Требуется определить, где бурить новую скважину.
Описание проекта
В нашем распоряжении имеются пробы нефти в трёх регионах: в каждом 10 000 месторождений, где измерили качество нефти и объём её запасов. Построим модель машинного обучения, которая поможет определить регион, где добыча принесёт наибольшую прибыль. Проанализируем возможную прибыль и риски техникой Bootstrap.
Шаги для выбора локации:
- В избранном регионе ищут месторождения, для каждого определяют значения признаков;
- Строят модель и оценивают объём запасов;
- Выбирают месторождения с самым высокими оценками значений. Количество месторождений зависит от бюджета компании и стоимости разработки одной скважины;
- Прибыль равна суммарной прибыли отобранных месторождений.
Инструменты:
Pandas
sklearn
math
numpy
Seaborn
Matplotlib
SciPy
Bootstrap
машинное обучение
Кртакое описание проведённой работы:
Добывающей компании «ГлавРосГосНефть» нужно решить, где бурить новую скважину.
Собраны характеристики пробы нефти для скважин: качество нефти и объём её запасов по трем регионам. Характеристики для каждой скважины в регионе уже известны.
Построена модель для предсказания объёма запасов в новых скважинах.
Выбраны скважины с самыми высокими оценками значений.
Определены регионы с максимальной суммарной прибылью отобранных скважин.
Построена модель для определения региона, где добыча принесёт наибольшую прибыль. Проанализирована возможная прибыль и риски техникой Bootstrap.
Данные и выводы
По результату полученных данных мы определили доверительный интревал получения прибыли в 95%, ограничив вероятность убытка величиной менее 2,5%. И на основе этих данных смогли выбрать более перспективный регион для разработки 200 скважин.
Таким образом не смотря на сравнительно меньшие предсказания запасов сырья в 27.75 млн.баррелей (по сравнению с другими регионами), с величиной вероятного возникновения убытка в 1,1%, но с превышающей средней прибылью в 489.66 млн.рублей мы сдели выбор в сторону разработки 200 скважин во 2 регионе.
Если проект не открывается, его можно просмотреть по ссылке: Determine_where_to_drill_a_new_well
Учебные проекты программы обучения «Специалист по Data Science»
comparing_of_music_preferences_in_moscow_and_st_petersburg_based_on_yandex_music_data
- Сравнение Москвы и Петербурга окружено мифами. Например:
- Москва — мегаполис, подчинённый жёсткому ритму рабочей недели;
- Петербург — культурная столица, со своими вкусами.
На данных Яндекс.Музыки мы сравним поведение пользователей двух столиц.
Использованные инструменты:
- Python, pandas
borrowers_reliability_study
Описание проекта:
- Заказчик — кредитный отдел банка.
Входные данные от банка — статистика о платёжеспособности клиентов.
Результаты исследования будут учтены при построении модели кредитного скоринга — специальной системы,
которая оценивает способность потенциального заёмщика вернуть кредит банку.
Использованные инструменты:
- Python, pandas
study_of_advertisements_for_the_sale_of_apartments
Описание проекта:
- В вашем распоряжении данные сервиса Яндекc Недвижимость — архив объявлений о продаже квартир
в Санкт-Петербурге и соседних населённых пунктах за несколько лет.
Нужно научиться определять рыночную стоимость объектов недвижимости.
Ваша задача — установить параметры. Это позволит построить автоматизированную систему:
она отследит аномалии и мошенническую деятельность.
По каждой квартире на продажу доступны два вида данных.
Первые вписаны пользователем, вторые получены автоматически на основе картографических данных.
Например, расстояние до центра, аэропорта, ближайшего парка и водоёма.
Использованные инструменты:
- Python, pandas, matplotlib
determination_of_a_prospective_tariff_for_a_telecom_company
Описание проекта:
- Проект для компании «Мегалайн» — федерального оператора сотовой связи.
Клиентам предлагают два тарифных плана: «Смарт» и «Ультра».
Чтобы скорректировать рекламный бюджет, коммерческий департамент хочет понять, какой тариф приносит больше денег.
Предстоит сделать предварительный анализ тарифов на небольшой выборке клиентов.
В нашем распоряжении данные 500 пользователей «Мегалайна»:
кто они, откуда, каким тарифом пользуются, сколько звонков и сообщений каждый отправил за 2018 год.
Нужно проанализировать поведение клиентов и сделать вывод — какой тариф лучше.
Использованные инструменты:
- Python, pandas, numpy, scikit-learn, matplotlib
definition_of_a_promising_product_for_an_online_store
Описание проекта:
- Вы работаете в интернет-магазине «Стримчик», который продаёт по всему миру компьютерные игры.
Из открытых источников доступны исторические данные о продажах игр, оценки пользователей и экспертов,
жанры и платформы (например, Xbox или PlayStation). Вам нужно выявить определяющие успешность игры закономерности.
Это позволит сделать ставку на потенциально популярный продукт и спланировать рекламные кампании.
Перед вами данные до 2016 года. Представим, что сейчас декабрь 2016 г., и вы планируете кампанию на 2017-й.
Нужно отработать принцип работы с данными.
Неважно, прогнозируете ли вы продажи на 2017 год по данным 2016-го или же 2027-й — по данным 2026 года.
Использованные инструменты:
- Python, pandas, numpy, scikit-learn, matplotlib, seaborn
tariff_recommendation
Описание проекта:
- Оператор мобильной связи «Мегалайн» выяснил: многие клиенты пользуются архивными тарифами.
Они хотят построить систему, способную проанализировать поведение клиентов и
предложить пользователям новый тариф: «Смарт» или «Ультра».
В вашем распоряжении данные о поведении клиентов, которые уже перешли на эти тарифы.
Нужно построить модель для задачи классификации, которая выберет подходящий тариф.
Использованные инструменты:
- Python, pandas, scikit-learn, matplotlib
exodus_of_bank_customers
Описание проекта:
- Из «Бета-Банка» стали уходить клиенты. Каждый месяц. Немного, но заметно.
Банковские маркетологи посчитали: сохранять текущих клиентов дешевле, чем привлекать новых.
Нужно спрогнозировать, уйдёт клиент из банка в ближайшее время или нет.
Вам предоставлены исторические данные о поведении клиентов и расторжении договоров с банком.
Использованные инструменты:
- Python, pandas, numpy, scikit-learn, matplotlib
well_site_selection
Описание проекта:
- Допустим, вы работаете в добывающей компании «ГлавРосГосНефть». Нужно решить, где бурить новую скважину.
Вам предоставлены пробы нефти в трёх регионах: в каждом 10 000 месторождений, где измерили качество нефти и объём её запасов.
Постройте модель машинного обучения, которая поможет определить регион, где добыча принесёт наибольшую прибыль.
Проанализируйте возможную прибыль и риски техникой Bootstrap.
Использованные инструменты:
- Python, pandas, numpy, scikit-learn
recovery_of_gold_from_ore
Описание проекта:
- Подготовьте прототип модели машинного обучения для «Цифры».
Компания разрабатывает решения для эффективной работы промышленных предприятий.
Модель должна предсказать коэффициент восстановления золота из золотосодержащей руды.
Используйте данные с параметрами добычи и очистки.
Модель поможет оптимизировать производство, чтобы не запускать предприятие с убыточными характеристиками.
Использованные инструменты:
- Python, pandas, numpy, scikit-learn
protection_of_personal_data_of_clients_of_the_insurance_company
Описание проекта:
- Вам нужно защитить данные клиентов страховой компании «Хоть потоп».
Разработайте такой метод преобразования данных, чтобы по ним было сложно восстановить персональную информацию.
Обоснуйте корректность его работы.
Нужно защитить данные, чтобы при преобразовании качество моделей машинного обучения не ухудшилось.
Подбирать наилучшую модель не требуется.
Использованные инструменты:
- Python, pandas, numpy, scikit-learn
determination_of_the_cost_of_cars
Описание проекта:
-Сервис по продаже автомобилей с пробегом «Не бит, не крашен» разрабатывает приложение для привлечения новых клиентов.
В нём можно быстро узнать рыночную стоимость своего автомобиля.
В вашем распоряжении исторические данные: технические характеристики, комплектации и цены автомобилей.
Вам нужно построить модель для определения стоимости.
Использованные инструменты:
- Python, pandas, numpy, matplotlib, seaborn, scikit-learn, catboost, lightgbm, time
taxi_ orders_forecasting
Описание проекта:
- Компания «Чётенькое такси» собрала исторические данные о заказах такси в аэропортах.
Чтобы привлекать больше водителей в период пиковой нагрузки, нужно спрогнозировать количество заказов такси на следующий час.
Необходимо построить модель для такого предсказания.
Использованные инструменты: Python, pandas, numpy, matplotlib, statsmodels, time, scikit-learn, catboost
search_for_toxic_comments
Описание проекта:
- Интернет-магазин «Викишоп» запускает новый сервис.
Теперь пользователи могут редактировать и дополнять описания товаров, как в вики-сообществах.
То есть клиенты предлагают свои правки и комментируют изменения других.
Магазину нужен инструмент, который будет искать токсичные комментарии и отправлять их на модерацию.
Использованные инструменты: Python, pandas, numpy, nltk, time, re, scikit-learn, catboost
determining_the_age_of_buyers
Описание проекта:
- Сетевой супермаркет «Хлеб-Соль» внедряет систему компьютерного зрения для обработки фотографий покупателей.
Фотофиксация в прикассовой зоне поможет определять возраст клиентов, чтобы:- Анализировать покупки и предлагать товары, которые могут заинтересовать покупателей этой возрастной группы;
- Контролировать добросовестность кассиров при продаже алкоголя.
Использованные инструменты:
- Python, pandas, numpy, matplotlib, tensorflow, keras
forecasting_customer_churn_of_telecom_company
Описание проекта:
- Телекомуникационная компания хочет научиться прогнозировать отток клиентов.
Если выяснится, что пользователь планирует уйти, ему будут предложены промокоды и специальные условия.
Команда оператора собрала персональные данные о некоторых клиентах, информацию об их тарифах и договорах.
Использованные инструменты:
- Python, pandas, numpy, matplotlib, seaborn, phik, time, scikit-learn, catboost
eduflow_telecom_customer_churn_study_additional_exercise
Описание проекта:
- Исследование оттока клиентов Телеком компании:
необходимо выяснить связь величин ежемесячных платежей с отказом от обслуживания
Использованные инструменты:
- Python, pandas, numpy, matplotlib, seaborn
Contributors
Проекты Яндекс.Практикум специализация DataScience
Проект 1: Выбор региона для разработки новых нефтяных месторождений
Использовались: Catboost, Bootstrap, Pandas, Seaborn
Описание: Добывающей компании «ГлавРосГосНефть» нужно
решить, где бурить новую скважину.
- Собраны характеристики пробы нефти для скважин: качество нефти
и объём её запасов по трем регионам. Характеристики для каждой
скважины в регионе уже известны. - Построена модель для предсказания объёма запасов в новых скважинах.
- Выбраны скважины с самыми высокими оценками значений.
- Определены регионы с максимальной суммарной прибылью отобранных скважин.
- Построена модель для определения региона, где добыча принесёт наибольшую прибыль.
- Проанализирована возможная прибыль и риски техникой Bootstrap.
Проект 2: Подготовка прототипа модели для металлообрабатывающего предприятия
Использовались: Catboost, Pandas, Sklearn, Numpy, Seaborn, Matplotlib, SciPy
Описание: Компания разрабатывает решения для эффективной работы
золотодобывающей отрасли.
- Построена модель, предсказывающая коэффициент восстановления
золота из золотосодержащей руды. - Проанализированы данные с параметрами добычи и очистки.
- Построена и обучена модель, помогающая оптимизировать производство, чтобы
не запускать предприятие с убыточными характеристиками.
Проект 3: Определение возраста покупателя по фото (Computer Vision)
Использовались: Keras, CNN, ResNet50
Описание: Сетевой супермаркет внедряет систему компьютерного зрения для
обработки фотографий покупателей. Фотофиксация в прикассовой зоне поможет
определять возраст клиентов, чтобы:
- Анализировать покупки и предлагать товары, которые могут заинтересовать
покупателей этой возрастной группы; - Контролировать добросовестность кассиров при продаже алкоголя.
- Построена модель, которая по фотографии определит приблизительный возраст человека.
- Проанализирован набор фотографий людей с указанием возраста при
помощи компьютерного зрения с привлечением готовых нейронных
сетей и библиотеки Keras.
Проект 4 — Прогнозирование заказов такси (Временные ряды)
Использовались: StatsModels, LinearRegression, DecisionTreeRegressor,
RandomForestRegressor, GridSearchCV, TimeSeriesSplit
Описание: Проанализированы исторические данные о заказах такси в аэропортах.
- Спрогнозировано количество заказов такси на следующий час, чтобы привлекать больше водителей в период пиковой нагрузки.
- Построена модель для такого предсказания.
- Значение метрики RMSE на тестовой выборке меньше 48.
Проект 5 — Классификация комментариев (Машинное обучение для текстов)
Описание: Для запуска нового сервиса интернет-магазину нужен инструмент,
который будет искать токсичные комментарии и отправлять их на модерацию.
Пользователи могут редактировать и дополнять описания товаров,
как в вики-сообществах. То есть клиенты предлагают свои правки и комментируют изменения других.
- Обучена модель классифицировать комментарии на позитивные и негативные.
- Проанализирован набор данных с разметкой о токсичности правок.
- Построена модель со значением метрики качества F1 не меньше 0.75.
- К текстам и временным рядам применена техника feature engineering.
- Векторизированы тексты посредством word2vec.
Проект 6 — Предсказание цены автомобиля (Численные методы, Градиентный бустинг)
Использовались: Gradient Boosting, LightGBM, Catboost, MSE
Описание: Сервис по продаже автомобилей с пробегом
разрабатывает приложение для привлечения новых клиентов.
В нём можно быстро узнать рыночную стоимость своего автомобиля.
- Проанализированы данные: технические характеристики,
комплектации и цены автомобилей. - Построена модель для определения стоимости автомобиля с пробегом.
- Использованы численные методы, приближённые вычисления,
оценка сложности алгоритма, градиентный спуск.
Проект 7 — Отток клиентов банка (Обучение с учителем)
Использовались: One-Hot Encoding, StandardScaler, Upsampling, AUC-ROC,
F1, Precision, Recall, TP, TN, FP, FN, Confusion Matrix, GridSearchCV,
DecisionTreeClassifier, RandomForestClassifier, LogisticRegression
Описание: Из банка стали уходить клиенты каждый месяц.
- Спрогнозирована вероятность ухода клиента из банка в ближайшее время.
- Построена модель с предельно большим значением F1-меры с
последующей проверкой на тестовой выборке. Доведена метрика до 0.59. - Дополнительно измерен AUC-ROC, соотнесен с F1-мерой.
- Обучение с учителем. Работа с несбалансированными данными.
Проект 8 — Определение выгодного тарифа для телеком компании (Описательная статистика)
Использовались: Pandas, Scipy, Stats
Описание: Оператор мобильной связи выяснил: многие клиенты пользуются архивными тарифами.
- Проведен предварительный анализ использования тарифов на выборке клиентов,
проанализировано поведение клиентов при использовании услуг оператора и
рекомендованы оптимальные наборы услуг для пользователей. - Проверены гипотезы о различии выручки абонентов разных тарифов и
различии выручки абонентов из Москвы и других регионов. - Определен выгодный тарифный план для корректировки рекламного бюджета.
- Разработана система, способная проанализировать поведение клиентов и предложить
пользователям новый тариф. - Построена модель для задачи классификации, которая выберет подходящий тариф.
- Построена модель с максимально большим значением accuracy.
- Доля правильных ответов доведена до 0.75. Проверены accuracy на тестовой выборке.
Выбор региона для разработки новых нефтяных месторождений
Проект в рамках обучения на курсе Яндекс.Практикум — Data Science
В этом репозитории моё решение задания Машинное обучение в бизнесе
Описание проекта
Допустим, вы работаете в добывающей компании «ГлавРосГосНефть». Нужно решить, где бурить новую скважину.
Вам предоставлены пробы нефти в трёх регионах: в каждом 10 000 месторождений, где измерили качество нефти и объём её запасов. Постройте модель машинного обучения, которая поможет определить регион, где добыча принесёт наибольшую прибыль. Проанализируйте возможную прибыль и риски техникой Bootstrap.
Шаги для выбора локации:
- В избранном регионе ищут месторождения, для каждого определяют значения признаков;
- Строят модель и оценивают объём запасов;
- Выбирают месторождения с самым высокими оценками значений. Количество месторождений зависит от бюджета компании и стоимости разработки одной скважины;
- Прибыль равна суммарной прибыли отобранных месторождений.
| Название проекта | Сферы деятельности | Используемые навыки, инструменты и библиотеки | Задачи проекта |
|---|---|---|---|
| Выбор региона для разработки новых нефтяных месторождений | Услуги для бизнеса [b2b] (аутсорс консалтинг аудит), Отраслевые компании / Индустрия / Промышленность | Python, Pandas, sklearn, math, numpy, Seaborn, Matplotlib, SciPy, Bootstrap, машинное обучение | Решить в каком регионе добывать нефть. Построить модель машинного обучения, которая поможет определить регион, где добыча принесет наибольшую прибыль с наименьшим риском убытков. |
Repo owner:
*Mikhail Bedarev
- Contacts:
- mikebedarev@gmail.com
- @CmonYeah (telegram)
Email / Online CV / GitHub / Telegram / LinkedIn / Kaggle
Нацеленный на решение проблем бизнеса руководитель группы разработчиков. Одиннадцать лет опыта в решении комплексных задач, требующих одновременного участия многих квалифицированных специалистов. С азартом берусь за выполнение задач с неочевидным решением. Внедрил в производство ряд инновационных технических решений позволивших снизить издержки, выиграть несколько тендеров и вывести продукцию предприятия на международный рынок. Являюсь автором двух патентов. Занимаюсь анализом сложных технологических проблем и поиском способов принести пользу компании.
Опыт работы
| Компания | Должность | Достижения | Период: с | Период: по |
|---|---|---|---|---|
| Nimbler | Data Scientist | — Разработал каталог категорий для приложения контроля трат. — Организовал сбор и разметку датасета для задачи классификации на платформе toloka.ai с учётом ограничений по бюджету. — Провёл анализ наиболее эффективных моделей категоризации и кластеризации. |
08.2022 | Н.В. |
| АО “НПО “КРИПТЕН” | Начальник R&D | — Вместе с командой разработали и внедрили в производство ряд новых средств защиты спец-документов. — Запатентовали несколько уникальных технических решений в области спец. полиграфии. — Ведём постоянный анализ технологических процессов и занимаемся их совершенствованием. — Занимаюсь внедрением систем автоматического контроля качества выпускаемой продукции, сбора статистики и верификации подлинности с применением машинного обучения. |
05.2018 | Н.В. |
Высшее образование
| ВУЗ | Направление | Специальность | Форма обучения |
|---|---|---|---|
| МГСУ | Строительство | Промышленное и гражданское строительство | дистанционная |
| РУДН | Лингвистика | Референт-переводчик с испанского языка (с отл.) | очная |
| РУДН | Химия | Магистр органической химии (с отл.) | очная |
Языки
Русский — родной, English — B2, Spanish — B1
Курсы
| Название | Форма обучения | Статус/Сертификат |
|---|---|---|
| Яндекс.Практикум DataScience+ | Дистанционная | В процессе |
Проекты Nimbler app
| Название проекта | Описание | Стек |
|---|---|---|
| Обзор базовых моделей ML | Осмотр базовых алгоритмов машинного обучения в задаче мультиклассовой классификации. Оценка эффективности данных моделей. Сравнение методов векторизации BoW и TF-IDF. | Jupyter Notebook, Python — pandas, numpy, pandas_profiling, seaborn, matplotlib, nltk, re, sklearn, lightgbm, keras, tensorflow |
| Обзор моделей кластеризации | Осмотр некоторых алгоритмов машинного обучения в задаче кластеризации. Оценка эффективности данных моделей. | Jupyter Notebook, Python — pandas, numpy, pandas_profiling, seaborn, matplotlib, tqdm, time, nltk, re, sklearn, scipy |
Проекты Practicum DS+
Аналитика
| Название проекта | Описание | Стек |
|---|---|---|
| Яндекс.Музыка | Сравнение предпочтений пользователей Яндекс.Музыки из Москвы и Санкт-Петербурга в зависимости от времени (утро и вечер) и дня недели (понедельник, среда, пятница) | Jupyter Notebook, Python — pandas |
| Исследование надёжности заёмщиков | Проведение исследования зависимости риска возникновения задолженности от различных факторов. | Jupyter Notebook, Python — pandas, numpy, seaborn, pymorphy2, os, collections |
| Исследование объявлений о продаже квартир | В нашем распоряжении данные сервиса Яндекс.Недвижимость — архив объявлений о продаже квартир в Санкт-Петербурге и соседних населённых пунктах за несколько лет. Нужно научиться определять рыночную стоимость объектов недвижимости. | Jupyter Notebook, Python — pandas, numpy, seaborn, os, matplotlib |
| Исследование данных о российском кинопрокате | Заказчик исследования — Министерство культуры Российской Федерации. Изучим рынок российского кинопроката, уделим внимание фильмам, которые получили государственную поддержку. | Jupyter Notebook, Python — pandas, numpy, seaborn, os, matplotlib |
Статистика
| Название проекта | Описание | Стек |
|---|---|---|
| Определение перспективного тарифа для телеком-компании | Проведём аналитику для компании «Мегалайн» — федерального оператора сотовой связи. Клиентам предлагают два тарифных плана: «Смарт» и «Ультра». Чтобы скорректировать рекламный бюджет, коммерческий департамент хочет понять, какой тариф приносит больше денег. | Jupyter Notebook, Python — pandas, numpy, seaborn, os, matplotlib, math, scipy |
Классическое машинное обучение
| Название проекта | Описание | Стек |
|---|---|---|
| Рекомендация тарифов | Оператор мобильной связи «Мегалайн» выяснил: многие клиенты пользуются архивными тарифами. Они хотят построить систему, способную проанализировать поведение клиентов и предложить пользователям новый тариф: «Смарт» или «Ультра». | Jupyter Notebook, Python — pandas, numpy, seaborn, os, tqdm, sklearn |
| Отток клиентов | Из «Бета-Банка» стали уходить клиенты. Каждый месяц. Немного, но заметно. Банковские маркетологи посчитали: сохранять текущих клиентов дешевле, чем привлекать новых. Нужно спрогнозировать, уйдёт клиент из банка в ближайшее время или нет. | Jupyter Notebook, Python — pandas, numpy, seaborn, os, tqdm, matplotlib, sklearn |
| Выбор локации для скважины | Мы работаем в добывающей компании «ГлавРосГосНефть». Нужно решить, где бурить новую скважину. | Jupyter Notebook, Python — pandas, numpy, seaborn, os, tqdm, matplotlib, pandas_profiling, sklearn |
| Прогнозирование оттока клиентов в сети отелей «Как в гостях» | Заказчик исследования — сеть отелей «Как в гостях». Чтобы привлечь клиентов, сеть отелей добавила на свой сайт возможность забронировать номер без предоплаты. Однако если клиент отменяет бронирование, то компания терпит убытки. Чтобы решить эту проблему, нам нужно разработать систему, которая предсказывает отказ от брони. Если модель покажет, что бронь будет отменена, то клиенту предлагается внести депозит. | Jupyter Notebook, Python — pandas, numpy, seaborn, os, tqdm, matplotlib, pandas_profiling, statsmodels, sklearn |
| Предсказание стоимости жилья в Калифорнии | В проекте нам нужно обучить модель линейной регрессии на данных о жилье в Калифорнии в 1990 году используя фреймворк Spark для распределённых вычислений. | Jupyter Notebook, Python — pandas, numpy, pyspark |
| Защита персональных данных клиентов | Нам нужно защитить данные клиентов страховой компании «Хоть потоп». Разработаем такой метод преобразования данных, чтобы по ним было сложно восстановить персональную информацию. Обоснуем корректность его работы. | Jupyter Notebook, Python — pandas, numpy, os, pandas_profiling, sklearn |
| Определение стоимости автомобилей | Сервис по продаже автомобилей с пробегом «Не бит, не крашен» разрабатывает приложение для привлечения новых клиентов. Нам нужно построить модель для определения стоимости. | Jupyter Notebook, Python — pandas, numpy, os, seaborn, pandas_profiling, sklearn, lightgbm, catboost |
| Оценка риска ДТП | Нужно создать систему для каршеринговой компании, которая могла бы оценить риск ДТП по совокупности факторов. Как только водитель забронировал автомобиль, сел за руль и выбрал маршрут, система должна оценить уровень риска. Если уровень риска высок, водитель увидит предупреждение и рекомендации по маршруту. | Jupyter Notebook, Python — pandas, numpy, plotly, matplotlib, pandas_profiling, snap, sklearn, sqlalchemy, lightgbm, catboost |
Временные ряды
| Название проекта | Описание | Стек |
|---|---|---|
| Прогнозирование заказов такси | Компания «Чётенькое такси» собрала исторические данные о заказах такси в аэропортах. Чтобы привлекать больше водителей в период пиковой нагрузки, нужно спрогнозировать количество заказов такси на следующий час. | Jupyter Notebook, Python — os, pandas, numpy, plotly, matplotlib, sklearn, statsmodels, lightgbm |
Нейронные сети
| Название проекта | Описание | Стек |
|---|---|---|
| Прогнозирование температуры звезды | Нам пришла задача от обсерватории «Небо на ладони»: придумать, как с помощью нейросети определять температуру на поверхности обнаруженных звёзд. | Jupyter Notebook, Python — os, pandas, numpy, plotly, tqdm, pandas_profiling, sklearn, pytorch |
NLP
| Название проекта | Описание | Стек |
|---|---|---|
| Мастерская. KPMI.ru | Тест «Ключи персонального мастерства» предназначен для определения индивидуального поведенческого стиля личности. Является оригинальной отечественной разработкой на базе широко известного типологического опросника Майер-Бриггс. С помощью моделей классического машинного обучения попробуем улучшить качество предсказания сферы деятельности в которой человек сможет максимально самореализоваться. | Jupyter Notebook, Python — os, pandas, numpy, matplotlib, seaborn, pymorphy2, statsmodels, sys, re, nltk, collections, symspellpy, sklearn |
| Проект для «Викишоп» с BERT | Интернет-магазин «Викишоп» запускает новый сервис. Теперь пользователи могут редактировать и дополнять описания товаров, как в вики-сообществах. Магазину нужен инструмент, который будет искать токсичные комментарии и отправлять их на модерацию. Обучим модель классифицировать комментарии на позитивные и негативные. | Jupyter Notebook, Python — os, pandas, pandas_profiling, numpy, matplotlib, seaborn, re, nltk, sklearn, pytorch, transformers, tqdm, pickle |
CV
| Название проекта | Описание | Стек |
|---|---|---|
| Определение возраста покупателей | Сетевой супермаркет «Хлеб-Соль» внедряет систему компьютерного зрения для обработки фотографий покупателей. Построим модель, которая по фотографии определит приблизительный возраст человека. | Jupyter Notebook, Python — pandas, numpy, matplotlib, plotly, keras |
| Поиск фото “Со смыслом” | В фотохостинге для профессиональных фотографов «Со Смыслом» (“With Sense”) пользователи размещают свои фотографии и сопровождают их полным описанием. Разработаем демонстрационную версию поиска изображений по запросу. | Jupyter Notebook, Python — pandas, numpy, matplotlib, pathlib, pickle, re, nltk, PIL, keras, tensorflow, tqdm, sklearn, sentence_transformers, glob |
文库首页 开发技术其它ML_Oil_company_predict:ML模型训练和油井收入预测。 引导程序

共5个文件
csv:3个
ipynb:1个
md:1个
需积分: 47
254 浏览量
2021-03-06
19:19:45
上传
评论
收藏 11.65MB ZIP 举报
![]() 身份认证 购VIP最低享 7 折!
身份认证 购VIP最低享 7 折! ![]()
![]() 领优惠券(最高得80元)
领优惠券(最高得80元)
![]()
ML_Oil_company_predict
ML模型训练和油井收入预测。
Описаниепроекта
Допустим,мыработаемвдобывающейкомпании«ГлавРосГосНефть»。 Нужнорешить,гдебуритьновуюскважину。 Вампредоставленыпробынефтивтрёхрегионах:10 000месторождений,гдеизмериликачествонефти。 Постройтемодельмашинногообучения,котораяпоможетопределитьрегион,гдедобычапринесётнаиб。。 引导程序。 标记文字: Строятмодельиоцениваютобъёмзапасов; Выбираютместорожденияссамымвы
Решение задачи принятия решениявыполнено на сайте www.matburo.ru Переходите на сайт, смотрите больше примеров или закажите свою работу https://www.matburo.ru/ex_emm.php?p1=emmdr
©МатБюро. Решение задач по математике, экономике, программированию
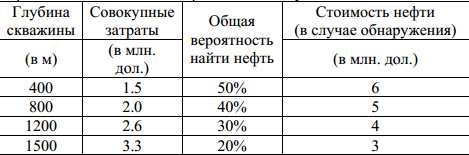
Пример решения задачи с помощью дерева решений
Компания «Большая
нефть» хочет знать, стоит ли бурить нефтяную скважину на одном из
участков, купленных ранее в перспективном месте. Бурение, проведенное на
множестве соседних участков, показало, что перспективы не так уж хороши.
Вероятность найти нефть на глубине не больше 400 м составляет около 50%. При
этом стоимость бурения составит $1.5 млн., а стоимость нефти, за вычетом всех
расходов, кроме расходов на бурение, составит $6 млн. Если нефть не найдена на
малой глубине, не исключена возможность найти ее при более глубоком бурении.
Расходы на бурение, вероятность найти нефть и приведенная стоимость нефти для
этих случаев даны в таблице.
a.
Постройте дерево решений, показывающее последовательные решения о
разработке скважины, которые должна принять компания «Большая нефть».
На какую среднюю прибыль компания может рассчитывать?
b.
Скважину какой глубины нужно быть готовыми пробурить? (Стоит ли остановиться
при достижении определенной глубины, или бурить до предельной глубины?)
c.
Какова вероятность найти нефть при бурении (при необходимости) до
выбранной вами предельной глубины? Какова полная вероятность найти нефть при
готовности бурить до 1500 м?
Решение задачипринятия решениявыполнено на сайте www.matburo.ru Переходите на сайт, смотрите больше примеров или закажите свою работу https://www.matburo.ru/ex_emm.php?p1=emmdr
©МатБюро. Решение задач по
математике,
экономике,
программированию
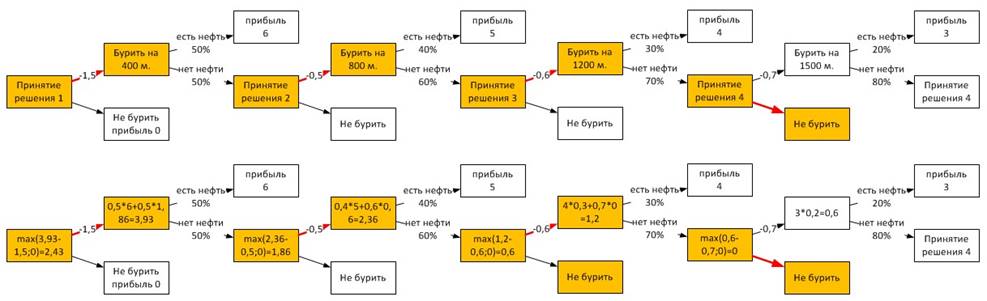
Решение. a.
дерево решений

Находим по дереву среднюю прибыль.
Решение задачипринятия решениявыполнено на сайте www.matburo.ru Переходите на сайт, смотрите больше примеров или закажите свою работу https://www.matburo.ru/ex_emm.php?p1=emmdr
©МатБюро. Решение задач по
математике,
экономике,
программированию
Решение задачи принятия решениявыполнено на сайте www.matburo.ru Переходите на сайт, смотрите больше примеров или закажите свою работу https://www.matburo.ru/ex_emm.php?p1=emmdr
©МатБюро. Решение задач по математике, экономике, программированию
Средняя ожидаемая
прибыль = 2,43.
b. Скважину какой
глубины нужно быть готовыми пробурить? (Стоит ли остановиться при достижении
определенной глубины, или бурить до предельной глубины?)
1200 м. – предел.
Бурить дальше не
выгодно.
Так как ожидаемый
прирост прибыли = 3*0,2=0,6, а затраты -0,7.
0,6-0,7 = -0,1.
Лучше выбрать «не
бурить», если на глубине 1200 нет нефти.
До глубины 1200 (если не
нашли на глубине 400 или 800) выгоднее копать дальше.
c. Какова вероятность
найти нефть при бурении (при необходимости) до выбранной вами предельной
глубины? Какова полная вероятность найти нефть при готовности бурить до 1500 м?
Вероятность найти нефть на глубине 1200: 0,5+0,5(0,4+0,6(0,3)) = 0,79
Вероятность найти нефть на глубине 1500:
0,5+0,5(0,4+0,6(0,3+0,7(0,2)))
= 0,832
4



