Логическая
модель РБД строится на 3-х уровнях (слоях)
абстракции данных: представления
информации, обработки (бизнес-логики)
и хранения. Слои образуют строгую
иерархию: слой бизнес — логики
взаимодействует со слоями хранения и
представления. Физически, слои могут
входить в состав одного программного
модуля, или же распределяться на
нескольких параллельных процессах в
одном или нескольких узлах сети. Каждый
слой обрабатывается соответственно
функциями стандартного интерактивного
приложения. На верхнем уровне
абстрагирования взаимодействия клиента
и сервера достаточно четко можно выделить
следующие компоненты:
-
слой представления
информации; функции ввода и
отображения данных или презентационная
логика (Presentation
Layer— PL);
— Обеспечивает интерфейс с пользователем.
Как правило, получение информации от
пользователя происходит посредством
различных форм. А выдача результатов
запросов — посредством отчетов. -
слой
бизнес-логики; прикладные
функции, характерные для данной
предметной области или бизнес-логика
(Business Layer—
BL); — Связующий,
именно он определяет функциональность
и работоспособность системы в целом.
Блоки программного кода распределены
по сети и могут использоваться многократно
(CORBA, DCOM) для создания сложных распределенных
приложений. -
слой
хранения данных;
фундаментальные функции хранения и
управления информационными ресурсами
(базами данных, файловыми системами и
т.д.) или логика доступа к ресурсам
(Accesss
Layer
– AL)
— Обеспечивает
физическое хранение, добавление,
модификацию и выборку данных. На данный
слой также возлагается проверка
целостности и непротиворечивости
данных, а также реализацию разделенных
транзакций. -
служебные
функции,
играющие роль связок между функциями
первых трех групп.
В
соответствии с этим в любом приложении
выделяются следующие логические
компоненты:
-
компонент
представления, реализующий функции
первой группы; -
прикладной
компонент, поддерживающий функции
второй группы; -
компонент
доступа к информационным ресурсам,
поддерживающий функции третьей группы; -
протокол
взаимодействия.
Различия
в реализациях технологии определяются
четырьмя факторами.
-
в
какие виды программного обеспечения
интегрирован каждый из этих компонентов. -
тем,
какие механизмы программного обеспечения
используются для реализации функций
всех четырех групп. -
как
логические компоненты распределяются
между компьютерами в сети. -
какие
механизмы используются для связи
компонентов между собой.
Слои
распределенной системы могут быть
по-разному реализованы и исполняться
в разных узлах сети. Обычно рассматриваются
следующие архитектуры
|
Слой Тип архитектуры |
Файл-сервер |
Клиент-сервер (Бизнес-логика на |
Клиент-сервер (бизнес-логика на |
N-уровневая архитектура |
|
Представления |
Клиент |
Клиент |
Клиент |
Клиент |
|
Бизнес- логики |
Клиент |
Клиент |
Сервер БД |
Сервер приложений |
|
Хранения |
Файл-сервер (или Все |
Сервер БД Пользоват. |
Сервер БД Вся |
Сервер БД Все |
Таким
образом, можно придти к нескольким
моделям клиент-серверного взаимодействия:
Классификация
архитектур информационных систем не
является абсолютно жесткой,
наиболее типичная классификация:
1. Система совместного использования
файлов – FS-модель Архитектура
системы БД с сетевым доступом предполагает
выделение одной из машин сети в качестве
центральной (сервер файлов). На такой
машине хранится совместно используемая
централизованная БД. Все другие машины
сети выполняют функции рабочих станций,
с помощью которых поддерживается доступ
пользовательской системы к централизованной
базе данных. Файлы базы данных в
соответствии с пользовательскими
запросами передаются на рабочие станции,
где в основном и производится обработка.
При большой интенсивности доступа к
одним и тем же данным производительность
информационной системы падает.
Пользователи могут также создавать на
рабочих станциях локальные БД, которые
используются ими монопольно.
В
соответствии с этой моделью один из
компьютеров в сети считается файловым
сервером и предоставляет услуги по
обработке файлов другим компьютерам и
играет роль компонента доступа к
информационным ресурсам (то есть к
файлам). Файл-сервер представляет собой
разделяемое всеми PC комплекса расширение
дисковой памяти. На других компьютерах
в сети функционирует приложение, в кодах
которого совмещены компонент представления
и прикладной компонент. Протокол обмена
представляет собой набор низкоуровневых
вызовов, обеспечивающих приложению
доступ к файловой системе на файл-сервере.
В системах, построенных по архитектуре
файл-сервера все слои системы представляют
единое и неделимое целое. БД хранится
в виде файла или набора файлов на
файл-сервере. Вся логика выборки, хранения
и обеспечения непротиворечивости данных
возлагается на клиентскую часть.
Файл-серверные системы ориентированы
на работу с отдельными записями в
таблице.
Достоинства
-
Простота логики.
-
Низкие требования к аппаратному
обеспечению и малый объем требуемой
памяти. -
Не требуют надежных многозадачных и
многопользовательских ОС. -
Невысокая цена СУБД.
Недостатки
-
Ограниченность языка и негибкость
среды разработки приложений -
Слабая масштабируемость
-
Не обеспечивают многопользовательский
режим работы -
Трудно поддерживать целостность и
непротиворечивость данных -
Необходимость ручной блокировки записей
или таблиц целиком. -
Низкий уровень защищенности как внешней
(от взлома), так и внутренней (от ошибок
приложений) Например индексы отдельно
от таблиц. -
Не имеют средств шифрации сетевого
трафика -
Создают высокую нагрузку на сеть
Выводы
Файл-серверная
архитектура является достаточно
привлекательной альтернативой для
создания однопользовательских ИС со
слабыми требованиями к защите данных.
В целом, в файл-серверной архитектуре
имеем «толстого» клиента и очень
«тонкий» сервер в том смысле, что
почти вся работа выполняется на стороне
клиента, а от сервера требуется только
достаточная емкость дисковой памяти.
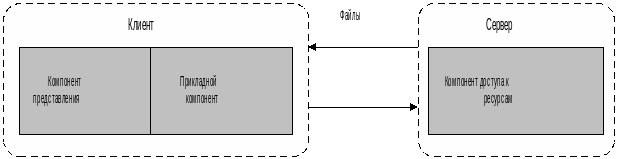
Рис.1.3.
Модель файлового сервера.
Клиент-сервер.
В этой
концепции подразумевается, что помимо
хранения централизованной базы данных
центральная машина (сервер базы данных)
должна обеспечивать выполнение основного
объема обработки данных. Запрос на
данные, выдаваемый клиентом (рабочей
станцией), порождает поиск и извлечение
данных на сервере. Извлеченные данные
(но не файлы) транспортируются по сети
от сервера к клиенту. Спецификой
архитектуры клиент-сервер является
использование языка запросов SQL
(Structured
Query
Language
2.
Система удаленной обработки или
распределенное представление –
предполагает
мощный компьютер-сервер, а клиентская
часть практически вырождена. Функцией
клиентской части является просто
отображение информации на экране. Модель
данного типа имели СУБД ранних поколений,
которые работали на малых, средних и
больших ЭВМ, использовался я один
компьютер с одним процессором.
3.
Удаленный доступ к данным (Remote
Data
Access
— RDA)
отличается от FS-модели
характером компонента доступа к
информационным ресурсам. Это, как
правило, SQL-сервер.
В RDA-модели программы реализующие функции
представления информации (коды компонента
представления) и логику прикладной
обработки(прикладная компонента),
совмещены и выполняются на компьютере-клиенте.
Последний поддерживает как функции
ввода и отображения данных, так и чисто
прикладные функции. Обращение за
сервисом управления данными происходит
через среду передачи с помощью операторов
языка SQL или вызовов
функций специальной библиотекой API
(Application Programming
Interfase- интерфейса прикладного
программирования). Наиболее часто
встречающийся вариант реализации
архитектуры клиент-сервер в уже внедренных
и активно используемых системах. Такая
модель обеспечивает полную децентрализацию
управления бизнес-логикой. Однако в
случае необходимости выполнения
каких-либо изменений в клиентском
приложении придется менять исходный
код. Серверная часть, при описанном
подходе, представляет собой сервер баз
данных, реализующий AL.
В
данных системах хранение, выборка и
поддержание непротиворечивости данных
возлагается на сервер БД, а вся
бизнес-логика и логика представления
исполняются на клиентских машинах. Так
как все операции по манипулированию
данными осуществляются только через
сервер, производительность и сохранность
данных зависит только от сервера БД.
Серверы БД изначально рассчитаны на
многопользовательский режим работы,
имеют эффективные алгоритмы кеширования
данных. Современные серверы имеют
хорошую масштабируемость.
Клиентская
часть обменивается данными с сервером
посредством SQL запросов. Обработка
информации в клинт-серверных системах
ведется на уровне множества кортежей.
Процесс
разработки разделяется на создание БД
и написание клиентской части с
бизнес-логикой.
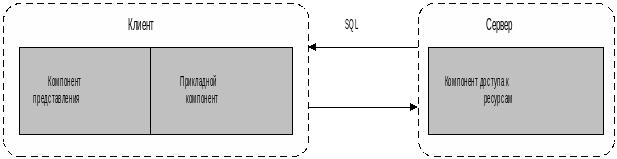
Рис
1.4. Модель доступа к удаленным данным.
Достоинства:
-
большое обилие готовых СУБД, имеющих
SQL-интерфейсы; -
унификация интерфейса «клиент-сервер»
в виде языка SQL -
Высокая производительность, стабильность
и надежность при многопользовательской
работе. -
Легко организуется защита данных
(шифрование сетевого трафика SSH, SSL) -
Универсальность языка определения и
манипулирования данными
Недостатки
-
Более высокая цена СУБД. (сервер БД
продается отдельно). -
Достаточно высокие требования к
квалификации разработчиков -
Навыки администрирования сервера БД
-
Повышенные требования к пропускной
способности сети -
Повышенные требования к клиентским
местам (на них выполняется высокая
загрузка систем передачи данных; -
Неудобны с точки зрения разработки,
модификации и сопровождения.
Выводы
При
количестве пользователей от 2 до ~50 она
является хорошим вариантом. С ростом
числа пользователей начинает
сказываться недостаточная пропускная
способность сети.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
17.09.2019139.78 Кб0рт.doc
- #
- #
- #
- #
- #
- #
- #
1. Модели клиент- сервер в технологии БД
Вычислительная модель клиент-сервер исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро развивалась. Термин клиент-сервер исходно применялся к архитектуре, при которой клиентский процесс запрашивает некоторые услуги, а серверный процесс обеспечивает их выполнение.
Реализация архитектуры клиент — сервер, применительно к разработке БД позволяет более полно использовать ресурсы сети. Нагрузка равномерно распределяется между компьютером сервером и компьютером клиентом, который также как и сервер обладает собственными ресурсами.
Основной принцип технологии клиент – сервер применительно к технологии БД заключается в разделении функций стандартного интерактивного приложения на 5 групп, имеющих различную природу:
· Функции ввода и отображения данных (Presentation Logic).
· Прикладные функции, определяющие основные алгоритмы решения задач приложения (Business Logic).
· Функции обработки данных внутри приложения (Database Logic).
· Функции управления информационными ресурсами (Database Manager System).
· Служебные функции, играющие роль связок между функциями первых 4-х групп.
Рекомендуемые материалы
Структура типового интерактивного приложения, работающего с БД, приведена на рисунке 2.
рис.
Презентационная логика – эта часть приложения, определяющая то, что пользователь видит на экране. Сюда относятся, интерфейсные экранные формы, а также все, что выводится пользователю на экран, как результаты решения промежуточных задач или справочная информация.
Основными задачами презентационной логики являются:
· Формирование экранных изображений;
· чтение и запись в экранные формы информации;
· управление экраном;
· обработка движений мыши и нажатия клавиш клавиатуры.
Бизнес- логика или логика приложений — это часть кода приложения, которая определяет собственно алгоритмы решения задач приложения. Обычно этот код пишется с помощью различных языков программирования: С, Соbol, Visual Basic.
Логика обработки данных — это часть кода приложения, которая связана с обработкой данных внутри приложения. Данными управляет собственно СУБД. Для обеспечения доступа к данным используются язык запросов и средства манипулирования данными языка SQL. Процессор управления данными – это собственно СУБД, которая обеспечивает хранение и управление БД.
В централизованной архитектуре эти функции располагаются в единой среде и комбинируются внутри исполняемой программы. В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений:
· распределенная презентация; (часть представления на клиенте, часть на сервере, на севере – все остальные части)
· удаленная презентация; (вся презентация на клиенте – все остальное на сервере)
· распределенная бизнес логика; (презентация и часть бизнес-логики на клиенте)
· распределенное управление данными; (презентация, бизнес-логика, и часть управления данными на клиенте);
· удаленное управление данными (презентационная и бизнес-логика на клиенте, остальное на сервере).
· распределенная БД.
Эта классификация показывает, как задачи могут быть распределены между серверным и клиентским процессами.
Двухуровневые модели
Двухуровневая модель предполагает распределение всех указанных функций между 2-мя процессами, которые выполняются на 2-х платформах – клиенте и сервере.
В чистом виде почти никакая модель не существует.
2. Модель удаленного доступа к данным
В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагается база данных и ядро СУБД (см. рис.3).
Обращение за сервисом управления данными происходит с помощью языка SQL. Достоинство модели – наличие большого числа готовых СУБД, имеющих SQL — интерфейсы и набор инструментальных средств, обеспечивающих создание клиентских приложений. В этой модели по сети передаются SQL-запросы, в ответ на запросы клиент получает не блоки файлов, а только данные, релевантные запросу. Основное достоинство – унификация интерфейса клиент- сервер, стандартом при общении клиента и сервера становится язык SQL. Недостатки: достаточно высокая загрузка системы передачи данных, вследствие того, что вся логика сосредоточена в приложении, а обрабатываемые данные расположены на удаленном узле.
Эти системы неудобны с точки зрения модификации и сопровождения. Даже при незначительном изменении функций системы требуется переделка всей прикладной части. Так как на клиенте расположена и презентационная логика и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения.
Сервер в этой модели играет пассивную роль, поэтому функции информационного управления должны выполняться на клиенте. Например, если необходимо выполнять контроль страховых запасов на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаления товара со склада, должно выполнять проверку на объем остатка. В случае если он меньше страхового запаса, необходимо формировать соответствующую заявку на поставку требуемого товара. Это может вызвать необоснованный заказ дополнительных товаров несколькими приложениями.
3. Удаленная презентация (Модель сервера БД)
Модель сервера БД приведена на рисунке 4.
Рисунок 4
Модель сервера БД отличается тем, что функции компьютера клиента ограничиваются представлением информации, в то время как прикладные функции обеспечиваются приложением, находящимся на компьютере-сервере. Эта модель является более технологичной, чем модель удаленного доступа.
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия:
· Необходимо, чтобы БД, в каждый момент отражала текущее состояние предметной области.
· БД должна отражать некоторые правила предметной области, законы, по которым она функционирует. Например, завод может нормально функционировать только в том случае, когда имеется достаточный запас деталей определенной номенклатуры, деталь может быть запущена в производство только в том случае, если на складе имеется достаточно материала для ее изготовления и т.д.
· Необходим постоянный контроль над состоянием БД, отслеживание всех изменений и адекватная реакция на них. Например, при уменьшении товарного запаса ниже критического уровня должна быть сформирована заявка на поставку соответствующего товара.
Такую модель поддерживают большинство современных СУБД: Informix, Oracle, Sybase, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который называется механизмом поддержки доменной структуры. Процедуры обычно хранятся в словаре БД и разделяются несколькими клиентами. Хранимые процедуры могут выполняться в режимах интерпретации и компиляции. Клиентское приложение обращается серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, соответствующие его запросу, которые требуются либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером заметно уменьшается.
Централизованный контроль целостности данных в модели сервера БД выполняется с использованием механизма триггеров. Триггеры также являются частью БД. Термин триггер взят из электроники и семантически точно отражает механизм отслеживания специальных событий, которые связаны с состоянием БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при наступлении соответствующего события сервер запускает соответствующий триггер. Триггер представляет собой некоторую программу, которая выполняется над БД. Триггеры могут вызывать хранимые процедуры.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для написания хранимых процедур и триггеров используется расширения стандартного языка SQL.
Достоинства модели — возможность хорошего централизованного администрирования приложений на этапах разработки, сопровождения и модификации, а также эффективное использование вычислительных и коммуникационных ресурсов. Один из недостатков модели связан с ограничениями средств разработки хранимых процедур. Основное ограничение — сильная привязка операторов хранимых процедур к используемой СУБД. Язык написания хранимых процедур, по сути, является процедурным расширением языка SQL и не может соперничать по функциональным возможностям с традиционными языками, такими как С или Паскаль. Другой недостаток — очень большая загрузка сервера.
Если мы переложили большую часть бизнес логики приложения на сервер, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с тонким клиентом, в отличие от предыдущих, где на клиента возлагались гораздо более серьезные задачи.
Возможна модель распределенной бизнес-функции, в которой общая часть бизнес-функций реализована на сервере, а специфические функции обработки информации находятся на клиенте. Функции общего характера могут включать в себя стандартное обеспечение целостности данных, например, в виде хранимых процедур, а оставшиеся прикладные функции реализуют специальную прикладную обработку.
4. Модель распределенной БД
Эта модель предполагает использование мощного компьютера клиента, причем данные хранятся и на компьютере-клиенте и на компьютере-сервере. Взаимосвязь обеих БД может быть 2-х разновидностей:
а) в локальной и удаленной базах хранятся отдельные части единой БД;
б) локальная и удаленная БД являются синхронизируемыми друг с другом копиями.
Достоинство – гибкость разрабатываемых ИС позволяющих компьютеру клиенту обрабатывать и локальные и удаленные БД. Недостаток – высокие затраты при выполнении большого числа одинаковых приложений на компьютерах клиентах.
5. Модель сервера приложений
Эта модель является расширением 2-хуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот промежуточный уровень содержит один или несколько серверов приложений.
В этой модели компоненты делятся между тремя исполнителями:
6. Клиент обеспечивает логику представления, включая графический пользовательский интерфейс; клиент может запускать локальный код приложения клиента, который может содержать обращения к локальной БД, находящейся на компьютере- клиенте. Клиент исполняет коммуникационные функции, которые обеспечивают доступ клиенту в локальную или глобальную сеть.
7. Серверы приложений представляет собой новый дополнительный уровень архитектуры. На сервере приложений реализуется несколько прикладных функций, каждая из которых оформлена как служба предоставления услуг всем требующим этого программам. Серверов приложений может быть несколько, причем каждый из них предоставляет свой вид сервиса. Любая программа, запрашивающая услугу у сервера приложений, является для него клиентом. Поступающие к серверам от клиентов запросы помещаются в очередь.
8. Серверы БД в этой модели занимаются исключительно функциями СУБД: обеспечивают создания и ведения БД, обеспечивают функции хранилищ БД, кроме того, на них возлагаются функции создания резервных копий, восстановления БД после сбоев, управления выполнением транзакций.
Эта модель обладает большей гибкостью, чем двухуровневая модель.
9. КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Перечислите основные функции стандартного интерактивного приложения, связанного с обработкой баз данных.
8. Вскрытие штольней — лекция, которая пользуется популярностью у тех, кто читал эту лекцию.
2. Перечислите основные задачи презентационной логики.
3. Что включает в себя бизнес-логика приложения?
4. Перечислите варианты распределения функций стандартного интерактивного приложения в архитектуре клиент-сервер.
5. Назовите основные двухуровневые модели архитектуры клиент-сервер.
6. В чем заключаются особенности модели удаленного доступа к данным?
7. Какими средствами реализуется бизнес-логика при использовании модели удаленной презентации?
Клиент-сервер с бизнес-логикой на клиенте
В данных системах хранение, выборка и поддержание непротиворечивости данных возлагается на сервер БД, а вся бизнес-логика и логика представления исполняются на клиентских машинах. Так как все операции по манипулированию данными осуществляются только через сервер, производительность и сохранность данных зависит только от сервера БД. Серверы БД изначально рассчитаны на многопользовательский режим работы, имеют эффективные алгоритмы кеширования данных. Современные серверы имеют хорошую масштабируемость.
Клиентская часть обменивается данными с сервером посредством SQL запросов. Обработка информации в клиент-серверных системах ведется на уровне множества кортежей.
Процесс разработки разделяется на создание БД и написание клиентской части с бизнес-логикой.

Достоинства
- Высокая производительность, стабильность и надежность при многопользовательской работе.
- Легко организуется защита данных (шифрование сетевого трафика SSH, SSL)
- Универсальность языка определения и манипулирования данными

Недостатки
- Более высокая цена СУБД. (сервер БД продается отдельно).
- Достаточно высокие требования к квалификации разработчиков
- Навыки администрирования сервера БД
- Повышенные требования к пропускной способности сети
- Повышенные требования к клиентским местам (на них выполняется слой бизнес- логики)
Выводы
При количестве пользователей от 2 до ~50 она является хорошим вариантом. С ростом числа пользователей начинает сказываться недостаточная пропускная способность сети.
Клиент-сервер с бизнес-логикой на сервере
Используется возможность современных серверов БД исполнять хранимые SQL процедуры на сервере, куда и переносится максимально возможная часть бизнес-логики. Требования к серверу БД возрастают, однако резко понижаются требования к клиентским машинам (за счет выноса с них бизнес-логики) и к пропускной способности сети (клиенту передаются только данные, необходимые пользователю).
Достоинства
- Пониженные, по сравнению с предыдущим классом систем, требования к пропускной способности сети и клиентским местам.
- Более простой процесс создания бизнес-логики.
Недостатки
- Повышенные требования к серверу БД.(каждый сеанс «съедает» память из расчета предельной загрузки)
- Невысокая переносимость (мобильность) системы на другие серверы БД.
Выводы
По сравнению с предыдущими классами, позволяет держать большую нагрузку.
N-уровневая архитектура
Основными элементами являются сервера БД, сервер(кластер) приложений и клиентская часть. Главная идея n-уровневой архитектуры заключается в максимальном упрощении клиента (тонкий клиент) , выносе всей бизнес-логики с клиента и сервера БД.
Тонкий клиент представляет собой некоторый терминал типа HTML—browser или эмуляторы X-терминала
Вся бизнес- логика оформляется в виде набора приложений, запускаемых на сервере приложений под управлением ОС типа UNIX.
Сервера БД занимаются только проблемами хранения, добавления, модификации и поддержания непротиворечивости данных.
Сервер приложений соединен с сервером БД при помощи отдельного высокоскоростного сегмента сети.
Достоинства
- Повышенная защищенность.
- Высокая производительность.
- Легкость развития и модификации.
- Легкость администрирования.
- Возможность создания системы с массовым параллелизмом (серверов БД может быть несколько, а сервером приложений могут служить несколько соединенных в кластер компьютеров).
Недостатки
- Высокая сложность.
- Высокая цена решения.
- В некоторых случаях уступает по производительности клиент-серверным системам с бизнес-логикой на сервере.
Выводы
Единственная альтернатива для создания ИС для очень большого количества пользователей.
Практические занятия
Постановка задачи. Проектирование данных на концептуальном и логическом уровнях. Нормализация отношений.
![]() Презентация по ER-моделированию
Презентация по ER-моделированию
![]() ER нотации
ER нотации
Пример модели в ERwin
Подготовка SQL скриптов генерации схемы отношений БД в ERwin. Разработка скрипта для ввода тестовой информации.
Видео-презентация (Для проигрывания требуется Windows Media Player)
Архитектура MS SQL Server 2005. Настройка и использование основных компонент среды. Создание учебной базы данных.
Видео-презентация (Для проигрывания требуется Windows Media Player)
Работа с СУБД MS SQL Server 2005, ORACLE 10g. Примеры соединений с БД, технологии разработки клиенского приложения
Использование технологии Java Database Connectivity (JDBC) для работы с базами данных
![]() Презентация
Презентация
Примеры к презентации
![]() SQL-скрипты, проект и исходные коды
SQL-скрипты, проект и исходные коды
package org.mai806.jdbcsample;
import java.sql.*;
public class QuerySample {
public static void main(String[] args) throws Exception {
/* ======== Подключение к MS SQL Server ===== */
// Загрузка драйвера
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
// Соединение с базой данных
Connection connection = DriverManager.getConnection(
"jdbc:sqlserver://localhost:1433;databaseName=o01;",
// localhost - сервер СУБД, o01 - имя базы данных
"sa", "123"); // пользователь, пароль
/* ======== Подключение к Oracle ============
// Загрузка драйвера
Class.forName("oracle.jdbc.OracleDriver");
// Соединение с базой данных
Connection connection = DriverManager.getConnection(
"jdbc:oracle:thin:@localhost:1521:orcl",
// localhost - сервер СУБД, orcl - SID базы оракла
"o01", "o01"); // пользователь, пароль
// Создание Statement
PreparedStatement stmt = connection.prepareStatement
("select ID, NAME from PERSON where NAME like ?");
stmt.setString(1, "%S%");
// Выполнение запроса
ResultSet rs = stmt.executeQuery();
// Перебор результата выполнения запроса
while(rs.next()) {
// Пример выбора параметра по номеру или по имени
System.out.println("ID: " +
rs.getLong(1) + "; NAME="+
rs.getString("NAME"));
}
// закрытие использованных ресурсов БД
rs.close();
stmt.close();
connection.close();
}
}
Листинг
P.1.
Выполнение запроса: QuerySample.java
package org.mai806.jdbcsample;
import java.sql.*;
import java.util.ResourceBundle;
public class StoredProcedureSample {
private static Connection connection = null;
public static void main(String[] args) throws Exception {
// Получение соединения из значений параметров в файле properties
ResourceBundle properties = ResourceBundle.getBundle("database");
Class.forName(properties.getString("driver"));
connection = DriverManager.getConnection(
properties.getString("url"),
properties.getString("user"),
properties.getString("password"));
transferAmount(1,2,100.0);
connection.close();
}
/**
* Переводит указанную сумму с одного счета на другой
* @param from счет плательщика
* @param to счет получателя
* @param amount сумма
*/
public static void transferAmount(long from, long to, double amount)
throws Exception {
// Создание Statement
CallableStatement stmt
= connection.prepareCall("{call TransferAmount(?,?,?)}");
// Установка параметров
stmt.setLong(1, from);
stmt.setLong(2, to);
stmt.setDouble(3, amount);
// Выполнение процедуры
stmt.execute();
}
}
Листинг
P.2.
Выполнение хранимой процедуры: StoredProcedureSample.java
package org.mai806.jdbcsample;
import java.sql.*;
import java.util.ResourceBundle;
public class TransactionalSample {
private static Connection connection = null;
public static void main(String[] args) throws Exception {
// Получение соединения из значений параметров в файле properties
ResourceBundle properties = ResourceBundle.getBundle("database");
Class.forName(properties.getString("driver"));
connection = DriverManager.getConnection(
properties.getString("url"),
properties.getString("user"),
properties.getString("password"));
// Ручное управление транзакциями
connection.setAutoCommit(false);
try {
transferAmount(2, 1, 10.0);
} finally {
connection.close();
}
}
/**
* Переводит указанную сумму с одного счета на другой
* @param from счет плательщика
* @param to счет получателя
* @param amount сумма
*/
public static void transferAmount(long from, long to,
double amount) throws Exception {
PreparedStatement stmt = null;
Statement query = null;
try {
stmt = connection.prepareStatement
("update ACCOUNT set AMOUNT=AMOUNT+? where ID=?");
// Забираем сумму со счета плательщика
stmt.setDouble(1, -amount);
stmt.setLong(2, from);
stmt.execute();
// Добавляем сумму на счет получателя
stmt.setDouble(1, amount);
stmt.setLong(2, to);
stmt.execute();
// Пост-проверка: отрицательность счета плательщика
query = connection.createStatement();
ResultSet rs = query.executeQuery(
"select AMOUNT from ACCOUNT where ID="+from+" and AMOUNT<0");
if (rs.next()) {
throw new Exception("На счете №"+from+"
недосточно средств ["+(amount+rs.getDouble(1))+"]
для снятия суммы ["+amount+"]");
}
connection.commit();
System.out.println("Перечисление средств успешно выполнено");
} catch(Exception e) {
e.printStackTrace();
connection.rollback();
} finally {
if (stmt!=null)
stmt.close();
if (query!=null)
query.close();
}
}
}
Листинг
P.3.
Работа с транзакциями: TransactionalSample.java
Работа с базами данных из J2EE Web-контейнера
![]() Презентация
Презентация
Объектно-реляционное отображения для работы с базами данных
![]() Презентация
Презентация
Использование препроцессора для работы с API СУБД
![]() Презентация
Презентация
Привет, мой друг, тебе интересно узнать все про паттерны организация бизнес-логики, тогда с вдохновением прочти до конца. Для того чтобы лучше понимать что такое
паттерны организация бизнес-логики , настоятельно рекомендую прочитать все из категории Объектно-ориентированное программирование ООП.
Рассматривая структуру логики предметной области (или бизнес-логики) приложения, мы изучаем варианты распределения множества предусматриваемых ею функций по трем типовым решениям: сценарий транзакции (Transaction Script), модель предметной области (Domain Model) и модуль таблицы (Table Module).
Простейший подход к описанию бизнес-логики связан с использованием сценария транзакции — процедуры, которая получает на вход информацию от слоя представления, обрабатывает ее, проводя необходимые проверки и вычисления, сохраняет в базе данных и активизирует операции других систем. Затем процедура возвращает слою представления определенные данные, возможно, осуществляя вспомогательные операции для форматирования содержимого результата. Бизнес-логика в этом случае описывается набором процедур, по одной на каждую (составную) операцию, которую способно выполнять приложение. Типовое решение сценарий транзакции, таким образом, можно трактовать как сценарий действия, или бизнес-транзакцию. Оно не обязательно должно представлять собой единый фрагмент кода. Код делится на подпрограммы, которые распределяются между различными сценариями транзакции.
Типовое решение сценарий транзакции отличается следующими преимуществами:
- представляет собой удобную процедурную модель, легко воспринимаемую всеми разработчиками;
- удачно сочетается с простыми схемами организации слоя источника данных на основе типовых решений шлюз записи данных (Row Data Gateway) и шлюз таблицы данных (Table Data Gateway);
- определяет четкие границы транзакции.
С возрастанием уровня сложности бизнес-логики типовое решение сценарий транзакции демонстрирует и ряд недостатков. Если нескольким транзакциям необходимо осуществлять схожие функции, возникает опасность дублирования фрагментов кода. С этим
явлением удается частично справиться за счет вынесения общих подпрограмм «за скобки», но даже в этом случае большая часть дубликатов остается на месте. В итоге приложение может выглядеть как беспорядочная мешанина без отчетливой структуры.
Конечно, сложная логика — это удачный повод вспомнить об объектах, и объектно-ориентированный вариант решения проблемы связан с использованием модели предметной области, которая, по меньшей мере в первом приближении, структурируется преимущественно вокруг основных сущностей рассматриваемого домена. Так, например, в лизинговой системе следовало бы создать классы, представляющие сущности «аренда», «имущество», «договор» и т.д., и предусмотреть логику проверок и вычислений: так, например, объект, представляющий сущность «имущество», вероятно, уместно снабдить логикой вычисления стоимости.
Выбор модели предметной области в противовес сценарию транзакции — это как раз та смена парадигмы программирования, о которой так любят говорить апологеты объектного подхода. Вместо использования одной подпрограммы, несущей в себе всю логику, которая соответствует некоторому действию пользователя, каждый объект наделяется только функциями, отвечающими его природе. Если прежде вы не пользовались моделью предметной области, процесс обучения может принести немало огорчений, когда в поисках нужных функций вам придется метаться от одного класса к другому.
Стоимость практической реализации модели предметной области обусловлена степенью сложности как самой модели, так и конкретного варианта слоя источника данных. Чтобы добиться успехов в применении модели, новичкам придется затратить немало времени: некоторым требуется несколько месяцев работы над соответствующим проектом, прежде чем их стиль мышления перестроится в нужном направлении. После приобретения опыта работать становится намного проще — в вас даже просыпается энтузиазм. Через это прошли все, кто так одержим объектной парадигмой. Впрочем, сбросить груз привычек и сделать шаг вперед многим, к сожалению, так и не удается.
Разумеется, каким бы ни был подход, необходимость отображать содержимое базы данных в структуры памяти и наоборот все еще остается. Чем более «богата» модель предметной области, тем сложнее становится аппарат взаимного отображения объектных структур в реляционные (обычно реализуемый на основе типового решения преобразователь данных (Data Mapper). Сложный слой источника данных стоит дорого — в финансовом смысле (если вы приобретаете услуги сторонних разработчиков) или в отношении затрат времен (если беретесь за дело самостоятельно), но если он у вас есть, считайте, что добрая половина проблемы уже решена.
Существует и третий вариант структуризации бизнес-логики, предусматривающий применение типового решения модуль таблицы Принципиальное различие модуля талицы от модели предметной области заключается в том, что модель предметной области содержит по одному объекту контракта для каждого контракта, зафиксированного в базе данных, а модуль таблицы является единственным объектом. Модуль таблицы применяется совместно с типовым решением множество записей (Record Set). Посылая запросы к базе данных, пользователь прежде всего формирует объект множество записей, а затем создает объект контракта, передавая ему множество записей в качестве аргумента. Если потребуется выполнять операции над отдельным контрактом, следует сообщить объекту соответствующий идентификатор (ID).
Модуль таблицы во многих смыслах представляет собой промежуточный вариант, компромиссный по отношению к сценарию транзакции и модели предметной области. Организация бизнес-логики вокруг таблиц, а не в виде прямолинейных процедур облегчает структурирование и возможность поиска и удаления повторяющихся фрагментов кода. Однако решение модуль таблицы не позволяет использовать многие технологии (скажем, наследование, стратегии и другие объектно-ориентированные типовые решения), которые применяются в модели предметной области для уточнения структуры логики.
Наибольшее преимущество модуля таблицы состоит в том, как это решение сочетается с остальными аспектами архитектуры. Многие графические интерфейсные среды позволяют работать с результатами обработки SQL-запроса, организованными в виде множества записей. Поскольку решение модуль таблицы также основано на использовании множества записей, открывается возможность выполнения запроса, манипулирования его результатом в контексте модуля таблицы и передачи данных графическому интерфейсу для отображения. Некоторые платформы, в частности Microsoft COM и .NET, поддерживают именно такой стиль разработки.
Выбор типового решения
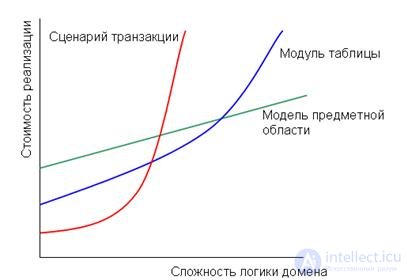
Рисунок 3.4 Зависимость стоимости реализации различных схем организации бмзнес-логики от ее сложности
Итак, какому из трех типовых решений отдать предпочтение. Ответ не очевиден и во многом зависит от степени сложности бизнес-логики. На рис. 3.4 показан один из тех неформальных графиков, которые многим действуют на нервы, когда приходится наблюдать презентации. Причиной раздражения служит отсутствие единиц измерения величин, представляемых координатными осями. Впрочем, в данном случае подобный график кажется уместным, так как помогает визуализировать критерии сопоставления решений. Если логика приложения проста, модель предметной области менее соблазнительна, поскольку затраты на ее реализацию не окупаются. Но с возрастанием сложности альтернативные подходы становятся все менее приемлемыми: трудоемкость пополнения приложения новыми функциями увеличивается по экспоненциальному закону.
Конечно, необходимо разобраться, к какому именно сегменту оси X относится конкретное приложение. Было бы совсем неплохо, если бы мы имели право сказать, что модель предметной области следует применять в тех случаях, когда сложность бизнес-логики составляет, например, 7,42 или больше. Однако никто не знает, как измерять сложность бизнес-логики. Поэтому на практике проблема обычно сводится к выслушиванию мнений сведущих людей, которые способны хоть как-то проанализировать ситуацию и прийти к осмысленным выводам.
Существует ряд факторов, влияющих на кривизну линий графика. Наличие команды разработчиков, уже знакомых с моделью предметной области, позволяет снизить величину начальных затрат — хотя и не до уровней, характерных для двух других зависимостей (последнее обусловлено сложностью слоя источника данных). Таким образом, чем опытнее вы и ваши коллеги, тем больше у вас оснований для применения модели предметной области.
Эффективность модуля таблицы серьезно зависит от уровня поддержки структуры множества записей в конкретной инструментальной среде. Если вы работаете с чем-то наподобие Visual Studio .NET, где многие средства построены именно на основе модели множества записей, это обстоятельство наверняка придаст модулю таблицы дополнительную привлекательность. Что касается сценария транзакции, то трудно найти доводы в пользу его применения в контексте .NET.
Как только архитектура выбрана (пусть и не окончательно), изменить ее со временем становится все труднее. Поэтому целесообразно приложить определенные усилия, чтобы заранее решить, каким путем двигаться. Если вы начали со сценария транзакции, но затем поняли свою ошибку, не мешкая обратитесь к модели предметной области. Если вы с нее и начинали, переход к сценарию транзакции вряд ли окажется удачным, если только вы не сможете серьезно упростить слой источника данных.
Три типовых решения, которые мы бегло рассмотрели, не являются взаимоисключающими альтернативами. На самом деле сценарий транзакции нередко используется для некоторого фрагмента бизнес-логики, а модель предметной области или модуль таблицы — для оставшейся части.
Уровень служб
Один из общих подходов к реализации бизнес-логики состоит в расщеплении слоя предметной области на два самостоятельных слоя: «поверх» модели предметной области или модуля таблицы располагается слой служб (Service Layer [4]) . Об этом говорит сайт https://intellect.icu . Обычно это целесообразно только при использовании модели предметной области или модуля таблицы, поскольку слой домена, включающий лишь сценарий транзакции, не настолько сложен, чтобы заслужить право на создание дополнительного слоя. Логика слоя представления взаимодействует с бизнес-логикой исключительно при посредничестве слоя служб, который действует как API приложения.
Поддерживая внятный интерфейс приложения (API), слой служб подходит также для размещения логики управления транзакциями и обеспечения безопасности. Это дает возможность снабдить подобными характеристиками каждый метод слоя служб.
Для таких целей обычно применяются файлы свойств, но атрибуты .NET предоставляют удобный способ описания параметров непосредственно в коде. Основное решение, принимаемое при проектировании слоя служб, состоит в том, какую часть функций уместно передать в его ведение. Самый «скромный» вариант — представить слой служб в виде промежуточного интерфейса, который только и делает, что направляет адресуемые ему вызовы к нижележащим объектам. В такой ситуации слой служб обеспечивает API, ориентированный на определенные варианты использования (use cases) приложения, и предоставляет удачную возможность включить в код функции оболочки, ответственные за управление транзакциями и проверку безопасности.
Другая крайность — в рамках слоя служб представить большую часть логики в виде сценариев транзакции. Нижележащие объекты домена в этом случае могут быть тривиальными; если они сосредоточены в модели предметной области, удастся обеспечить их однозначное отображение на элементы базы данных и воспользоваться более простым вариантом слоя источника данных (скажем, активной записью (Active Record).
Между двумя указанными полюсами существует вариант, представляющий собой больше, нежели «смесь» двух подходов: речь идет о модели «контроллер-сущность» («controller-entity»). Главная особенность модели заключается в том, что логика, относящаяся к отдельным транзакциям или вариантам использования, располагается в соответствующих сценариях транзакции, которые в данном случае называют контроллерами (или службами). Они выполняют роль входных контроллеров в типовых решениях модель-представление-контроллер (Model View Controller,) и контроллер приложения (Application Controller [4]) (вы познакомитесь с ними позже) и поэтому называются также контроллерами вариантов использования (use case controller). Функции, характерные одновременно для нескольких вариантов использования, передаются объектам-сущностям (entities) домена.
Хотя модель «контроллер-сущность» распространена довольно широко, следует иметь ввиду, что контроллеры вариантов использования, подобные любому сценарию транзакции, негласно поощряют дублирование фрагментов кода.
3.3.1 Паттерн Transaction Script
Название
Transaction Script (сценарий транзакции)
Назначение
Способ организации бизнес-логики по процедурам, каждая из которых обслуживает один запрос, инициируемый слоем представления.
Многие бизнес-приложения могут восприниматься как последовательности транзакций. Одна транзакция способна модифицировать данные, другая — воспринимать их в структурированном виде и т.д. Каждый акт взаимодействия клиента с сервером описывается определенным фрагментом логики. В одних случаях задача оказывается настолько же простой, как отображение части содержимого базы данных. В других могут предусматриваться многочисленные вычислительные и контрольные операции. Сценарий транзакции организует логику вычислительного процесса преимущественно в виде единой процедуры, которая обращается к базе данных напрямую или при посредничестве кода тонкой оболочки. Каждой транзакции ставится в соответствие собственный сценарий транзакции (общие подзадачи могут быть вынесены в подчиненные процедуры).
Принцип действия
При использовании типового решения сценарий транзакции логика предметной области распределяется по транзакциям, выполняемым в системе. Если, например, пользователю необходим заказать номер в гостинице, соответствующая процедура должна предусматривать действия по проверке наличия подходящего номера, вычислению суммы оплаты и фиксации заказа в базе данных.
Простые случаи не требуют особых объяснений. Разумеется, как и при написании иных программ, структурировать код по модулям следует осмысленно. Это не должно вызывать затруднений, если только транзакция не оказывается слишком сложной. Одно из основных преимуществ сценария транзакции заключается в том, что вам не приходится беспокоиться о наличии и вариантах функционирования других параллельных транзакций. Ваша задача — получить входную информацию, опросить базу данных, сделать вы- воды и сохранить результаты.
Где расположить сценарий транзакции, зависит от организации слоев системы. Этим местом может быть страница сервера, сценарий CGI или объект распределенного сеанса. Я предпочитаю обособлять сценарии транзакции настолько строго, насколько это возможно. В самом крайнем случае можно размещать их в различных подпрограммах, а лучше — в классах, отличных от тех, которые относятся к слоям представления и источника данных. Помимо того, следует избегать вызовов, направленных из сценариев транзакции к коду логики представления; это облегчит тестирование сценариев транзакции и их возможную модификацию.
Существует два способа разнесения кода сценариев транзакции по классам. Наиболее общий, прямолинейный и удобный во многих ситуациях — использование одного класса для реализации нескольких сценариев транзакции. Второй, следующий схеме типового решения команда (Command), связан с разработкой собственного класса для каждого сценария транзакции (рис. 3.5): определяется тип, базовый по отношению ко всем командам, в котором предусматривается некий метод выполнения, удовлетворяющий логике сценария транзакции. Преимущество такого подхода — возможность манипулировать экземплярами сценариев как объектами в период выполнения, хотя в системах, где бизнес-логика организована с помощью сценариев транзакции, подобная потребность возникает сравнительно редко. Разумеется, во многих языках модель классов можно полностью игнорировать, полагаясь, скажем, только на глобальные функции. Однако вполне очевидно, что аппарат создания объектов помогает преодолевать проблемы потоков вычислений и облегчает изоляцию данных.
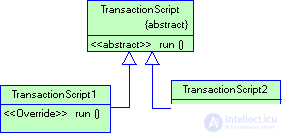
Рисунок 3.5. Применение паттерна Command в паттерне Transaction Script
Применимость
Главным достоинством типового решения сценарий транзакции является простота. Именно такой вид организации логики, эффективный с точки зрения восприятия и производительности, весьма характерен и естествен для небольших приложений. По мере усложнения бизнес-логики становится все труднее содержать ее в хорошо структурированном виде. Одна из достойных внимания проблем связана с повторением фрагментов кода. Поскольку каждый сценарий транзакции призван обслуживать одну транзакцию, все общие порции кода неизбежно приходится воспроизводить вновь и вновь.
Проблема может быть частично решена за счет тщательного анализа кода, но наличие более сложной бизнес-логики требует применять модель предметной области (Domain Model). Последняя предлагает гораздо больше возможностей структурирования кода, повышения степени его удобочитаемости и уменьшения повторяемости. Определить количественные критери выбора конкретного типового решения довольно сложно, особенно если одни решения знакомы вам в большей степени, нежели другие. Проект, основанный на сценарии транзакции, с помощью техники рефакторинга вполне возможно преобразовать в реализацию модели предметной области, но дело слишком хлопотно, чтобы им стоило заниматься. Поэтому, чем раньше вы расставите все точки над i, тем лучше. Однако каким бы ярым приверженцем объектных технологий вы ни становились, не отбрасывайте сценарий транзакции: существует множество простых проблем, и их решения также должны быть простыми.
3.3.2 Паттерн Domain Model
Название
Domain Model (модель предметной области).
Назначение
В своих наихудших проявлениях бизнес-логика бывает чрезвычайно сложной, с множеством правил и условий, оговаривающих различные варианты использования и особенности поведения системы. Для облегчения именно таких трудностей и предназначены объекты. Типовое решение модель предметной области предусматривает создание сети взаимосвязанных объектов, каждый из которых представляет некую осмысленную сущность — либо такую крупную, как промышленная корпорация, либо настолько мелкую, как строка формы заказа.
Принцип действия
Реализация модели предметной области означает пополнение приложения целым слоем объектов, описывающих различные стороны определенной области бизнеса. Одни объекты призваны имитировать элементы данных, которыми оперируют в этой области, а другие должны формализовать те или иные бизнес-правила. Функции тесно сочетаются сданными, которыми они манипулируют.
Объектно-ориентированная модель предметной области часто напоминает схему соответствующей базы данных, хотя между ними все еще остается множество различий. В модели предметной области смешиваются данные и функции, допускаются многозначные атрибуты, создаются сложные сети ассоциаций и используются связи наследования. В сфере корпоративных программных приложений можно выделить две разновидности моделей предметной области. «Простая» во многом походит на схему базы данных и содержит, как правило, по одному объекту домена в расчете на каждую таблицу. «Сложная» модель может отличаться от структуры базы данных и содержать иерархии наследования, стратегии и иные шаблоны, а также сложные сети мелких взаимосвязанных объектов. Сложная модель более адекватно представляет запутанную бизнес-логику, но труднее поддается отображению в реляционную схему базы данных. В простых моделях подчас достаточно применять варианты тривиального типового решения активная запись (Active Record), в то время как в сложных без замысловатых преобразователей данных (Data Mapper) порой просто не обойтись.
Бизнес-логика обычно подвержена частым изменениям, поэтому весьма важна возможность простой модификации и тестирования этого слоя кода. Отсюда следует настоятельная необходимость снижать степень зависимости модели предметной области от других слоев системы. Более того, как вы сможете убедиться, именно это требование является основополагающим аспектом многих типовых решений, имеющих отношение к «расслоению» системы.
С моделью предметной области связано большое количество различных контекстов.Простейший вариант— однопользовательское приложение, где единый граф объектов считывается из дискового файла и располагается в оперативной памяти. Такой стиль работы присущ настольным программам, но менее характерен для многоуровневых прило-жений, поскольку в них намного больше объектов. Размещение каждого объекта в памяти сопряжено с чрезмерными затратами ресурсов памяти и времени. Прелесть объектно-ориентированных систем баз данных заключается в том, что они создают впечатление, будто объекты пребывают в памяти постоянно.
Без такой системы заботиться о создании объектов вам придется самому. Обычно в ходе выполнения сеанса в память загружается полный граф объектов, хотя речь вовсе не идет обо всех объектах и, может быть, классах. Если, например, ведется поиск множества контрактов, достаточно считать информацию только о таких продуктах, которые упоминаются в этих контрактах. Если же в вычислениях участвуют объекты контрактов и зачтенных доходов, объекты продуктов, возможно, создавать вовсе не нужно. Точный перечень данных, загружаемых в память, определяется параметрами объектнореляционного отображения.
Одна из типичных проблем бизнес-логики связана с чрезмерным увеличением объектов. Занимаясь конструированием интерфейсного экрана, позволяющего манипулировать заказами, вы наверняка заметите, что только некоторые функции отличаются сугубо специфическим характером и узким назначением. Возлагая на единственный класс заказа всю полноту ответственности, вы рискуете раздуть его до непомерной величины. Что-бы избежать подобного, можно выделить общие характеристики «заказов» и сосредоточить их в одноименном классе, а все остальные функции вынести во вспомогательные классы сценариев транзакции (Transaction Script) или даже слоя представления. преобразователей данных (Data Mapper) порой просто не обойтись.
При этом, однако, возникает опасность повторения фрагментов кода. Функции, не относящиеся к категории общих, отыскать довольно трудно, и многие предпочитают этим просто не заниматься, соглашаясь с дублированием кода. Повторение часто приводит к усложнению и несогласованности, хотя, по моему мнению, эффекты излишнего увеличения размеров классов наблюдаются значительно реже, чем можно было ожидать
Применимость
Если вопросы как, касающиеся модели предметной области, трудны потому, что предмет чересчур велик, вопрос когда сложен ввиду неопределенности ситуации. Все зависит от степени сложности поведения системы. Если вам приходится иметь дело с изощренными и часто меняющимися бизнес-правилами, включающими проверки, вычисления и ветвления, вполне вероятно, что для их описания вы предпочтете объектную модель. Если, напротив, речь идет о паре сравнений значения с нулем и нескольких операциях сложения, проще прибегнуть к сценарию транзакции (Transaction Script).
Существует еще один фактор, который нельзя обойти вниманием: насколько комфортно чувствует себя команда разработчиков, манипулируя объектами домена. Изучение способов проектирования и применения модели предметной области — урок крайне сложный, пробудивший к жизни целый информационный пласт о «смене парадигмы». Чтобы привыкнуть к модели, нужны практика и советы профессионала, но зато среди тех, кто дошел до цели, редко встречаютсятакие, кто хотел бы вновь вернуться к сценарию транзакции, — разве только в самых простых случаях.
При необходимости взаимодействия с базой данных в контексте модели предметной области прежде всего я обратился бы к преобразователю данных. Это типовое решение поможет сохранить независимость бизнес-модели от схемы базы данных и обеспечить наилучшие возможности изменения их в будущем.
Встречаются ситуации, когда модель предметной области целесообразно снабдить более отчетливым интерфейсом API, и для этого можно порекомендовать типовое решение слой служб (Service Layer [4]) .
3.3.3 Паттерн Table Module
Название
Table Module (модуль таблицы)
Назначение
Одна из ключевых предпосылок объектной модели — сочетание элементов данных и пользующихся ими функций. Традиционный объектно-ориентированный подход основан на концепции объектов с идентификационными признаками в совокупности с требованиями модели предметной области (Domain Model). Если, например, речь идет о классе, представляющем сущность «служащий», любой экземпляр класса соответствует определенному служащему; коль скоро есть ссылка на объект, отвечающий служащему, с ним легко выполнять все необходимые операции, собирать информациюи следовать в направлении связей с другими объектами.
Одна из проблем модели предметной области заключается в сложности создания интерфейсов к реляционным базам данных; последние в подобной ситуации приобретают роль эдаких бедных родственников, с которыми никто не желает иметь дела. Поэтому считывание информации из базы данных и запись ее с необходимыми преобразованиями превращается в прихотливую игру ума.
Типовое решение модуль таблицы предусматривает создание по одному классу на каждую таблицу базы данных, и единственный экземпляр класса содержит всю логику обработки данных таблицы. Основное отличие модуля таблицы от модели предметной области состоит в том, что если, например, приложение обслуживает множество заказов, в соответствии с моделью предметной области придется сконструировать по одному объекту на каждый заказ, а при использовании модуля таблицы понадобится всего один объект, представляющий одновременно все заказы.
Принцип действия
Сильная сторона решения модуль таблицы заключается в том, что оно позволяет сочетать данные и функции для их обработки и в то же время эффективно использовать ресурсы реляционной базы данных. На первый взгляд модуль таблицы во многом напоминает обычный объект, но отличается тем, что не содержит какого бы то ни было упоминания об идентификационном признаке объекта. Если, скажем, требуется получить адрес служащего, для этого применяется метод anEmployeeModule.GetAddress(long empioyeeId). В том случае, когда необходимо выполнить операцию, касающуюся определенного служащего, соответствующему методу следует передать ссылку на идентификатор, значение которого зачастую совпадает с первичным ключом служащего в таблице базы данных.
Модулю таблицы, как правило, отвечает некая табличная структура данных. Подобная информация обычно является результатом выполнения SQL-запроса и сохраняется в виде множества записей (RecordSet). Модуль таблицы предоставляет обширный арсенал методов ее обработки. Объединение функций и данных обеспечивает многие преимущества модели инкапсуляции.
Нередко для решения общей задачи необходимо создать несколько модулей таблицыи, более того, позволить им манипулировать одним и тем же множеством записей. Наиболее очевидный пример связан с использованием отдельных модулей таблицы для каждой (хранимой) таблицы базы данных. Кроме того, можно сконструировать модули таблицы для любых достойных SQL-запросов и виртуальных таблиц. Конкретный модуль таблицы может принимать вид экземпляра класса или набора статических методов. Достоинство первого варианта состоит в том, что он позволяет инициировать модуль данными существующего множества записей, чаще всего получаемого в результате обработки SQL-запроса. Для манипуляции записями применяются методы класса. Не исключается и возможность создания иерархии наследования, когда, скажем, определяются базовый класс с описанием контракта общего вида и целое семейство производных классов, отвечающих частным разновидностям контрактов.
Модуль таблицы способен содержать методы-оболочки, представляющие запросы к базе данных. Альтернативой служит шлюз таблицы данных (Table Data Gateway). Недостаток последнего обусловлен необходимостью конструирования дополнительного класса, а преимущество заключается в возможности применения единого модуля таблицы для данных из различных источников, поскольку каждому отвечает собственный шлюз таблицы данных.
Шлюз таблицы данных позволяет структурировать информацию в виде множества записей, которое затем передается конструктору модуля таблицы в качестве аргумента (рис. 3.6). Если необходимо использовать несколько модулей таблицы, все они могут быть созданы на основе одного и того же множества записей. Затем каждый модуль таблицы применяет к множеству записей функции бизнес-логики и передает измененное множество записей слою представления для отображения и редактирования информации средствами графических табличных элементов управления. Последние не «осведомлены», откуда поступили данные — непосредственно от реляционной СУБД или от промежуточного модуля таблицы, который успел осуществить их предварительную обработку. По завершении редактирования информация возвращается модулю таблицы для проверки перед сохранением в базе данных. Одно из преимуществ подобного стиля — возможность тестирования модуля таблицы путем «искусственного» создания множества записей в памяти без обращения к реальной таблице базы данных.
Слово «таблица» в названии типового решения подчеркивает, что в приложении предусматривается по одному модулю таблицы для каждой хранимой таблицы базы данных. Это правда, но не вся. Полезно также иметь модули таблицы для общеупотребительных виртуальных таблиц и запросов, поскольку структура модуля таблицы на самом деле не зависит напрямую от структуры физических таблиц базы данных, а определяется в ос-новном характеристиками виртуальных таблиц и запросов, используемых в приложении
Применимость
Типовое решение модуль таблицы во многом основывается на табличной структуре данных и потому допускает очевидное применение в ситуациях, где доступ к информации обеспечивается при посредничестве множеств записей. Структуре данных отводится центральная роль, так что методы обращения к данным в структуре должны быть прямолинейными и эффективными.
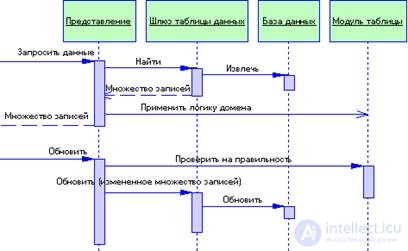
Рисунок 3.6 Схема взаимодействия слоев кода с модулем таблицы
Модуль таблицы, однако, не позволяет воспользоваться всей мощью объектного подхода к организации сложной бизнес-логики. Вам не удастся создать прямые связи от объекта к объекту, да и механизм полиморфизма действует в этих условиях не безукоризненно. Поэтому для реализации особо изощренной логики предпочтительнее модель предметной области. По существу, проблема сводится к поиску компромисса между способностью модели предметной области к эффективному отображению бизнес-логики и простотой интеграции кода приложения и реляционных структур данных, обеспечиваемой модулем таблицы.
Если объекты модели предметной области относительно точно отвечают таблицам базы данных, возможно, целесообразнее применить модель предметной области совместно с активной записью (Active Record). Модуль таблицы, однако, ведет себя лучше, чем комбинация модели предметной области и активной записи, если разные части приложения основаны на общей табличной структуре данных. Впрочем, в среде Java, например, модуль таблицы пока не пользуется популярностью, хотя с распространением модели множеств записей ситуация, возможно, и изменится.
Чаще всего образцы использования модуля таблицы приходится видеть в проектах на основе архитектуры Microsoft COM. В технологии СОМ (и .NET) множество записей представляет собой основное хранилище данных, с которыми оперирует приложение. Множества записей могут передаваться фафическим элементам управления для воспро- изведения информации на экране. Добротный механизм доступа к реляционным данным, представленным в виде множеств записей, реализован в семействе библиотек Microsoft ADO. В подобных случаях модуль таблицы позволяет описать бизнес-логику в хорошо структурированном виде.
Понравилась статья про паттерны организация бизнес-логики? Откомментируйте её Надеюсь, что теперь ты понял что такое паттерны организация бизнес-логики
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Объектно-ориентированное программирование ООП
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Perspective
Rub your eyes and look at what you are discussing: a WebApp and a Server that communicate across a network.
That is literally two separate applications with a network interface.
In fact you have just reinvented the Thick client. Just instead of installing it on Windows, and compiling it from C++ you are writing it in JavaScript and installing it in a browser tab.
What this means is that each application (the thick client, and the api server) both have need of a business logic layer.
Now if your server is written in javascript. You might be able to share some of that business logic. But you probably don’t want to. The business concerns of the backend are different to those of the front end, so aside from the data objects for communications, or some of the more general utilities their probably isn’t much worth sharing. Sharing introduces its own headaches, as both applications will want to head in their own directions.
Domain Logic
There is a balance between what can be done by the client and what can be done by the server.
- When its all in the server, the client is called a thin-client.
- When its all in the client, the client is just called an application, with maybe some networked services available
- When its balanced, the client is called a thick client.
If you are going for a thin client, the absolute minimum required information for presentation is given to the client a video stream would be ideal, and the raw inputs are passed back to the server.
If you are going for a complete local experience, then everything goes in the client. Only those things which cannot be done locally be that for secrecy, or some form shared service are kept in the server. Even better if the server isn’t even responsible for distributing the client.
If you are going for a thick client, its a matter of taste and circumstance.
- At the very least the client needs the logic for handling the UI. Which includes responding to input, formatting, and layout.
- At the very least the server has to have the Secret/compute intensive/server storage features.
- Every other feature has to be traded off on whether it makes more sense in the client, or in the server.
A good way to figure this out is to pick a range of client devices. How much ram, cpu, etc resource they have available. Everything from the smallest device you will support up to the beefiest device you expect a client to have.
- Everything that can be put on a client, and fits in the smallest device belongs in the client.
- Everything that can be put in a client, and can be handled by the powerful device easily, and by the least powerful device but just takes longer, has a compelling argument for being in the client.
- Everything that can be put in the client, and can only be handled by the more powerful devices has an argument for going into a pro version, or staying on the server (maybe both).
- Everything else, even if it can go in the client is obviously to taxing/secret/impossible for the clients device. It has to stay in the server.

