Improve Article
Save Article
Improve Article
Save Article
In this article, we will get into detail about the three-tier client-server architecture. The most common type of multi-tier architecture in distributed systems is a three-tier client-server architecture. In this architecture, the entire application is organized into three computing tiers
- Presentation tier
- Application tier
- Data-tier
The major benefit of the three tiers in client-server architecture is that these tiers are developed and maintained independently and this would not impact the other tiers in case of any modification. It allows for better performance and even more scalability in architecture can be made as with the increasing demand, more servers can be added.
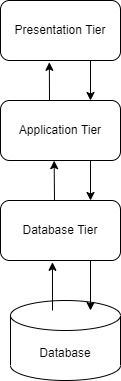
Three-tier client-server architecture in a distributed system:
- Presentation Tier: It is the user interface and topmost tier in the architecture. Its purpose is to take request from the client and displays information to the client. It communicates with other tiers using a web browser as it gives output on the browser. If we talk about Web-based tiers then these are developed using languages like- HTML, CSS, JavaScript.
- Application Tier: It is the middle tier of the architecture also known as the logic tier as the information/request gathered through the presentation tier is processed in detail here. It also interacts with the server that stores the data. It processes the client’s request, formats, it and sends it back to the client. It is developed using languages like- Python, Java, PHP, etc.
- Data Tier: It is the last tier of the architecture also known as the Database Tier. It is used to store the processed information so that it can be retrieved later on when required. It consists of Database Servers like- Oracle, MySQL, DB2, etc. The communication between the Presentation Tier and Data-Tier is done using middle-tier i.e. Application Tier.
Advantages:
- Logical separation is maintained between Presentation Tier, Application Tier, and Database Tier.
- Enhancement of Performance as the task is divided on multiple machines in distributed machines and moreover, each tier is independent of other tiers.
- Increasing demand for adding more servers can also be handled in the architecture as tiers can be scaled independently.
- Developers are independent to update the technology of one tier as it would not impact the other tiers.
- Reliability is improved with the independence of the tiers as issues of one tier would not affect the other ones.
- Programmers can easily maintain the database, presentation code, and business/application logic separately. If any change is required in business/application logic then it does not impact the presentation code and codebase.
- Load is balanced as the presentation tier task is separated from the server of the data tier.
- Security is improved as the client cannot communicate directly with Database Tier. Moreover, the data is validated at Application Tier before passing to Database Tier.
- The integrity of data is maintained.
- Provision of deployment to a variety of databases rather than restraining yourself to one particular technology.
Disadvantages:
- The Presentation Tier cannot communicate directly with Database Tier.
- Complexity also increases with the increase in tiers in architecture.
- There is an increase in the number of resources as codebase, presentation code, and application code need to be maintained separately.
5.1.5. Многоуровневый «клиент-сервер»
Многоуровневая архитектура клиент-сервер (Multitier architecture) – разновидность архитектуры клиент-сервер, в которой функция обработки данных вынесена на один или несколько отдельных серверов [15]. Это позволяет разделить функции хранения, обработки и представления данных для более эффективного использования возможностей серверов и клиентов.
Среди многоуровневой архитектуры клиент-сервер наиболее распространена трехуровневая архитектура (трехзвенная архитектура, three-tier), предполагающая наличие следующих компонентов приложения: клиентское приложение (обычно говорят «тонкий клиент» или терминал), подключенное к серверу приложений, который в свою очередь подключен к серверу базы данных [14, 17].
Схематически такую архитектуру можно представить, как показано на рис. 5.4.
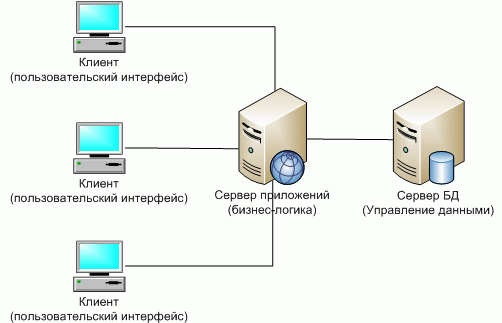
Рис.
5.4.
Представление многоуровневой архитектуры «клиент-сервер»
- Терминал – это интерфейсный (обычно графический) компонент, который представляет первый уровень, собственно приложение для конечного пользователя. Первый уровень не должен иметь прямых связей с базой данных (по требованиям безопасности), быть нагруженным основной бизнес-логикой (по требованиям масштабируемости) и хранить состояние приложения (по требованиям надежности). На первый уровень может быть вынесена и обычно выносится простейшая бизнес-логика: интерфейс авторизации, алгоритмы шифрования, проверка вводимых значений на допустимость и соответствие формату, несложные операции (сортировка, группировка, подсчет значений) с данными, уже загруженными на терминал.
- Сервер приложений располагается на втором уровне. На втором уровне сосредоточена большая часть бизнес-логики. Вне его остаются фрагменты, экспортируемые на терминалы, а также погруженные в третий уровень хранимые процедуры и триггеры.
- Сервер базы данных обеспечивает хранение данных и выносится на третий уровень. Обычно это стандартная реляционная или объектно-ориентированная СУБД. Если третий уровень представляет собой базу данных вместе с хранимыми процедурами, триггерами и схемой, описывающей приложение в терминах реляционной модели, то второй уровень строится как программный интерфейс, связывающий клиентские компоненты с прикладной логикой базы данных.
В простейшей конфигурации физически сервер приложений может быть совмещен с сервером базы данных на одном компьютере, к которому по сети подключается один или несколько терминалов.
В «правильной» (с точки зрения безопасности, надежности, масштабирования) конфигурации сервер базы данных находится на выделенном компьютере (или кластере), к которому по сети подключены один или несколько серверов приложений, к которым, в свою очередь, по сети подключаются терминалы.
Плюсами данной архитектуры являются [12, 14, 16, 17]:
- клиентское ПО не нуждается в администрировании;
- масштабируемость;
- конфигурируемость – изолированность уровней друг от друга позволяет быстро и простыми средствами переконфигурировать систему при возникновении сбоев или при плановом обслуживании на одном из уровней;
- высокая безопасность;
- высокая надежность;
- низкие требования к скорости канала (сети) между терминалами и сервером приложений;
- низкие требования к производительности и техническим характеристикам терминалов, как следствие снижение их стоимости.
Минусы [12, 14, 16, 17]:
- растет сложность серверной части и, как следствие, затраты на администрирование и обслуживание;
- более высокая сложность создания приложений;
- сложнее в разворачивании и администрировании;
- высокие требования к производительности серверов приложений и сервера базы данных, а, значит, и высокая стоимость серверного оборудования;
- высокие требования к скорости канала (сети) между сервером базы данных и серверами приложений.
Некоторые авторы (например, Мартин Фаулер [18]) представляют многозвенную архитектуру (трехзвенную) в виде пяти уровней (рис. 5.5):
- Представление;
- Уровень представления;
- Уровень логики;
- Уровень данных;
- Данные.
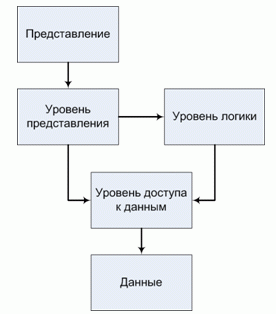
Рис.
5.5.
Пять уровней многозвенной архитектуры «клиент-сервер»
К представлению относится вся информация, непосредственно отображаемая пользователю: сгенерированные html-страницы, таблицы стилей, изображения.
Уровень представления охватывает все, что имеет отношение к общению пользователя с системой. К главным функциям слоя представления относятся отображение информации и интерпретация вводимых пользователем команд с преобразованием их в соответствующие операции в контексте логики и данных.
Уровень логики содержит основные функции системы, предназначенные для достижения поставленной перед ним цели. К таким функциям относятся вычисления на основе вводимых и хранимых данных, проверка всех элементов данных и обработка команд, поступающих от слоя представления, а также передача информации уровню данных.
Уровень доступа к данным – это подмножество функций, обеспечивающих взаимодействие со сторонними системами, которые выполняют задания в интересах приложения.
Данные системы обычно хранятся в базе данных.
5.1.6. Архитектура распределенных систем
Такой тип систем является более сложным с точки зрения организации системы. Суть распределенной системы заключается в том, чтобы хранить локальные копии важных данных [19].
Схематически такую архитектуру можно представить, как показано на рис. 5.6.
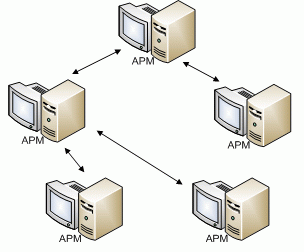
Рис.
5.6.
Архитектура распределенных систем
Более 95 % данных, используемых в управлении предприятием, могут быть размещены на одном персональном компьютере, обеспечив возможность его независимой работы [16]. Поток исправлений и дополнений, создаваемый на этом компьютере, ничтожен по сравнению с объемом данных, используемых при этом. Поэтому если хранить непрерывно используемые данные на самих компьютерах, и организовать обмен между ними исправлениями и дополнениями к хранящимся данным, то суммарный передаваемый трафик резко снизится. Это позволяет понизить требования к каналам связи между компьютерами и чаще использовать асинхронную связь, и благодаря этому создавать надежно функционирующие распределенные информационные системы, использующие для связи отдельных элементов неустойчивую связь типа Интернета, мобильную связь, коммерческие спутниковые каналы. А минимизация трафика между элементами сделает вполне доступной стоимость эксплуатации такой связи. Конечно, реализация такой системы не элементарна, и требует решения ряда проблем, одна из которых своевременная синхронизация данных.
Каждый АРМ независим, содержит только ту информацию, с которой должен работать, а актуальность данных во всей системе обеспечивается благодаря непрерывному обмену сообщениями с другими АРМами. Обмен сообщениями между АРМами может быть реализован различными способами, от отправки данных по электронной почте до передачи данных по сетям.
Еще одним из преимуществ такой схемы эксплуатации и архитектуры системы, является обеспечение возможности персональной ответственности за сохранность данных. Так как данные, доступные на конкретном рабочем месте, находятся только на этом компьютере, при использовании средств шифрования и личных аппаратных ключей исключается доступ к данным посторонних, в том числе и IT администраторов.
Такая архитектура системы также позволяет организовать распределенные вычисления между клиентскими машинами. Например, расчет какой-либо задачи, требующей больших вычислений, можно распределить между соседними АРМами благодаря тому, что они, как правило, обладают одной информацией в своих БД и, таким образом, добиться максимальной производительности системы.
Распределенные системы с репликацией
Данными между различными рабочими станциями и централизованным хранилищем данных, передаются репликацией [19] (рис. 5.7). При вводе информации на рабочих станциях – данные также записываются в локальную базу данных, а лишь затем синхронизируются.
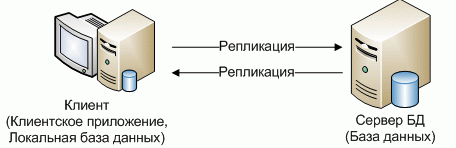
Рис.
5.7.
Архитектура распределенных систем с репликацией
Распределенные системы с элементами удаленного исполнения
Существуют определенные особенности, которые невозможно качественно реализовать на обычной распределенной системе репликативного типа. К этим особенностям можно отнести [19]:
- использование данных из сущностей, которые хранятся на удаленном сервере (узле);
- использование данных из сущностей, хранящихся на разных серверах (узлах) частично;
- использование обособленного функционала, на выделенном сервере (узле).
У каждого из описанных типов используется общий принцип: программа клиент или обращается к выделенному (удаленному) серверу непосредственно или обращается к локальной базе, которая инкапсулирует в себе обращение к удаленному серверу (рис. 5.8).
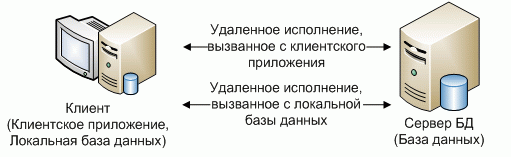
Рис.
5.8.
Архитектура распределенных систем с удаленным исполнением
Клиент — серверная архитектура (Client-Server Architecture)
Клиент — сервер — вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг, называемыми серверами, и заказчиками услуг, называемыми клиентами. Фактически клиент и сервер — это программное обеспечение. Обычно эти программы расположены на разных вычислительных машинах и взаимодействуют между собой через вычислительную сеть посредством сетевых протоколов, но они могут быть расположены также и на одной машине. Программы-серверы ожидают от клиентских программ запросы и предоставляют им свои ресурсы в виде:
- данных (например, загрузка файлов посредством HTTP, FTP, BitTorrent, потоковое мультимедиа или работа с базами данных);
- сервисных функций (например, работа с электронной почтой, общение посредством систем мгновенного обмена сообщениями или просмотр web-страниц во всемирной паутине).
Поскольку одна программа-сервер может выполнять запросы от множества программ-клиентов, ее размещают на специально выделенной вычислительной машине, настроенной особым образом, как правило, совместно с другими программами-серверами, поэтому производительность этой машины должна быть высокой. Из-за особой роли такой машины в сети, специфики ее оборудования и программного обеспечения, её также называют сервером, а машины, выполняющие клиентские программы, соответственно, клиентами.
Архитектуру «клиент-сервер» принято разделять на три класса: одно-, двух- и трехуровневую. Однако, нельзя сказать, что в вопросе о таком разделении в сообществе ИТ-специалистов существует полный консенсус. Многие называют одноуровневую архитектуру двухуровневой и наоборот, то же можно сказать о соотношении двух- и трёхуровневой архитектур.
Одноуровневая архитектура (1-Tier)
Одноуровневая архитектура «клиент-сервер» (1-Tier) — такая, где все прикладные программы рассредоточены по рабочим станциям, которые обращаются к общему серверу баз данных или к общему файловому серверу. Никаких прикладных программ сервер при этом не исполняет, только предоставляет данные.
В целом, такая архитектура очень надежна, однако, ей сложно управлять, поскольку в каждой рабочей станции данные будут присутствовать в разных вариантах. Поэтому возникает проблема их синхронизации на отдельных машинах. В общем, как можно видеть из рисунка, в этой архитектуре просматривается еще один уровень — базы данных, что дает повод во многих случаях называть её двухуровневой.
Двухуровневая архитектура (2-Tier)
К двухуровневой архитектуре «клиент-сервер» следует относить такую, в которой прикладные программы сосредоточены на сервере приложений (Application Server), например, сервере 1С или сервере CRM, а в рабочих станциях находятся программы-клиенты, которые предоставляют для пользователей интерфейс для работы с приложениями на общем сервере.
Такая архитектура представляется наиболее логичной для архитектуры «клиент-сервер». В ней, однако, можно выделить два варианта. Когда общие данные хранятся на сервере, а логика их обработки и бизнес-данные хранятся на клиентской машине, то такая архитектура носит название “fat client thin server” (толстый клиент, тонкий сервер). Когда не только данные, но и логика их обработки и бизнес-данные хранятся на сервере, то это называется “thin client fat server” (тонкий клиент, толстый сервер). Такая архитектура послужила прообразом облачных вычислений (Cloud Computing).
Трехуровневая архитектура (3-Tier)
В трехуровневой архитектуре сервер баз данных, файловый сервер и другие представляют собой отдельный уровень, результаты работы которого использует сервер приложений. Логика данных и бизнес-логика находятся в сервере приложений. Все обращения клиентов к базе данных происходят через промежуточное программное обеспечение (middleware), которое находится на сервере приложений. Вследствие этого, повышается гибкость работы и производительность.

Многоуровневая архитектура (N-Tier)
В отдельный класс архитектуры «клиент-сервер» можно вынести многоуровневую архитектуру, в которой несколько серверов приложений используют результаты работы друг друга, а также данные от различных серверов баз данных, файловых серверов и других видов серверов.
По сути, предыдущий вариант, трехуровневая архитектура — не более, чем частный случай многоуровневой архитектуры.
Преимуществом многоуровневой архитектуры является гибкость предоставления услуг, которые могут являться комбинацией работы различных приложений серверов разных уровней и элементов этих приложений.
Очевидным недостатком является сложность, многокомпонентность такой архитектуры.
Характеристики архитектуры «клиент-сервер»
- Асимметричность протоколов. Между клиентами и сервером существуют отношения «один ко многим». Инициатором диалога с сервером обычно является клиент.
- Инкапсуляция услуг. После получения запроса на услугу от клиента, сервер решает, как должна быть выполнена данная услуга. Модификация («апгрейд») сервера может производиться без влияния на работу клиентов, поскольку это не влияет на опубликованный интерфейс взаимодействия между ними. Иными словами, максимум, что может при этом почувствовать пользователь — незначительная задержка отклика сервера в течение небольшого времени апгрейда.
- Целостность. Программы и общие данные для сервера управляются централизованно, что снижает стоимость обслуживания и защищает целостность данных. В то же время, данные клиентов остаются персонифицированными и независимыми.
- Местная прозрачность. Сервер — это программный процесс, который может исполняться на той же машине, что и клиент, либо на другой машине, подключенной по сети. Программное обеспечение «клиент-сервер» обычно скрывает местоположение сервера от клиентов, перенаправляя запрос на услуги через сеть.
- Обмен на основе сообщений. Клиенты и сервер являются нежёстко связанными («loosely-coupled») процессами, которые обмениваются сообщениями: запросами на услуги и ответами на них.
- Модульный дизайн, способный к расширению. Модульный дизайн программной платформы «клиент-сервер» придаёт ей устойчивость к отказам, то есть, отказ в каком-то модуле не вызывает отказа всего приложения. В такой системе, один или больше серверов могут отказать без остановки всей системы в целом, до тех пор, пока услуги отказавшего сервера могут быть предоставлены с резервного сервера. Другое преимущество модульности в том, что приложение «клиент-сервер» может автоматически реагировать на повышение или понижение нагрузки на систему, путем добавления или отключения услуг или серверов.
- Независимость от платформы. Идеальное приложение «клиент-сервер» не зависит от платформ оборудования или операционной системы. Клиенты и серверы могут развертываться на различных аппаратных платформах и разных операционных системах.
- Масштабируемость. Системы «клиент-сервер» могут масштабироваться как горизонтально (по числу серверов и клиентов), так и вертикально (по производительности и спектру услуг).
- Разделение функционала. Система «клиент-сервер» — это соотношение между процессами, работающими на одной или на разных машинах. Сервер — это процесс предоставления услуг. Клиент — это потребитель услуг.
- Общее использование ресурсов. Один сервер может предоставлять услуги множеству клиентов одновременно, и регулировать их доступ к совместно используемым ресурсам.
Практические применения архитектуры «клиент-сервер»
Архитектура «клиент-сервер» — один из основных принципов работы сети Интернет. Любой веб-сайт, или приложение в Интернет работает на сервере, а его пользователи являются клиентами. Социальные сети (Фейсбук, ВК и пр.), сайты электронной коммерции (Amazon, Озон и др.) , мобильные приложения (Instagram и т.д.), устройства Интернета вещей (умные колонки или смарт-часы) работают на основе клиент-серверной архитектуры.
Хорошим примером работы системы «клиент-сервер» является автомобильный навигатор. Приложение навигации на сервере собирает данные с многих смартфонов пользователей, на которых установлены клиенты приложения. Кроме того, приложение навигации использует ещё и данные с сервера базы данных — геоинформационной системы, который предоставляет данные, например, о текущих ремонтах дорог, о появлении новых дорог и пр. Данные со многих клиентов (местоположение, скорость) обрабатывается сервером навигации и выдаётся на смартфоны пользователей в виде информации о средней скорости движения по тому или иному участку маршрута.
Практически любая корпоративная сеть или ИТ-система предприятия, как правило, строится по архитектуре «клиент-сервер». В небольших сетях (3-5 компьютеров в компании) функции сервера может выполнять один из рабочих компьютеров. Если число машин в организации более 10, то лучше сделать выделенный сервер (почтовый сервер, приложений, баз данных и пр.), который будет заниматься обслуживанием клиентов — компьютеров и телефонов сотрудников организации.
В домашних сетях архитектура «клиент-сервер» тоже используется довольно часто. Например, в домашнюю сеть могут быть объединены компьютеры членов семьи, один из которых выполняет функции сервера. В домашнюю сеть также могут быть включены такие устройства, как умные колонки, умные домашние устройства (пылесосы-роботы, фотоаппараты, DVD-плееры и пр.), а также «умные» счётчики (вода, электричество) и т.д. Тогда в системе управления сервера, будут видны все параметры, данные и медиа файлы (музыка, видео, фото), а также «умные устройства».
В настоящее время можно встретить термин Serverless Architecture, т.н. «бессерверная архитектура». Однако, по сути, она представляет собой процесс получения функций сервера в виде облачной услуги. То есть, серверы в облаке тоже есть, но для конечного пользователя они не видны, и он получает их сервисы в виде абстрактной «функции как услуги» FaaS (Function as a Service).
Архитектура «клиент-сервер» является основой большинства корпоративных сетей и берет свое начало от самых первых вычислительных машин, т.н. «мэйнфреймов».
Статические и динамические сайты
Статический сайт — это тот, который возвращает тот же жёсткий кодированный контент с сервера всякий раз, когда запрашивается конкретный ресурс. Например, если у вас есть страница о товаре в /static/myproduct1.html, эта же страница будет возвращена каждому пользователю. Если вы добавите еще один подобный товар на свой сайт, вам нужно будет добавить ещё одну страницу (например, myproduct2.html) и так далее. Это может стать действительно неэффективным — что происходит, когда вы попадаете на тысячи страниц товаров? Вы повторяли бы много кода на каждой странице (основной шаблон страницы, структуру и т. д.), И если бы вы захотели изменить что-либо в структуре страницы — например, добавить новый раздел «связанные товары» — тогда вам придётся менять каждую страницу отдельно.
На заметку: Статические сайты превосходны, когда у вас небольшое количество страниц и вы хотите отправить один и тот же контент каждому пользователю. Однако их обслуживание может потребовать значительных затрат по мере увеличения количества страниц.
Когда пользователь хочет перейти на страницу, браузер отправляет HTTP-запрос GET с указанием URL-адреса его HTML-страницы. Сервер извлекает запрошенный документ из своей файловой системы и возвращает HTTP-ответ, содержащий документ и код состояния HTTP Response status code 200 OK (успех). Сервер может вернуть другой код состояния, например, «404 Not Found», если файл отсутствует на сервере или «301 Moved Permanently», если файл существует, но был перемещён в другое место.
Серверу для статического сайта нужно будет только обрабатывать GET-запросы, потому что сервер не сохраняет никаких модифицируемых данных. Он также не изменяет свои ответы на основе данных HTTP-запроса (например, URL-параметров или файлов cookie).
Понимание того, как работают статические сайты, тем не менее полезно при изучении программирования на стороне сервера, поскольку динамические сайты точно так же обрабатывают запросы для статических файлов (CSS, JavaScript, статические изображения и т. д.).
Динамический сайт — это тот, который может генерировать и возвращать контент на основе конкретного URL-адреса запроса и данных (а не всегда возвращать один и тот же жёсткий код для определенного URL-адреса). Используя пример сайта товара, сервер будет хранить «данные» товара в базе данных, а не отдельные HTML-файлы. При получении GET-запроса для товара сервер определяет идентификатор товара, извлекает данные из базы данных и затем создает HTML-страницу для ответа, вставляя данные в HTML-шаблон. Это имеет большие преимущества перед статическим сайтом:
- Использование базы данных позволяет эффективно хранить информацию о товаре с помощью легко расширяемого, изменяемого и доступного для поиска способа.
- Использование HTML-шаблонов позволяет очень легко изменить структуру HTML, потому что это нужно делать только в одном месте, в одном шаблоне, а не через потенциально тысячи статических страниц.
Анатомия динамического запроса: чтобы не отдаляться от практики, мы будем использовать контекст веб-сайта менеджера спортивной команды, где тренер может выбрать имя своей команды и размер команды в HTML-форме и вернуться к предлагаемому «лучшему составу» для своей следующей игры.
На приведённой ниже диаграмме показаны основные элементы веб-сайта «team coach», а также пронумерованные ярлыки для последовательности операций, когда тренер обращается к списку «лучших команд». Частями сайта, которые делают его динамичным, являются веб-приложение (так мы будем ссылаться на серверный код, обрабатывающий HTTP-запросы и возвращающие HTTP-ответы), база данных, которая содержит информацию об игроках, командах, тренерах и их отношениях, и HTML-шаблоны.
После того, как тренер отправит форму с именем команды и количеством игроков, последовательность операций будет следующей:
- Веб-браузер отправит HTTP-запрос GET на сервер с использованием базового URL-адреса ресурса (/best) и кодирования номера команды и игрока в форме URL-параметров (например, /best?team=my_team_name&show=11) или как часть URL-адреса (например, /best/my_team_name/11/). Запрос GET используется, потому что речь идёт только о запросе выборки данных (а не об их изменении).
- Веб-сервер определяет, что запрос является «динамическим» и пересылает его в веб-приложение для обработки (веб-сервер определяет, как обрабатывать разные URL-адреса на основе правил сопоставления шаблонов, определённых в его конфигурации).
- Веб-приложение определяет, что цель запроса состоит в том, чтобы получить «лучший список команд» на основе URL (/best/) и узнать имя команды и количество игроков из URL-адреса. Затем веб-приложение получает требуемую информацию из базы данных (используя дополнительные «внутренние» параметры, чтобы определить, какие игроки являются «лучшими», и, возможно, определяя личность зарегистрированного тренера из файла cookie на стороне клиента).
- Веб-приложение динамически создаёт HTML-страницу, помещая данные (из базы данных) в заполнители внутри HTML-шаблона.
- Веб-приложение возвращает сгенерированный HTML в веб-браузер (через веб-сервер) вместе с кодом состояния HTTP 200 («успех»). Если что-либо препятствует возврату HTML, веб-приложение вернёт другой код, например, «404», чтобы указать, что команда не существует.
- Затем веб-браузер начнёт обрабатывать возвращённый HTML, отправив отдельные запросы, чтобы получить любые другие файлы CSS или JavaScript, на которые он ссылается (см. шаг 7).
- Веб-сервер загружает статические файлы из файловой системы и возвращает их непосредственно в браузер (опять же, правильная обработка файлов основана на правилах конфигурации и сопоставлении шаблонов URL).
Операция по обновлению записи в базе данных будет обрабатываться аналогичным образом, за исключением того, что, как и любое обновление базы данных, HTTP-запрос из браузера должен быть закодирован как запрос POST.
Выполнение другой работы: задача веб-приложения — получать HTTP-запросы и возвращать HTTP-ответы. Хотя взаимодействие с базой данных для получения или обновления информации является очень распространённой задачей, код может делать другие вещи одновременно или вообще не взаимодействовать с базой данных.
Хорошим примером дополнительной задачи, которую может выполнять веб-приложение, является отправка электронной почты пользователям для подтверждения их регистрации на сайте. Сайт также может выполнять протоколирование или другие операции.
Возвращение чего-то другого, кроме HTML: серверный код сайта может возвращать не только HTML-фрагменты и файлы в ответе. Он может динамически создавать и возвращать другие типы файлов (текст, PDF, CSV и т. д.) или даже данные (JSON, XML и т. д.).
Идея вернуть данные в веб-браузер, чтобы он мог динамически обновлять свой собственный контент (AJAX) существует довольно давно. Совсем недавно «Одностраничные приложения» стали популярными, где весь сайт написан с одним HTML-файлом, который динамически обновляется по мере необходимости. Веб-сайты, созданные с использованием приложений такого рода, переносят большие вычислительные затраты с сервера на веб-браузер и приводят к тому, что веб-сайты, ведут себя больше как нативные приложения (очень отзывчивые и т. д.).
Источники:
- Клиент — сервер
- Архитектура «Клиент-Сервер»
- Клиент-сервер
Доп. материал:
- Computer Networking Tutorial: The Ultimate Guide
- Web Server vs. Application Server
- Что такое сервер приложения
- Клиент-серверная архитектура в картинках
- Тестировщик с нуля / Урок 11. Клиент-серверная архитектура. Веб-сайт, веб-приложение и веб-сервис
- Клиент-серверная архитектура
Определение
Архитектура «Клиент-Сервер» (также используются термины «сеть Клиент-Сервер» или «модель Клиент-Сервер») предусматривает разделение процессов предоставление услуг и отправки запросов на них на разных компьютерах в сети, каждый из которых выполняют свои задачи независимо от других.
В архитектуре «Клиент-Сервер» несколько компьютеров-клиентов (удалённые системы) посылают запросы и получают услуги от централизованной служебной машины – сервера (server – англ. «официант, обслуга»), которая также может называться хост-системой (host system, от host – англ. «хозяин», обычно гостиницы).
Клиентская машина предоставляет пользователю т.н. «дружественный интерфейс» (user-friendly interface), чтобы облегчить его взаимодействие с сервером.

Рис. 1. Архитектура «Клиент-Сервер».
Типы клиент-серверной архитектуры
Архитектуру «клиент-сервер» принято разделять на три класса: одно-, двух- и трёхуровневую. Однако, нельзя сказать, что в вопросе о таком разделении в сообществе ИТ-специалистов существует полный консенсус. Многие называют одноуровневую архитектуру двухуровневой и наоборот, то же можно сказать о соотношении двух- и трёхуровневой архитектур.
Постараемся внести ясность в этот вопрос.
Одноуровневая архитектура (1-Tier)
Одноуровневая архитектура «клиент-сервер» (1-Tier) – такая, где все прикладные программы рассредоточены по рабочим станциям, которые обращаются к общему серверу баз данных или к общему файловому серверу. Никаких прикладных программ сервер при этом не исполняет, только предоставляет данные.
")
Рис. 2. Одноуровневая архитектура «клиент-сервер» (1-Tier).
В целом, такая архитектура очень надёжна, однако, ей сложно управлять, поскольку в каждой рабочей станции данные будут присутствовать в разных вариантах. Поэтому возникает проблема их синхронизации на отдельных машинах. В общем, как можно видеть из рисунка, в этой архитектуре просматривается ещё один уровень – базы данных, что даёт повод во многих случаях называть её двухуровневой.
Двухуровневая архитектура (2-Tier)
К двухуровневой архитектуре «клиент-сервер» следует относить такую, в которой прикладные программы сосредоточены на сервере приложений (Application Server), например, сервере 1С или сервере CRM, а в рабочих станциях находятся программы-клиенты, которые предоставляют для пользователей интерфейс для работы с приложениями на общем сервере.
")
Рис. 3. Двухуровневая архитектура «клиент-сервер» (2-Tier).
Такая архитектура представляется наиболее логичной для архитектуры «клиент-сервер». В ней, однако, можно выделить два варианта. Когда общие данные хранятся на сервере, а логика их обработки и бизнес-данные хранятся на клиентской машине, то такая архитектура носит название “fat client thin server” (толстый клиент, тонкий сервер). Когда не только данные, но и логика их обработки и бизнес-данные хранятся на сервере, то это называется “thin client fat server” (тонкий клиент, толстый сервер). Такая архитектура послужила прообразом облачных вычислений (Cloud Computing).
Преимущества двухуровневой архитектуры:
- Легко конфигурировать и модифицировать приложения;
- Пользователю обычно легко работать в такой среде;
- Хорошая производительность и масштабируемость.
Однако, у двухуровневой архитектуры есть и ограничения:
- Производительность может падать при увеличении числа пользователей;
- Потенциальные проблемы с безопасностью, поскольку все данные и программы находятся на центральном сервере;
- Все клиенты зависимы от базы данных одного производителя;
Трёхуровневая архитектура (3-Tier)
В трёхуровневой архитектуре сервер баз данных, файловый сервер и другие представляют собой отдельный уровень, результаты работы которого использует сервер приложений. Логика данных и бизнес-логика находятся в сервере приложений. Все обращения клиентов к базе данных происходят через промежуточное программное обеспечение (middleware), которое находится на сервере приложений. Вследствие этого, повышается гибкость работы и производительность.
")
Рис. 4. Трёхуровневая архитектура «клиент-сервер» (3-Tier).
Преимущества трёхуровневой архитектуры:
- Целостность данных;
- Более высокая безопасность, по сравнению с двухуровневой архитектурой;
- Защищённость базы данных от несанкционированного проникновения.
Ограничения:
- Более сложная структура коммуникаций между клиентов и сервером, поскольку в нём также находится middleware.
Многоуровневая архитектура (N-Tier)
В отдельный класс архитектуры «клиент-сервер» можно вынести многоуровневую архитектуру, в которой несколько серверов приложений используют результаты работы друг друга, а также данные от различных серверов баз данных, файловых серверов и других видов серверов.
По сути, предыдущий вариант, трёхуровневая архитектура – не более, чем частный случай многоуровневой архитектуры.
")
Рис. 5. Многоуровневая архитектура «клиент-сервер» (N-Tier).
Преимуществом многоуровневой архитектуры является гибкость предоставления услуг, которые могут являться комбинацией работы различных приложений серверов разных уровней и элементов этих приложений.
Очевидным недостатком является сложность, многокомпонентность такой архитектуры.
Характеристики архитектуры «клиент-сервер»
- Асимметричность протоколов. Между клиентами и сервером существуют отношения «один ко многим». Инициатором диалога с сервером обычно является клиент.
- Инкапсуляция услуг. После получения запроса на услугу от клиента, сервер решает, как должна быть выполнена данная услуга. Модификация («апгрейд») сервера может производиться без влияния на работу клиентов, поскольку это не влияет на опубликованный интерфейс взаимодействия между ними. Иными словами, максимум, что может при этом почувствовать пользователь – незначительная задержка отклика сервера в течение небольшого времени апгрейда.
- Целостность. Программы и общие данные для сервера управляются централизованно, что снижает стоимость обслуживания и защищает целостность данных. В то же время, данные клиентов остаются персонифицированными и независимыми.
- Местная прозрачность. Сервер – это программный процесс, который может исполняться на той же машине, что и клиент, либо на другой машине, подключенной по сети. Программное обеспечение «клиент-сервер» обычно скрывает местоположение сервера от клиентов, перенаправляя запрос на услуги через сеть.
- Обмен на основе сообщений. Клиенты и сервер являются нежёстко связанными («loosely-coupled») процессами, которые обмениваются сообщениями: запросами на услуги и ответами на них.
- Модульный дизайн, способный к расширению. Модульный дизайн программной платформы «клиент-сервер» придаёт ей устойчивость к отказам, то есть, отказ в каком-то модуле не вызывает отказа всего приложения. В такой системе, один или больше серверов могут отказать без остановки всей системы в целом, до тех пор, пока услуги отказавшего сервера могут быть предоставлены с резервного сервера. Другое преимущество модульности в том, что приложение «клиент-сервер» может автоматически реагировать на повышение или понижение нагрузки на систему, путём добавления или отключения услуг или серверов.
- Независимость от платформы. Идеальное приложение «клиент-сервер» не зависит от платформ оборудования или операционной системы. Клиенты и серверы могут развёртываться на различных аппаратных платформах и разных операционных системах.
- Масштабируемость. Системы «клиент-сервер» могут масштабироваться как горизонтально (по числу серверов и клиентов), так и вертикально (по производительности и спектру услуг).
- Разделение функционала. Система «клиент-сервер» — это соотношение между процессами, работающими на одной или на разных машинах. Сервер – это процесс предоставления услуг. Клиент – это потребитель услуг.
- Общее использование ресурсов. Один сервер может предоставлять услуги множеству клиентов одновременно, и регулировать их доступ к совместно используемым ресурсам.
Практические применения архитектуры «клиент-сервер»
Архитектуры «клиент-сервер» — один из основных принципов работы сети Интернет. Любой веб-сайт, или приложение в Интернет работает на сервере, а его пользователи являются клиентами. Социальные сети (Фейсбук, ВК и пр.), сайты электронной коммерции (Amazon, Озон и др.) , мобильные приложения (Instagram и т.д.), устройства Интернета вещей (умные колонки или смарт-часы) работают на основе клиент-серверной архитектуры.
Хорошим примером работы системы «клиент-сервер» является автомобильный навигатор. Приложение навигации на сервере собирает данные с многих смартфонов пользователей, на которых установлены клиенты приложения. Кроме того, приложение навигации использует ещё и данные с сервера базы данных – геоинформационной системы, который предоставляет данные, например, о текущих ремонтах дорог, о появлении новых дорог и пр. Данные со многих клиентов (местоположение, скорость) обрабатывается сервером навигации и выдаётся на смартфоны пользователей в виде информации о средней скорости движения по тому или иному участку маршрута.
Практически любая корпоративная сеть или ИТ-система предприятия, как правило, строится по архитектуре «клиент-сервер». В небольших сетях (3-5 компьютеров в компании) функции сервера может выполнять один из рабочих компьютеров. Если число машин в организации более 10, то лучше сделать выделенный сервер (почтовый сервер, приложений, баз данных и пр.), который будет заниматься обслуживанием клиентов – компьютеров и телефонов сотрудников организации.
В домашних сетях архитектура «клиент-сервер» тоже используется довольно часто. Например, в домашнюю сеть могут быть объединены компьютеры членов семьи, один из которых выполняет функции сервера. В домашнюю сеть также могут быть включены такие устройства, как умные колонки, умные домашние устройства (пылесосы-роботы, фотоаппараты, DVD-плееры и пр.), а также «умные» счётчики (вода, электричество) и т.д. Тогда в системе управления сервера, будут видны все параметры, данные и медифайлы (музыка, видео, фото), а также «умные устройства».
Преимущества и недостатки архитектуры «клиент-сервер»
К преимуществам архитектуры «клиент-сервер» можно отнести:
- Централизованность, поскольку все данные и управление сосредоточены в центральном сервере;
- Информационная безопасность, поскольку ресурсы общего пользования администрируются централизованно;
- Производительность, использование выделенного сервера повышает скорость работы ресурсов общего пользования;
- Масштабируемость, количество клиентов и серверов можно увеличивать независимо друг от друга.
К недостаткам архитектуры «клиент-сервер» следует отнести:
- Перегрузку трафика в сети, что является главной проблемой в сетях «клиент-сервер». Когда большое число клиентов одновременно запрашивают одну услугу на сервере, то число запросов может создать перегрузку в сети;
- Наличие единой точки отказа в небольших сетях с одним сервером. Если он отказывает, все клиенты остаются без обслуживания;
- Превышение пределов ресурсов сервера, когда новые клиенты, запрашивающие услугу, остаются без обслуживания. В таких случаях, требуется срочное расширение ресурсов сервера;
- Иногда клиентские программы могут не работать на терминалах пользователей, если не установлены соответствующие драйверы. Например, пользователь посылает запрос на печать документа, а на сервере нет подходящего драйвера для печати данного формата документа на определённом принтере.
Заключение
В настоящее время можно встретить термин Serverless Architecture, т.н. «бессерверная архитектура». Однако, по сути, она представляет собой процесс получения функций сервера в виде облачной услуги. То есть, серверы в облаке тоже есть, но для конечного пользователя они не видны, и он получает их сервисы в виде абстрактной «функции как услуги» FaaS (Function as a Service).
Архитектура «клиент-сервер» является основой большинства корпоративных сетей и берёт свое начало от самых первых вычислительных машин, т.н. «мэйнфреймов». Программное обеспечение для локальных компьютерных сетей, подавляющее большинство которых основано на архитектуре «клиент-сервер», начало создаваться около 50 лет назад.
Дальнейшее развитие информационных технологий также будет происходить в значительной степени с использованием архитектуры «клиент-сервер».
В программная инженерия, многоуровневая архитектура (часто упоминается как п-старшая архитектура) или же многослойная архитектура это клиент-серверная архитектура в котором функции представления, обработки приложений и управления данными физически разделены. Наиболее распространенным использованием многоуровневой архитектуры является трехуровневая архитектура.
NАрхитектура приложений -tier предоставляет модель, с помощью которой разработчики могут создавать гибкие и повторно используемые приложения. Разделяя приложение на уровни, разработчики получают возможность изменять или добавлять определенный уровень вместо того, чтобы переделывать все приложение. Трехуровневая архитектура обычно состоит из презентация ярус, а логика предметной области ярус, а хранилище данных ярус.
Хотя концепции уровня и уровня часто используются как взаимозаменяемые, одна довольно распространенная точка зрения состоит в том, что действительно существует разница. Согласно этой точке зрения, слой представляет собой механизм логического структурирования элементов, составляющих программное решение, а ярус представляет собой механизм физического структурирования системной инфраструктуры.[1][2] Например, трехуровневое решение можно легко развернуть на одном уровне, например на персональной рабочей станции.[3]
Слои
«Слои» архитектурный образец был описан в различных публикациях.[4]
Общие слои
В логической многоуровневой архитектуре информационной системы с объектно-ориентированный дизайн, наиболее распространены следующие четыре:
- Уровень представления (также известный как слой пользовательского интерфейса, уровень представления, уровень представления в многоуровневой архитектуре)
- Уровень приложения (a.k.a. уровень обслуживания[5][6] или же ПОНЯТЬ Уровень контроллера [7])
- Бизнес-уровень (a.k.a. уровень бизнес-логики (BLL), уровень домена)
- Уровень доступа к данным (a.k.a. слой устойчивости, ведение журнала, сеть и другие службы, необходимые для поддержки определенного бизнес-уровня)
Книга Доменно-ориентированный дизайн описывает некоторые общие способы использования вышеуказанных четырех слоев, хотя его основное внимание уделяется уровень домена.[8]
Если в архитектуре приложения нет явных различий между бизнес-уровнем и уровнем представления (т. Е. Уровень представления считается частью бизнес-уровня), то была реализована традиционная модель клиент-сервер (двухуровневая).[нужна цитата ]
Более обычным соглашением является то, что уровень приложения (или уровень сервиса) считается подуровнем бизнес-уровня, обычно инкапсулируя определение API, отображающее поддерживаемые бизнес-функции. Фактически, уровни приложения / бизнеса могут быть дополнительно подразделены, чтобы выделить дополнительные подслои с отдельной ответственностью. Например, если модель – представление – ведущий Если используется шаблон, то подуровень презентатора может использоваться в качестве дополнительного уровня между уровнем пользовательского интерфейса и уровнем бизнеса / приложения (представленным подуровнем модели).[нужна цитата ]
Некоторые также определяют отдельный уровень, называемый уровнем бизнес-инфраструктуры (BI), расположенный между бизнес-уровнем (-ами) и уровнем (-ами) инфраструктуры. Его также иногда называют «низкоуровневым бизнес-уровнем» или «уровнем бизнес-сервисов». Этот уровень является очень общим и может использоваться на нескольких уровнях приложения (например, CurrencyConverter).[9]
Уровень инфраструктуры можно разделить на разные уровни (технические услуги высокого или низкого уровня).[9] Разработчики часто сосредотачиваются на возможностях персистентности (доступа к данным) уровня инфраструктуры и поэтому говорят только об уровне постоянства или уровне доступа к данным (а не об уровне инфраструктуры или уровне технических услуг). Другими словами, другие виды технических услуг не всегда явно рассматриваются как часть какого-либо конкретного уровня.[нужна цитата ]
Один слой находится поверх другого, потому что это зависит от него. Каждый слой может существовать без слоев над ним, и для работы требуются уровни под ним. Другое распространенное мнение состоит в том, что слои не всегда строго зависят только от соседнего слоя ниже. Например, в расслабленной многослойной системе (в отличие от строгой многоуровневой системы) слой также может зависеть от всех нижележащих слоев.[4]
Трехуровневая архитектура

Обзор трехуровневого приложения.
Трехуровневая архитектура — клиент-сервер шаблон архитектуры программного обеспечения в которой пользовательский интерфейс (презентация), функциональная логика процесса («бизнес правила»), компьютерное хранилище данных и доступ к данным разработаны и поддерживаются как независимые модули, чаще всего на отдельных платформы.[10] Он был разработан Джон Дж. Донован в Open Environment Corporation (OEC), инструментальной компании, которую он основал в Кембридж, Массачусетс.
Помимо обычных преимуществ модульного программного обеспечения с четко определенными интерфейсами трехуровневая архитектура предназначена для того, чтобы позволить любому из трех уровней независимо обновляться или заменяться в ответ на изменения требований или технологии. Например, изменение Операционная система в уровень представления повлияет только на код пользовательского интерфейса.
Обычно пользовательский интерфейс работает на рабочем столе. ПК или же рабочая станция и использует стандартный графический интерфейс пользователя, функциональная логика процесса, которая может состоять из одного или нескольких отдельных модулей, работающих на рабочей станции или сервер приложений, и СУБД на сервер базы данных или же мэйнфрейм который содержит логику хранения компьютерных данных. Средний уровень может быть многоуровневым (в этом случае общая архитектура называется «п-тище архитектуры »).
- Уровень презентации
- Это самый верхний уровень приложения. Уровень представления отображает информацию, относящуюся к таким услугам, как просмотр товаров, покупка и содержимое корзины покупок. Он взаимодействует с другими уровнями, с помощью которых он передает результаты на уровень браузера / клиента и на все другие уровни в сети. Проще говоря, это уровень, к которому пользователи могут получить доступ напрямую (например, веб-страница или графический интерфейс операционной системы).
- Уровень приложения (бизнес-логика, логический уровень или средний уровень)
- Логический уровень извлекается из уровня представления и, как собственный уровень, управляет функциональностью приложения, выполняя подробную обработку.
- Уровень данных
- Уровень данных включает в себя механизмы сохранения данных (серверы баз данных, общие файловые ресурсы и т. Д.) И уровень доступа к данным, который инкапсулирует механизмы сохранения и предоставляет данные. Уровень доступа к данным должен обеспечивать API к уровню приложения, который предоставляет методы управления хранимыми данными без раскрытия или создания зависимостей от механизмов хранения данных. Избежание зависимостей от механизмов хранения позволяет выполнять обновления или изменения, не затрагивая клиентов уровня приложений или даже не подозревая об этом. Как и в случае разделения любого уровня, существуют затраты на внедрение и часто затраты на производительность в обмен на улучшенную масштабируемость и ремонтопригодность.
Использование веб-разработки
в Веб-разработка поле, трехуровневое часто используется для обозначения веб-сайты, обычно электронная коммерция веб-сайты, построенные на трех уровнях:
- Интерфейс веб сервер обслуживает статический контент и, возможно, некоторые кешированный динамический контент. В веб-приложении интерфейс — это контент, отображаемый браузером. Контент может быть статическим или генерироваться динамически.
- Средний уровень обработки и генерации динамического контента сервер приложений (например., Symfony, Весна, ASP.NET, Джанго, Рельсы, Node.js ).
- Бэкэнд база данных или же хранилище данных, включающий как наборы данных, так и система управления базами данных программное обеспечение, которое управляет данными и предоставляет доступ к ним.
Прочие соображения
Передача данных между уровнями является частью архитектуры. Участвующие протоколы могут включать в себя один или несколько из SNMP, CORBA, Java RMI, .NET Remoting, Фонд связи Windows, Розетки, UDP, веб-сервисы или другие стандартные или проприетарные протоколы. Часто промежуточное ПО используется для соединения отдельных ярусов. Отдельные уровни часто (но не обязательно) работают на отдельных физических серверах, и каждый уровень может сам работать на кластер.
Прослеживаемость
Сквозная прослеживаемость потоков данных через пБолее сложные системы — сложная задача, которая становится более важной, когда системы становятся сложнее. В Измерение отклика приложений определяет концепции и API для измерения производительности и сопоставления транзакций между уровнями. Обычно термин «уровни» используется для описания физического распределения компонентов системы на отдельных серверах, компьютерах или сетях (узлах обработки). Тогда трехуровневая архитектура будет иметь три узла обработки. Термин «уровни» относится к логической группе компонентов, которые могут или не могут быть физически расположены на одном узле обработки.
Смотрите также
- Слой абстракции
- Клиент-серверная модель
- Архитектура, ориентированная на базу данных
- Front-end и back-end
- Иерархическая модель межсетевого взаимодействия
- Балансировка нагрузки (вычисления)
- Архитектура открытых сервисов
- Богатое Интернет-приложение
- Уровень обслуживания
- Слои стрижки
- веб приложение
Рекомендации
- ^ Шаблоны развертывания (Корпоративная архитектура Microsoft, шаблоны и практики)
- ^ Фаулер, Мартин «Шаблоны архитектуры корпоративных приложений» (2002). Эддисон Уэсли.
- ^ Шаблоны развертывания (корпоративная архитектура, шаблоны и методы Microsoft)
- ^ а б Бушманн, Франк; Менье, Регина; Ронерт, Ганс; Соммерлад, Питер; Сталь, Михаил (1996-08). Шаблонно-ориентированная архитектура программного обеспечения, Том 1, Система шаблонов. Wiley, август 1996 г. ISBN 978-0-471-95869-7. Извлекаются из http://www.wiley.com/WileyCDA/WileyTitle/productCd-0471958697.html.
- ^ Уровень обслуживания Мартина Фаулера
- ^ Мартин Фаулер объясняет, что уровень обслуживания совпадает с уровнем приложения.
- ^ Сравнение / обсуждение уровня контроллера GRASP и уровня приложения / сервиса
- ^ Домен-ориентированный дизайн, книга, стр. 68-74. Извлекаются из http://www.domaindrivendesign.org/books#DDD.
- ^ а б Применение UML и шаблонов, Издание 3-е, стр. 203 ISBN 0-13-148906-2
- ^ Экерсон, Уэйн В. «Трехуровневая архитектура клиент / сервер: достижение масштабируемости, производительности и эффективности клиент-серверных приложений». Открытые информационные системы 10, 1 (январь 1995): 3 (20)
внешняя ссылка
- Журнал Linux, Трехуровневая архитектура
- Руководство по архитектуре приложений Microsoft
- Пример бесплатной 3-х уровневой системы
- Что такое трехуровневая архитектура?
- Описание конкретной многоуровневой архитектуры для .NET / WPF Rich Client Applications
История первая
Некоторое время назад я работал в одной игровой компании, которой руководил немец. Создание игр не было основным бизнесом этого немца. Основные доходы он получал от продажи косметики и от сдачи коммерческой недвижимости в аренду. Наличие игровой компании было способом выделиться среди своих знакомых бизнесменов.
Игровая компания немца разрабатывала 3 вида игр:
- Флэш-игры для мобильных телефонов с поддержкой технологии J2ME.
- Обучающие игры для портативной игровой приставки Nintendo DS. Заказчиками этих игр были европейские издатели, а покупателями — родители, чьи чада имели проблемы с обучением по математике, английскому или немецкому языкам. Подразделение игр для Nintendo DS выпустило много игр. Хотя они и не стали AAA-тайтлами, но окупили свою разработку и принесли небольшую прибыль.
- Игры для платформы Nintendo Wii.
В последней команде был я. Команда должна была разработать игру для маленьких девочек по детскому бренду. Бренд был достаточно известен в Германии (это был основной рынок) и в ряде других европейских стран: во Франции и в Великобритании.
С самого начала была понятна только общая канва игры. Маленькая фея ходит по саду, встречает своих подруг (других фей), разговаривает с ними и приглашает на вечеринку. Подготовка к этой вечеринке занимает значительную часть игры: фея украшает сад, собирает яблоки, готовит из них праздничный пирог. Вечеринка проходит весело: фея и ее подруги играют на музыкальных инструментах, а затем — танцуют.
Предполагалось, что игра будет представлять собой последовательность мини-игр. Каждая мини-игра посвящена определенной теме: украшению сада, сбору яблок, приготовлению праздничного пирога, исполнению музыки и танцам. Не смотря на то, что были понятны темы мини-игр, не были понятны их детали. Геймдизайнера в команде не было.
Поначалу над игрой работало два программиста и один 3D-моделлер. Когда я присоединился к команде, не было ни проработанного игрового дизайна (или человека за него отвечающего), ни платформы, на которой можно было бы сделать игру.
На второй день после моего устройства на работу ко мне подошел владелец компании и спросил: “Когда будет готова игра?”. К тому времени у меня был опыт работы в игровой индустрии и, согласно этому опыту, разработка такой несложной игры командой из 3-4 человек занимала около года. Так я и сказал, что потребуется где-то около года.
На это немец мне ответил: “Такого срока нет. Игра должна быть сделана через 3 месяца”. Немного офигевая, я спросил: “А почему через три месяца?” На что немец мне ответил: “У меня будет день рождения, и нужно, чтобы к моему дню рождения игра была сделана”.
Для такого жесткого требования по срокам были и объективные предпосылки. У немца был заключен контракт с издательством, согласно которому он получал фиксированную сумму денег на разработку плюс процент от продаж. Но процент от продаж он получал только в том случае, если игра будет сдана в срок. А срок сдачи игры совпадал с его днем рождения.
После добавления в команду 4-го программиста, на повестке дня встал вопрос о выборе начальства. Как обычно формируют проектную команду? Согласно правильному подходу, сначала ищется руководитель, а затем уже он нанимает под себя остальных сотрудников. Здесь же было сделано все наоборот. Сначала были найдены сотрудники, а затем начальство стало смотреть, кто из них может быть руководителем. Ладно бы, если бы при выборе руководителя во главу угла поставили бы профессиональные навыки.
Но в качестве руководителя выбрали человека, который пообещал сделать игру за 3 месяца.
После назначения руководителя команды началась работа над игрой. Проблемы с игровым дизайном и отсутствием технологии так и не были решены. Поэтому работа не двигалась. Это изрядно злило вновь назначенного руководителя. Нередкий диалог между ним и программистом:
Руководитель: “Где игра про яблоки?”
Программист: “Еще не сделана”.
Руководитель: “Когда будет сделана?”
Программист: “Не знаю. Мне непонятно, что программировать”.
Руководитель: “Ну ты же — программист! Придумай!”
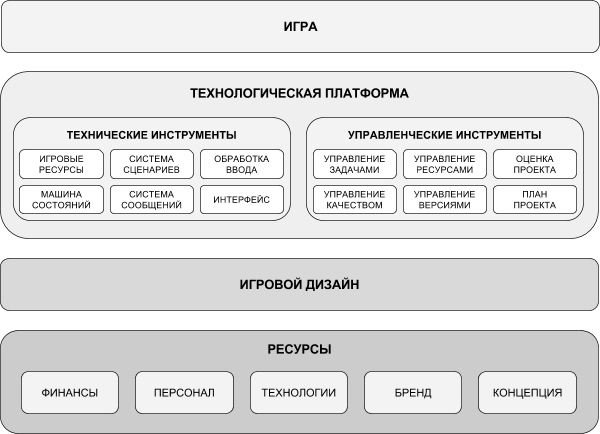
Систему разработки игр в игровой студии можно представить в виде иерархии из 4-х системных уровней.
Первый системный уровень — это уровень ресурсов. К ним относятся: финансы, сотрудники (которые доступны либо на рынке, либо внутри компании), бренд (если игра создается по бренду), первоначальная концепция игры. Этот уровень задает основу для всего проекта.
Второй системный уровень — это игровой дизайн. Он не должен представлять “дизайн игры в вакууме”. Наоборот, он должен опираться на имеющиеся ресурсы.
Например, бюджет упомянутой игры для девочек был незначительным. К тому же, на разработку могла быть потрачена лишь половина суммы, т.к. вторая половина предназначалась для покупки оборудования (компьютеров, телевизоров, девкитов, тесткитов) и лицензирование программ для художников и программистов. Небольшой бюджет разработки и ограничения платформы исключали возможность использования в игре реалистичной графики и реалистичной физики. Денег не было на приобретение лицензии технологически продвинутого движка, а игровая консоль не позволяла использовать шейдеры. Приходилось использовать то, что уже есть — бесплатный 3D-движок NintendoWare компании Nintendo.
Применение физического движка дает игроку свободу передвижения. Игрок может двигаться по игровому уровню в любом направлении до тех пор, пока не столкнется с препятствием. Но поддержка физики требует определенных затрат как со стороны дизайнеров, которые должны расставлять на сцене collision boxes, так и со стороны программистов, которым приходится обрабатывать коллизии. Все это сказывается на длительности разработки. Поэтому мы решили ограничиться использованием физики только в одной, главной сцене и реализовать мини-игры исключительно с использованием анимаций.
Третий системный уровень — это технологическая платформа. Платформа позволяет создавать игры по имеющемуся игровому дизайну, вернее, определенные виды игр. Для достижения этой цели она использует имеющиеся ресурсы первого системного уровня.
Платформа включает в себя определенные технические и управленческие инструменты. В качестве технических инструментов выступают:
- система управления игровыми ресурсами;
- машина игровых состояний, или система управления игровым потоком (game flow);
- система сценариев (scripting system);
- система рассылки и обработки сообщений;
- система обработки ввода (например, в случае игровой приставки Nintendo Wii она может распознавать движения контроллера Wii Remote);
- пользовательский интерфейс;
- система загрузки ассетов (поверхности, статических и динамических объектов, сценариев);
- система загрузки и сохранения пользовательских данных;
- и т.д.
Управленческие инструменты включают:
- систему управления задачами;
- систему управления качеством;
- систему управления ресурсами;
- систему управления версиями;
- оценку проекта;
- план проекта;
- и т.д.
Четвертый системный уровень — это сама игра или серия подобных игр.
Разбиение на системные уровни позволяет бороться со сложностью. Есть разница, делает ли программист мини-игру по определенному дизайну и с использованием конкретной платформы, по которой он может задать вопросы другим опытным программистам, работающим в той же компании, или же “льет код” на низкоуровневом API. Сложность реализации одной и той же мини-игры в обоих случаях будет неравноценной.
Например, после того, как был придуман и описан гейм-дизайн каждой мини-игры и была реализована платформа, один программист мог реализовать одну мини-игру в черновом качестве за 3 рабочих дня. Еще 2 дня требовались для того, чтобы добавить в мини-игру мультиплеер и навести некоторые красивости. Таким образом, создание одной мини-игры в финальном качестве обходилось в 5 человеко-дней. Между тем, как до этого момента (при отсутствующих дизайне и технологической платформе) проходили недели, а работа — не двигалась.
История вторая
Однажды меня пригласили на собеседование в один стартап. Проект был не очень интересный для меня, но подкупило то, что компания находилась буквально в пяти минутах ходьбы от моего дома. Я подумал, что впервые в своей карьере смогу не тратить время на дорогу на работу.
Собеседование в стартап проводилось по скайпу, и вопросы были достаточно адекватные. В основном, они касались моего предыдущего опыта. Что я делал? Чем занимался? С какими задачами сталкивался?
Процедура отбора кандидатов в стартап была двухступенчатая. Собеседование я прошел успешно, поэтому через некоторое время руководитель стартапа связался со мной и предложил выполнить тестовое задание.
Тестовое задание звучало так:
Разработать текстовый онлайн-редактор наподобие того, что используется в Google Docs.
Необходимо было поддержать следующие возможности:
- разбиение текста на абзацы;
- автоматическое распределение текста по страницам;
- форматирование текста;
- возможность одновременного редактирования несколькими пользователями;
- отображение и маркировка всех изменений, сделанных разными пользователями;
- хранение документа в “облаке”.
На выполнение тестового задания выделялась неделя.
Не стоит говорить, что я не стал выполнять такое тестовое задание, а, вежливо поблагодарив руководителя, более с ним не связывался.
Промежуточные итоги
Подводя итоги, можно утверждать, что в обеих историях была допущена одинаковая ошибка — пропуск системного уровня [6].
В первой истории при работе над игрой для девочек были пропущены “уровень игрового дизайна” и “уровень технологической платформы”, что привело к застопориванию работы над проектом и увеличению времени разработки. Работа над проектом была разблокирована только после того, как были добавлены недостающие уровни: проработан игровой дизайн и реализована (пусть и легковесная) платформа.
Во второй истории тоже пропущены системные уровни. Предложенная задача выглядит явно сложнее обычного тестового задания. Для борьбы со сложностью решение надо бы представить в виде иерархической системы, где нижние слои обеспечивают работу слоев, расположенных выше. Но такая работа требует значительных трудозатрат и предъявляет к квалификации инженера завышенные требования. Он должен разбираться буквально во всех областях: и в сетевых протоколах, в текстовых редакторах. Поэтому она более доступна для компании, чем для одного человека.
Иерархия системных уровней
Подход с выявлением системных уровней можно использовать при проектировании приложений. Конечно, если речь идет о написании какой-то простой программы, то в разбиении на уровни нет необходимости. Многоуровневая (или многослойная) архитектура имеет смысл, если разрабатывается сложное приложение или приложение средней сложности.
Выявление системных уровней — это первый шаг к разработке архитектуры. Если вы читали книгу по объектно-ориентированному анализу и проектированию, то наверняка не раз видели, как автор задается вопросом: “Как находить кандидаты в классы?”. Возможно, программируя, вы и сами задавали себе такой же вопрос.
Процесс структурирования приложения не следует начинать с выявления классов. Класс — это слишком маленький элемент абстракции. Если проводить аналогию со строительством, то класс — как отдельный кирпичик. А строительство небоскреба вряд ли следует начинать с вопроса о том, как сложить его из кирпичей.
Трехслойная архитектура
Фаулер [7] и руководство компании Microsoft по проектированию архитектуры приложений [5] выделяют три системных уровня (другими словами — три слоя абстракции), на которые можно разделить разрабатываемое приложение.
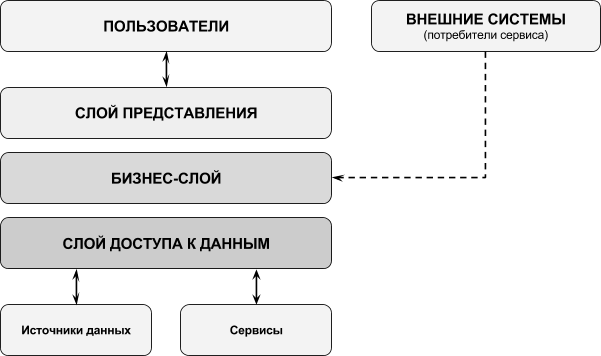
Примечание: Оригинальную версию диаграммы можно посмотреть на сайте Microsoft
Первый слой абстракции — это слой доступа к данным. В задачи данного слоя входит абстрагирование от базы данных. SQL-запросы к базе данных, в которой и хранятся данные приложения, скрываются за фасадом, который использует бизнес-слой.
Второй слой абстракции — это слой бизнес-логики. Он содержит объекты предметной области, а также функции для работы с ними. Эти функции и реализуют данную бизнес-логику.
Третий слой абстракции — это слой взаимодействия с пользователем. Данный слой включает компоненты пользовательского интерфейса.
Трехслойная архитектура, описанная в руководстве компании Microsoft, является рабочей. Единственное, у меня вызывает непонимание некоторая вещь, связанная с взаимодействием слоя бизнес-логики со слоем доступа к данным.
Согласно моему пониманию, классы предметной области должны относиться к слою бизнес-логики. С другой стороны, основная задача слоя доступа к данным заключается в том, чтобы получать данные из базы данных и копировать эти полученные данные в бизнес-объекты.
Получается противоречие:
- С одной стороны, бизнес-объекты должны быть объявлены на уровне бизнес-логики, т.к. логически относятся к нему.
- А с другой стороны, бизнес-объекты должны быть доступны на уровне доступа к данным, чтобы в них можно было скопировать данные, прочитанные из базы данных.
Видя это противоречие, мне хочется предложить несколько иной подход к разбиению приложения на системные уровни.
Пятиуровневая архитектура
Предлагаемый мною подход подразумевает разбиение клиентского приложения на 5 системных уровней. Ключевыми из предложенных пяти уровней являются лишь два. Это означает, что клиентское приложение, как минимум, может состоять из двух системных уровней. Использование же всех 5-ти слоев — это опциональный и, возможно, более желательный вариант.
Ограничения
Предлагаемая архитектура имеет ряд ограничений:
Во-первых, она была опробована мной и коллегами при создании 5-ти чистых клиентских приложений. Т.е. не было серверной составляющей, не использовалась СУБД, а приложения запускались на десктопных компьютерах и мобильных устройствах.
Четыре приложения предназначены для создания и редактирования различных игровых ресурсов. Пятое приложение — это сервисная программа, предназначенная для оказания услуг.
Во-вторых, разработанные приложения предназначались для создания и редактирования документов. Они обладали минимальной бизнес-логикой (например, не должны были проводить платежки), но богатым интерфейсом — он содержал множество различных элементов управления (контролов) для создания и редактирования данных (редакторы треков, графики функций, редакторы свойств и т.п.).
Описание
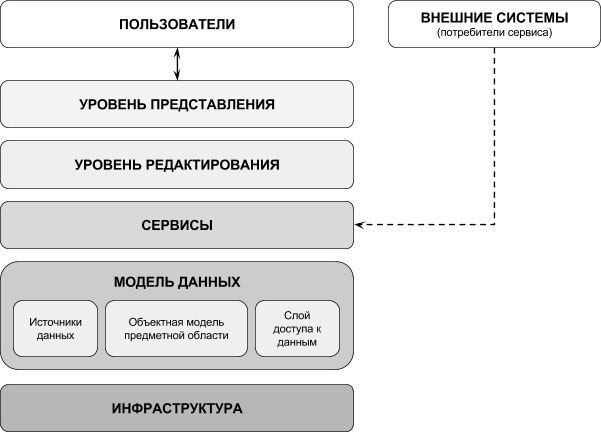
Первый уровень можно назвать инфраструктурным. Называется он так, потому что содержит инфраструктуру, т.е. библиотеки, модули, классы и методы, которые используются во всем приложении.
Если разработка приложения ведется на языке программирования C++, то, как правило, в инфраструктурный уровень включают:
- библиотеки работы с растровыми изображениями;
- XML и JSON-парсеры;
- библиотеки сжатия и шифрования данных;
- библиотеки контейнеров и различных вспомогательных классов (STL, boost);
- вспомогательные утилиты, написанные разработчиками приложения.
Инфраструктурный уровень представляет собой некоторую “свалку” из разных полезных утилит и вспомогательных классов. Наличие такого слоя позволяет избавиться от энтропии в выше расположенных слоях. Все, что является полезным, но трудно упорядочить, нужно помещать в инфраструктурный уровень.
Второй уровень можно назвать моделью данных. Этот уровень является ключевым, потому что без него вряд ли может обойтись хоть одно клиентское приложение.
Название “модель данных” перекликается с названием “слой доступа к данным” из руководства Microsoft по проектированию приложений. Не смотря на то, что задачи этого уровня приблизительно совпадают с задачами слоя доступа к данным, имеется и существенное отличие:
Модель данных объединена с источником данных, в качестве которого используются файлы в форматах XML или JSON. Для хранения данных не используется СУБД.
Модель данных представляет собой объектную модель предметной области [7, с. 140] и состоит из самосериализуемых классов, объекты которых загружают себя из файла и сохраняют себя в файл.
Модель данных содержит бизнес-объекты, которые, согласно упомянутому руководству, должны включаться в слой бизнес-логики.
Данные объекты либо не содержат никакой логики, либо обладают некоторой минимальной логикой, связанной, например, с верификацией данных. Количество методов, которыми обладают эти объекты, тоже невелико. Как правило, они либо предоставляют упрощенный доступ к другим объектам, связанным с первыми, либо отвечают за сериализацию и десериализацию самого объекта.
Согласно Фаулеру [7, с. 140] объектная модель предметной области относится к бизнес-логике. Поэтому, проводя прямое сопоставление предложенной пятиуровневой модели с классической трехслойной архитектурой [5], трудно соотнести, какому слою абстракции соответствует модель данных. Получается некоторый микс между источником данных, слоем доступа к данным и частью бизнес-логики. Он оправдан, когда нет необходимости разносить по физическим уровням (tires) хранение данных (СУБД) и их обработку (сервер приложений).
В программе для создания визуальных эффектов и в программе для создания анимационных блюпринтов объекты модели данных сами сериализуют себя в XML. Это само сохраняющиеся объекты. Модель данных включает в себя как объекты в памяти в виде экземпляров классов, так и сериализованные XML-файлы на жестком диске.
В GPS-навигаторе модель данных немного сложнее. Она состоит из нескольких специализированных баз данных и прослойки кода, осуществляющей доступ к данным.
Объединение объектной модели предметной области, слоя доступа к данным и источников данных в одном системном уровне позволяет использовать подход “проектирование на основе предметной области” и создать единое пространство решений, которое используется для организации данных как внутри приложения, так и при их хранении.
Подобный подход может быть применен, если приложению не нужно оперировать большим массивом данных и/или использовать СУБД. В противном случае уровень модели данных придется все-таки разделить.
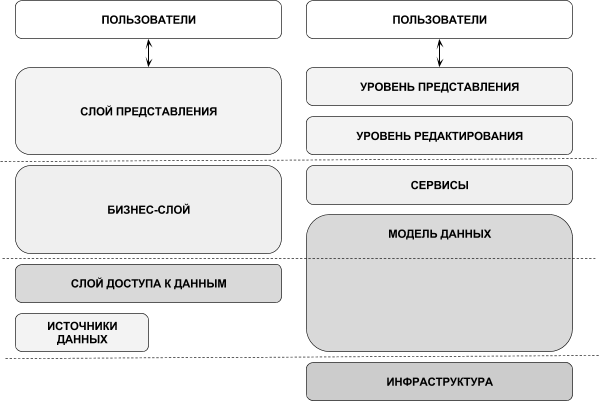
Рисунок “Сравнение классической трехслойной и пятиуровневой архитектур”
Третий уровень — это уровень сервисов или служб. С моей точки зрения именно этот слой соответствует слою бизнес-логики из руководства компании Microsoft. Однако такое соответствие формально, потому что в случае программ для редактирования трудно понять, что является бизнес-логикой. Если пользователю просто нужно создать и/или отредактировать документ (например, визуальный эффект или анимационный блюпринт), то что считать бизнес-логикой? Сам процесс редактирования? В приложениях-редакторах нет финансовых проводок и нет системы управления производственным процессом. К бизнес-логике можно было бы отнести объектную модель предметной области. Но она уже располагается на уровне модели данных.
Такие вопросы показывают, что механическое сопоставление трехслойной архитектуры, изложенной в руководстве Microsoft, и пятиуровневой архитектуры, предлагаемой в этой статье, не является корректным вне рассмотрения архитектур конкретных приложений.
Уровень сервисов представляет собой набор функциональных модулей. Каждый модуль отвечает за реализацию какой-нибудь одной операции, выполняемой над моделью данных.
В некоторых клиентских приложениях таких бизнес-функций может быть много. В некоторых — мало. А в некоторых — они совсем отсутствуют. Поэтому для ряда приложений уровень сервисов может быть пропущен.
Например, в редакторе визуальных эффектов каждый эффект может быть сохранен в формате XML. Однако для того, чтобы данный визуальный эффект мог использоваться в игре, его необходимо преобразовать в бинарный формат. Таким преобразованием занимается компилятор. Этот компилятор и является отдельным сервисом.
В GPS-навигаторе сервисов больше. Потому что это приложение предназначено для оказания услуг пользователям. К числу таких сервисов относятся:
- рисование карты местности, где находится пользователь;
- прокладывание маршрута в заданную точку;
- навигация по маршруту;
- поиск координат по адресу.
Модули, ответственные за оказание услуг, располагаются на уровне сервисов. Сервисы не зависят или слабо зависят друг от друга. Их можно поместить в разные модули и избежать излишней связности между ними.
Четвертый уровень отвечает за редактирование. Данный уровень характерен для программ-редакторов. Он содержит типовые компоненты или типовые архитектуры редакторов. Прежде всего, я имею в виду:
- Архитектуру Документ/Вид (еще известную из библиотеки классов MFC) [1]
- Undo/Redo Management [3]
Архитектура Документ/Вид осуществляет привязку конкретного расширения файла к определенному типу документа, а также привязывает определенный тип документа к определенному виду, ответственному за его визуализацию.
Undo/Redo Management обеспечивает поддержку отмены операции. Благодаря такой возможности пользователь при редактировании сложного документа в любой момент может отменить ошибочно выполненную операцию. В результате, редактирование становится устойчивым к ошибкам и не страшным для человека. Такая функциональность стала де-факто стандартом различных программ редактирования.
Уровень редактирования является частью слоя представления классической трехслойной архитектуры [5]. Его выделение в отдельный слой обусловлено тем, что он задает каркас для редактирования. Кроме того, архитектурные концепции, используемые для организации уровня редактирования, не зависят от визуализации данных.
Пятый уровень тоже является ключевым. Без него не обойдется ни одно клиентское приложение. Этот уровень содержит компоненты, отвечающие за визуализацию данных и взаимодействие с пользователем.
Не смотря на то, что этот уровень называется точно так же, как и слой из классической трехслойной модели, тем не менее, он имеет чуть меньше обязанностей. Исключение из него компонентов, отвечающих за редактирование, позволяет разработчику сконцентрировать свое внимание на визуализации данных и написании разнообразных органов управления.
Разделение между уровнем редактирования и уровнем представления может носить не физический, а ментальный характер. Компоненты обоих слоев могут располагаться в одном модуле.
Связь с шаблоном проектирования “Модель — Вид — Контроллер”
Концепция “Модель — Вид — Контроллер” была сформулирована норвежцем Трюгве Реенскаугом в 1978/79-ом годах во время его работы в лаборатории Xerox PARC [8]. Она предполагает разделение структуры приложения на три составляющих:
- Модель. Описывает данные. Не занимается преобразованием данных. Не содержит кода по их визуализации.
- Вид. Отвечает за визуализацию Модели.
- Контроллер. Изменяет Модель, как правило, в результате действий пользователя.
Одним из самых неоднозначных компонентов является Контроллер. В разных реализациях шаблона проектирования “Модель — Вид — Контроллер” компонент Контроллер выполняет разные обязанности. Например, в API операционных систем Mac OS и iOS существует контроллер видов, который отвечает за управление видами, а в библиотеке классов Microsoft Foundation Classes для программирования под Windows используется архитектура “Документ — Вид”, в которой под Моделью понимается Документ, а Контроллер — отсутствует.
В ряде трактовок под Контроллером понимают обработку команд от устройств ввода (например, мыши и клавиатуры). В других случаях к устройствам ввода добавляют и визуальные элементы ввода, отображаемые на экране (например, меню) [8].
Некоторые трактовки отождествляют Контроллер с бизнес-логикой приложения [8].
Хотя концепция “Модель — Вид — Контроллер” и не имеет устоявшегося взгляда на элемент Контроллер, тем не менее, она предполагает отделение данных от их визуализации.
В этой связи, можно сказать, что и трехслойная архитектура, описанная в руководстве Microsoft [5], и пятиуровневая архитектура, излагаемая в настоящей статье, в той или иной мере отвечают концепции “Модель — Вид — Контроллер”. Критерии, использованные для разделения приложения на системные уровни, отчасти пересекаются с критериями, используемыми в “Модель — Вид — Контроллер” для выделения ее компонентов.
Организация же выделенных элементов в виде слоев однозначно задает их соподчиненность и устраняет различные вопросы на тему “Должен ли Контроллер знать о Виде?” или “Должна ли Модель обновлять Вид при своем изменении?”.
Разделение архитектуры на слои задает не только логику выделение компонентов, но и четко специфицирует зависимости между ними. Модель данных ничего не знает ни об уровне сервисов, ни об уровне редактирования. Однако может быть преобразована ими. Уровень сервисов ничего не знает о визуализации модели. Однако уровень представления использует как модель, так и сервисы.
Также в предложенной архитектуре отсутствует такой неоднозначный компонент, как Контроллер. Вместо него добавлены уровень сервисов, уровень редактирования и уровень представления, обязанности которых и положение в иерархии четко специфицированы.
На уровне редактирования используется архитектура “Документ — Вид”, которая является подвидом шаблона проектирования “Модель — Вид — Контроллер”. Данная архитектура предполагает выделение классов Документ (отвечает за хранение и преобразование данных и, по сути дела, является оберткой над классами из модели данных) и Вид (отвечает за визуализацию данных и обработку команд от пользователя).
Использование архитектуры “Документ — Вид” позволяет специфицировать взаимодействие между моделью и представлением (видом), добавить возможность редактирования модели данных и поддержать возможность отмены операций.
Пример 1. Редактор All Sparks
Обзор
Редактор All Sparks представляет собой приложение для создания визуальных эффектов. По внешнему виду данное приложение напоминает аудиоредактор. Этому есть обоснование: как и звук, визуальный эффект имеет определенную длительность. Поэтому окно редактирования визуального эффекта содержит ось времени (timeline), расположенную горизонтально. Под осью времени расположены треки, которые тоже ориентированы горизонтально. Пользователь может добавлять и удалять треки.
Главное окно редактора All Sparks
На треках размещаются компоненты. Пользователь может выбирать эти компоненты из списка Component List и перетаскивать их на треки.
В качестве компонентов выступают:
- частицы;
- биллборды;
- трехмерные модели;
- источники света;
- музыка и звуки;
- различные силы, например:
- сила тяготения;
- сила сопротивления воздуха;
- сила турбулентности;
- и т.д.
Компоненты-силы воздействуют на компоненты-частицы. Если расположить компонент “частицы” на одном треке, а под ним расположить компонент “сила тяготения”, то во время проигрывания эффекта на разлетающиеся частицы будет действовать сила тяжести. Постепенно частицы будут падать вниз.
Компоненты располагаются на треках
Каждый компонент представлен в виде прямоугольника. Поскольку компонент может занимать место только на одном треке, то высота компонента совпадает с высотой трека. Длина компонента задает длительность его существования, а начало — момент времени его появления при воспроизведении эффекта.
Для того, чтобы пользователь мог быстро идентифицировать тип компонента, каждый тип компонента имеет свой цвет.
После размещения компонента на треке, пользователь может задавать различные его свойства. Свойства компонента отображаются в редакторе свойств, который располагается в нижней части окна редактирования.
Редактор свойств
Редактор свойств представляет собой таблицу из двух столбцов и множества строк. В левой колонке указываются названия свойства, а в правой — значения.
Пользователь может посмотреть на то, как выглядит визуальный эффект, в окне просмотра. Это окно располагается в левой части главного окна программы. Для того, чтобы воспроизвести эффект, пользователь должен нажать кнопку Play. После этого эффект компилируется в бинарный формат и передается игровому движку для воспроизведения.
Визуальный эффект в окне просмотра
Архитектура
Архитектуру редактора визуальных эффектов можно представить в виде иерархии из 5-ти системных уровней:
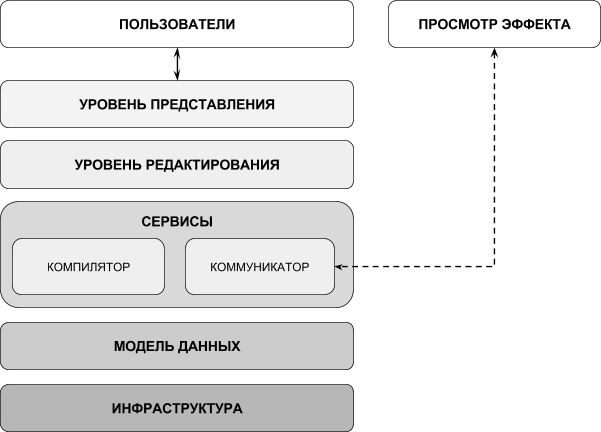
Первый системный уровень — это инфраструктура. Он представляет собой набор вспомогательных классов. Как правило, эти классы содержат какие-то математические методы, которые отсутствуют в стандартном классе Math, или же какие-то дополнительные операции со строками и с именами файлов. Инфраструктурный уровень очень небольшой.
Второй системный уровень — это модель данных. Модель данных описывает структуру визуального эффекта: треки, компоненты на них, свойства компонентов.
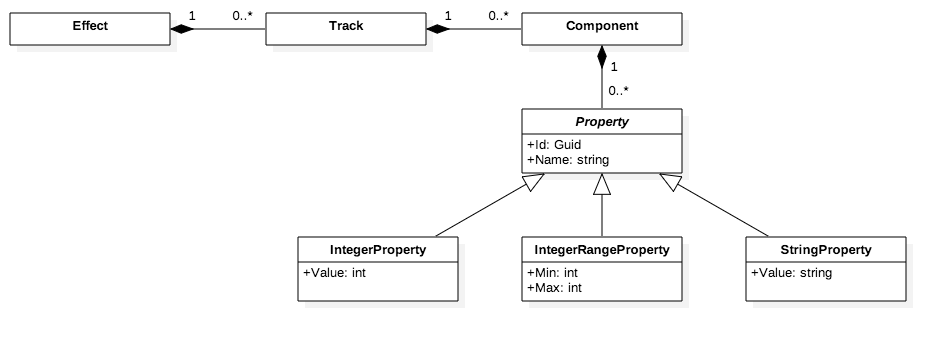
Каждый класс модели данных имеет методы Load и Save, которые предназначены для загрузки и сохранения объекта из/в XML. Для чтения и записи XML используется LINQ to XML.
public class Component
{
public Dictionary<Guid, Property> Properties { get; } = new Dictionary<Guid, Property>();
public Component Load(XElement item)
{
if (item == null)
{
throw new ArgumentNullException(nameof(item));
}
// Loading logic
return this;
}
public XElement Save()
{
return new XElement("component",
Properties.Values.Select(prop => prop.Save()).ToArray()
);
}
}
Третий системный уровень — это уровень сервисов и служб. В настоящий момент данный слой содержит только один сервис. Это — компилятор. Компилятор осуществляет преобразование эффекта в бинарный формат, который затем может быть использован движком.
Какое-то время назад редактор визуальных эффектов не был интегрирован с игровым движком. Это были два разных приложения. И для того, чтобы визуальный эффект можно было посмотреть, как он выглядит, существовал еще один сервис, который позволял обмениваться данными между клиентской программой (редактором визуальных эффектов) и сервером, в роли которого выступала программа-просмотр. Этот сервис назывался коммуникатором.
Таким образом, ранее было два сервиса. А сейчас, поскольку произошла интеграция редактора визуальных эффектов с игровым движком, необходимость в коммуникаторе отпала, и остался один сервис — компилятор.
Четвертым системным уровнем является уровень редактирования. Он реализует две архитектуры:
- Архитектуру Документ/Вид, которая позволяет открывать файлы визуальных эффектов в исходном формате и создавать для их редактирования и отображения различные виды.
- Undo/Redo Management, которая представляет собой стек команд, которые могут быть выполнены или отменены при редактировании эффекта.
В качестве пятого системного уровня выступает уровень взаимодействия с пользователем, который содержит различные контролы. В нашем случае такими контролами являются линия времени (timeline), треки, редактор свойств и т.д.
Пример 2. Редактор Genome
Обзор
Вторым приложением, архитектуру которого мне хочется рассмотреть, является редактор анимационных блюпринтов. Блюпринт — это программный модуль, реализующий определенную функциональность, но не написанный на языке программирования, а представленный в виде графа. Получается, что редактор блюпринтов — это средство визуального программирования.
Впервые блюпринты были реализованы в движке Unreal Engine 4 [2]. Они используются для разных целей, в том числе, для “программирования” логики игровой сцены или поведения персонажа.
В современных видеоиграх для создания качественной картинки 3D-аниматорам приходится делать очень много различных анимаций. Если речь идет о создании человекоподобного персонажа, то нужно анимировать множество движений: походку, бег, прыжок, приседание, поднимание рук (вместе и каждой руки по отдельности) и т.д.
Часто поведение персонажа нельзя свести к проигрыванию одной из анимаций или к проигрыванию какой-то заранее определенной последовательности этих анимаций. Порою анимации нужно совмещать. Например, персонаж может идти и одновременно нести чашку с горячим кофе в правой руке. Не останавливаясь, он может подносить эту чашку ко рту, чтобы сделать глоток.
Современные 3D-движки позволяют смешивать различные персонажные анимации, т.е. проигрывать их одновременно. Такое требуется для плавного перехода от одной анимации к другой или же когда одна анимация проигрывается на одной части скелета персонажа, а другая — на другой. Для того, чтобы задать логику подобного смешения и используется редактор анимационных блюпринтов. Впервые он появился в движке Unreal Engine 4. И поскольку он показался удобным нашим 3D-аниматорам, то потребовалось создать подобный редактор и у нас.
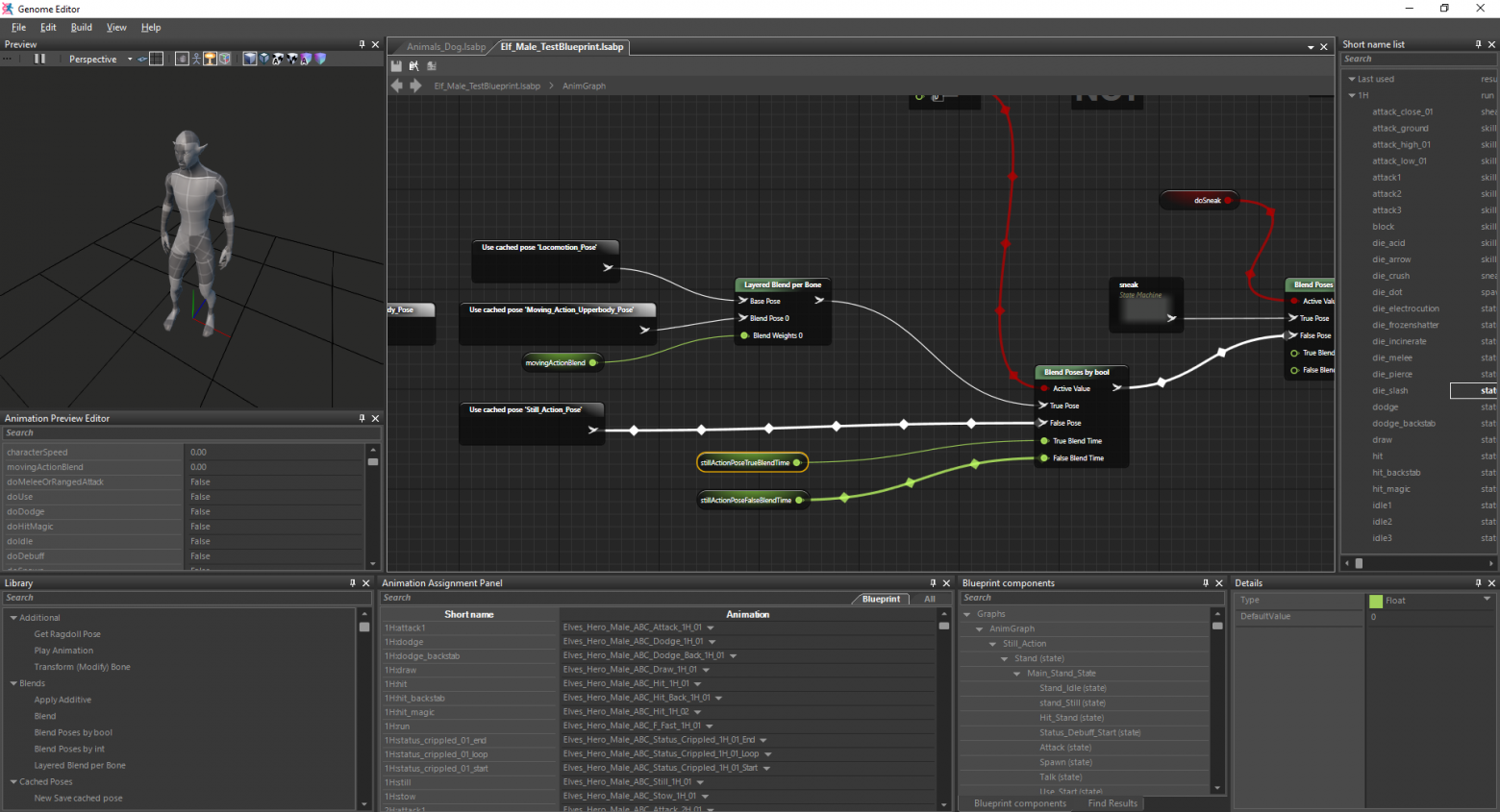
Главное окно редактора Genome
Анимационный блюпринт представляет собой граф. Он состоит из узлов и соединительных линий. Линии можно провести не в произвольное место узла, а к определенному сокету. Каждый узел графа может содержать один или несколько сокетов.
Узлы представляют собой различные операции, например, сравнение, сложение, вычитание, цикл, ветвление и т.д.
Примеры узлов-операций
Есть и более сложные узлы такие, как машина состояний. Сложные узлы содержат в себе вложенные графы. Например, машина состояний содержит в себе граф состояний, каждый узел которого обозначает определенное состояние, а соединительные линии — условные переходы. Состояния тоже содержат вложенные графы.
Машина состояний
Для попадания во вложенный граф пользователь должен дважды кликнуть по узлу мышью. Вложенный граф можно редактировать точно также, как и родительский. Он тоже состоит из узлов и соединительных линий.
Каждый узел может иметь один или несколько сокетов. Сокеты располагаются с левой и правой сторон узла. Сокеты, которые расположены слева, называются входными, а расположенные справа — выходными. Во входные сокеты поступают входные данные или управляющие сигналы, а из выходных сокетов могут быть получены результаты выполнения операции, за которую отвечает узел.
Узлы с различными входными и выходными сокетами
Сокеты являются типизированными, как и соединительные линии между ними. Существуют сокеты для целых и вещественных чисел, для булевских значений и строк. Типизация сокетов позволяет избежать ошибок, когда выходной сокет одного типа соединяется с входным сокетом другого типа, например, строка с целым числом. Напрямую такое соединение невозможно, только через вспомогательный узел, который выполняет операцию преобразования типа.
Соединительные линии между сокетами задают потоки данных и потоки управления. Для организации потоков управления существуют специализированные сокеты, которые в анимационном графе называются animation pose, а в графе событий — exec.
Подробнее о блюпринтах, узлах и сокетах можно прочитать в Blueprints Visual Scripting из руководства Unreal Engine 4 Documentation [2]. В редакторе Genome был использован аналогичный подход.
Архитектура
Архитектура редактора анимационных блюпринтов может быть представлена иерархией из 5-ти системных уровней. Эта иерархия похожа на ту, что используется и в редакторе визуальных эффектов. Названия уровней, их назначения, отдельные компоненты практически совпадают. Но есть и различия, на которые мне хочется обратить ваше внимание.
Различия обусловлены тем, что в основе редактора анимационных блюпринтов лежит редактор графов. Была поставлена задача переиспользовать этот редактор при переписывании других приложений: редактора материалов и редактора диалогов.
Это означает, что нельзя ограничиться одной моделью данных, которая будет представлять графы для анимационных блюпринтов. Нужна некоторая базовая модель данных для всех возможных графов. И нужен некоторый фреймворк для создания и редактирования графов. Этот фреймворк должны использовать конкретные редакторы: редактор анимационных блюпринтов, редактор диалогов, редактор материалов и т.п.
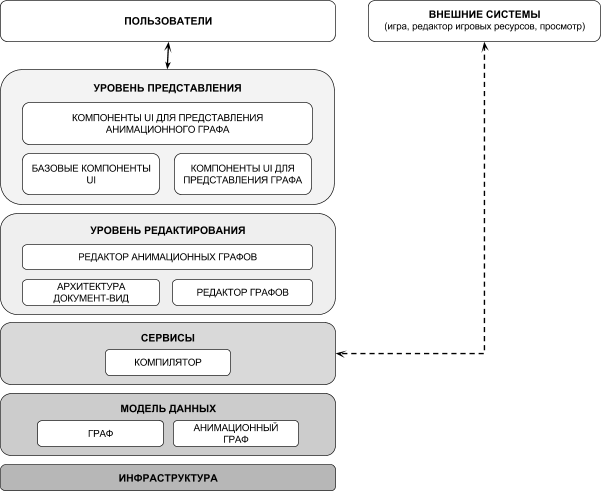
Инфраструктурный уровень редактора анимационных блюпринтов практически ничем не отличается от аналогичного уровня редактора визуальных эффектов за одним исключением. Поскольку контрол для визуализации графов реализован с помощью технологии WPF, то инфраструктурный слой содержит всякие вспомогательные классы, облегчающие работу с WPF, а также — стили для используемых контролов. Стили применяются не только в редакторе Genome, но и в других приложениях. Поэтому они расположены на уровне инфраструктуры.
Модель данных разделена на две части. Первая часть — это обобщенная модель данных для любого графа и любого блюпринта. Она представляет собой иерархический граф. Граф содержит узлы и соединительные линии. Некоторые узлы могут содержать в себе другие графы.
Вторая часть — это модель данных для анимационных блюпринтов. Она содержит в себе классы, которые описывают узлы анимационного блюпринта. К таким узлам относятся математические операции, операции сравнения, операции преобразования типов, операции смешивания анимаций и т.д. Отдельные классы представляют сокеты и соединительные линии.
Поверх модели данных располагается уровень сервисов. Как и в случае с редактором визуальных эффектов, данный уровень содержит только один сервис — компилятор. Компилятор преобразует анимационный блюпринт в исходном формате в бинарный формат, который воспроизводится движком.
Уровень редактирования разделен на три части. Первая часть — это библиотека, которая содержит базовые классы для архитектуры Документ/Вид и для управления Undo/Redo. Эта библиотека используется как в редакторе анимационных блюпринтов, так и в редакторе визуальных эффектов.
Вторая библиотека отвечает за редактирование графов. Она позволяет пользователю создавать узлы, расставлять их в окне редактирования, соединять узлы коннекторами различных типов, а также — удалять узлы и переключаться между вложенными графами. Однако эта библиотека имеет дело с обобщенной моделью графов и ничего не знает о конкретных узлах для редактора анимационных блюпринтов.
Третья библиотека предназначена для редактирования анимационных блюпринтов. Она позволяет создавать, удалять, редактировать конкретные узлы анимационного блюпринта.
Уровень взаимодействия с пользователем тоже разбит на три части. Первая часть содержит базовые компоненты пользовательского интерфейса. Второй часть содержит компоненты интерфейса, используемые для редактирования графов. А третья часть содержит компоненты пользовательского интерфейса, используемые для редактирования анимационных блюпринтов.
В целом, архитектуры редактора визуальных эффектов и редактора анимационных блюпринтов очень похожи и состоят из одних и тех же системных уровней. Однако имеются и различия, которые обуславливаются необходимостью создания обобщенной библиотеки для редактирования графов. Эти различия выливаются в то, что, прежде всего, модель данных разделяется на две части:
- обобщенную модель данных, которая описывает некий обобщенный граф;
- и конкретную модель данных, которая описывает граф конкретного вида — анимационный блюпринт.
Вместе с моделью данных такое же разделение происходит и на уровне редактирования, и на уровне взаимодействия с пользователем.
Пример 3. GPS-навигатор
Обзор
В третьем примере мне хотелось бы рассмотреть создание GPS-навигационного приложения для смартфона. Эта программа отличается от рассмотренных в предыдущих двух примерах приложений: редактора визуальных эффектов и редактора анимационных блюпринтов.
Основное отличие заключается в том, что редакторы нацелены на создание и редактирование документов в то время, как GPS-навигатор предназначен для оказания услуг.
К таким услугам относятся:
- Помощь пользователю в ориентации на местности. Эта услуга осуществляется путем отрисовки карты местности и указания места, где находится пользователь. При движении пользователя показывается и направление этого движения.
- Построение маршрута в заданную точку. Место назначение может быть задано как путем указания точки на карте, так и при помощи поиска.
- Поиск конкретного адреса или места пересечения двух дорог.
- Поиск ближайших точек интереса: кафе, автозаправочных станций, банкоматов и т.д.
Не смотря на нацеленность навигационной системы на оказание услуг, тем не менее, она также позволяет создавать и редактировать некоторые несложные документы. К ним относятся:
- профиль пользователя;
- история поиска точек интереса и адресов;
- редактирование списка фаворитов (домашний адрес, адрес места работы и другие).
Архитектура
Архитектура GPS-навигатора может быть представлена уже известной нам иерархией из 5-ти системных уровней.
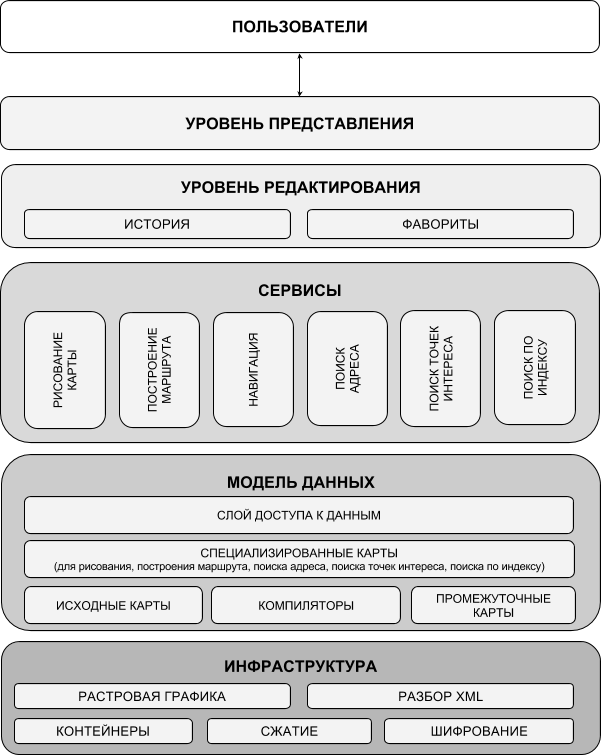
Первый, самый нижний, инфраструктурный уровень состоит из библиотек и утилит, которые используются сквозным образом во всем приложении. Поскольку навигационная система разрабатывалась с использованием языков программирования C и C++, то в число этих библиотек входили:
- библиотека stlport, которая содержит набор стандартных контейнеров и алгоритмов и собирается под разные платформы;
- библиотека zlib, которая позволяет сжимать и разжимать данные при помощи алгоритма deflate;
- библиотеки libpng и libjpeg для работы с изображениями растровой графики в форматах png и jpeg;
- библиотека aes для шифрования данных и создания электронных подписей;
- библиотека expat xml parser для чтения и разбора xml-файлов.
Уровень модели данных является наиболее сложным по сравнению с аналогичными уровнями в других рассмотренных приложениях. Дело в том, что скорость работы многих алгоритмов навигации определяется скоростью доступа к необходимым данным. Поэтому данные нужно организовать таким образом, чтобы скорость доступа была высокой.
Данные содержат картографическую информацию, которая затем используется для рисования карт, прокладки маршрута, поиска координат по адресу.
Уровень модели данных может быть разделен на два подуровня:
- база данных;
- слой доступа к данным.
База данных содержит навигационные данные: карты, почтовые индексы, точки интереса, историю поездок, список мест-фаворитов.
Слой доступа к данным получает данные из базы данных и предоставляет их вышестоящему уровню в виде соответствующих структур данных.
Изначально карты в исходном формате поступают на вход компилятора, который преобразует их в промежуточный формат. Как правило, в качестве исходного формата выступает GDF 3.0. Это текстовый файл с определенной разметкой. Нередко одна карта, представленная в GDF 3.0, “весит” более одного гигабайта. Чтобы представить дорожную сеть Великобритании, необходимо 7 таких карт. В качестве промежуточного выступает бинарный формат, который позволяет представить полную информацию в компактной форме.
Далее карты в промежуточном формате поступают на вход пяти компиляторам, которые преобразуют их в специализированные базы данных.
Первая специализированная база данных содержит информацию, необходимую для отрисовки карты. Она включает не только дороги, но и различные области такие, как парки, водоемы, леса. Основное требование к ней — быстрый доступ ко всем элементам, которые находятся в заданной области.
Вторая специализированная база данных хранит информацию, необходимую для построения маршрута. В отличие от базы данных для рисования, она содержит информацию только о дороге. Для построения маршрута не нужно что-либо знать о водоемах, лесах, парках и геометрии дорожных элементов. Требуется только длина дорожного элемента, максимальная скорость и направление движения. Основное требование к ней — это быстрый доступ к соседним дорожным элементам.
Третья специализированная база данных содержит адреса. Основное требование к ней — это быстрый поиск адреса по введенному тексту и дорожного элемента по адресу.
Четвертая специализированная база данных содержит информацию о почтовых индексах. Основное требование к ней — это быстрый поиск координат района по почтовому индексу.
Пятая база данных содержит информацию о различных точках интереса (ресторанах, кафе, автозаправочных станциях, банкоматах и т.п.). Основное требование к ней заключается в быстром нахождении точек интереса в пределах определенной области.
Для доступа к картографическим данным используется слой доступа к данным.
Таким образом, модель данных для GPS-навигатора включает в себя:
- карты в исходном (текстовом) формате;
- компилятор для преобразования карт из текстового формата в промежуточный бинарный;
- пять специализированных компиляторов, которые формируют специализированные базы данных:
- базу данных для рисования карт;
- базу данных для построения маршрута;
- базу данных для поиска координат по адресу;
- базу данных почтовых индексов;
- базу данных точек интереса;
- слой доступа к данным, которые обеспечивает доступ к данным из специализированных баз данных.
Поверх модели данных располагается уровень сервисов. Поскольку GPS-навигатор — это приложение, ориентированное на оказание услуг, то этот уровень включает несколько функционально-ориентированных модулей. Каждый модуль отвечает за какую-нибудь одну ключевую функцию или же группу похожих ключевых функций навигационной системы.
Можно выделить такие модули:
- Растеризатор карты. Формирует двумерное или трехмерное представление карты в заданной области.
- Модуль роутинга. Отвечает за прокладку маршрута из текущего местоположения в заданную точку.
- Модуль поиска адреса. Отвечает за поиск координат по адресу.
- Модуль поиска по индекса. Отвечает за поиск координат по почтовому индексу.
- Модуль поиска точек интереса. Отвечает за нахождение точек интереса в пределах заданной области.
- Навигатор. Отвечает за формирование и выдачу навигационных указаний при движении по маршруту.
Уровень редактирования является достаточно небольшим и не содержит слишком много кода. Причина этого заключается в том, что навигационная система предназначена для оказания услуг пользователя и не предназначена для создания и редактирования каких-то документов.
Можно выделить 3 основных функции, которые можно делегировать уровню редактирования:
- работа с профилями пользователей (у навигационной системы могут быть несколько пользователей, и данные каждого пользователя должны сохраняться в отдельном профиле);
- создание и управление списком мест-фаворитов;
- сохранение истории поездок (в простейшем случае — сохранение точек назначения).
В принципе, GPS-навигатор может спокойно обойтись и без слоя редактирования. Но если хочется поддержать профили, то работа с ними может быть делегирована такому слою.
Уровень взаимодействия с пользователем отвечает за представление информации для пользователя на экране или на звуковой карте устройства, а также — за обработку ввода со стороны пользователя. Он содержит различные экраны и органы управления. Уровень взаимодействия с пользователем может поддерживать скины, если есть необходимость сделать интерфейс удобным при работе на разных устройствах.
Итоги
Подведем итоги рассмотрения архитектур трех приложений.
- Архитектура клиентского приложения может быть представлена иерархией из пяти системных уровней:
- Инфраструктурный уровень содержит библиотеки, которые используются во всем приложении.
- Уровень модели данных содержит классы, описывающие предметную область.
- Уровень сервисов предоставляет услуги для пользователя. К таким услугам относятся: компиляция, прокладка маршрута, поиск координат по адресу и т.д. Каждая услуга помещается в отдельный модуль, который называется сервисом.
- Уровень редактирования предназначен для создания и редактирования документов. Он также поддерживает возможность отмены операции.
- Уровень взаимодействия с пользователем отвечает за представление данных в удобном для пользователя виде, а также — за обработку ввода. Он содержит различные органы управления.
- Каждый уровень может содержать один или несколько модулей, или же быть пустым. В последнем случае он остается в пятиуровневой модели только из общесистемных соображений.
- Количество модулей, расположенных на уровне, зависит от типа приложения. Если разрабатывается приложение, предназначенное для редактирования различных документов, то будут насыщенными уровни редактирования и взаимодействия с пользователем. Если же создается приложение, нацеленное на оказание услуг пользователю, то будет насыщенным уровень сервисов в то время, как уровень редактирования будет небольшим.
- Сложность модели данных зависит от объема данных и от требований по производительности. В ряде случаев модель данных можно реализовать в виде самосериализуемых в XML классов. И этого будет достаточно. В других случаях потребуется создать базы данных со сложными структурами данных, оптимизированные для произвольного доступа. При использовании таких баз данных потребуется разработка программ-компиляторов, которые тоже относятся к модели данных.
- Если требуется разработать линейку приложений, позволяющих редактировать или отображать однотипные данные (например, графы), то необходимо разделить модель данных на одну обобщенную и несколько специализированных (по числу разрабатываемых приложений). Такое разделение пройдет и через вышестоящие уровни: уровень редактирования и уровень взаимодействия с пользователем.
Литература
- Document/View Architecture
- Blueprint Visual Scripting/Unreal Engine 4 Documentation
- Introduction to Undo Architecture
- Gregory, Jason. Game Engine Architecture
- Руководство Microsoft по проектированию архитектуры приложений, 2-е издание
- Лебедев К.А., Сычев С.В. О потерянном уровне
- Фаулер, Мартин. Архитектура корпоративных программных приложений. – Пер. с англ. – М.: Издательский дом «Вильямс», 2006. – 544 с.: ил.
- @cobiot. Охота на мифический MVC. Обзор, возвращение к первоисточниками и про то, как анализировать и выводить шаблоны самому
- @cobiot. Охота на мифический MVC. Построение пользовательского интерфейса
Автор благодарит своих коллег за помощь при подготовке статьи.


