты подготовки данных и способы их моделирования
Сбор данных
Важный вопрос на этом этапе — поиск данных. Согласно И.В. Бегтину поиск данных осуществляется по следующей схеме:
- формулировка запроса — что ищем;
- запрос консультаций с целью помощи в поиске источников поиска;
- самостоятельный поиск;
- запрос и получение данных.
Хранение данных
Хранение данных — это процесс обеспечения доступности, целостности, защищенности данных. Данные можно хранить разным способом:
- твердотельный съемный или несъемный носитель — нужен доступ к самому носителю или устройству, в которое он помещается, для получения данных;
- сервера баз данных;
- облачное хранилище данных — доступ к данным возможен из любой локации и др.
Выбор способа хранения данных зависит от объема данных, необходимой скорости доступа к ней, частоте обновлений данных, количества лиц, которым будет разрешен доступ к данным, стоимости хранения нужного объема данных.
Основной формой хранения данных является база данных. С помощью СУБД можно получить доступ к данным, записать их, переместить, изменить, удалить.

Обработка данных
Под обработкой данных понимается определенная последовательность операций с данными, выполненных для получения новой информации путем пересмотра и уточнения имеющейся результатов анализа данных, вычислений и пр. На первом этапе осуществляется первичная обработка данных — приведение данных к единому формату, выделение общих признаков, структурирование данных. Затем выбирается наиболее актуальная для решения задачи модель работы:
- точечная обработка активных задач — операции только с выбранными категориями;
- потоковая обработка в реальном времени — операции с большим объемом данных, поступающих непрерывно, в процессе чего результаты анализа меняются каждый раз когда поступают новые данные;
- пакетная обработка исторических данных — обработка данных, накопленных за определенный срок.
В зависимости от выбранной модели, решаемой задачи подбираются технологии, тип базы данных, которые будут наиболее эффективны в конкретном случае.
К процедурам обработки данных относятся: создание данных, модификация данных, поиск информации, принятие решений, создание отчетов, создание документов, повышение безопасности данных.
При обработке данных обращают внимание на их качество. Выделяют чистые и грязные данные. Грязные данные отличает наличие обработки, дополнительной, не связанных с первоначальными данными, информации, недостаток первичных данных. Все это мешает полному анализу данных, так как грязные данные уже содержат в себе некоторые критерии анализа, “обнулить” значение которых нельзя.
Визуализация данных
Визуализация данных — процесс представления данных в агрегированном, понятном для восприятия человеком виде. Визуализация может быть презентационной — готовой для демонстрации аудитории, исследовательской — готовой для получения некоторых промежуточных результатов обработки данных.
Визуализация может быть использована на всех этапах работы с данными: визуализация результатов первичной обработки, визуализация промежуточных результатов, визуализация окончательных результатов.
В связи с объемом анализируемых данных визуализация – это необходимый способ оформления данных в понятный человеку вид. Поэтому инструменты визуализации важны в работе с данными.
Вид визуализации данных:
- Графики: линейный, график рассеивания и др.
- Диаграммы: столбиковая, круговая, гистограмма, кольцевая, лепестковая, облако тегов и др.
- Инфографика.
- Схемы.
- Презентации.
- Карты: фотографическая, географическая, дорожная, тематическая, картограмма.
- Дашборды.
- Иллюстрации.
Выводы
- Методология исследования данных CRISP включается шесть этапов: понимание бизнеса, начальное изучение данных, подготовка данных, моделирование, оценка решения и внедрение.
- Поиск данных включает четыре этапа: формулировка запроса, консультации, самостоятельный поиск, запрос и получение данный
- Хранить данные можно на твердых носителях, серверах или в облачных хранилищах.
- Обработка данных включает в себя: первичную обработку и очистку, выделение общих признаков, уплотнение данных, выбор модели для анализа.
- Анализ данных — совокупность действий исследователя, направленных на получение определенных представлений о характере явления, описываемых этими данными.
- Визуализация данных — процесс представления данных в агрегированном, понятном для восприятия человеком виде.
Дата последней редакции 29 мая 2020
Постановка задач машинного обучения математически очень проста. Любая задача классификации, регрессии или кластеризации – это по сути обычная оптимизационная задача с ограничениями. Несмотря на это, существующее многообразие алгоритмов и методов их решения делает профессию аналитика данных одной из наиболее творческих IT-профессий. Чтобы решение задачи не превратилось в бесконечный поиск «золотого» решения, а было прогнозируемым процессом, необходимо придерживаться довольно четкой последовательности действий. Эту последовательность действий описывают такие методологии, как CRISP-DM.
Методология анализа данных CRISP-DM упоминается во многих постах на Хабре, но я не смог найти ее подробных русскоязычных описаний и решил своей статьей восполнить этот пробел. В основе моего материала – оригинальное описание и адаптированное описание от IBM. Обзорную лекцию о преимуществах использования CRISP-DM можно посмотреть, например, здесь.

* Crisp (англ.) — хрустящий картофель, чипсы
Я работаю в компании CleverDATA (входит в группу ЛАНИТ) на позиции дата-сайентиста с 2015 года. Мы занимаемся проектами в области больших данных и машинного обучения, преимущественно в сфере data-driven маркетинга (то есть маркетинга, построенного на «глубоком» анализе клиентских данных). Также развиваем платформу управления данными 1DMP и биржу данных 1DMC. Наши типичные проекты по машинному обучению – это разработка и внедрение предиктивных (прогнозирующих) и прескриптивных (рекомендующих наилучшее действие) моделей для оптимизации ключевых бизнес-показателей заказчика. В ряде подобных проектов мы использовали методологию CRISP-DM.
CRoss Industry Standard Process for Data Mining (CRISP-DM) – стандарт, описывающий общие процессы и подходы к аналитике данных, используемые в промышленных data-mining проектах независимо от конкретной задачи и индустрии.
На известном аналитическом портале kdnuggets.org периодически публикуется опрос (например, здесь), согласно которому среди методологий анализа данных первое место по популярности регулярно занимает именно CRISP-DM, дальше с большим отрывом идет SEMMA и реже всего используется KDD Process.
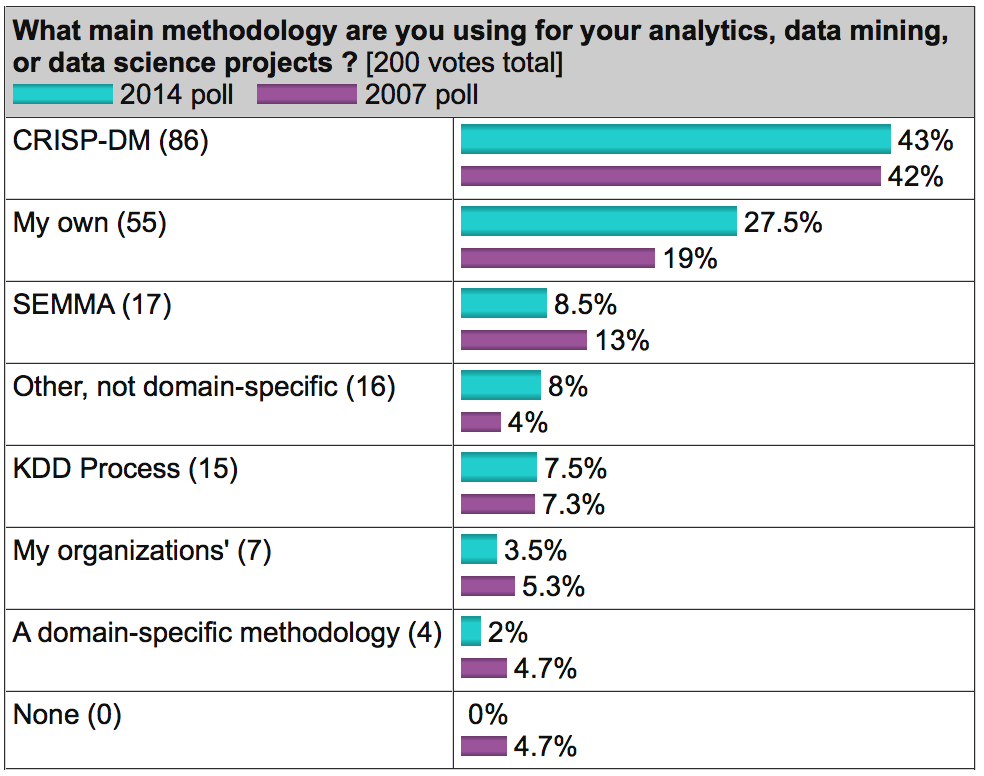
Источник: kdnuggets.com
В целом, эти три методологии очень похожи друг на друга (здесь сложно придумать что-то принципиально новое). Однако CRISP-DM заслужила популярность как наиболее полная и детальная. По сравнению с ней KDD является более общей и теоретической, а SEMMA – это просто организация функций по целевому предназначению в инструменте SAS Enterprise Miner и затрагивает исключительно технические аспекты моделирования, никак не касаясь бизнес-постановки задачи.
О методологии
Методология разработана в 1996 году по инициативе трех компаний (нынешние DaimlerChrysler, SPSS и Teradata) и далее дорабатывалась при участии 200 компаний различных индустрий, имеющих опыт data-mining проектов. Все эти компании использовали разные аналитические инструменты, но процесс у всех был построен очень похоже.
Методология активно продвигается компанией IBM. Например, она интегрирована в продукт IBM SPSS Modeler (бывший SPSS Clementine).
Важное свойство методологии – уделение внимания бизнес-целям компании. Это позволяет руководству воспринимать проекты по анализу данных не как «песочницу» для экспериментов, а как полноценный элемент бизнес-процессов компании.
Вторая особенность — это довольно детальное документирование каждого шага. По мнению авторов, хорошо задокументированный процесс позволяет менеджменту лучше понимать суть проекта, а аналитикам – больше влиять на принятие решений.
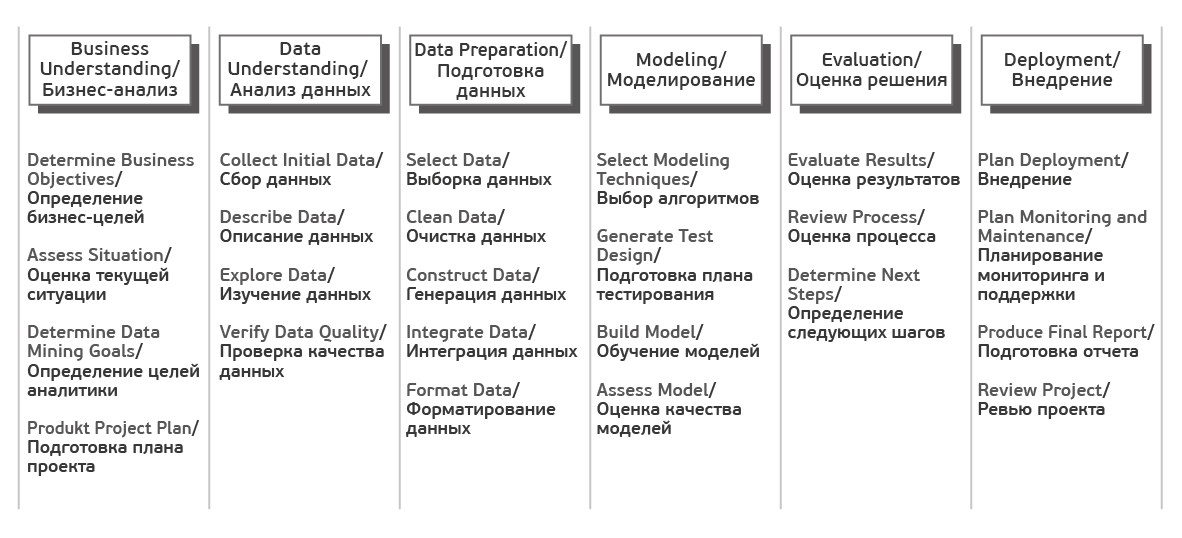
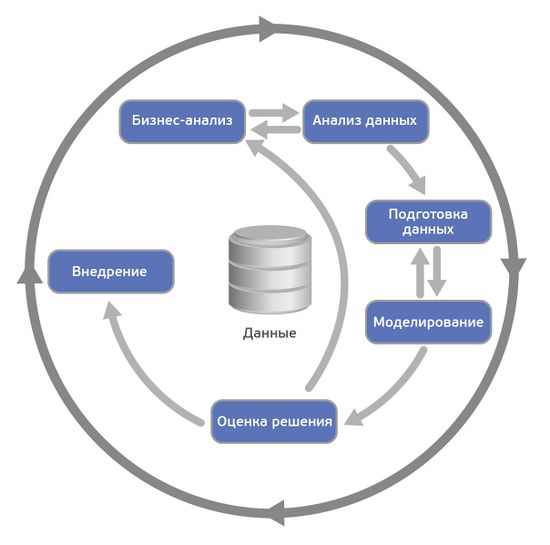
Согласно CRISP-DM, аналитический проект состоит из шести основных этапов, выполняемых последовательно:
- Бизнес-анализ (Business understanding)
- Анализ данных (Data understanding)
- Подготовка данных (Data preparation)
- Моделирование (Modeling)
- Оценка результата (Evaluation)
- Внедрение (Deployment)
Методология не жесткая. Она допускает вариацию в зависимости от конкретного проекта – можно возвращаться к предыдущим шагам, можно какие-то шаги пропускать, если для решаемой задачи они не важны:
Источник Wikipedia
Каждый из этих этапов в свою очередь делится на задачи. На выходе каждой задачи должен получаться определенный результат. Задачи следующие:
Источник Crisp_DM Documentation
В описании шагов я сознательно не буду углубляться в математику и алгоритмы, поскольку в статье фокус делается именно на процесс. Предполагаю, что читатель знаком с основами машинного обучения, но на всякий случай в следующем параграфе приводится описание базовых терминов.
Также обращу внимание, что методология одинаково применима как для внутренних проектов, так и для ситуаций, когда проект делается консультантами.
Несколько базовых понятий машинного обучения
Как правило, основным результатом аналитического проекта является математическая модель. Что такое модель?
Пусть у бизнеса есть некая интересующая его величина — y (например, вероятность оттока клиента). А также есть данные — x (например, обращения клиента в техподдержку), от которых может зависеть y. Бизнес хочет понимать, как именно y зависит от x, чтобы в дальнейшем через настройку x он мог влиять на y. Таким образом, задача проекта — найти функцию f, которая лучше всего моделирует исследуемую зависимость y = f(x).
Под моделью мы будем понимать формулу f(x) либо программу, реализующую эту формулу. Любая модель описывается, во-первых, своим алгоритмом обучения (это может быть регрессия, дерево решений, градиентный бустинг и прочее), а во-вторых, набором своих параметров (которые у каждого алгоритма свои). Обучение модели – процесс поиска таких параметров, при которых модель лучше всего аппроксимирует наблюдаемые данные.
Обучающая выборка – таблица, содержащая пары x и y. Строки в этой таблице называются кейсами, а столбцы – атрибутами. Атрибуты, обладающие достаточной предсказательной способностью, будем называть предикторами. В случае с обучением «без учителя» (например, в задачах кластеризации), обучающая выборка состоит только из x. Скоринг – это применение найденной функции f(x) к новым данным, по которым y пока неизвестен. Например, в задаче кредитного скоринга сначала моделируется вероятность несвоевременной оплаты долга клиентом, а затем разработанная модель применяется к новым заявителям для оценки их кредитоспособности.
Пошаговое описание методологии

Источник
1. Бизнес-анализ (Business Understanding)
На первом шаге нам нужно определиться с целями и скоупом проекта.
Цель проекта (Business objectives)
Первым делом знакомимся с заказчиком и пытаемся понять, что же он на самом деле хочет (или рассказываем ему). На следующие вопросы хорошо бы получить ответ.
- Организационная структура: кто участвует в проекте со стороны заказчика, кто выделяет деньги под проект, кто принимает ключевые решения, кто будет основным пользователем? Собираем контакты.
- Какова бизнес-цель проекта?
Например, уменьшение оттока клиентов. - Существуют ли какие-то уже разработанные решения? Если существуют, то какие и чем именно текущее решение не устраивает?
1.2 Текущая ситуация (Assessing current solution)

Источник
Когда вместе с заказчиком разобрались, что мы хотим, нужно оценить, что мы можем предложить с учетом текущих реалий.
Оцениваем, хватает ли ресурсов для проекта.
- Есть ли доступное железо или его необходимо закупать?
- Где и как хранятся данные, будет ли предоставлен доступ в эти системы, нужно ли дополнительно докупать/собирать внешние данные?
- Сможет ли заказчик выделить своих экспертов для консультаций на данный проект?
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению.
Типичные риски следующие.
- Не уложиться в сроки.
- Финансовые риски (например, если спонсор потеряет заинтересованность в проекте).
- Малое количество или плохое качество данных, которые не позволят получить эффективную модель.
- Данные качественные, но закономерности в принципе отсутствуют и, как следствие, полученные результаты не интересны заказчику.
Важно, чтобы заказчик и исполнитель говорили на одном языке, поэтому перед началом проекта лучше составить глоссарий и договориться об используемой в рамках проекта терминологии. Так, если мы делаем модель оттока для телекома, необходимо сразу договориться, что именно мы будем считать оттоком – например, отсутствие значительных начислений по счету в течение 4 недель подряд.
Далее стоит (хотя бы грубо) оценить ROI. В machine-learning проектах обоснованную оценку окупаемости часто можно получить только по завершению проекта (либо пилотного моделирования), но понимание потенциальной выгоды может стать хорошим драйвером для всех.
1.3 Решаемые задачи с точки зрения аналитики (Data Mining goals)
После того, как задача поставлена в бизнес-терминах, необходимо описать ее в технических терминах. В частности, отвечаем на следующие вопросы.
- Какую метрику мы будем использовать для оценки результата моделирования (а выбрать есть из чего: Accuracy, RMSE, AUC, Precision, Recall, F-мера, R2, Lift, Logloss и т.д.)?
- Каков критерий успешности модели (например, считаем AUC равный 0.65 — минимальным порогом, 0.75 — оптимальным)?
- Если объективный критерий качества использовать не будем, то как будут оцениваться результаты?
1.4 План проекта (Project Plan)
Как только получены ответы на все основные вопросы и ясна цель проекта, время составить план проекта. План должен содержать оценку всех шести фаз внедрения.
2. Анализ данных (Data Understanding)
Начинаем реализацию проекта и для начала смотрим на данные. На этом шаге никакого моделирования нет, используется только описательная аналитика.
Цель шага – понять слабые и сильные стороны предоставленных данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять процессы заказчика. Для этого мы строим графики, делаем выборки и рассчитываем статистики.
2.1 Сбор данных (Data collection)

Источник
Для начала нужно понимать, какими данными располагает заказчик. Данные могут быть:
- собственные (1st party data),
- сторонние данные (3rd party),
- «потенциальные» данные (для получения которых необходимо организовать сбор).
Необходимо проанализировать все источники, доступ к которым предоставляет заказчик. Если собственных данных недостаточно, возможно, стоит закупить сторонние или организовать сбор новых данных.
2.2 Описание данных (Data description)
Далее смотрим на доступные нам данные.
- Необходимо описать данные во всех источниках (таблица, ключ, количество строк, количество столбцов, объем на диске).
- Если объем слишком велик для используемого ПО, создаем сэмпл данных.
- Считаем ключевые статистики по атрибутам (минимум, максимум, разброс, кардинальность и т.д.).
2.3 Исследование данных (Data exploration)
С помощью графиков и таблиц исследуем данные, чтобы сформулировать гипотезы относительно того, как эти данные помогут решить задачу.
В мини-отчете фиксируем, что интересного нашли в данных, а также список атрибутов, которые потенциально полезны.
2.4 Качество данных (Data quality)
Важно еще до моделирования оценить качество данных, так как любые несоответствия могут повлиять на ход проекта. Какие могут быть сложности с данными?
- Пропущенные значения.
К примеру, мы делаем модель классификации клиентов банка по их продуктовым предпочтениям, но, поскольку анкеты заполняют только клиенты-заемщики, атрибут «уровень з/п» у клиентов-вкладчиков не заполнен. - Ошибки данных (опечатки)
- Неконсистентная кодировка значений (например «M» и «male» в разных системах)
3. Подготовка данных (Data Preparation)

Источник
Подготовка данных – это традиционно наиболее затратный по времени этап machine learning проекта (в описании говорится о 50-70% времени проекта, по нашему опыту может быть еще больше). Цель этапа – подготовить обучающую выборку для использования в моделировании.
3.1 Отбор данных (Data Selection)
Для начала нужно отобрать данные, которые мы будем использовать для обучения модели.
Отбираются как атрибуты, так и кейсы.
Например, если мы делаем продуктовые рекомендации посетителям сайта, мы ограничиваемся анализом только зарегистрированных пользователей.
При выборе данных аналитик отвечает на следующие вопросы.
- Какова потенциальная релевантность атрибута решаемой задаче?
Так, электронная почта или номер телефона клиента как предикторы для прогнозирования явно бесполезны. А вот домен почты (mail.ru, gmail.com) или код оператора в теории уже могут обладать предсказательной способностью. - Достаточно ли качественный атрибут для использования в модели?
Если видим, что большая часть значений атрибута пуста, то атрибут, скорее всего, бесполезен. - Стоит ли включать коррелирующие друг с другом атрибуты?
- Есть ли ограничения на использование атрибутов?
Например, политика компании может запрещать использование атрибутов с персональной информацией в качестве предикторов.
3.2 Очистка данных (Data Cleaning)
Когда отобрали потенциально интересные данные, проверяем их качество.
- Пропущенные значения => нужно либо их заполнить, либо удалить из рассмотрения
- Ошибки в данных => попробовать исправить вручную либо удалить из рассмотрения
- Несоответствующая кодировка => привести к единой кодировке
На выходе получается 3 списка атрибутов – качественные атрибуты, исправленные атрибуты и забракованные.
3.3 Генерация данных (Constructing new data)
Часто генерация признаков (feature engineering) – это наиболее важный этап в подготовке данных: грамотно составленный признак может существенно улучшить качество модели.
К генерации данных можно отнести:
- агрегацию атрибутов (расчет sum, avg, min, max, var и т.д.),
- генерацию кейсов (например, oversampling или алгоритм SMOTE),
- конвертацию типов данных для использования в разных моделях (например, SVM традиционно работает с интервальными данными, а CHAID с номинальными),
- нормализацию атрибутов (feature scaling),
- заполнение пропущенных данных (missing data imputation).
3.4 Интеграция данных (Integrating data)
Хорошо, когда данные берутся из корпоративного хранилища (КХД) или заранее подготовленной витрины. Однако часто данные необходимо загружать из нескольких источников и для подготовки обучающей выборки требуется их интеграция. Под интеграцией понимается как «горизонтальное» соединение (Merge), так и «вертикальное» объединение (Append), а также агрегация данных. На выходе, как правило, имеем единую аналитическую таблицу, пригодную для поставки в аналитическое ПО в качестве обучающей выборки.
3.5 Форматирование данных (Formatting Data)
Наконец, нужно привести данные к формату, пригодному для моделирования (только для тех алгоритмов, которые работают с определенным форматом данных). Так, если речь идет об анализе временного ряда – к примеру, прогнозируем ежемесячные продажи торговой сети – возможно, его нужно предварительно отсортировать.
4. Моделирование (Modeling)
На четвертом шаге наконец-то начинается самое интересное — обучение моделей. Как правило, оно выполняется итерационно – мы пробуем различные модели, сравниваем их качество, делаем перебор гиперпараметров и выбираем лучшую комбинацию. Это наиболее приятный этап проекта.
4.1 Выбор алгоритмов (Selecting the modeling technique)
Необходимо определиться, какие модели будем использовать (благо, их множество). Выбор модели зависит от решаемой задачи, типов атрибутов и требований по сложности (например, если модель будет дальше внедряться в Excel, то RandomForest и XGBoost явно не подойдут). При выборе следует обратить внимание на следующее.
- Достаточно ли данных, поскольку сложные модели как правило требуют большей выборки?
- Сможет ли модель обработать пропуски данных (какие-то реализации алгоритмов умеют работать с пропусками, какие-то нет)?
- Сможет ли модель работать с имеющимися типами данных или необходима конвертация?
4.2 Планирование тестирования (Generating a test design)
Далее надо решить, на чем мы будем обучать, а на чем тестировать нашу модель.
Традиционный подход – это разделение выборки на 3 части (обучение, валидацию и тест) в примерной пропорции 60/20/20. В этом случае обучающая выборка используется для подгонки параметров модели, а валидация и тест для получения очищенной от эффекта переобучения оценки ее качества. Более сложные стратегии предполагают использование различных вариантов кросс-валидации.
Здесь же прикидываем, как будем делать оптимизацию гиперпараметров моделей – сколько будет итераций по каждому алгоритму, будем ли делать grid-search или random-search.
4.3 Обучение моделей (Building the models)
Запускаем цикл обучения и после каждой итерации фиксируем результат. На выходе получаем несколько обученных моделей.
Кроме того, для каждой обученной модели фиксируем следующее.
- Показывает ли модель какие-то интересные закономерности?
Например, что точность предсказания на 99% объясняется всего одним атрибутом. - Какова скорость обучения/применения модели?
Если модель обучается 2 дня, возможно, стоит поискать более эффективный алгоритм или уменьшить обучающую выборку. - Были ли проблемы с качеством данных?
Например, в тестовую выборку попали кейсы с пропущенными значениями, и из-за этого не вся выборка проскорилась.
4.4 Оценка результатов (Assessing the model)

Источник
После того, как был сформирован пул моделей, нужно их еще раз детально проанализировать и выбрать модели-победители. На выходе неплохо иметь список моделей, отсортированный по объективному и/или субъективному критерию.
Задачи шага:
- провести технический анализ качества модели (ROC, Gain, Lift и т.д.),
- оценить, готова ли модель к внедрению в КХД (или куда нужно),
- достигаются ли заданные критерии качества,
- оценить результаты с точки зрения достижения бизнес-целей. Это можно обсудить с аналитиками заказчика.
Если критерий успеха не достигнут, то можно либо улучшать текущую модель, либо пробовать новую.
Прежде чем переходить к внедрению нужно убедиться, что:
- результат моделирования понятен (модель, атрибуты, точность)
- результат моделирования логичен
Например, мы прогнозируем отток клиентов и получили ROC AUC, равный 95%. Слишком хороший результат – повод проверить модель еще раз. - мы попробовали все доступные модели
- инфраструктура готова к внедрению модели
Заказчик: «Давайте внедрять! Только у нас места нет в витрине…».
5. Оценка результата (Evaluation)

Источник
Результатом предыдущего шага является построенная математическая модель (model), а также найденные закономерности (findings). На пятом шаге мы оцениваем результаты проекта.
5.1 Оценка результатов моделирования (Evaluating the results)
Если на предыдущем этапе мы оценивали результаты моделирования с технической точки зрения, то здесь мы оцениваем результаты с точки зрения достижения бизнес-целей.
Адресуем следующие вопросы:
- Формулировка результата в бизнес-терминах. Бизнесу гораздо легче общаться в терминах $ и ROI, чем в абстрактных Lift или R2
Классический пример диалога
Аналитик: Наша модель показывает десятикратный lift!
Бизнес: Я не впечатлён…
Аналитик: Вы заработаете дополнительных 100K$ в год!
Бизнес: С этого надо было начинать! Поподробнее, пожалуйста… - В целом насколько хорошо полученные результаты решают бизнес-задачу?
- Найдена ли какая-то новая ценная информация, которую стоит выделить отдельно?
К примеру, компания-ритейлер фокусировала свои маркетинговые усилия на сегменте «активная молодежь», но, занявшись прогнозированием вероятности отклика, с удивлением обнаружила, что их целевой сегмент совсем другой – «обеспеченные дамы 40+».
5.2 Разбор полетов (Review the process)
Стоит собраться
за кружкой пива
за столом, проанализировать ход проекта и сформулировать его сильные и слабые стороны. Для этого нужно пройтись по всем шагам:
- Можно ли было какие-то шаги сделать более эффективными?
Например, из-за неповоротливости IT-отдела заказчика целый месяц ушел на согласование доступов. Не гуд! - Какие были допущены ошибки и как их избежать в будущем?
На этапе планирования недооценили сложность выгрузки данных из источников и в результате не уложились в сроки. - Были ли не сработавшие гипотезы? Если да, стоит ли их повторять?
Аналитик: «А давайте теперь попробуем сверточную нейронную сеть… Всё становится лучше с нейросетями!» - Были ли неожиданности при реализации шагов? Как их предусмотреть в будущем?
Заказчик: «Ok. А мы думали, что обучающая выборка для разработки модели не нужна…»
5.3 Принятие решения (Determining the next steps)
Далее нужно либо внедрять модель, если она устраивает заказчика, либо, если виден потенциал для улучшения, попытаться еще ее улучшить.
Если на данном этапе у нас несколько удовлетворяющих моделей, то отбираем те, которые будем дальше внедрять.
6. Внедрение (Deployment)

Источник
Перед началом проекта с заказчиком всегда оговаривается способ поставки модели. В одном случае это может быть просто проскоренная база клиентов, в другом – SQL-формула, в третьем – полностью проработанное аналитическое решение, интегрированное в информационную систему.
На данном шаге осуществляется внедрение модели (если проект предполагает этап внедрения). Причем под внедрением может пониматься как физическое добавление функционала, так и инициирование изменений в бизнес-процессах компании.
6.1 Планирование развертывания (Planning Deployment)
Наконец собрали в кучу все полученные результаты. Что теперь?
- Важно зафиксировать, что именно и в каком виде мы будем внедрять, а также подготовить технический план внедрения (пароли, явки и прочее)
- Продумать, как с внедряемой моделью будут работать пользователи
Например, на экране сотрудника колл-центра показываем склонность клиента к подключению дополнительных услуг. - Определить принцип мониторинга решения. Если нужно, подготовиться к опытно-промышленной эксплуатации.
Например, договариваемся об использовании модели в течение года и тюнинге модели раз в 3 месяца.
6.2 Настройка мониторинга модели (Planning Monitoring)
Очень часто в проект включаются работы по поддержке решения. Вот что оговаривается.
- Какие показатели качества модели будут отслеживаться?
В своих банковских проектах мы часто используем популярный в банках показатель population stability index PSI. - Как понимаем, что модель устарела?
Например, если PSI больше 0.15, либо просто договариваемся о регулярном пересчете раз в 3 месяца. - Если модель устарела, достаточно ли будет ее переобучить или нужно организовывать новый проект?
При существенных изменениях в бизнес-процессах тюнинга модели недостаточно, нужен полный цикл переобучения – с добавлением новых атрибутов, отбором предикторов и.т.д.
6.3 Отчет по результатам моделирования (Final Report)
По окончании проекта, как правило, пишется отчет о результатах моделирования, в который добавляются результаты по каждому шагу, начиная от первичного анализа данных и заканчивая внедрением модели. В этот отчет также можно включить рекомендации по дальнейшему развитию модели.
Написанный отчет презентуется заказчику и всем заинтересованным лицам. В отсутствие ТЗ этот отчет является главным документом проекта. Также важно поговорить с задействованными в проекте сотрудниками (как со стороны заказчика, так и со стороны исполнителя) и собрать их мнение о проекте.
Как насчет практики?
Важно понимать, что методология не является универсальным рецептом. Это просто попытка формально описать последовательность действий, которую в той или иной степени выполняет любой аналитик, занимающийся анализом данных.
У нас в CleverDATA следование методологии на дата-майнинговых проектах не является жестким требованием, но, как правило, при составлении плана проекта наша детализация довольно точно укладывается в данную последовательность шагов.
Методология применима к совершенно разным задачам. Мы следовали ей в ряде маркетинговых проектов, в том числе, когда предсказывали вероятность отклика клиента торговой сети на рекламное предложение, делали модель оценки кредитоспособности заемщика для коммерческого банка и разрабатывали сервис рекомендаций товаров для интернет-магазина.
Сто и один отчет

Источник
По задумке авторов, после каждого шага должен писаться некий отчет. Однако на практике это не очень реалистично. Как и у всех, у нас бывают проекты, когда заказчик ставит очень сжатые сроки и необходимо быстро получить результат. Понятно, что в таких условиях нет смысла тратить время на детальное документирование каждого шага. Всю промежуточную информацию, если она нужна, мы в таких случаях фиксируем карандашом «на салфетке». Это позволяет максимально быстро заняться реализацией модели и уложиться в сроки.
На практике многие вещи делаются куда менее формально, чем требует методология. Мы, например, обычно не тратим время на выбор и согласование используемых моделей, а тестируем сразу все доступные алгоритмы (конечно, если ресурсы позволяют). Аналогично поступаем с атрибутами – готовим сразу несколько вариантов каждого атрибута, чтобы можно было опробовать максимальное количество вариантов. Нерелевантные атрибуты при таком подходе отсеиваются автоматически с помощью алгоритмов feature selection – автоматическом определении предсказательной способности атрибутов.
Полагаю, формализм методологии объясняется тем, что она писалась еще в 90-е, когда не было такого количества вычислительнных мощностей и важно было грамотно спланировать каждое действие. Сейчас доступность и дешевизна «железа» упрощает многие вещи.
О важности планирования
Всегда есть соблазн «пробежать» первые два этапа и перейти сразу к реализации. Практика показывает, что это не всегда оправдано.
На этапе постановки бизнес-целей (business understanding) важно как можно детальнее проговорить с заказчиком предлагаемое решение и убедиться, что ваши с ним ожидания совпадают. Бывает так, что бизнес рассчитывает получить в результате некоего «волшебного» робота, который сходу решит все его проблемы и мгновенно увеличит вдвое выручку. Поэтому, чтобы ни у кого не было разочарований по итогам проекта, всегда стоит четко проговаривать, какой именно результат получит заказчик и что он даст бизнесу.
Кроме того, не всегда заказчик может дать правильную оценку точности модели. В качестве примера: предположим, мы анализируем отклик на рекламную кампанию в интернете. Знаем, что по ссылке переходят примерно 10% клиентов. Разработанная нами модель отбирает 1000 наиболее склонных к отклику клиентов, и мы видим, что среди них переходит по ссылке каждый четвертый – получаем точность (precision) в 25%. Модель показывает неплохой результат (в 2.5 раза лучше «случайной» модели), но для заказчика точность в 25% слишком мала (он ждет цифр в районе 80-90%). И наоборот, совершенно бессмысленная модель, которая относит всех в один класс, покажет точность (accuracy), равную 90%, и формально будет удовлетворять заявленному критерию успеха. Т.е. важно вместе с заказчиком выбирать правильную меру качества модели и правильно ее интерпретировать.
Этап исследования (data understanding) важен тем, что позволяет и нам, и заказчику лучше понять его данные. У нас были примеры, когда после презентации результатов шага мы параллельно с основным проектом договаривались о новых, так как заказчик видел потенциал в найденных на этом этапе закономерностях.
В качестве другого примера приведу один из наших проектов, когда мы положились на диалог с заказчиком, ограничились поверхностным изучением данных и на этапе моделирования обнаружили, что часть данных оказалась неприменима из-за многочисленных пропусков. Поэтому всегда стоит заранее изучить данные, с которыми предстоит работать.
Наконец, хочу отметить, что, несмотря на свою полноту, методология все-таки достаточно общая. Она ничего не говорит о выборе конкретных алгоритмов и не дает готовых решений. Возможно, это и хорошо, так как всегда остается пространство для творческого поиска, ведь, повторюсь, сегодня профессия data scientist по-прежнему остается одной из наиболее творческих в IT-сфере.
Жизненный цикл модели машинного обучения Источник
Жизненный цикл модели машинного обучения — это многоэтапный процесс, в течении которого исследователи, инженеры и разработчики обучают, разрабатывают и обслуживают модель машинного обучения. Разработка модели машинного обучения принципиально отличается от традиционной разработки программного обеспечения и требует своего собственного уникального способа разработки. Модель машинного обучения — это приложение искусственного интеллекта (ИИ), которое дает возможность автоматически учиться и совершенствоваться на основе собственного опыта без явного участия человека. Основная цель модели заключается в том, чтобы компания смогла использовать преимущества алгоритмов искусственного интеллекта и машинного обучения для получения дополнительных конкурентных преимуществ. Над каждым этапом работает SCRUM-команда. Сотрудничество команд организуется по методике SCRUM of SCRUMs.
Содержание
- 1 Бизнес-анализ
- 2 Анализ и подготовка данных
- 2.1 Анализ данных
- 2.2 Сбор данных
- 2.3 Нормализация данных
- 2.4 Моделирование данных
- 2.5 Конструирование признаков
- 3 Моделирование
- 3.1 Выбор алгоритма
- 3.2 Планирование тестирования
- 3.3 Обучение модели
- 3.4 Оценка результатов
- 4 Оценка решения
- 5 Внедрение
- 6 Тестирование и мониторинг
- 6.1 Дифференциальные тесты
- 6.2 Контрольные тесты
- 6.3 Нагрузочные / стресс-тесты
- 6.4 A/B-тестирование
- 7 См.также
- 8 Источники информации
Бизнес-анализ
На этом этапе необходимо вместе с заказчиком сформулировать проблемы бизнеса, которые будет решать модель. Также, требуется понять, кто участвует в проекте со стороны заказчика, кто выделяет деньги под проект, и кто принимает ключевые решения. Вдобавок необходимо узнать существуют ли готовые решения и, если да, чем они не устраивают заказчика.
Главная задача этого этапа — понять основные бизнес-переменные, которые будет прогнозировать модель. Такие переменные называются ключевыми показателями модели. После этого необходимо определить какие метрики будут использоваться, чтобы определить успешность проекта. Например, может потребоваться спрогнозировать количество абонентов, которые хотели уйти от своего оператора, но в итоге остались у него. К моменту завершения проекта требуется чтобы модель уменьшила отток абонентов на X%. С помощью этих данных можно составить рекламные предложения для минимизации оттока. Метрики должны быть составлены в соответствии с принципами SMART.
Далее необходимо оценить какие ресурсы потребуются в течении проекта: есть ли у заказчика доступное железо или его необходимо закупать, где и как хранятся данные, будет ли предоставлен доступ в эти системы, нужно ли дополнительно докупать/собирать внешние данные, сможет ли заказчик выделить своих экспертов для консультаций на данный проект.
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению. Типичные риски следующие:
- Не успеть закончить проект к назначенной дате.
- Финансовые риски.
- Малое количество или плохое качество данных, которые не позволят получить эффективную модель.
- Данные качественные, но закономерности в принципе отсутствуют и, в результате, заказчик не заинтересован в полученной модели.
После того, как задача описана на языке бизнеса, необходимо поставить ее в терминах машинного обучения. Особенно нужно узнать ответы на следующие вопросы: Какая метрика будет использована для оценки результата модели(например: accuracy, precision, recall, MSE, MAE и т.д.)? Каков критерий успешности модели (например, считаем точность (англ. accuracy) равный 0.8 — минимально допустимым значением, 0.9 — оптимальным)?
После необходимо сформировать команду проекта, распределить роли и обязанности между его участниками; создать расширенный поэтапный план проекта, который будет дополняться по мере поступления новой информации. Команда проекта состоит из менеджера, исследователей, разработчиков, аналитиков и тестировщиков.
Анализ и подготовка данных
На этом этапе осуществляется анализ, сбор и подготовка всех необходимых данных для использования в модели. Основные задача этого этапа состоит в том, чтобы получить обработанный, высококачественный набор данных, который подчиняется некоторой закономерности. Анализ и подготовка данных состоят из 4 стадий: анализ данных, сбор данных, нормализация данных и моделирование данных.
Анализ данных
Задача этого шага – понять слабые и сильные стороны в имеющихся данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять бизнес-процессы заказчика. Требуется провести анализ всех источников данных, к которым заказчик предоставляет доступ. Если собственных данных не хватает, тогда необходимо купить данные у третьих лиц или организовать сбор новых данных. Для начала нужно понимать, какие данные есть у заказчика. Данные могут быть: собственными, сторонними и «потенциальными» данными (нужно организовать сбор, чтобы их получить). Также требуется описать данные во всех источниках (таблица, ключ, количество строк, количество столбцов, объем на диске). Далее, с помощью таблиц и графиков смотрим на данные, чтобы сформулировать гипотезы о том, как данные помогут решить поставленную задачу. Обязательно до моделирования требуется оценить, насколько качественные нужны данные, так как любые ошибки на данном шаге могут негативно повлиять на ход проекта. Типичные проблемы, которые могут быть в данных: пропущенные значения, ошибки в данных, опечатки, неконсистентная кодировка значений (например «w» и «women» в разных системах).
Сбор данных
Сбор данных — это процесс сбора информации по интересующим переменным в установленной систематической форме, которая позволяет отвечать на поставленные вопросы исследования, проверять гипотезы и оценивать результаты. Правильный сбор данных имеет важное значение для обеспечения целостности исследований. Как выбор подходящих инструментов сбора данных, так и четко разграниченные инструкции по их правильному использованию снижают вероятность возникновения ошибок. Прогнозирующие модели хороши только для данных, из которых они построены, поэтому правильная практика сбора данных имеет решающее значение для разработки высокопроизводительных моделей. Данные не должны содержать ошибок и должны быть релевантными.
Нормализация данных
Следующий шаг в процессе подготовки — это то место, где аналитики и инженеры данных обычно проводят большую часть своего времени: очистка и нормализация «грязных» данных. Часто это требует от них принимать решения на основе данных, которые они не совсем понимают, например, что делать с отсутствующими или неполными данными, а также с выбросами. Что еще хуже, эти данные нелегко соотнести с соответствующей единицей анализа: клиентом. Например, чтобы предсказать, уйдет ли один клиент (а не сегмент или целая аудитория), нельзя полагаться на данные из разрозненных источников. Инженер по данным подготавливает и объединяет все данные из этих источников в формат, который могут интерпретировать модели машинного обучения.
Моделирование данных
Следующим этапом подготовки данных является моделирование данных, которые мы хотим использовать для прогнозирования. Моделирование данных — это сложный процесс создания логического представления структуры данных. Правильно сконструированная модель данных должна быть адекватна предметной области, т.е. соответствовать всем пользовательским представлениям данных. Моделирование также включает в себя смешивание и агрегирование веб данных, данных из мобильных приложений, оффлайн данных и др.
Для модели, рассматриваемой в данном конспекте, инженеры объединяют разнородные данные в цельный набор данных. Например, у них есть уже готовые данные по признакам, и они объединяют их в один набор данных.
Конструирование признаков
Конструирование признаков состоит из учета, статистической обработки и преобразования данных для выбора признаков, используемых в модели. Чтобы понять лежащие в основе модели механизмы, целесообразно оценить связь между компонентами и понять, как алгоритмы машинного обучения будут использовать эти компоненты.
На данном этапе нужно творческое сочетание опыта и информации, полученной на этапе исследования данных. В конструирование признаков необходимо найти баланс. Важно найти и учесть информативные переменные, не создавая при этом лишние несвязанные признаки. Информативные признаки улучшают результат модели, а не информативные — добавляют в модель ненужный шум. При выборе признаков необходимо учитывать все новые данные, полученные во время обучения модели.
Моделирование
На этом шаге происходит обучения модели. Обучение моделей машинного обучения происходит итерационно – пробуются различные модели, перебираются гиперпараметры, сравниваются значения выбранной метрики и выбирается лучшая комбинация.
Выбор алгоритма
Вначале нужно понять, какие модели будут использоваться. Выбор модели зависит от решаемой задачи, используемых признаков и требований по сложности (например, если модель будет дальше внедряться в Excel, то Дерево решений или AdaBoost не подойдут). При выборе модели обязательно принять во внимание следующие факторы:
- Достаточность данных (обычно, сложные модели требуют большого количества данных).
- Обработка пропусков (некоторые алгоритмы не умеют обрабатывать пропуски).
- Формат данных (для части алгоритмов потребуется конвертация данных).
Планирование тестирования
Далее необходимо определить, на каких данных будет обучаться модель, а на каких тестироваться. Традиционный подход – это разделение набора данных на 3 части (обучение, валидация и тестирование) в пропорции 60/20/20. В данном случае обучающая выборка используется для обучения модели, а валидация и тестирование для получения значения метрики без эффекта переобучения. Более сложные стратегии обучения модели подразумевают использование различных вариантов кросс-валидации. Также на данном шаге требуется определить, как будет происходить оптимизация гиперпараметров моделей, сколько потребуется итераций для каждого алгоритма, будет ли использоваться grid-search или random-search.
Обучение модели
На данном шаге начинается цикл обучения. После каждой итерации записывается результат модели. На выходе получаем результаты для каждой модели и использованных в ней гиперпараметров. Кроме того, для моделей, у которых значение выбранной метрики превышает минимально допустимое, нужно обратить внимание на следующие особенности:
- Необычные закономерности (Например, точность предсказания модели на 95% объясняется всего лишь одним признаком).
- Скорость обучения модели (Если модель долго обучается, то стоит использовать более эффективный алгоритм или уменьшить обучающую выборку).
- Проблемы с данными (Например, в тестовую выборку попали объекты с пропущенными значениями, и, как следствие, значение метрики было посчитано не полностью, и она не позволяет целиком оценить модель).
Оценка результатов
После формирования списка из подходящих моделей, нужно еще раз их детально проанализировать и выбрать лучшие модели. На выходе необходимо иметь список моделей, отсортированный по объективному и/или субъективному критерию. Задачи шага: провести технический анализ качества модели (ROC, Gain, K-S и т.д.), оценить, готова ли модель к внедрению в корпоративное хранилище данных, достигаются ли заданные критерии качества, проанализировать результаты с точки зрения достижения бизнес-целей. Если критерий успешности (выбранная метрика) не достигнут, то необходимо или улучшить текущую модель, или использовать другую. Прежде чем переходить к внедрению нужно убедиться, что результат моделирования понятен и логичен. Например, прогнозируется отток клиентов и значение метрики GAIN равно 99%. Слишком хороший результат – повод проверить модель еще раз.
Оценка решения
Результатом предшествующего этапа является построенная модель машинного обучения и найденные закономерности. На данном этапе происходит оценивание результатов проекта.
Если на предыдущем этапе оценивались результаты моделирования с технической точки зрения, то здесь происходит оценка результатов с позиции достижения бизнес-целей. Например, насколько качественно полученная модель решает поставленные бизнес-задачи. Также, необходимо понять найдена ли в течении проекта какая-то новая полезная информация, которую стоит выделить отдельно. Далее необходимо проанализировать ход проекта и сформулировать его сильные и слабые стороны. Для этого нужно ответить на следующие вопросы:
- Какие этапы проекта можно было сделать эффективнее?
- Какие ошибки были сделаны? Возможно ли их избежать в будущем?
- Были ли не сработавшие гипотезы? Если да, стоит ли их повторять?
- Были ли неожиданности при реализации шагов? Как их предусмотреть в будущем?
Затем, если модель устраивает заказчика, то необходимо или внедрить модель, или, если существует возможности для улучшения, улучшить модель. Если на данном этапе несколько подходящих моделей, то нужно выбрать модель, которая будет дальше внедряться.
Внедрение
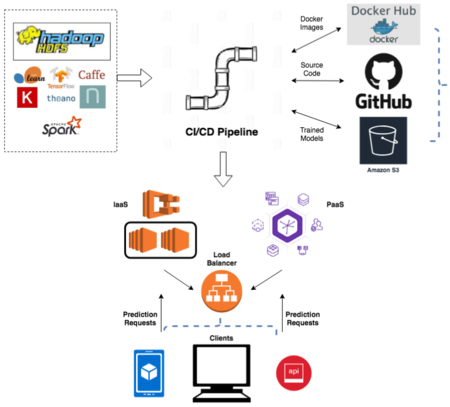
Внедрение модели машинного обучения в производство означает доступность модели для других бизнес-систем. Внедряя модель, другие системы могут отправлять ей данные и получать от модели прогнозы, которые, в свою очередь, используются в системах компании. Благодаря внедрению модели машинного обучения, компания сможет в полной мере воспользоваться созданной моделью машинного обучения.
Основная задача, решаемая на этом этапе — ввод модели в эксплуатацию. Необходимо развернуть модель и конвейер в рабочую или близкую к ней среду, чтобы приложения могли к ней обращаться.
Создав эффективно работающую модель, требуется ввести ее в эксплуатацию для взаимодействия с другими системами компании. В зависимости от бизнес-требований, модель исполняет прогнозы в режиме реального времени или в стандартном режиме. Для развертывания модели, необходимо внедрять модель с помощью открытого API-интерфейса. Интерфейс упрощает использование модели различными приложениями, например:
- Веб-сайты.
- Электронные таблицы.
- Панели мониторинга бизнес-приложения.
- Серверные приложения.
Также необходимо понять, собирается ли компания использовать Платформу как Сервис (англ. Platform as a Service, PaaS) или Инфраструктуру как Сервис (англ. Infrastructure as a Service, IaaS). PaaS может быть полезен для создания прототипов и компаний с меньшим трафиком. В конце концов, по мере роста бизнеса и / или увеличения трафика компании придется использовать IaaS с большей сложностью. Есть множество решений от больших компаний (AWS, Google, Microsoft). Если приложения контейнеризованы, развертывание на большинстве платформ / инфраструктур будет проще. Контейнезирование также дает возможность использовать платформу оркестровки контейнеров для быстрого масштабирования количества контейнеров по мере увеличения спроса. Далее, нужно убедиться, что развертывание происходит через платформу непрерывного развертывания(англ. Continuous Deployment platform).
Тестирование и мониторинг
На данном этапе осуществляется тестирование, мониторинг и контролирование модели. В основном тесты моделей машинного обучения делятся на следующие части:
Дифференциальные тесты
Происходит сравнение результатов, данных новой моделью, и результатов, данных старой моделью для стандартного набора тестовых данных. Необходимо настроить чувствительность этих тестов в зависимости от варианта использования модели. Эти тесты могут быть жизненно важны для обнаружения модели, которая выглядит работающей, но, на самом деле, таковой не является, например, когда устаревший набор данных использовался в обучении или модель обучилась не на всех признаках. Такие проблемы, присущие машинному обучения, не приведут к ошибке на стандартных тестах.
Контрольные тесты
Тесты сравнивают время, затрачиваемое либо на обучение, либо на предоставление прогнозов из модели от одной версии к другой. Они мешают вводить неэффективные добавления кода в модели машинного обучения. Опять же, это то, что трудно уловить с помощью традиционных тестов (хотя некоторые инструменты статического анализа кода могут помочь).
Нагрузочные / стресс-тесты
Это не совсем специфичные тесты для модели машинного обучения, но с учетом необычно больших требований к ЦП / памяти в некоторых моделях машинного обучения такие тесты особенно стоит использовать.
A/B-тестирование
Еще один популярный способ тестирования — A/B-тестирование. Этот метод также называется сплит-тестированием (англ. split testing ). A/B-тестирование позволяет оценивать количественные показатели работы двух вариантов модели, а также сравнивать их между собой. Чтобы получить статистически значимый результат, очень важно исключить влияние моделей друг на друга.
Все вышеперечисленные тесты намного проще использовать с контейнеризованными приложениями, так как это делает раскрутку реалистичного производственного стека тривиальной.
Мониторинг и оповещение могут быть особенно важны при развертывании моделей. По мере усложнения системы потребуются возможности мониторинга и оповещения, чтобы сообщать, когда прогнозы для конкретной системы выходят за пределы ожидаемого диапазона. Мониторинг и оповещение также могут быть связаны с косвенными проблемами, например, при обучении новой сверточной нейронной сети расходовать ежемесячный бюджет AWS за 30 минут. Также понадобятся панели управления, позволяющие быстро проверить развернутые версии моделей.
См.также
- Общие понятия
- Модель алгоритма и её выбор
- Оценка качества в задачах классификации и регрессии
Источники информации
- The Team Data Science Process lifecycle
- How to Deploy Machine Learning Models
- Deploy Machine Learning Models with Django
- Machine Learning Data Preparation
Постановка задач машинного обучения математически очень проста. Любая задача классификации, регрессии или кластеризации – это по сути обычная оптимизационная задача с ограничениями. Несмотря на это, существующее многообразие алгоритмов и методов их решения делает профессию аналитика данных одной из наиболее творческих IT-профессий. Чтобы решение задачи не превратилось в бесконечный поиск «золотого» решения, а было прогнозируемым процессом, необходимо придерживаться довольно четкой последовательности действий. Эту последовательность действий описывают такие методологии, как CRISP-DM.
Методология анализа данных CRISP-DM упоминается во многих постах на Хабре, но я не смог найти ее подробных русскоязычных описаний и решил своей статьей восполнить этот пробел. В основе моего материала – оригинальное описание и адаптированное описание от IBM. Обзорную лекцию о преимуществах использования CRISP-DM можно посмотреть, например, здесь.
* Crisp (англ.) — хрустящий картофель, чипсы
Я работаю в компании CleverDATA (входит в группу ЛАНИТ) на позиции дата-сайентиста с 2015 года. Мы занимаемся проектами в области больших данных и машинного обучения, преимущественно в сфере data-driven маркетинга (то есть маркетинга, построенного на «глубоком» анализе клиентских данных). Также развиваем платформу управления данными 1DMP и биржу данных 1DMC. Наши типичные проекты по машинному обучению – это разработка и внедрение предиктивных (прогнозирующих) и прескриптивных (рекомендующих наилучшее действие) моделей для оптимизации ключевых бизнес-показателей заказчика. В ряде подобных проектов мы использовали методологию CRISP-DM.
CRoss Industry Standard Process for Data Mining (CRISP-DM) – стандарт, описывающий общие процессы и подходы к аналитике данных, используемые в промышленных data-mining проектах независимо от конкретной задачи и индустрии.
На известном аналитическом портале kdnuggets.org периодически публикуется опрос (например, здесь), согласно которому среди методологий анализа данных первое место по популярности регулярно занимает именно CRISP-DM, дальше с большим отрывом идет SEMMA и реже всего используется KDD Process.
Источник: kdnuggets.com
В целом, эти три методологии очень похожи друг на друга (здесь сложно придумать что-то принципиально новое). Однако CRISP-DM заслужила популярность как наиболее полная и детальная. По сравнению с ней KDD является более общей и теоретической, а SEMMA – это просто организация функций по целевому предназначению в инструменте SAS Enterprise Miner и затрагивает исключительно технические аспекты моделирования, никак не касаясь бизнес-постановки задачи.
О методологии
Методология разработана в 1996 году по инициативе трех компаний (нынешние DaimlerChrysler, SPSS и Teradata) и далее дорабатывалась при участии 200 компаний различных индустрий, имеющих опыт data-mining проектов. Все эти компании использовали разные аналитические инструменты, но процесс у всех был построен очень похоже.
Методология активно продвигается компанией IBM. Например, она интегрирована в продукт IBM SPSS Modeler (бывший SPSS Clementine).
Важное свойство методологии – уделение внимания бизнес-целям компании. Это позволяет руководству воспринимать проекты по анализу данных не как «песочницу» для экспериментов, а как полноценный элемент бизнес-процессов компании.
Вторая особенность — это довольно детальное документирование каждого шага. По мнению авторов, хорошо задокументированный процесс позволяет менеджменту лучше понимать суть проекта, а аналитикам – больше влиять на принятие решений.
Согласно CRISP-DM, аналитический проект состоит из шести основных этапов, выполняемых последовательно:
- Бизнес-анализ (Business understanding)
- Анализ данных (Data understanding)
- Подготовка данных (Data preparation)
- Моделирование (Modeling)
- Оценка результата (Evaluation)
- Внедрение (Deployment)
Методология не жесткая. Она допускает вариацию в зависимости от конкретного проекта – можно возвращаться к предыдущим шагам, можно какие-то шаги пропускать, если для решаемой задачи они не важны:

Источник Wikipedia
Каждый из этих этапов в свою очередь делится на задачи. На выходе каждой задачи должен получаться определенный результат. Задачи следующие:
Источник Crisp_DM Documentation
В описании шагов я сознательно не буду углубляться в математику и алгоритмы, поскольку в статье фокус делается именно на процесс. Предполагаю, что читатель знаком с основами машинного обучения, но на всякий случай в следующем параграфе приводится описание базовых терминов.
Также обращу внимание, что методология одинаково применима как для внутренних проектов, так и для ситуаций, когда проект делается консультантами.
Несколько базовых понятий машинного обучения
Как правило, основным результатом аналитического проекта является математическая модель. Что такое модель?
Пусть у бизнеса есть некая интересующая его величина — y (например, вероятность оттока клиента). А также есть данные — x (например, обращения клиента в техподдержку), от которых может зависеть y. Бизнес хочет понимать, как именно y зависит от x, чтобы в дальнейшем через настройку x он мог влиять на y. Таким образом, задача проекта — найти функцию f, которая лучше всего моделирует исследуемую зависимость y = f(x).
Под моделью мы будем понимать формулу f(x) либо программу, реализующую эту формулу. Любая модель описывается, во-первых, своим алгоритмом обучения (это может быть регрессия, дерево решений, градиентный бустинг и прочее), а во-вторых, набором своих параметров (которые у каждого алгоритма свои). Обучение модели – процесс поиска таких параметров, при которых модель лучше всего аппроксимирует наблюдаемые данные.
Обучающая выборка – таблица, содержащая пары x и y. Строки в этой таблице называются кейсами, а столбцы – атрибутами. Атрибуты, обладающие достаточной предсказательной способностью, будем называть предикторами. В случае с обучением «без учителя» (например, в задачах кластеризации), обучающая выборка состоит только из x. Скоринг – это применение найденной функции f(x) к новым данным, по которым y пока неизвестен. Например, в задаче кредитного скоринга сначала моделируется вероятность несвоевременной оплаты долга клиентом, а затем разработанная модель применяется к новым заявителям для оценки их кредитоспособности.
Пошаговое описание методологии
Источник
1. Бизнес-анализ (Business Understanding)
На первом шаге нам нужно определиться с целями и скоупом проекта.
Цель проекта (Business objectives)
Первым делом знакомимся с заказчиком и пытаемся понять, что же он на самом деле хочет (или рассказываем ему). На следующие вопросы хорошо бы получить ответ.
- Организационная структура: кто участвует в проекте со стороны заказчика, кто выделяет деньги под проект, кто принимает ключевые решения, кто будет основным пользователем? Собираем контакты.
- Какова бизнес-цель проекта?
Например, уменьшение оттока клиентов. - Существуют ли какие-то уже разработанные решения? Если существуют, то какие и чем именно текущее решение не устраивает?
1.2 Текущая ситуация (Assessing current solution)
Источник
Когда вместе с заказчиком разобрались, что мы хотим, нужно оценить, что мы можем предложить с учетом текущих реалий.
Оцениваем, хватает ли ресурсов для проекта.
- Есть ли доступное железо или его необходимо закупать?
- Где и как хранятся данные, будет ли предоставлен доступ в эти системы, нужно ли дополнительно докупать/собирать внешние данные?
- Сможет ли заказчик выделить своих экспертов для консультаций на данный проект?
Нужно описать вероятные риски проекта, а также определить план действий по их уменьшению.
Типичные риски следующие.
- Не уложиться в сроки.
- Финансовые риски (например, если спонсор потеряет заинтересованность в проекте).
- Малое количество или плохое качество данных, которые не позволят получить эффективную модель.
- Данные качественные, но закономерности в принципе отсутствуют и, как следствие, полученные результаты не интересны заказчику.
Важно, чтобы заказчик и исполнитель говорили на одном языке, поэтому перед началом проекта лучше составить глоссарий и договориться об используемой в рамках проекта терминологии. Так, если мы делаем модель оттока для телекома, необходимо сразу договориться, что именно мы будем считать оттоком – например, отсутствие значительных начислений по счету в течение 4 недель подряд.
Далее стоит (хотя бы грубо) оценить ROI. В machine-learning проектах обоснованную оценку окупаемости часто можно получить только по завершению проекта (либо пилотного моделирования), но понимание потенциальной выгоды может стать хорошим драйвером для всех.
1.3 Решаемые задачи с точки зрения аналитики (Data Mining goals)
После того, как задача поставлена в бизнес-терминах, необходимо описать ее в технических терминах. В частности, отвечаем на следующие вопросы.
- Какую метрику мы будем использовать для оценки результата моделирования (а выбрать есть из чего: Accuracy, RMSE, AUC, Precision, Recall, F-мера, R2, Lift, Logloss и т.д.)?
- Каков критерий успешности модели (например, считаем AUC равный 0.65 — минимальным порогом, 0.75 — оптимальным)?
- Если объективный критерий качества использовать не будем, то как будут оцениваться результаты?
1.4 План проекта (Project Plan)
Как только получены ответы на все основные вопросы и ясна цель проекта, время составить план проекта. План должен содержать оценку всех шести фаз внедрения.
2. Анализ данных (Data Understanding)
Начинаем реализацию проекта и для начала смотрим на данные. На этом шаге никакого моделирования нет, используется только описательная аналитика.
Цель шага – понять слабые и сильные стороны предоставленных данных, определить их достаточность, предложить идеи, как их использовать, и лучше понять процессы заказчика. Для этого мы строим графики, делаем выборки и рассчитываем статистики.
2.1 Сбор данных (Data collection)
Источник
Для начала нужно понимать, какими данными располагает заказчик. Данные могут быть:
- собственные (1st party data),
- сторонние данные (3rd party),
- «потенциальные» данные (для получения которых необходимо организовать сбор).
Необходимо проанализировать все источники, доступ к которым предоставляет заказчик. Если собственных данных недостаточно, возможно, стоит закупить сторонние или организовать сбор новых данных.
2.2 Описание данных (Data description)
Далее смотрим на доступные нам данные.
- Необходимо описать данные во всех источниках (таблица, ключ, количество строк, количество столбцов, объем на диске).
- Если объем слишком велик для используемого ПО, создаем сэмпл данных.
- Считаем ключевые статистики по атрибутам (минимум, максимум, разброс, кардинальность и т.д.).
2.3 Исследование данных (Data exploration)
С помощью графиков и таблиц исследуем данные, чтобы сформулировать гипотезы относительно того, как эти данные помогут решить задачу.
В мини-отчете фиксируем, что интересного нашли в данных, а также список атрибутов, которые потенциально полезны.
2.4 Качество данных (Data quality)
Важно еще до моделирования оценить качество данных, так как любые несоответствия могут повлиять на ход проекта. Какие могут быть сложности с данными?
- Пропущенные значения.
К примеру, мы делаем модель классификации клиентов банка по их продуктовым предпочтениям, но, поскольку анкеты заполняют только клиенты-заемщики, атрибут «уровень з/п» у клиентов-вкладчиков не заполнен. - Ошибки данных (опечатки)
- Неконсистентная кодировка значений (например «M» и «male» в разных системах)
3. Подготовка данных (Data Preparation)
Источник
Подготовка данных – это традиционно наиболее затратный по времени этап machine learning проекта (в описании говорится о 50-70% времени проекта, по нашему опыту может быть еще больше). Цель этапа – подготовить обучающую выборку для использования в моделировании.
3.1 Отбор данных (Data Selection)
Для начала нужно отобрать данные, которые мы будем использовать для обучения модели.
Отбираются как атрибуты, так и кейсы.
Например, если мы делаем продуктовые рекомендации посетителям сайта, мы ограничиваемся анализом только зарегистрированных пользователей.
При выборе данных аналитик отвечает на следующие вопросы.
- Какова потенциальная релевантность атрибута решаемой задаче?
Так, электронная почта или номер телефона клиента как предикторы для прогнозирования явно бесполезны. А вот домен почты (mail.ru, gmail.com) или код оператора в теории уже могут обладать предсказательной способностью. - Достаточно ли качественный атрибут для использования в модели?
Если видим, что большая часть значений атрибута пуста, то атрибут, скорее всего, бесполезен. - Стоит ли включать коррелирующие друг с другом атрибуты?
- Есть ли ограничения на использование атрибутов?
Например, политика компании может запрещать использование атрибутов с персональной информацией в качестве предикторов.
3.2 Очистка данных (Data Cleaning)
Когда отобрали потенциально интересные данные, проверяем их качество.
- Пропущенные значения => нужно либо их заполнить, либо удалить из рассмотрения
- Ошибки в данных => попробовать исправить вручную либо удалить из рассмотрения
- Несоответствующая кодировка => привести к единой кодировке
На выходе получается 3 списка атрибутов – качественные атрибуты, исправленные атрибуты и забракованные.
3.3 Генерация данных (Constructing new data)
Часто генерация признаков (feature engineering) – это наиболее важный этап в подготовке данных: грамотно составленный признак может существенно улучшить качество модели.
К генерации данных можно отнести:
- агрегацию атрибутов (расчет sum, avg, min, max, var и т.д.),
- генерацию кейсов (например, oversampling или алгоритм SMOTE),
- конвертацию типов данных для использования в разных моделях (например, SVM традиционно работает с интервальными данными, а CHAID с номинальными),
- нормализацию атрибутов (feature scaling),
- заполнение пропущенных данных (missing data imputation).
3.4 Интеграция данных (Integrating data)
Хорошо, когда данные берутся из корпоративного хранилища (КХД) или заранее подготовленной витрины. Однако часто данные необходимо загружать из нескольких источников и для подготовки обучающей выборки требуется их интеграция. Под интеграцией понимается как «горизонтальное» соединение (Merge), так и «вертикальное» объединение (Append), а также агрегация данных. На выходе, как правило, имеем единую аналитическую таблицу, пригодную для поставки в аналитическое ПО в качестве обучающей выборки.
3.5 Форматирование данных (Formatting Data)
Наконец, нужно привести данные к формату, пригодному для моделирования (только для тех алгоритмов, которые работают с определенным форматом данных). Так, если речь идет об анализе временного ряда – к примеру, прогнозируем ежемесячные продажи торговой сети – возможно, его нужно предварительно отсортировать.
4. Моделирование (Modeling)
На четвертом шаге наконец-то начинается самое интересное — обучение моделей. Как правило, оно выполняется итерационно – мы пробуем различные модели, сравниваем их качество, делаем перебор гиперпараметров и выбираем лучшую комбинацию. Это наиболее приятный этап проекта.
4.1 Выбор алгоритмов (Selecting the modeling technique)
Необходимо определиться, какие модели будем использовать (благо, их множество). Выбор модели зависит от решаемой задачи, типов атрибутов и требований по сложности (например, если модель будет дальше внедряться в Excel, то RandomForest и XGBoost явно не подойдут). При выборе следует обратить внимание на следующее.
- Достаточно ли данных, поскольку сложные модели как правило требуют большей выборки?
- Сможет ли модель обработать пропуски данных (какие-то реализации алгоритмов умеют работать с пропусками, какие-то нет)?
- Сможет ли модель работать с имеющимися типами данных или необходима конвертация?
4.2 Планирование тестирования (Generating a test design)
Далее надо решить, на чем мы будем обучать, а на чем тестировать нашу модель.
Традиционный подход – это разделение выборки на 3 части (обучение, валидацию и тест) в примерной пропорции 60/20/20. В этом случае обучающая выборка используется для подгонки параметров модели, а валидация и тест для получения очищенной от эффекта переобучения оценки ее качества. Более сложные стратегии предполагают использование различных вариантов кросс-валидации.
Здесь же прикидываем, как будем делать оптимизацию гиперпараметров моделей – сколько будет итераций по каждому алгоритму, будем ли делать grid-search или random-search.
4.3 Обучение моделей (Building the models)
Запускаем цикл обучения и после каждой итерации фиксируем результат. На выходе получаем несколько обученных моделей.
Кроме того, для каждой обученной модели фиксируем следующее.
- Показывает ли модель какие-то интересные закономерности?
Например, что точность предсказания на 99% объясняется всего одним атрибутом. - Какова скорость обучения/применения модели?
Если модель обучается 2 дня, возможно, стоит поискать более эффективный алгоритм или уменьшить обучающую выборку. - Были ли проблемы с качеством данных?
Например, в тестовую выборку попали кейсы с пропущенными значениями, и из-за этого не вся выборка проскорилась.
4.4 Оценка результатов (Assessing the model)
Источник
После того, как был сформирован пул моделей, нужно их еще раз детально проанализировать и выбрать модели-победители. На выходе неплохо иметь список моделей, отсортированный по объективному и/или субъективному критерию.
Задачи шага:
- провести технический анализ качества модели (ROC, Gain, Lift и т.д.),
- оценить, готова ли модель к внедрению в КХД (или куда нужно),
- достигаются ли заданные критерии качества,
- оценить результаты с точки зрения достижения бизнес-целей. Это можно обсудить с аналитиками заказчика.
Если критерий успеха не достигнут, то можно либо улучшать текущую модель, либо пробовать новую.
Прежде чем переходить к внедрению нужно убедиться, что:
- результат моделирования понятен (модель, атрибуты, точность)
- результат моделирования логичен
Например, мы прогнозируем отток клиентов и получили ROC AUC, равный 95%. Слишком хороший результат – повод проверить модель еще раз. - мы попробовали все доступные модели
- инфраструктура готова к внедрению модели
Заказчик: «Давайте внедрять! Только у нас места нет в витрине…».
5. Оценка результата (Evaluation)
Источник
Результатом предыдущего шага является построенная математическая модель (model), а также найденные закономерности (findings). На пятом шаге мы оцениваем результаты проекта.
5.1 Оценка результатов моделирования (Evaluating the results)
Если на предыдущем этапе мы оценивали результаты моделирования с технической точки зрения, то здесь мы оцениваем результаты с точки зрения достижения бизнес-целей.
Адресуем следующие вопросы:
- Формулировка результата в бизнес-терминах. Бизнесу гораздо легче общаться в терминах $ и ROI, чем в абстрактных Lift или R2
Классический пример диалога
Аналитик: Наша модель показывает десятикратный lift!
Бизнес: Я не впечатлён…
Аналитик: Вы заработаете дополнительных 100K$ в год!
Бизнес: С этого надо было начинать! Поподробнее, пожалуйста… - В целом насколько хорошо полученные результаты решают бизнес-задачу?
- Найдена ли какая-то новая ценная информация, которую стоит выделить отдельно?
К примеру, компания-ритейлер фокусировала свои маркетинговые усилия на сегменте «активная молодежь», но, занявшись прогнозированием вероятности отклика, с удивлением обнаружила, что их целевой сегмент совсем другой – «обеспеченные дамы 40+».
5.2 Разбор полетов (Review the process)
Стоит собраться за кружкой пива за столом, проанализировать ход проекта и сформулировать его сильные и слабые стороны. Для этого нужно пройтись по всем шагам:
- Можно ли было какие-то шаги сделать более эффективными?
Например, из-за неповоротливости IT-отдела заказчика целый месяц ушел на согласование доступов. Не гуд! - Какие были допущены ошибки и как их избежать в будущем?
На этапе планирования недооценили сложность выгрузки данных из источников и в результате не уложились в сроки. - Были ли не сработавшие гипотезы? Если да, стоит ли их повторять?
Аналитик: «А давайте теперь попробуем сверточную нейронную сеть… Всё становится лучше с нейросетями!» - Были ли неожиданности при реализации шагов? Как их предусмотреть в будущем?
Заказчик: «Ok. А мы думали, что обучающая выборка для разработки модели не нужна…»
5.3 Принятие решения (Determining the next steps)
Далее нужно либо внедрять модель, если она устраивает заказчика, либо, если виден потенциал для улучшения, попытаться еще ее улучшить.
Если на данном этапе у нас несколько удовлетворяющих моделей, то отбираем те, которые будем дальше внедрять.
6. Внедрение (Deployment)
Источник
Перед началом проекта с заказчиком всегда оговаривается способ поставки модели. В одном случае это может быть просто проскоренная база клиентов, в другом – SQL-формула, в третьем – полностью проработанное аналитическое решение, интегрированное в информационную систему.
На данном шаге осуществляется внедрение модели (если проект предполагает этап внедрения). Причем под внедрением может пониматься как физическое добавление функционала, так и инициирование изменений в бизнес-процессах компании.
6.1 Планирование развертывания (Planning Deployment)
Наконец собрали в кучу все полученные результаты. Что теперь?
- Важно зафиксировать, что именно и в каком виде мы будем внедрять, а также подготовить технический план внедрения (пароли, явки и прочее)
- Продумать, как с внедряемой моделью будут работать пользователи
Например, на экране сотрудника колл-центра показываем склонность клиента к подключению дополнительных услуг. - Определить принцип мониторинга решения. Если нужно, подготовиться к опытно-промышленной эксплуатации.
Например, договариваемся об использовании модели в течение года и тюнинге модели раз в 3 месяца.
6.2 Настройка мониторинга модели (Planning Monitoring)
Очень часто в проект включаются работы по поддержке решения. Вот что оговаривается.
- Какие показатели качества модели будут отслеживаться?
В своих банковских проектах мы часто используем популярный в банках показатель population stability index PSI. - Как понимаем, что модель устарела?
Например, если PSI больше 0.15, либо просто договариваемся о регулярном пересчете раз в 3 месяца. - Если модель устарела, достаточно ли будет ее переобучить или нужно организовывать новый проект?
При существенных изменениях в бизнес-процессах тюнинга модели недостаточно, нужен полный цикл переобучения – с добавлением новых атрибутов, отбором предикторов и.т.д.
6.3 Отчет по результатам моделирования (Final Report)
По окончании проекта, как правило, пишется отчет о результатах моделирования, в который добавляются результаты по каждому шагу, начиная от первичного анализа данных и заканчивая внедрением модели. В этот отчет также можно включить рекомендации по дальнейшему развитию модели.
Написанный отчет презентуется заказчику и всем заинтересованным лицам. В отсутствие ТЗ этот отчет является главным документом проекта. Также важно поговорить с задействованными в проекте сотрудниками (как со стороны заказчика, так и со стороны исполнителя) и собрать их мнение о проекте.
Как насчет практики?
Важно понимать, что методология не является универсальным рецептом. Это просто попытка формально описать последовательность действий, которую в той или иной степени выполняет любой аналитик, занимающийся анализом данных.
У нас в CleverDATA следование методологии на дата-майнинговых проектах не является жестким требованием, но, как правило, при составлении плана проекта наша детализация довольно точно укладывается в данную последовательность шагов.
Методология применима к совершенно разным задачам. Мы следовали ей в ряде маркетинговых проектов, в том числе, когда предсказывали вероятность отклика клиента торговой сети на рекламное предложение, делали модель оценки кредитоспособности заемщика для коммерческого банка и разрабатывали сервис рекомендаций товаров для интернет-магазина.
Сто и один отчет

Источник
По задумке авторов, после каждого шага должен писаться некий отчет. Однако на практике это не очень реалистично. Как и у всех, у нас бывают проекты, когда заказчик ставит очень сжатые сроки и необходимо быстро получить результат. Понятно, что в таких условиях нет смысла тратить время на детальное документирование каждого шага. Всю промежуточную информацию, если она нужна, мы в таких случаях фиксируем карандашом «на салфетке». Это позволяет максимально быстро заняться реализацией модели и уложиться в сроки.
На практике многие вещи делаются куда менее формально, чем требует методология. Мы, например, обычно не тратим время на выбор и согласование используемых моделей, а тестируем сразу все доступные алгоритмы (конечно, если ресурсы позволяют). Аналогично поступаем с атрибутами – готовим сразу несколько вариантов каждого атрибута, чтобы можно было опробовать максимальное количество вариантов. Нерелевантные атрибуты при таком подходе отсеиваются автоматически с помощью алгоритмов feature selection – автоматическом определении предсказательной способности атрибутов.
Полагаю, формализм методологии объясняется тем, что она писалась еще в 90-е, когда не было такого количества вычислительнных мощностей и важно было грамотно спланировать каждое действие. Сейчас доступность и дешевизна «железа» упрощает многие вещи.
О важности планирования
Всегда есть соблазн «пробежать» первые два этапа и перейти сразу к реализации. Практика показывает, что это не всегда оправдано.
На этапе постановки бизнес-целей (business understanding) важно как можно детальнее проговорить с заказчиком предлагаемое решение и убедиться, что ваши с ним ожидания совпадают. Бывает так, что бизнес рассчитывает получить в результате некоего «волшебного» робота, который сходу решит все его проблемы и мгновенно увеличит вдвое выручку. Поэтому, чтобы ни у кого не было разочарований по итогам проекта, всегда стоит четко проговаривать, какой именно результат получит заказчик и что он даст бизнесу.
Кроме того, не всегда заказчик может дать правильную оценку точности модели. В качестве примера: предположим, мы анализируем отклик на рекламную кампанию в интернете. Знаем, что по ссылке переходят примерно 10% клиентов. Разработанная нами модель отбирает 1000 наиболее склонных к отклику клиентов, и мы видим, что среди них переходит по ссылке каждый четвертый – получаем точность (precision) в 25%. Модель показывает неплохой результат (в 2.5 раза лучше «случайной» модели), но для заказчика точность в 25% слишком мала (он ждет цифр в районе 80-90%). И наоборот, совершенно бессмысленная модель, которая относит всех в один класс, покажет точность (accuracy), равную 90%, и формально будет удовлетворять заявленному критерию успеха. Т.е. важно вместе с заказчиком выбирать правильную меру качества модели и правильно ее интерпретировать.
Этап исследования (data understanding) важен тем, что позволяет и нам, и заказчику лучше понять его данные. У нас были примеры, когда после презентации результатов шага мы параллельно с основным проектом договаривались о новых, так как заказчик видел потенциал в найденных на этом этапе закономерностях.
В качестве другого примера приведу один из наших проектов, когда мы положились на диалог с заказчиком, ограничились поверхностным изучением данных и на этапе моделирования обнаружили, что часть данных оказалась неприменима из-за многочисленных пропусков. Поэтому всегда стоит заранее изучить данные, с которыми предстоит работать.
Наконец, хочу отметить, что, несмотря на свою полноту, методология все-таки достаточно общая. Она ничего не говорит о выборе конкретных алгоритмов и не дает готовых решений. Возможно, это и хорошо, так как всегда остается пространство для творческого поиска, ведь, повторюсь, сегодня профессия data scientist по-прежнему остается одной из наиболее творческих в IT-сфере.
Просмотры: 509
Описание методологии анализа данных и разделения на этапы
Настоящий документ опирается на рекомендации, представленные в международной методологии по исследованию данных Cross-Industry Standard Process for Data Mining (CRISP-DM).
Этап №1
Этап №2
Этап №3
Этап №4
Этап №5
На диаграмме выделены стадии:
- “Определение целей и задач” проекта (Business Understanding) | Понимание целей и задач бизнеса или государства, именуемого в дальнейшем “Заказчик” исследований. Результатом данной стадии является выбор и согласование метрики качества с Заказчиком. Выбор метрик качества должен учитывать балансировку классов, возможность проведения A/B-тестирования и т.п.
- “Исследование данных” (Data Understanding) | Стадия “Исследования данных” включает в себя получение информации о формате и объеме доступных наборов данных (что может выявить дополнительные требования к инфраструктуре анализа данных), особенности инструментов для выгрузки данных, доступная разметка и ее формат. Доступные данные и инфраструктура для их анализа могут сильно повлиять на выбранные метрики качества стадии “Определения целей и задач” (Business Understanding). Именно поэтому на диаграмме выделены стрелки для перехода между этими стадиями в обе стороны.
- “Подготовка данных” (Data Preparation) | Для подготовки и обучения моделей данные должны быть представлены в специализированном формате (наиболее часто – в табличном виде, см. csv формат). В дополнение к этому, по опыту взаимодействия с Заказчиками по проектам анализа данных, часто необходима очистка данных: работа с опечатками, неправильным вводом данных, обновление разметки (исправление ошибок или самого формата разметки для удобства обработки на компьютере).
- “Моделирование” (Modeling) | Результатом стадии “Моделирование” является разработка решения, основанного на алгоритмах и структурах данных. Исполнитель производит разработку решения на очищенных наборах данных и оптимизирует метрики качества, зафиксированные на предыдущих стадиях. Разные модели могут требовать специализированной предобработки для обучения, поэтому на диаграмме представлена стрелка от стадии “Моделирования” в стадию “Подготовка данных”.
- “Оценка решения” (Evaluation) | Проведение оценки обобщающей способности выбранной модели на новых данных, а также пилотные запуски в формате A/B-тестирования производятся на стадии “Оценка решения”.
- “Опытная эксплуатация” (Trial operation) | Стадия “Опытная эксплуатация” проводится для апробации планируемого к внедрению решения, в рамках которого проверяется нагрузочная способность, интеграционные возможности и эргономика решения, основной целью которой является снижение рисков, связанных с внедрением решения.
- “Внедрение” (Deployment) | Стадия “Внедрение” используется для введения в продуктив выбранных моделей, которые решают поставленные задачи Заказчика исследований и приносят большую ценность, чем требуют затрат на использование, развитие и поддержку модели / решения.
Внутренними стрелками на диаграмме выделены наиболее важные и частые зависимости и переходы между стадиями. Внешний цикл на диаграмме обозначает итеративную процедуру ведения проекта. На каждом новом цикле происходит уточнение постановки задачи за счет более глубокого понимания данных и результатов экспериментов (моделирования, пилотного тестирования и опыта внедрения).
Методические рекомендации по выделению этапов работы
Для работы над проектами по анализу данных, рекомендуется на начальной фазе проекта выделить следующие этапы:
- Постановка задачи и формирование представлений о доступных данных;
- формулировка задачи и критериев успешности решения;
- спецификация данных и их источников;
- оценка планируемых социально-экономического эффекта от внедрения и сроков окупаемости.
Подготовка данных и моделирование: макетирование и прототипирование решения, не рассматривая само решение в отрыве от данных, над которыми оно должно работать.
Оценка модели и принятие решения о внедрении: включая оценку ресурсов на получение более точной модели решения в случае повторного прохождения первого и второго этапов.
При этом, помнить, что корректно поставленная задача — это модель предметной области, исходные данные, над которыми она действует, цель постановки и критерии её решения. Цель постановки и критерии решения здесь — ключевой фокус, та как всё остальное в постановке подчиняется им.
Макетирование и прототипирование решения, которое происходит на этапе № 2 после того, как задача сформулирована, и проведена первичная оценка эффекта от внедрения, позволяет предложить несколько решений, которые могут рассматриваться, как по отдельности, так и совместно в итоговом решении. Переход на третий этап возможен, когда появилась уверенность в том, что предлагаемый макет удовлетворит критериям успешности решения.
Здесь особое место занимает вопрос существующего потребительского опыта: слишком новаторские решения могут быть весьма результативны, но могут требовать значительного времени для внедрения на местах. Поэтому, формулируя критерии результативности при оценке решений на Этапе № 3, необходимо принимать во внимание этот фактор, чтобы сохранить степень актуальности решаемой задачи.
Важным аспектом оценки является проверка моделей на технологические ограничения, так как у любой технологии, какой бы передовой она ни была, существуют рамки применения. Для технологий искусственного интеллекта это:
Необходимость обучения — как бы оно ни было устроено, речь всегда идёт о выборках для обучения и тестирования моделей.
Проблема “чёрного ящика” — если речь идёт о технологиях глубокого машинного обучения, основанных на нейронных сетях, то выявить чёткую причину того или иного решения, а также факторы, на них влияющие, в настоящее время, крайне затруднительно или невозможно.
События, с которыми нейронные сети ранее не встречались, будут обработаны случайным образом.
Введение новых факторов в модель влечёт за собой переобучение. Это может занимать время.
Если оценка возможности внедрения после Этапа № 3 будет положительной, то следующим шагом будет:
Планирование и согласование опытной эксплуатации разработанного решения, цель которого не только апробация разработанной модели, но и проверка действий участников внедрения в новых условиях. Такой подход позволяет получать дополнительные гарантии успешности внедрения.
Если учёт человеческого фактора приводит к тому, что оценка решения близка к удовлетворительной или хуже, следует рассмотреть возможность дополнительной проработки постановки задачи: снова зайти на Этап № 1 и сформулировать комплект частных технических заданий, относительно которых будет повторно выполнен Этап № 2.
Оценка возможности внедрения должна включать в себя учёт вычислительной мощности, доступной заказчику, так как это может существенным образом повлиять на характер решения, а это неизбежно приведёт к уточнению постановки задачи из-за изменения эксплуатационных условий решения.
Такой подход позволяет выйти на Этап № 4 с хорошо поставленными границами проектов (подпроектов) и утвердить образ технического решения, так как в рамках этапа внедрения решения основной фокус будет смещён в сторону автоматики и развития потребительского опыта людей (UX). Возникающие “болезни” решения будут не только оттягивать ресурс, но и создавать барьеры для внедрения изменений в создание людей. Поэтому в спектре компетенций четвёртого этапа присутствуют консультанты, специалисты HR и эксперты в UX.
В этой связи, если, например, решение будет охватывать большое количество людей, 4-ый этап целесообразно продублировать: в первую очередь выполнить ввод системы в опытную эксплуатацию и, при успехе, внедрить решение в промышленную: Этапы № 4 и № 5 соответственно. Для оценки качества перехода из опытной в промышленную эксплуатацию рекомендуем пройти сценарий этапа № 3 повторно, рассматривая полученный опыт, как моделирование (Этап 2). Такой подход позволит взглянуть на результат в комплексе.
Именно поэтому необходимо вести журнал проекта на всех этапах его выполнения, чтобы получить возможность объективной оценки результатов и трудозатрат, а также осмысленного выбора шагов и их последовательности, когда субъектами изменений станут большее количество человек.
На каждом из этапов могут появиться условия или возникнуть события, благодаря которым сразу или позже проявят себя новые возможности. Их следует фиксировать в отдельном журнале (соответствующие практики существуют и в ГОСТах, и в стандартах ISO, и в CRISP-DM), так как они могут стать точками роста. Это особенно важно в проектах, основанных на аналитике данных, где важную роль играют политики и практики повторного использования, например, при решении других, в том числе, ещё не поставленных задач, смысл которых проявит себя позже. Непрерывно и целенаправленно увеличивая качество процессов извлечения и преобразования информации, можно получать и закреплять эффекты во вновь создаваемых аналитических продуктах.
Ярким примером здесь является стратегия развития цифровых сервисов Яндекс от карты автомобильных дорог к уже привычной навигации и цифровому сервису срочной аренды автотранспорта или связи карты с контентом рекламного характера. Анализ карты точек роста в долгосрочной перспективе может приводить к формированию фундаментальных конкурентных преимуществ.
Текущая страница: 4 (всего у книги 12 страниц) [доступный отрывок для чтения: 3 страниц]
Процесс CRISP-DM
В научной среде регулярно выдвигаются новые идеи о том, каким способом лучше всего взбираться на вершину пирамиды науки о данных. Наиболее часто используется межотраслевой стандартный процесс исследования данных CRISP-DM. Этот процесс в течение целого ряда лет занимает первые места всевозможных отраслевых опросов. Одно из преимуществ CRISP-DM и причина, по которой он так широко используется, заключается в том, что процесс спроектирован как независимый от программного обеспечения, поставщика или метода анализа данных.
CRISP-DM разрабатывался консорциумом организаций, в который входили ведущие поставщики данных, конечные пользователи, консалтинговые компании и исследователи. Первоначальный проект CRISP-DM был частично спонсирован Европейской комиссией в рамках программы ESPRIT и представлен на семинаре в 1999 г. С тех пор было предпринято несколько попыток обновить процесс, но оригинальная версия все еще остается наиболее востребованной. В течение многих лет существовал отдельный сайт CRISP-DM, но сейчас он закрыт, и в большинстве случаев вы будете перенаправлены на сайт SPSS компании IBM, которая участвовала в проекте с самого начала. Консорциум участников опубликовал детальную (76 страниц), но вполне понятную пошаговую инструкцию для процесса, которая находится в свободном доступе в интернете[35]35
Chapman, Pete, Julian Clinton, Randy Kerber, Thomas Khabaza, Thomas Reinartz, Colin Shearer, and Rudiger Wirth. 1999. “CRISP-DM 1.0: Step-by-Step Data Mining Guide.” ftp://ftp.software.ibm.com/software/analytics/spss/support/Modeler/Documentation/14/UserManual/CRISP-DM.pdf.
[Закрыть]
. Далее мы кратко изложим основную структуру и задачи процесса.
Жизненный цикл CRISP-DM состоит из шести этапов – понимание бизнес-целей, начальное изучение данных, подготовка данных, моделирование, оценка и внедрение, – показанных на рис. 4. Данные являются центром всех операций, как это видно из диаграммы CRISP-DM. Стрелки между этапами указывают типичное направление процесса. Сам процесс является частично структурированным, т. е. специалист по данным не всегда проходит все шесть этапов линейно. В зависимости от результата конкретного этапа может потребоваться вернуться к одному из предыдущих, повторить текущий или перейти к следующему.

На первых двух этапах – понимания бизнес-целей и начального изучения данных – специалист пытается сформулировать цели проекта с точки зрения бизнеса и знакомится с данными, которые тот имеет в своем распоряжении. На ранних стадиях проекта придется часто переключаться между фокусировкой на бизнесе и изучением доступных данных. Это связано с тем, что специалист по данным должен идентифицировать бизнес-проблему, а затем понять, доступны ли соответствующие данные для поиска ее решения. Если они доступны, то проект может продолжаться, в противном случае специалисту придется искать альтернативную проблему. В течение этого периода специалист по данным плотно работает с коллегами из бизнес-отделов организации (продаж, маркетинга, операций), пытаясь вникнуть в их проблемы, а также с администраторами баз данных, чтобы изучить доступный материал.
Как только бизнес-проблема была четко сформулирована, а специалист убедился в том, что соответствующие данные доступны, происходит переход к очередному этапу CRISP-DM – подготовке данных. Целью этого этапа является создание набора данных, который можно использовать для анализа. Обычно это подразумевает интеграцию источников из нескольких баз данных. Когда в организации существует хранилище данных, эта интеграция значительно упрощается. После создания набора данных необходимо проверить и исправить их качество. Типичные проблемы качества включают выбросы и пропущенные значения. Проверка качества крайне важна, поскольку ошибки в данных могут серьезно повлиять на производительность алгоритмов анализа.
Следующим этапом CRISP-DM является моделирование. На этой стадии используются автоматические алгоритмы для выявления полезных закономерностей в данных и создаются модели, которые кодируют эти закономерности. Алгоритмы для выявления закономерностей также называются алгоритмами машинного обучения. На этапе моделирования специалист по данным обычно использует несколько алгоритмов машинного обучения для подготовки разных моделей в каждом наборе данных. Необходимость в нескольких моделях вызвана тем, что разные типы алгоритмов машинного обучения ищут разные типы закономерностей в данных, и на этапе моделирования специалист, как правило, не знает, какие именно закономерности нужно искать. Таким образом, имеет смысл поэкспериментировать с различными алгоритмами и посмотреть, какой из них работает лучше всего.
В большинстве проектов тестовые результаты испытания моделей позволят выявить проблемы с данными. Иногда эти ошибки обнаруживаются, когда специалист выясняет, что производительность модели ниже ожидаемой или, наоборот, она подозрительно хороша. Бывает, что, изучая структуру моделей, специалист по данным неожиданно выясняет ее зависимость от каких-либо атрибутов и возвращается к данным, чтобы проверить, правильно ли они кодированы. В результате некоторые этапы в проекте повторяются: за моделированием следует подготовка данных, затем снова моделирование, снова подготовка данных и т. д. Например, Дэн Стейнберг и его команда сообщили, что в ходе одного своего проекта они перестраивали набор данных 10 раз в течение шести недель, причем на пятой неделе этого процесса после ряда итераций по очистке данных и подготовке в них была обнаружена существенная ошибка[36]36
Steinberg, Dan. 2013. “How Much Time Needs to Be Spent Preparing Data for Analysis?” http://info.salford-systems.com/blog/bid/299181/How-Much-Time-Needs-to-be-SpentPreparing-Data-for-Analysis.
[Закрыть]
. Если бы она не была выявлена и исправлена, проект не стал бы успешным.
На двух последних этапах (при оценке и внедрении) вы сосредотачиваетесь на том, каким образом модели будут приспособлены к бизнесу и его процессам. Тесты, выполняемые на этапе моделирования, ориентированы исключительно на точность модели в наборе данных. Этап оценки включает оценку моделей в более широком контексте, определяемом потребностями бизнеса. Соответствует ли модель целям процесса? Адекватна ли она с точки зрения бизнеса? На этом этапе специалист по данным должен провести анализ для обеспечения качества проекта: не было ли что-то упущено, можно ли было сделать лучше и т. д. На основании общей оценки моделей принимается основное решение этого этапа – можно ли внедрять какую-то из них в бизнес или требуется еще одна итерация процесса CRISP-DM для создания моделей более адекватных. Если модели одобрены, проект переходит к финальной стадии процесса – внедрению. На этапе внедрения изучается то, каким образом можно развернуть выбранные модели в бизнес-среде, как интегрировать их в техническую инфраструктуру и бизнес-процессы организации. Лучшие из моделей – те, которые плавно вписываются в существующую практику. Такие модели ориентированы на конкретных пользователей, столкнувшихся с четко обозначенной проблемой, которую эта модель и призвана решить. Кроме того, на этапе внедрения создается план периодической проверки эффективности модели.
Внешняя окружность диаграммы CRISP-DM подчеркивает тот факт, что весь процесс имеет итеративный характер. При обсуждении проектов науки о данных об их итеративности часто забывают. После разработки и внедрения модель должна регулярно пересматриваться, чтобы удовлетворять задачам бизнеса и оставаться актуальной. Существует масса причин, по которым модель может устареть: изменяются потребности бизнеса, процессы, которые модель имитирует или поясняет (например, поведение клиентов, типы спама и т. д.), или потоки данных, используемые моделью (скажем, новый датчик дает несколько другие показатели, что снижает точность модели). Частота пересмотра зависит от того, как быстро развиваются экосистема бизнеса и данные, используемые моделью. Постоянный мониторинг необходим, чтобы определить наилучшее время для повторного запуска процесса. Это как раз то, что представляет собой внешний круг CRISP-DM. Например, в зависимости от данных, поставленной задачи и сферы деятельности вы можете проходить этот итеративный процесс еженедельно, ежемесячно, ежеквартально, ежегодно или даже ежедневно. На рис. 5 приведена сводная информация об этапах процесса и основных задачах, связанных с ними.
Неопытные специалисты по данным часто допускают ошибку: сосредотачивая усилия на этапе моделирования CRISP-DM, они чересчур поспешно проходят другие этапы. Их логика заключается в том, что наиболее важным результатом проекта должна стать модель, поэтому бо́льшую часть своего времени необходимо посвятить именно ее разработке. Однако маститые специалисты по данным тратят больше времени на то, чтобы задать проекту четкий вектор и обеспечить его правильными данными. Успех в науке о данных достигается ясностью бизнес-задач для специалиста, ведущего проект. Поэтому этап понимания бизнес-целей крайне важен. Что касается получения правильных данных для проекта, то опрос специалистов, проведенный в 2016 г., показал, что 79 % своего времени они уделяют именно подготовке данных[37]37
CrowdFlower. 2016. «Отчет о науке данных за 2016 год». http://visit.crowdflower.com/rs/416-ZBE142/images/CrowdFlower_DataScienceReport_2016.pdf.
[Закрыть]
. Тот же опрос выявил, что распределение времени между основными задачами в проектах выглядит следующим образом:
● сбор данных – 19 %;
● очистка и организация данных – 60 %;
● построение обучающих моделей – 3 %;
● анализ данных для выявления закономерностей – 9 %;
● уточнение алгоритмов – 4 %;
● другие задачи – 5 %.
Показатель 79 % для подготовки суммирует время, затраченное на сбор, очистку и организацию данных. Этот показатель – около 80 % времени проекта – присутствует в разных отраслевых опросах уже в течение ряда лет. Такой вывод может удивить, поскольку принято считать, что специалист по данным тратит свое время на создание сложных моделей, помогающих получить новые знания. Но простая истина состоит в том, что, как бы ни был хорош ваш анализ, он не найдет полезных закономерностей в неправильных данных.

Глава 3
Экосистема науки о данных
Набор технологий, используемых для обработки данных, варьируется в зависимости от организации. Чем больше организация и/или объем обрабатываемых данных, тем сложнее технологическая экосистема науки о данных. Обычно эта экосистема содержит инструменты и узлы от нескольких поставщиков программного обеспечения, которые обрабатывают данные в разных форматах. Существует ряд подходов, которые организация может использовать для разработки собственной экосистемы науки о данных. На одном конце этого ряда организация принимает решение инвестировать в готовую систему интегрированных инструментов. На другом – самостоятельно создавать экосистему путем интеграции инструментов и языков с открытым исходным кодом. Между этими двумя крайностями есть несколько поставщиков программного обеспечения, которые предоставляют решения, являющие собой смесь коммерческих продуктов и продуктов с открытым исходным кодом. Однако, хотя конкретный набор инструментов в каждой организации будет свой, наука о данных предусматривает общие компоненты для большинства архитектур.
Рис. 6 дает обзор типичной архитектуры данных. Эта архитектура предназначена не только для больших данных, но и для данных любого размера. Диаграмма состоит из трех основных частей: уровня источников данных, на котором генерируются все данные в организации; уровня хранения данных, на котором данные хранятся и обрабатываются, и уровня приложений, на котором данные передаются потребителям этих данных и информации, а также различным приложениям.

У каждой организации есть приложения, которые генерируют и собирают данные о клиентах, транзакциях и обо всем, что связано с работой организации (операционные данные). Это источники и приложения следующих типов: управление клиентами, заказы, производство, доставка, выставление счетов, банкинг, финансы, управление взаимодействием с клиентами (CRM), кол-центр, ERP и т. д. Приложения такого типа обычно называют системами обработки транзакций в реальном времени, или OLTP. Во многих проектах науки о данных именно эти приложения используются как источник входного набора данных для алгоритмов машинного обучения. Со временем объем данных, собираемых различными приложениями по всей организации, становится все больше и начинает включать данные, которые ранее были проигнорированы, недоступны или не были собраны по иным причинам. Эти новые источники, как правило, относятся уже к большим данным, поскольку их объем значительно выше, чем объем данных основных операционных приложений организации. Распространенные источники – это сетевой трафик, регистрационные данные различных приложений, данные датчиков, веб-журналов, социальных сетей, веб-сайтов и т. д. В традиционных источниках данные обычно хранятся в базе. Новые источники больших данных часто не предназначены для длительного их хранения, как в случае с потоковыми данными, поэтому форматы и структуры хранения будут варьироваться от приложения к приложению.
По мере увеличения количества источников возрастает проблема использования данных в аналитике и обмена ими между удаленными частями организации. Из истории (см. главу 1) нам известно, что хранение данных стало ключевым компонентом аналитики. В хранилище данные, поступающие со всей организации, интегрируются и становятся доступными для приложений (OLAP) и дальнейшего анализа.
Слой хранения данных, представленный на рис. 6, предназначен для обмена данными и их анализа. При этом он разделен на две части. Первая охватывает программное обеспечение для обмена данными, используемое большинством организаций. Наиболее популярным типом традиционного ПО для интеграции и хранения данных остаются реляционные базы данных (RDBMS). Это ПО часто служит основой для систем бизнес-аналитики (BI) в организациях. BI-системы призваны облегчить процесс принятия решений для бизнеса. Они предоставляют функции агрегирования, интеграции, отчетности и анализа. В основе BI-систем лежат базы данных, которые содержат интегрированные, очищенные, стандартизированные и структурированные данные, поступающие из различных источников. В зависимости от уровня зрелости архитектура BI-систем может состоять из очень разных компонентов – от базовой копии рабочего приложения и оперативного склада данных (ODS) до массивно-параллельных (MPP) решений баз данных BI и хранилищ данных. Аналитику, сгенерированную BI-системой, можно использовать в качестве входных данных для ряда потребителей на уровне приложений (рис. 6).
Вторая часть слоя хранения данных занимается управлением большими данными организации. Архитектура для их хранения и анализа включает платформу с открытым исходным кодом Hadoop, разработанную Apache Software Foundation для обработки больших данных. Эта платформа осуществляет распределенное хранение и обработку данных прямо в кластерах стандартных серверов. Для ускорения обработки запросов в наборах больших данных используется модель программирования MapReduce, которая реализует стратегию разделения – использования – объединения: a) большой набор данных разбивается на фрагменты, и каждый блок сохраняется в отдельном узле кластера; б) затем ко всем фрагментам применяется параллельный запрос; в) результат запроса вычисляется путем объединения результатов, сгенерированных для разных фрагментов. Кроме того, в последние годы платформа Hadoop стала использоваться для расширения корпоративных хранилищ данных. Не так давно хранилища вмещали данные за три года, но теперь это число достигло 10 лет и продолжает расти. Поскольку объемы данных все увеличиваются, требования к хранилищу и обработке баз и сервера также растут. Это может повлечь за собой значительные затраты. В качестве альтернативы некоторые устаревшие данные перемещают из хранилища в кластер Hadoop. В хранилище, таким образом, остаются только последние данные, скажем за три года, которые часто используются и должны быть доступны для быстрого анализа и представления, а старые или редко используемые данные хранятся в Hadoop. Большинство баз данных уровня предприятия имеют соответствующие функции для прямого подключения хранилищ к Hadoop, позволяя специалисту запрашивать на языке SQL любые данные, как если бы они все находились в одной среде. Такой запрос открывает доступ и к хранилищу данных, и к Hadoop. Обработка запроса автоматически разделяет его на две отдельные части, каждая из которых выполняется независимо, а результаты объединяются и интегрируются, прежде чем будут представлены специалисту по данным.
Анализ данных затрагивает и ту и другую части слоя хранения, представленного на рис. 6. Он может выполняться как на основе данных, взятых непосредственно из BI-систем или Hadoop, так и на результатах их анализа, повторенного множество раз. Часто данные из традиционных источников бывают заметно чище и плотнее полученных из источников больших данных. Тем не менее гигантский объем и режим реального времени, свойственные большим данным, означают, что усилия, приложенные для подготовки и анализа их источников, могут окупиться с точки зрения важной информации, недоступной из традиционных источников. Разнообразные методы анализа данных для тех или иных областей исследования (включая обработку естественного языка, компьютерное зрение и машинное обучение), используются для преобразования неструктурированных больших данных низкой плотности в ценные данные высокой плотности. Такие данные уже могут быть интегрированы с другими ценными данными из традиционных источников для дальнейшего анализа. Описанная структура, проиллюстрированная на рис. 3.1, представляет собой типичную архитектуру экосистемы науки о данных. Она подойдет для большинства организаций независимо от размера, однако по мере масштабирования организации увеличивается и сложность экосистемы науки о данных. Например, для небольших организаций может и не требоваться компонент Hadoop, но для крупных он становится незаменим.
Перемещение алгоритмов в данные
Традиционный подход к анализу данных включает их извлечение из различных баз, интеграцию, очистку, размещение, построение прогнозной модели, а затем загрузку окончательных результатов анализа в базу данных, чтобы их можно было использовать как часть рабочего процесса, отображать в виде отчетности и т. д. На рис. 7 показано, что большая часть процесса обработки данных, включающего их подготовку и анализ, протекает на отдельном сервере, вне баз и хранилища. При этом значительное количество времени может быть затрачено только на перемещение данных из базы и загрузку в нее результатов.

Для примера: в эксперименте по построению модели линейной регрессии около 70–80 % времени ушло на извлечение и подготовку данных. На создание моделей было потрачено лишь оставшееся время. В процессе скоринга данных примерно 90 % времени было затрачено на их извлечение и сохранение готового набора обратно в базу. Только 10 % времени пришлось на сам скоринг. Эти результаты основаны на наборах данных от 50 000 до 1,5 млн записей. Большинство поставщиков корпоративных баз данных уже осознали, сколько времени экономится, если отказаться от их перемещения, и отреагировали на это включением функции анализа и алгоритмов машинного обучения непосредственно в механизмы базы данных. В последующих разделах мы рассмотрим, каким образом алгоритмы машинного обучения были интегрированы в современные базы данных, как хранятся большие данные в Hadoop и как комбинации этих двух подходов позволяют легко работать со всеми данными в организации, используя SQL как общий язык доступа, анализа, машинного обучения и прогнозной аналитики в режиме реального времени.

Традиционные и современные базы данных
Поставщики баз данных постоянно инвестируют в развитие масштабируемости, производительности, безопасности и функциональности своих продуктов. Современные базы данных намного более продвинуты, чем традиционные реляционные базы данных. Они могут хранить и запрашивать данные в различных форматах. Кроме реляционных форматов, можно определять типы объектов, хранить документы, хранить и запрашивать объекты JSON, геоданные и т. д. Помимо этого, большинство современных баз имеют массу статистических функций, а некоторые поставляются с основными статистическими приложениями. Например, база данных Oracle поставляется с более чем 300 различными встроенными статистическими функциями. Они охватывают бо́льшую часть статистического анализа, необходимого для проектов науки о данных, и включают практически все статистические функции, доступные в других инструментах и языках, таких как R. Изучение функционала баз данных организации может позволить аналитику действовать более эффективно и масштабируемо, используя язык SQL. Кроме того, большинство поставщиков баз данных (включая Oracle, Microsoft, IBM и EnterpriseDB) интегрировали в свои базы разнообразные алгоритмы машинного обучения, которые можно запускать на SQL. Использование алгоритмов машинного обучения, встроенных в ядро базы и доступных через SQL, известно как машинное обучение в базе данных. Такое машинное обучение способствует более быстрой разработке моделей и скорейшей интеграции результатов анализа с приложениями и панелями мониторинга. Кратко идея размещения алгоритмов машинного обучения непосредственно в базах данных может быть выражена следующим образом: «Переместить алгоритмы в данные, вместо того чтобы перемещать данные в алгоритмы».
Использование алгоритмов машинного обучения в базе данных имеет следующие преимущества:
● Отсутствие движения данных. Некоторые продукты для обработки данных требуют их экспорта из базы и конвертации в особый формат, чтобы поместить в алгоритм машинного обучения. Благодаря машинному обучению в базе данных перемещение или преобразование данных не требуется. Это упрощает весь процесс, делает его менее трудоемким и подверженным ошибкам.
● Скорость. Для аналитических операций, выполняемых в базе данных без их перемещения, можно использовать вычислительные возможности сервера самой базы, обеспечивая увеличение производительности до 100 раз по сравнению с традиционным подходом. Большинство серверов баз данных имеют высокие спецификации, множество процессоров и эффективное управление памятью для обработки наборов данных, содержащих более миллиарда записей.
● Высокая безопасность. База данных обеспечивает контролируемый и поддающийся проверке доступ к данным, увеличивая производительность специалиста и поддерживая нормы безопасности. Кроме того, машинное обучение в базе данных позволяет избежать рисков, присущих процессу извлечения и загрузки данных на альтернативные серверы. К тому же традиционный процесс обработки данных приводит к созданию множества копий (а иногда и разных версий) наборов данных в разных хранилищах организации.
● Масштабируемость. База данных может легко масштабировать аналитику по мере увеличения объема данных благодаря алгоритмам машинного обучения. Программное обеспечение баз предназначено для эффективного управления большими объемами данных с использованием нескольких серверных процессоров и памяти, что позволяет выполнять алгоритмы машинного обучения параллельно другим задачам. Базы данных также очень эффективны при обработке больших наборов данных, которые не помещаются в память. Сорокалетняя история развития баз гарантирует, что наборы данных будут обработаны быстро.
● Режим реального времени. Модели, разработанные с использованием алгоритмов машинного обучения в базе данных, могут быть немедленно развернуты и использованы в средах реального времени. Это позволяет интегрировать модели в привычные приложения и предоставлять прогнозы конечным пользователям и клиентам.
● Развертывание в среде эксплуатации. SQL – это язык базы данных, который может быть использован для доступа к алгоритмам и моделям машинного обучения в базах. Модели, разработанные с использованием автономного ПО для машинного обучения, возможно, придется перекодировать на другие языки программирования, прежде чем они смогут быть развернуты в корпоративных приложениях. Но это не относится к машинному обучению в базе данных. SQL можно использовать и вызывать любым языком программирования и инструментом науки о данных. Это значительно упрощает задачу включения модели из базы данных в производственные приложения.
Многие организации используют преимущества машинного обучения в базе данных. Среди них встречаются как небольшие компании, так и крупные. Вот примеры организаций, использующих эту технологию:
● Fiserv – американский поставщик финансовых услуг, который занимается выявлением и анализом мошенничества. Он перешел от работы с несколькими поставщиками технологий хранения данных и машинного обучения к использованию машинного обучения в своей базе данных. В частности, эта технология позволяет сократить время создания/обновления и развертывания модели обнаружения мошенничества с почти недели до нескольких часов.
● Компания 84.51° (формально Dunnhumby, USA) использовала множество различных аналитических решений при создании моделей для своих клиентов. Обычно каждый месяц более 318 часов уходило на перемещение данных из базы на сервера машинного обучения и обратно. При этом на создание моделей тратилось еще как минимум 67 часов. Компания внедрила алгоритмы машинного обучения непосредственно в базу данных. Как только данные перестали покидать базу, экономия времени сразу составила более 318 часов. Поскольку база данных использовалась в качестве вычислительного инструмента, специалисты смогли масштабировать аналитику и время создания или обновления моделей машинного обучения сократилось с 67+ часов до 1 часа. Это дало экономию 16 дней. Теперь они могут получать результаты значительно быстрее и начинать взаимодействие с клиентами намного раньше, вскоре после совершения ими покупки.
● Wargaming – создатели World of Tanks и многих других игр – использует машинное обучение в базе данных, чтобы моделировать и прогнозировать взаимодействие с более чем 120 млн своих клиентов.
Данные в мире Hadoop
Хотя современная база данных невероятно эффективна для обработки транзакций, в эпоху больших данных для управления разнообразными формами данных и их долгосрочного хранения требуется новая инфраструктура. Современная база данных может справляться с объемами до нескольких петабайт, но при таком масштабе традиционные решения для баз могут стать чрезмерно дорогими. Этот вопрос стоимости обычно упирается в вертикальное масштабирование. В традиционной парадигме чем больше данных должна хранить и обрабатывать организация в течение необходимого срока, тем больший ей требуется сервер, а это увеличивает стоимость его конфигурации и лицензирования баз данных. Традиционная технология позволяет запрашивать и принимать миллиард записей ежедневно, но такой масштаб обработки обойдется в несколько миллионов долларов.
Hadoop – это платформа с открытым исходным кодом, которая была разработана и выпущена Apache Software Foundation. Она хорошо зарекомендовала себя для эффективного приема и хранения больших объемов данных и обходится дешевле, чем традиционный подход. Кроме того, на рынке появился широкий ассортимент продуктов для обработки и анализа данных на платформе Hadoop. Приведенное выше высказывание, касающееся современных баз данных – «переместить алгоритмы в данные, вместо того чтобы перемещать данные в алгоритмы», – также применимо и к Hadoop.
В Hadoop данные делятся на разделы, которые распределяются по узлам кластера. В процессе работы с Hadoop различные аналитические инструменты обрабатывают данные в каждом из кластеров (часть этих данных может постоянно находиться в оперативной памяти), что обеспечивает быструю обработку данных, поскольку несколько кластеров анализируются одновременно. Ни извлечение данных, ни ETL-процесс не требуются. Данные анализируются там, где они хранятся. Существуют и другие примеры аналогичного подхода, скажем решения от Google и Amazon, где аналитическое программное обеспечение, такое как Spark, разворачивается на распределенных вычислительных архитектурах, позволяя анализировать данные там, где они находятся.
В мире больших данных специалист может запрашивать их массивные наборы с использованием аналитических языков, таких как Spark, Flink, Storm, и широкого спектра инструментов, а также постоянно растущего числа бесплатных и коммерческих продуктов. Эти продукты представляют собой инструменты высокоуровневой аналитики или панели мониторинга, которые упрощают работу специалиста с данными и аналитикой, что позволяет ему сконцентрироваться на анализе данных. Однако современному специалисту по данным приходится анализировать их в двух разных местах: в современных базах данных и в хранилищах больших данных на Hadoop. В следующей части мы рассмотрим, как решается эта проблема.
Мир гибридных баз данных
Если у организации нет данных такого размера и масштаба, которым требуется Hadoop, то для управления данными ей будет достаточно традиционной базы данных. Однако есть мнение, что инструменты хранения и обработки данных, доступные в мире Hadoop, в итоге вытеснят традиционные базы данных. Такое сложно себе представить, и потому в последнее время обсуждается более сбалансированный подход к управлению данными в так называемом мире гибридных баз, где традиционные базы данных сосуществуют с Hadoop.

В мире гибридных баз все данные связаны между собой и работают вместе, что позволяет эффективно обмениваться ими, обрабатывать и анализировать их. На рис. 8 показано традиционное хранилище данных, но при этом большая часть данных находится не в базе или хранилище, а перемещена в Hadoop. Между базой данных и Hadoop создается соединение, которое позволяет специалисту запрашивать данные, как если бы они находились в одном месте. Ему не потребуется запрашивать отдельно данные из базы и из Hadoop. Гибридная база автоматически определит, какие части запроса необходимо выполнить в каждом из местоположений, затем объединит результаты и представит их специалисту. Точно так же по мере роста хранилища часть данных устаревает, и гибридное решение автоматически перемещает редко используемые данные в среду Hadoop, а те, что становятся востребованными, наоборот, возвращает обратно. Гибридная база данных сама определяет местоположение данных на основе частоты запросов и типа проводимого анализа.
Одним из преимуществ гибридных решений является то, что специалист по-прежнему запрашивает данные на SQL. Ему не нужно изучать другой язык запросов или применять особые инструменты. Сегодняшние тенденции позволяют предположить, что в ближайшем будущем основные поставщики баз данных, облачных хранилищ и программного обеспечения для интеграции данных будут предлагать именно гибридные решения.