Внезапно, будучи в полном расцвете сил, маркетинговая лошадка по кличке «Big Data» вдруг приказала долго жить. Gartnerв в августе 2015 года исключил Big Data из числа прорывных технологий (emerging technologies) и удалил ее с графика Hype Cycle. В исследовании, озаглавленном “The Demise of Big Data, Its Lessons and the State of Things to Come” («Смерть Больших Данных, извлеченные уроки и ситуация в будущем»), говорится, что это было сделано, чтобы перевести дискуссию о Больших Данных из области спекуляций в практическую плоскость. В утешение нам, скорбящим по Big Data, аналитики говорят, что эта технология просто уже выросла из «цикла ажиотажа» и, дескать, перешла в следующий класс – в класс технологий продуктивного использования. Ведь никто же не говорит сегодня о реляционных СУБД или WiFi, но все этими вещами пользуются. Не волнуйтесь, граждане, жива ваша Big Data.
Гм. Как-то не верится. С кривой Hype Cycle есть два выхода: первый – это когда технология действительно достигает плато продуктивности и за ней престают следить так пристально – как за повзрослевшим ребенком; второй вариант – это когда технология устаревает так и не достигнув стадии зрелости – умерла, так умерла, своего рода естественный отбор. В Hype Cycle Gartner мониторит около 2000 инновационных технологий, и нет ничего необычного, что каждый год какие-то из них погибают — никто не сочиняет по ним пространных некрологов, как мы наблюдаем в случае с Big Data.

Так что же все-таки произошло? Почему Gartner пустил под нож эту славную лошадку? Ей бы еще скакать и скакать – интерес публики к ней отнюдь не угас. Это мы видим на графике GoogleTrends: рост числа запросов стабилизировался, но признаков падения еще нет.

Ну, да, пик популярности миновал, Big Data стала потихоньку спускаться в долину разочарованя (Trough of Disillusionment–букв. ‘корыто разочарования’), но это еще не приговор. Многие проходят фазу столкновения с суровой реальностью после эйфории от всеобщего внимания и все-таки попадают на плато продуктивности. Могла бы и Big Data спокойно себе развиваться – но нет же! Зачем-то понадобилось объявить на весь мир о ее кончине.
Зонтик оказался слишком большим
Возможно, дело в том, что Big Data — это типичный зонтичный термин, и в какой-то момент стало ясно, что зонтик оказался слишком большим. На волне ажиотажа все, что угодно стали относить к Big Data – все, что связано с хранением и анализом данных, лишь бы попасть в модный тренд. Разумеется, в отсутствие точных определений базового термина и стека технологий нельзя обозначить и четкие границы рынка, а, следовательно, невозможно строить сколько-нибудь ответственные прогнозы. Может быть поэтому — чтобы не оказаться в какой-нибудь неловкой ситуации из-за слишком широкой трактовки самого понятия Big Data, аналитики Gartner и решили от него избавиться. (Это моя гипотеза.)
Кстати, Джон Мэши (JohnR. Mashey), Chief Scientist, SGI, который в 1998 году одним из первых ввел в обиход термин Big Data , вообще не считал это какой-то особенной своей заслугой: «Это слишком простой термин – я использовал один ярлык для очень разных вещей, и мне хотелось наиболее простой и емкой фразой передать, что границы возможностей компьютеров постоянно расширяются.»
Что ж, термин действительно оказался очень емким и прилипчивым – о Больших Данных вдруг заговорили даже те, у кого их кот наплакал, какие-то сотни гигабайт. Данные растут! Сенсация! На стенку лезет пресса! О Big Data стали писать специализированные и деловые издания, даже гламурные журналы. Вполне закономерно, что это привело к профанации термина, и серьезные заказчики стали его чураться. Наступила полная путаница – BI это тоже Big Data или нет? Хранилища данных и аналитические инструменты – это один рынок или разные? И так далее. В итоге, в Gartner решили с 2015 года выпускать пять отдельных «циклов ажиотажа», которые более четко очерчивают несколько предметных областей, связанных с хранением, управлением и анализом данных:
• Advanced Analytics and Data Science;
• Business Intelligence and Analytics;
• Enterprise Information Management;
• In-Memory Computing Technology;
• Information Infrastructure.
Пусть это выглядит более скучно, чем Big Data, но так будет лучше. Только едва ли публика так легко расстанется с полюбившейся ей игрушкой. Big Data = Big Marketing. Мы еще много-много-много раз услышим знакомые заклинания, что нас окружают пета-экза-зетта-йота-байты и надо с этим что-то делать!
Иллюзия простоты: любой вопрос – любой ответ
Вторая беда с Big Data была в ее обманчивой простоте. По крайней мере так это преподносилось широкой аудитории. Возьмите все ваши данные, загрузите в Hadoop (благо он бесплатный) и наслаждайтесь — скрытые прежде закономерности проявятся сами собой.
Помните, на заре Big Data, году в 2008 появился сервис Google Flu Trends (GFT), который вроде как регистрировал начало эпидемии гриппа быстрее и точнее, чем врачи? В его основе лежало предположение, что, когда приходит грипп, люди начинаю активно искать в интернете лекарства и статьи про способы лечения, поток запросов, связанных с гриппом резко возрастает, а из анализа этих данных можно сделать вывод об уровне распространения вируса в каком-то регионе. Красивая идея, но, увы, ложная. Это стало окончательно ясно в 2013 году, когда GFT ошибся с определением пика эпидемии на 140%. И все потому, что под этим не было никакой внятной математической модели, лишь допущения на уровне здравого смысла. Увы, этого недостаточно, чтобы давать точный прогноз. Корпорация Google тихо похоронила проект, а люди – на то они и люди – одни (кто не прочитал свежих публикаций) по-прежнему преподносят GFT как торжество Big Data, а другие – как полный провал. (Например, вот: )
У этой истории есть еще и вторая сторона: кто сказал, что данные медиков абсолютно точны и достоверны? Ведь грипп – это же просто клондайк для фармкомпаний, продавцов марлевых масок и всей структуры здравоохранения. Потому что как только официально объявлена эпидемия, тут же выделяются дополнительные средства из бюджета на борьбу с ней. Как вы, наверное, догадываетесь, есть много возможностей манипулирования статистическими данными, чтобы заинтересованным сторонам добиться нужного результата. А телевидение и СМИ еще больше раскачивают ситуацию. Так что, на самом деле при помощи GFT мы анализируем не распространение вируса, а лишь уровень озабоченности людей гриппом, что далеко не одно и то же. То есть, это инструмент социологии, а не медицины.
Мнимые закономерности на основе статистики
Технологии Big Data действительно позволяют находить разнообразные корреляции в любых данных. Например, что с XVI века до наших дней сильно сократилось число пиратов и одновременно выросла среднегодовая температура. Означает ли это, что численность пиратов влияет на глобальное потепление? Что за чушь! Конечно же нет! Однако, во многих других случаях ответ может быть не столь очевиден – наблюдаем ли мы причинно-следственную связь или случайное совпадение.
Поэтому скажем честно: модели, основанные только на статистике, фактически моделями не являются, ибо они не обладают предсказательной силой. Не надо обманывать себя и других. А что мы видим на рынке Big Data? Сплошь и рядом — якобы научные «модели покупательского поведения», корреляции всего со всем, если человек купил А, он точно купит и Б. Но, позвольте спросить, почему? Так свидетельствуют Большие данные!

Увы, это огромная системная проблема. В общественных и социальных науках, политологии, маркетинге, психологии, экономике, антропологии на самом деле нет сколько-нибудь строгой теории – теории в том смысле, как это понимают физики. «Вся наука — или физика, или коллекционирование марок» – сказал Эрнест Резерфорд, когда получил известие о присуждении ему Нобелевской премии по химии в 1908 году. И он был абсолютно прав.
Ведь, как известно, нет ничего практичнее хорошей теории! Поэтому все эти забавы с цифрами могут дать результат, который совпадет с реальностью лишь по воле случая. Например, из графика прошлых колебаний цены на нефть совершенно не следует, какой она окажется в будущем. (Просто ради интереса – сравните прогнозы аналитиков с фактическими данными. Будет 50/50, если не хуже.)
Отлично показывает ущербность статистических моделей Нассим Талеб, рассказывая об ошибке индюшки: «Мясник откармливает индюшку тысячу дней; с каждым днем аналитики все больше убеждаются в том, что мясники любят индюшек «с возрастающей статистической достоверностью». Мясник продолжает откармливать индюшку, пока до Дня благодарения не останется несколько суток. Тут мясник преподносит индюшке сюрприз, и она вынуждена пересмотреть свои теории – именно тогда, когда уверенность в том, что мясник любит индюшку, достигла апогея и жизнь индюшки вроде бы стала спокойной и удивительно предсказуемой.»

Примерно также себя ощущали владельцы торговых павильонов возле метро до 9 февраля – арендные ставки растут, с мэрией все вопросы решены, все хорошо. А тут бац! – и бульдозеры. Могла бы Big Data предсказать такой поворот событий? Вряд ли. Поэтому глядя на красивые модели прежде всего стоит поинтересоваться, на основании какой теории они построены. Или хотя бы гипотезы.
К счастью, надежда, что вслед за физикой и другие науки обретут прочный теоретический фундамент, все-таки есть. Станислав Лем в «Сумме технологии» еще в начале 1960-х годов писал: «Общая тенденция математизации наук (в том числе и таких, которые до сих пор по традиции не использовали математических средств), охватив биологию, психологию и медицину, постепенно проникает даже в гуманитарные области — правда, пока еще скорее в виде отдельных «партизанских налетов»; это можно заметить, например, в области языкознания (теоретическая лингвистика) или теории литературы (применение теории информации к исследованию литературных, в частности поэтических, текстов).»
Без математической модели не добудешь ответ из озера данных
Без труда не выловишь и рыбку из пруда — пока не построишь математическую модель явления или предметной области, никаких достоверных ответов из озер данных не получишь. Вообще говоря, озера данных (data lakes) продвигаются поставщиками как платформы управления данными масштаба предприятия, чтобы анализировать данные из различных источников в нативном формате, говорит Ник Эудекер (Nick Heudecker), директор по исследованиям Gartner. Идея очень проста: вместо того, чтобы загружать данные в специализированное хранилище, можно слить их в «озеро» в формате, в котором они поступили из внешних систем. Это сильно удешевляет проект и избавляет нас от сложностей, связанных с очисткой и трансформацией. А дальше кто угодно может их анализировать, пользуясь палочкой-выручалочкой Big Data. Красиво, да?
Следует сказать, что компании недооценивают риски такого подхода. К 2018 году 90% внедренных озер данных будут бесполезны потому что они будут переполнены информацией, собранной неизвестно с какой целью. (Gartner, Strategic Planning Assumption, Gartner BI Summit, 2015). Данные в озере могут быть неконсистентны и не иметь метаданных, поэтому реально только очень опытные аналитики, хорошо знающие контекст, смогут сливать и согласовывать данные из разных источников. Однако, это уже какая-то алхимия. Сегодня мы получим один ответ на свой запрос, а завтра может быть другой – в зависимости от квалификации и настроения аналитика. Можно ли принимать серьезные бизнес-решения на такой зыбкой почве? Не думаю. Прежде, чем вбрасывать аналитические данные в контур управления, нужно разработать математическую модель, которая поможет эти данные правильно интерпретировать. Иначе не получится ничего, кроме игрушек для менеджеров – а ну-ка построим такой график, а теперь другой!
Самая сексуальная работа 21-го века
Логично, что наблюдается большой спрос на специалистов по Data Science. Средняя зарплата «ученого по данным», согласно исследованию Glassdoor, составляет 114 808 долларов, тогда как средняя зарплата обычного статистика находится на уровне 75 000 долл. McKinsey предсказывает, что к 2018 году США столкнутся с нехваткой 190 тысяч data scientists и 1.5 миллиона менеджеров с навыками использования аналитических данных для принятия бизнес-решений. Сегодня дефицит этих специалистов так велик, что на работу берут и без профильного образования по математике и программированию. Harvard Business Review назвал работу ученого по данным самой сексуальной работой 21-го века . В корпорациях даже появились должности директоров по данным и аналитике — chief data officers или chief analytics officers.
Поскольку работа эта новая, какого-либо канонического определения, кто такой data scientist и тем более профессионального стандарта еще не сформировалось. Некоторые шутят, что data scientist–это аналитик, живущий в Калифорнии, но вообще-то требования к этим специалистам различаются, аналитик и «ученый по данным» – это не одно и то же. Объединяет же их академическое любопытство, способность делать выводы и доходчиво о них рассказывать.

Источник.
Правда, злые языки предрекают, что уже к 2025 году все эти хипстеры от Big Data, получающие сейчас большие деньги, останутся без работы. Аналитиков-людей заменит искусственный интеллект – и целая армия новоиспеченных data scientists вовсе не понадобится. Ну, поживем – увидим.
Почему все-таки данные большие?
Как известно, Big Data характеризуется тремя «V»: Volume, Velocity, Variety – объем, скорость, разнообразие. Первым, определяющим параметром идет объем. Но откуда пошла такая мода говорить о Больших данных?
С этим как раз все просто. В конце 90-х разработчики систем визуализации в Silicon Graphics, которая на тот момент была признанным лидером в ИТ-индустрии и выполняла множество заказов для студии Disney, NASA и других клиентов, столкнулись с тем, что данные не помещались в оперативной памяти, а при обращении к диску все начинало тормозить и нельзя было выдать качественную видео-картинку, даже если использовать самые мощные по тем временам рабочие станции.
В 1997 году на 8-й конференции IEEE по визуализации Майкл Кокс и Дэвид Эллсворс (Michael Coxand David Ellsworth) из NASA делали доклад о своей работе по вычислительной гидродинамике. Им нужно было показывать результаты расчетов на экране, для чего приходилось идти на различные ухищрения – об этом и была их статья “Application-controlled demand paging for out-of-corevisualization” («Управляемый приложением спрос на подкачку данных вне ядра визуализации»). Вот что они писали: «Визуализация представляет интересный вызов для компьютерных систем: наборы данных в основном настолько велики, что они превосходят емкость основной памяти, локального диска и даже удаленного диска. Мы называем это проблемой больших данных.»
Насколько тогда велики были данные? Собственно, наборы данных, используемые в расчетах Кокса и Эллворса были порядка 100-500 ГБ. А параметры компьютеров SGI смотрите в таблице:

То есть, изначально это была сугубо инженерная проблема – как при ограниченных ресурсах компьютера обеспечить визуализацию различных моделей. И заметьте, что big data тогда писали еще с маленькой буквы!
Тема вычислений в памяти сегодня по-прежнему актуальна, только масштабы выросли. В 2012 году SAP анонсировала самую большую in-memory базу данных HANA объемом 100 ТБ, способную хранить миллиард записей. MarketsandMarkets прогнозирует, что глобальный рынок вычислений в памяти (In-Memory Computing – IMC) вырастет с USD 5.58 млрд. долл. в 2015 до 23.15 млрд. долл. к 2020 году, со среднегодовым приростом (CAGR) порядка 32.9% в течение этого периода. (Это что касается второй ‘V’ — Velocity.)
Где данных реально много – XLDB
Большинство презентаций на наших конференциях по Big Data повторяет одну и ту же мысль: «давайте анализировать данные о потребителях, чтобы больше продавать». По правде говоря, это как-то мелко – и в прямом, и в переносном смысле. В прямом – потому что объемы данных в коммерции, банкинге или даже в телекоме и рядом не лежали с объемами научных данных. А в переносном – потому что едва ли оправданно тратить столько интеллектуальных усилий на то, чтобы продать лишнюю пачку памперсов.
Действительно огромные массивы данных вы найдете не в бизнесе, а в Большой науке – это астрономия, физика, науки о Земле, науки о жизни. Новые инструменты научных исследований достигли сегодня поистине циклопических размеров и производят невообразимые объемы данных, хранить которые ученые настроены вечно. Например, Large Synoptic Survey Telescope (LSST) с основным зеркалом диаметром 8,4 метра способен заснять всю доступную площадь неба всего за несколько ночей. Телескоп снабжен 3.3 Гигапиксельной цифровой камерой, которая за ночь производит 30 ТБ данных, а за все время работы накоплен архив более чем 200 ПБ!
Но это еще цветочки. Возьмем Большой адронный коллайдер (LHC). Его главный детектор ATLAS (A Toroidal LHC ApparatuS) при всех своих гигантских размерах (длина 46 метров, диаметр 25 метров и вес 7000 тонн) еще генерит данные с фантастической производительностью. Одно событие (то есть, столкновение частиц) дает нам примерно 25 МБ данных. Вроде немного, да? Но событий этих – 40 миллионов в секунду! Итого мы имеем 1 ПБ сырых данных в секунду. Разумеется, такой поток информации мы не в силах записывать в реальном времени, поэтому приходится выбирать, что сохранить для дальнейшего изучения. Но даже если отфильтровать 100 тысяч наиболее интересных событий (в секунду, не забываем, в секунду!) все равно получается около 1 ПБ в год. А подобных датчиков на LHC – семь. Вот и считайте…
Чтобы ответить на этот вызов, в 2007 году команда по масштабируемым системам данным в SLAC, которая как раз отвечала за проектирование и разработку 100-Петабайтного хранилища для телескопа LSST, инициировала организацию на базе Стэнфордского университета сообщества по разработке сверхбольших СУБД (XLDB — Extremely Large Data bases). Точного определения, что значит «сверхбольшие» нет, это как говорят, подвижная цель. По состоянию на сегодня речь идет об объемах порядка нескольких петабайт.
Одним из результатов деятельности этого сообщества стал opensource-проект SciDB – многомерная СУБД для научных, геопространственных, финансовых и промышленных данных, созданная под руководством Майкла Стоунбрекера (Michael Stonebraker), одного из пионеров реляционных баз данных. Стоунбрекер был техническим директором Informix, занимался разработкой Ingres (а потом и Postgres), Illustra, Cohera, StreamBaseSystems, Vertica, VoltDB, TamrиParadigm4.
После 40 лет разработки баз данных, Стоунбекер пришел к выводу, что мир изменился и позиция «один размер для всех» больше не работает, что жизнь не вписывается в реляционную модель. Его SciDB– это пост-реляционная база данных, которая может работать с очень большими массивами информации в распределенных дата-центрах. «В 1980-х «ответом» на все вопросы была обработка бизнес-данных, и это делалось с помощью реляционных баз. Мы старались натянуть SQL на все, что только можно, но это был неестественный путь,» — говорит Стоунбекер. Для научных СУБД нужна иная модель. SciDB нативно работает с многомерными массивами и может выполнять над ними алгебраические операции, выигрывая у РСУБД в скорости и эффективности хранения данных. SciDB не использует Map Reduce и совсем не похожа на Hadoop. Причина в том, что операции линейной алгебры весьма трудно реализовать в концепции Map Reduce. SciDB отлично масштабируется и активно используется в больших проектах, типа архива LSST.
От Big Data к продвинутой аналитике
Термины приходят и уходят, не всегда точно отражая суть вещей. Пускай говорить Big Data стало немодно, однако сами задачи никуда не делись – все равно нужно хранить весьма большие объемы данных, управлять ими и, самое главное, – извлекать из них знания, получать ответы на самые разнообразные запросы. Причем делать все нужно максимально быстро. Аналитика как область профессиональной деятельности была, есть и будет. Новые инструменты будут востребованы – и не только статистические. На подходе когнитивные семантические технологии и искусственный интеллект. Да какое там на подходе! Фанаты IBM Watson организуют кампанию по выдвижению его в президенты США!

С другой стороны, будет расширяться круг пользователей, аналитические технологии будут встроены во многие продукты и станут незаметными для людей – как сегодня мы не замечаем, скажем уровень сетевых протоколов и другие инфраструктурные вещи. Они просто есть и работают. Также и аналитика из умственного упражнения для избранных превратится в сугубо утилитарную технологию, тем не менее, пронизывающую все сферы деятельности.
Big Data – феномен культуры
Надо признать, что сейчас Большие Данные стали феноменом массовой культуры – как и Большой взрыв. Но это уже совсем другая история, совсем не про технологии. Эту проблематику начинают осваивать философы – нужно ли нам столько данных и как жить в мире, перенасыщенном информацией. (См. напр. М. Эпштейн » Информационный взрыв и травма постмодерна»).
На самом деле история о том, как данные стали большими, началась за много лет до нынешней шумихи вокруг Big Data. Про «информационный взрыв» — это термин впервые был использован в 1941 году, согласно Oxford English Dictionary, начали говорить еще семьдесят лет назад – пишет Джил Пресс (GilPress), колумнист Forbes в статье «Очень короткая история Больших данных» (A Very Short History Of Big Data).
Как ученые раньше работали с информацией? Шестьдесят лет назад — читали все вышедшие статьи; сорок лет назад — все статьи по теме + аннотации в реферативных журналах; двадцать лет назад – все аннотации по теме плюс некоторые статьи. А что можно успеть прочитать сегодня из этой лавины публикаций, которая на нас обрушилась?
Вот вам еще одно новое словечко– «datanami», по аналогии с цунами. Весьма удачное название сайта по Big Data. А что, очень хороший образ для нынешней картины. Может быть, вообще грядет идеальный информационный шторм, кто знает?
Big data сами по себе мертвы, говорит Михаил Свердлов, директор по стратегическому развитию ИТ в Уральском банке реконструкции и развития. Но идея больших данных осталась в прикладных кейсах и физических объектах – беспилотниках и предметах IoT. Все чаще внимание обращается на машинное обучение и безопасное хранение информации.
… Так, может, большим данным еще предстоит большое будущее?
По миру шагают саммиты, конференции и недели big data. И если последние несколько лет назад евангелисты больших данных воодушевленно рассказывали про наше светлое будущее, то сейчас это больше похоже на панихиду. После выхода очередных магических кривых Gartner гвоздь в крышку гроба big data не забил разве что ленивый.
Я предлагаю разобрать эту историю немного под другим углом, а точнее, под четырьмя углами. Рассмотрим:
- 4 основных проблемы, которые могут возникнуть при работе с большими массивами данных (специально уже не говорю big data – этот термин все похоронили);
- 3 проблемы, которые могут испортить самую правильную инициативу по использованию данных в компании;
- А также поймем, куда Gartner спрятал все осколки, на которые распалась громада больших данных;
- … и как банки могут получать доход от экспорта своих данных или монетизировать чужие данные для себя.
Одни проблемы с этими big data?
Данных много, а пользы нет? Только проверенные компании, которые специализируются на Big DataПочти месяц назад в Бостоне закончилась конференция Big Data Innovation Summit. Туда съехались ведущие эксперты, прошло больше 60 сессий, где рассматривались самые большие проблемы и пути их решения в работе с большими данными.
Чтобы не было необходимости смотреть все доклады с конференции, специально для вас я собрал «самую соль». Итак, по большому счету, все жаловались, что управление большими наборами данных может быть проблематичным. Лидеры данных сейчас стоят перед вызовом работы с количеством данных, анализом, хранением, конфиденциальностью и их интерпретацией.
Теперь разберем немного подробнее.
- Где я должен хранить свои данные?
Чем больше данных есть у организации, тем, с одной стороны лучше. Но, другой стороны, тем больше проблем с хранением и управлением возникает. Merrill Lynch из Bank of America рассказывал про то, как они реализовали облачную инфраструктуру под эти нужды, а коллеги из StubHub, MapQuest дополнили это рассказом про Apache Innovation.
- Могу ли я делать это безопасно?
Пять из шести самых крупных по объему и ущербу утечек данных всех времен произошли в течение последних двух лет. В то же время несоблюдение законов о защите данных может привести к искам и существенным потерям. Политика конфиденциальности и безопасности данных уже слишком важна и ее нельзя игнорировать. Чтобы понять, о чем тут речь, можно посмотреть слайды, которые подготовил главный научный сотрудник Счетной палаты правительства США (US Government Accountability Office) Timothy Persons. В своем выступлении он рассказал, как защищает данные Америки.
- False positives
Я не смог найти релевантного аналога в русском языке термину «false positives», поэтому оставил в оригинале. Эксперты говорят, что очень трудно сделать полезные выводы из больших данных без конкретного приложения аналитической модели с хорошим базисом для гипотез. В истории с большими данными быстрые решения иногда могут привести как раз к этим самым «ложным срабатываниям». Jack Levis, директор по управлению процессами UPS, объяснил, как организациям решать проблемы и задачи с помощью аналитики.
- Неправильные выводы
Работа с большими данными может как направить нас в сторону более точного прогнозирования поведения клиентов и просто будущего, так и увести в сторону. Последнее может произойти, если принимать информацию за чистую монету, без поправки на человеческий фактор, который имеет основное влияние на участие в процессе подготовки данных, анализе и выводах.
Как вишенка – доклад Riley Newman, главного по данным в Airbnb, «A/B тестирования в реальном мире».
А тут доступны все материалы конференции.
Если вы хотите все-таки почитать тексты в первоисточнике – вот свежий Big Data Innovation Magazine.
Fail
Gartner в своем исследовании говорят, что почти все компании полагаются на большие данные при принятии более взвешенных и обоснованных решений. А всего год назад они утверждали, что 3 из 4 организаций уже инвестируют или будут инвестировать в большие данные на горизонте ближайших двух лет. Пока опустим тему, что большие данные ушли из Garter уже в сентябре, про это – в третьей части нашего «детектива».
А пока – вот 3 распространенных сценария, которые, по мнению ребят из Lavastorm Analytics, могут убить все ваши начинания в работе с данными:
- Данные ради данных – их будет невозможно применить в разрезе конкретного бизнес-процесса и бизнес-контекста;
- Традиционные ETL-системы и подходы, которые сейчас реализованы в компаниях, не потянут сложность и комплексность работы с большими массивами данных;
- Проекты превратятся в «лоскутное одеяло» и, соответственно, не смогут обеспечить комплексного решения бизнес-потребностей.
Подробно можно почитать в отчете компании.
Gartner здесь, Gartner там
Наверняка все уже видели последний Gartner 2015 Hype Cycle, который говорит о том, что big data ушла, а на ее место встало машинное обучение.
Если вы не следили за ситуацией, то вот картинки 2014 и 2015 годов.
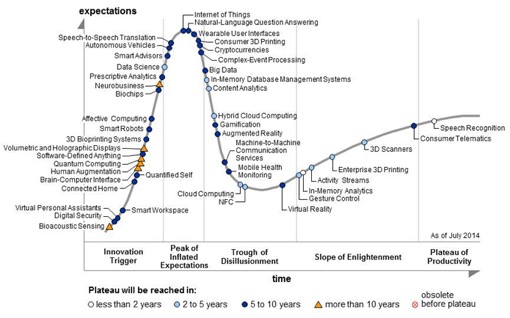
Gartner 2014 Hype Cycle
И для сравнения –

Gartner 2015 Hype Cycle
Конечно, было бы совсем обидно, если бы сначала раззадорились, а потом большие данные попросту ушли бы в небытие. Но нет: все распалось на более осязаемые и прикладные кейсы. На пике теперь нас ждут автономные автомобили, IoT, «умная пыль» и другие новые интересные технологии. Но это в следующей декаде, а пока поговорим про то, куда «приземлились» большие данные.
- Автономные транспортные средства. Успешно перескочив с пре-пика 2014 года на пик в 2015 году, беспилотные машины обосновались в краткосрочных планах крупнейших автоконцернов мира;
- Интернет вещей (сеть интеллектуальных объектов вокруг нас с координацией деятельности) неизменно остается на пике второй год подряд. Считается, что нам предстоит чуть ли не следующая индустриальная революция, и, как вы понимаете, в основе всего – данные и аналитика;
- Машинное обучение, впервые появившись на кривой Gartner, сразу же попало мимо пика завышенных ожиданий, и теперь занимает место больших данных.
По теме: Как устроены нейронные сети
- Цифровой гуманизм (digital humanism), по мнению экспертов Garner, делает лучше людей, а не технологии. Носимые гаджеты, интернет вещей и машинное обучение дали развитие человеку в цифровом мире;
- Citizen data scientist: еще одна новинка сезона. По словам Александра Линдена из Gartner, уже сейчас стоит выращивать новое поколения специалистов по данным, сitizen data scientists, компетенции которых будут лежать на стыке бизнеса, математики и социальных наук. Это позволит им более качественно накладывать аналитику на массивы данных;
- Цифровые навыки (digital dexterity) – тоже новичок списка.
Сегодняшние сотрудники обладают в большей степени цифровой ловкостью. Они сами разрабатывают и монтируют беспроводные сети дома, связывают различные устройства и управляют ими, свободно используют приложения и веб-сервисы практически в каждом аспекте своей личной жизни.
– Мэтт Кейн, вице-президент по исследованиям Gartner.
Gartner наметил несколько способов, в которых ИТ-организации должны использовать цифровые навыки своих сотрудников.
- Безопасность данных (data security) вызывает сегодня большой вопрос, как я уже упоминал ранее, и остается одним из вызовов на ближайшее время.
Что-то из этого списка опять будет раздуто евангелистами в новые прорывные вещи, а другое исчезнет, не получив развития. Я же предлагаю перейти к самой прикладной части нашего расследования по большим данным – к непосредственному применению. В банке.
Моя big data круче твоей
Сразу же за саммитом в Бостоне в России проходила конференция «Большие данные 2015», где я предложил свое видение того, как можно монетизировать данные в банке. Сейчас я хочу поделиться основными темами своего рассказа.
Всю ситуацию с big data, на мой взгляд, можно описать всего одной цитатой:
Big data – как подростковый секс. Каждый говорит об этом, никто толком не знает, как это делается, и каждый уверен, что все остальные это делают. Поэтому все говорят, что тоже этим занимаются…
– Dan Ariely.
За последние 2 года работы с проектами по клиентским данным в Дирекция стратегического развития ИТ в «УБРИР» получила десятки подтверждений. Мы рассмотрели за это время порядка 15 компаний и 28 кейсов, которые мы реализовывали для клиентской аналитики, скоринга, стратегий взыскания. В итоге пришли к тому, что big data – это красивая маркетинговая история, кейсы же реализуются на данных и с помощью машинного обучения.
По теме: Как технологии помогают коллекторам собирать долги
Слайдами с кейсами и направлениями монетизации данных в финансовых организациях я и предлагаю закончить наш разговор.
С радостью отвечу на все возникшие вопросы.
Фото на обложке: Shutterstock.
13 Июля 2020 13:24
13 Июл 2020 13:24
|
В противодействии пандемии COVID-19 большую роль играют средства аналитики. Использование баз данных, которые в режиме реального времени пополняются данными о заболевших и результатами клинических испытаний потенциальных методов лечения (а их было проведено в разных странах более 500), помогает прогнозировать темпы распространения нового инфекционного заболевания, искать методы его лечения и разрабатывать тактику ведения тяжелых пациентов.
Аналитика после пандемии: тренды меняются
Эпидемия коронавируса и вызванный ею мировой кризис заставили аналитические компании пересмотреть свои прогнозы. Коснулось это и средств аналитики. Оценив, как разные типы и виды аналитических технологий и инструментов отработали в кризисной ситуации, развивающейся по всему земному шару, в Gartner внесли коррективы в список 10 важнейших тенденций развития аналитических технологий в перспективе 3-5 лет, сформулированных в прошлом году. Вот как он выглядит с учетом изменений.
1. Искусственный интеллект станет распределенным и «ответственным»
На место дополненной аналитики, занимавшей первую строчку в рейтинге Gartner в 2019 г., пандемия вывела в лидеры рейтинга перспективных аналитических инструментов технологии искусственного интеллекта, машинного обучения, оптимизации и обработки естественного языка, которые позволили получать информацию о динамике распространения нового вируса, а также об эффективности принятых мер для борьбы с ним. Тем более, к концу 2024 г., по прогнозу Gartner, 75% предприятий будут иметь «рабочие» решения на базе ИИ.
Кроме того, в Gartner ожидают, что инвестиции в нейроморфные микросхемы позволят вынести искусственный интеллект на границы ИТ-систем и развернуть его на периферийном оборудовании. Это уменьшит зависимость средств аналитики от «центральных» ИТ-систем и от пропускной способности каналов передачи данных. Это, в свою очередь, будет способствовать появлению более масштабируемых решений.
В Gartner также указывают на то, что ИИ должен быть «ответственным», базироваться на «прозрачных» моделях. Тогда его решениям можно доверять.
2. Аналитика с учетом контекста и снижение роли дашбордов
Средства дополненной аналитики, обработки естественного языка, потоковой аналитики и совместной работы в перспективе 3-5 лет будут полностью автоматизированы и смогут настраиваться для решения задач, стоящих перед обращающимся к ним специалистам. При этом в каждом случае будет учитываться роль сотрудника и контекст использования аналитических методов и инструментов.
Как результат, количество времени, которое пользователи аналитических систем проводят в предварительно определенных панелях инструментов, дашбордах, уменьшится. И, соответственно, значение этих популярных сейчас инструментов — тоже.
3. Аналитика для принятия решений
К 2023 году, прогнозирует Gartner, треть крупных компаний и корпораций будут иметь в своем штате аналитиков, специализирующихся в области средств моделирования принятия решений (Decision Intelligence). Математическая основа для проектирования, моделирования, согласования, выполнения решений, а также методы отслеживания и настройки моделей принятия решений в контексте бизнес-результатов, создаются уже сегодня.
Decision Intelligence — это относительно новая дисциплина, которая рассматривает все аспекты процесса принятия решений, дополняя науку о данных достижениями социальных наук и теории управления.
Тем организациям, которые хотят использовать инструменты Decision Intelligence в своих организациях, Gartner напоминает, что технологии управления решениями и их моделирования при необходимости применения нескольких логических и математических методов должны быть автоматизированы, задокументированы и проверены на практике.
4. X-аналитика
Термин X-аналитика введен Gartner как зонтичный для разных видов контента, структурированного и неструктурированного, привлеченного из разных источников. Во время пандемии искусственный интеллект и X-аналитика сыграли решающую роль в поиске тысяч научных статей, новостных источников, постов в соцсетях и данных клинических испытаний, чтобы помочь медицинским работникам и специалистам-организаторам здравоохранения прогнозировать распространение заболевания, оценивать его потенциал, находить новые методы лечения и выявлять уязвимые группы населения. Так что в обновленном рейтинге Gartner они вытеснили с четвертой строчки графовую аналитику.
В будущем средства X-аналитики, как считают в Gartner, сыграют решающую роль в прогнозировании стихийных бедствий и других серьезных кризисов. Ведущим разработчикам аналитических средств надо обратить внимание на работу с X-данными, правда в Gartner считают, что инновации, скорее всего, будут исходить от облачных провайдеров, и стартапов.
5. Расширенное управление данными
Средства расширенного управления данными также используют методы машинного обучения и искусственного интеллекта для оптимизации работы предприятия. Они могут исследовать большие выборки оперативных данных и на их примере повышать безопасность, оптимизировать конфигурацию и производительность корпоративных систем.
6. Облако как данность
К 2022 году публичные облачные сервисы будут необходимы для проведения в жизнь 90% инноваций в области данных и аналитики. Эксперты Gartner рекомендуют лидерам рынка в области работы с данными сосредоточить свои усилия на создании облачных аналитических сервисов. В этом аспекте важно расставить приоритеты и выделить нагрузки, которые могут использовать облачные возможности и сосредоточиться на оптимизации затрат на их перевод в облако.
7. Данные и аналитика: два мира сталкиваются
Раньше работа с данными (например — создание и обслуживание баз данных) и средства аналитики традиционно рассматривались и управлялись как отдельные объекты. Вендоры, предлагающие средства создания сквозных рабочих процессов с помощью средств дополненной аналитики, стирают различия между этими сферами работы. В результате, в течение ближайших 3-5 лет, прогнозирует Gartner, спектр возможностей по работе с данными расширится, с аналитическими приложениями смогут работать не только профильные специалисты, но и «гражданские разработчики» — сотрудники бизнес-подразделений.
8. Появятся маркетплейсы и биржи данных
К 2022 году 35% крупных организаций станут либо продавцами, либо покупателями данных через официальные торговые площадки (в 2020 году, по оценке Gartner, доля таких предприятий — 25%).
Илья Маркелов, «Лаборатория Касперского»: Подход «внедрил и забыл» недопустим для SIEM
безопасность

Торговые площадки и биржи данных предоставляют единую платформу для консолидации предложений. Они обеспечивают централизованный доступ к X-аналитике и к уникальным наборам данных, создают эффект масштаба и снижают затраты на закупку данных.
Однако для успешной работы маркетплейсы и биржи данных должны разработать справедливую и прозрачную методологию, которая определит принцип управления этим дорогостоящим активом.
9. В аналитику придет блокчейн
Технологии блокчейна решают две проблемы в области данных. Во-первых, они позволяют полностью отследить всю цепочку транзакций; во-вторых — он обеспечивает прозрачность в сложных сетях из множества участников.
На предприятиях будут использоваться биткойны и умные контракты (хотя и ограниченно), а кроме того, на блокчейн перейдут базы бухгалтерских данных.
Алексей Шовкун, «Информационные системы и сервисы»: Наша философия изначально строилась на использовании open source
ит в госсекторе

Эксперты Gartner рекомендуют позиционировать технологии блокчейна как дополнение к существующей инфраструктуре управления данными.
10. Ценность данных будут формировать взаимосвязи
Замыкают новый топ трендов развития аналитики Gartner технологии графовой аналитики — набора методов, ориентированных на анализ структуры связей между объектами. К 2023 году они будут способствовать быстрой констектуализации для принятия решений в 30% компаний по всему миру, где будут использоваться для исследования отношений между организациями, людьми и транзакциями.
С помощью средств графовой аналитики данных будут находиться связи, которые нелегко было выявить с помощью традиционных аналитических инструментов. Например, в условиях, когда мир стремится быстро и правильно реагировать на пандемии, текущую и будущую, графовые технологии помогут связать пространственные данные на смартфонах жителей и выявить людей, находившихся в контакте с лицами, чьи тесты на коронавирус дали положительный результат.
В сочетании с алгоритмами машинного обучения эти технологии могут использоваться для анализа тысяч источников данных и документов с тем, чтобы помочь врачам и специалистам в области организации здравоохранения быстро найти новые возможные методы лечения или факторы, которые способствуют негативным проявлениям у некоторых пациентов.
Подводя черту под обновленным Gartner перечнем трендов, надо отметить, что опыт их применения в условиях пандемии подтвердил, что средства аналитики с технологиями искусственного интеллекта будут иметь первостепенное значение для прогнозирования, подготовки и быстрого реагирования на любой глобальный кризис и его последствия.
На конференции Gartner IT Symposium/Xpo 2022 аналитики отвечали на вопрос, каким образом ИТ-директора могут бороться с неопределенностью.
Компания Gartner представила главные стратегические прогнозы на 2023 год и последующий период. Аналитики изложили свой взгляд на то, каким образом лидеры бизнеса и руководители ИТ-служб могли бы переосмыслить ранее сделанные предположения и воспользоваться моментом, превратив неопределенность в уверенность.
По мнению Gartner, неопределенность несет в себе не меньше возможностей, чем рисков. Ключом к раскрытию этих возможностей является переосмысление предположений (особенно тех, что исходят из доцифрового прошлого) о характере выполнения работы, выстраивании отношений между клиентами и поставщиками и развитии текущих тенденций. Постоянство удобно, но оно наносит ущерб росту любой компании, которая стремится занять лидирующие позиции в современном цифровом мире, наполненном неизвестностью. Прогнозы Gartner свидетельствуют о создании условий для того, чтобы руководители могли воспользоваться неопределенностью, бросить вызов традиционному мышлению и изменить ожидания, сохранив при этом темпы поступательного движения.
На симпозиуме Gartner IT Symposium/Xpo аналитики Gartner представили 10 основных стратегических прогнозов.
1. К 2027 году на полностью виртуальные рабочие пространства будет приходиться 30% роста инвестиций предприятий в технологии метавселенной, а офисный опыт будет переосмыслен. Поскольку сотрудники продолжают стремиться к более гибким сценариям работы, в метавселенных появятся виртуальные рабочие пространства для поддержки нового иммерсивного опыта. Под полностью виртуальными рабочими пространствами понимаются созданные компьютером среды, в которых группы сотрудников могут собираться вместе, используя персональные аватары или голограммы.
По мнению аналитиков Gartner, поставщики существующих решений для совещаний должны предлагать клиентам технологии метавселенной и виртуального рабочего пространства, иначе они рискуют утратить свои позиции на рынке. Виртуальные рабочие пространства обеспечивают такую же экономию финансовых ресурсов и времени, что и видеоконференции, но при этом улучшают вовлеченность и повышают качество связи и взаимодействия.
2. К 2025 году при отсутствии экологически чистых технологий искусственный интеллект будет потреблять больше энергии, чем вся человеческая рабочая сила, вместе взятая. Это в значительной степени подрывает смысл стратегии нулевого выброса углерода. В условиях, когда искусственный интеллект получает все более широкое распространение и требует более сложных моделей машинного обучения, он потребляет больше данных, вычислительных ресурсов и мощностей. Если нынешние способы использования искусственного интеллекта останутся неизменными, энергетические ресурсы, необходимые для машинного обучения и связанных с ним процессов хранения и обработки данных, могут составить к 2030 году до 3,5% от общего объема энергопотребления.
По мере осознания защитниками искусственного интеллекта масштабов порождаемых им выбросов, предпочтение все чаще отдается экологически чистым методам, включающим в себя применение специализированного оборудования, снижающего энергопотребление, эффективное написание программного кода, трансферное обучение, методы работы с небольшими объемами данных, федеративное обучение и многое другое.
По оценкам Gartner, искусственный интеллект открывает огромные перспективы для дальнейшего повышения операционной эффективности, намного перевешивающие его собственное негативное влияние. Если искусственный интеллект начнет применяться более широко и эффективно, глобальные выбросы углекислого газа удастся сократить еще на пять-десять процентов.
3. К 2026 году атаки, направленные на отказ в обслуживании и проводимые гражданами с использованием виртуальных помощников (citizen-led denial of service, cDOS) в целях прекращения операций, станут самой быстрорастущей формой протеста. Протесты против бизнеса и правительственных организаций все активнее перемещаются в цифровую сферу. За атаками cDOS стоят не хакеры, а обычные люди, обращающиеся к помощи виртуальных помощников.
Согласно прогнозам Gartner, к 2025 году 37% клиентов при взаимодействии со службой поддержки начнут использовать виртуальных помощников для связывания ее ресурсов. Такое вполне легитимное с виду взаимодействие станет выражением протеста. К 2024 году граждане смогут парализовывать контакт-центры компаний, входящих в список Fortune 500, инициируя атаки, направленные на отказ в обслуживании, при помощи виртуальных помощников.
4. К 2025 году мощные облачные экосистемы консолидируют 30% поставщиков, уменьшив выбор и контроль клиентов над своим программным обеспечением. Крупнейшие поставщики облачных сервисов (cloud service providers, CSP) создают экосистемы, в рамках которых наряду с избранными независимыми поставщиками программного обеспечения (independent software vendors, ISV) предлагают заранее интегрированные и скомпонованные сервисы. Экосистемы CSP обладают достаточным для существенного повышения производительности потенциалом, который формируется за счет упрощения выбора, интеграции и компоновки программных компонентов. По мере развития экосистем CSP потребность в инструментах независимых поставщиков программного обеспечения будет уменьшаться, поскольку CSP регулярно предлагают новые функции и оперативно внедряют инновации благодаря быстроте и гибкости облачной разработки.
5. К 2024 году совместные суверенные партнерства, санкционированные регулирующими органами, сумеют повысить доверие заинтересованных сторон к глобальным облачным брендам и будут способствовать дальнейшей глобализации ИТ. По мере роста глобальных взаимосвязей сообществ и их зависимости от цифровой информации появляется все больше нормативных и законодательных актов, направленных на осуществление контроля за гражданами и их защиту, а также обеспечение постоянной доступности важнейших услуг. Правительства и коммерческие регуляторы ужесточают политику в части использования ресурсов облачных провайдеров, не имеющих отношения к данному региону, для критически важных или чувствительных рабочих нагрузок.
В связи с последними геополитическими событиями и санкциями, направленными против конкретных платформ, спрос на суверенные облачные решения растет. Санкционирование правительствами и регулирующими органами конкретных совместных инициатив облачных провайдеров и их партнеров на местах соответствует ужесточению требований к суверенности и при этом способствует продолжению технической глобализации.
6. К 2025 году «нестабильность рабочей силы» приведет к тому, что 40% организаций столкнутся с существенными потерями в бизнесе, а это в свою очередь будет способствовать смене стратегии в отношении персонала с привлечения на сохранение. Проблемы Великой отставки (Great Resignation), начавшейся в 2021 году, эмоционального выгорания и тихого ухода ставят перед руководством бизнеса новые задачи в части поиска, привлечения, найма и удержания талантов. В своих корпоративных заявлениях и финансовых отчетах организации все чаще будут акцентировать внимание на существенных стратегических сдвигах вследствие неспособности поддерживать существующие продукты или услуги и предлагать новые возможности из-за проблем с персоналом.
По мнению аналитиков Gartner, волатильность рабочей силы напрямую коррелирует с корпоративными моделями управления и эффективностью процессов, что оказывает влияние на финансовые показатели. Обсуждение вопросов устойчивости должно вестись на уровне генерального директора и членов совета директоров, не оставаясь исключительной прерогативой отдела кадров.
7. К 2025 году доля акционеров, лояльно относящихся к инвестициям в прорывные технологии, удвоится, что сделает их жизнеспособной альтернативой традиционным расходам на НИОКР, направленным на увеличение темпов роста. Пытаясь найти для себя конкурентные преимущества в условиях неопределенности и волатильности, лидеры отрасли все чаще соглашаются на высокорискованные инвестиции в технологии с неизвестной доходностью и потенциальным риском провала.
Успешные предприятия понимают, что на самом деле главный риск, с которым они сталкиваются, заключается в том, что ими делается слишком мало и слишком поздно. Внедрение революционных подходов позволяет предприятиям добиться максимальной выгоды от прорыва, регулируя склонность к риску и повышая толерантность к неудачам.
8. К 2027 году модели платформ социальных сетей начнут сдвигаться от «клиента в качестве продукта» в сторону «платформы в качестве клиента» – к децентрализованной личности пользователей, продаваемой через рынки данных. Нынешняя парадигма, при которой пользователям приходится многократно подтверждать свою личность в онлайн-сервисах, вызывает вопросы с точки зрения эффективности, масштабируемости и безопасности. Web3 позволяет внедрять новые децентрализованные стандарты идентификации, которые обладают рядом серьезных преимуществ – усиливается контроль над данными, которыми делятся пользователи, исключается необходимость повторной проверки подлинности в разных службах, поддерживаются общие службы аутентификации.
9. К 2025 году устранение рядом организаций задокументированных гендерных различий в оплате труда приведет к уменьшению дискриминации женщин на 30%, что должно способствовать снижению кадрового дефицита.
Опросы Gartner неизменно показывают, что уровень компенсации является главным фактором привлечения и удержания талантов, однако только 34% сотрудников считают, что их заработная плата справедлива. Общепринятой методологии оценки равенства в оплате труда не существует, что ставит перед организациями задачу выявления и учета гендерных различий при расчете зарплаты. Формируется зарождающийся рынок программных средств, предназначенных для оценки справедливости оплаты труда, а поставщики предоставляют дополнительные способы анализа и моделирования данных, связанных со справедливой оплатой.
10. К 2025 году треть удачных инвестиционых решений будет основываться не на рентабельности инвестиций, а на таких показателях, как благополучие сотрудников, их эмоциональное выгорание и удовлетворенность брендом. Инвестиции в благополучие сотрудников и обслуживание клиентов начнут приносить прямую финансовую отдачу за счет роста выручки и снижения затрат. Еще более значительное влияние они оказывают на ценность бренда и репутацию компании, а также на привлечение и удержание сотрудников и клиентов. Такие показатели с трудом поддаются количественной оценке с точки зрения краткосрочных финансовых выгод, но влияют на долгосрочные финансовые результаты, определяющие стоимость предприятия.
Использование традиционных моделей ROI при принятии инвестиционных решений может снизить или полностью нивелировать нефинансовые преимущества. По мнению аналитиков Gartner, организации, которые используют более широкие подходы к оценке, начнут переключать свое инвестиционное внимание на долгосрочный рост, прорывные инициативы и инновации.
Время на прочтение
8 мин
Количество просмотров 8.7K
Оракул технологического мира Gartner регулярно и охотно делится с обществом своими наблюдениями относительно текущих трендов. Эксперты компании составили подборку из 10 трендов в сфере данных и аналитики, которые стоит учитывать ИТ-лидерам в 2021 году – от искусственного интеллекта до малых данных и применения графовых технологий.
Материал Gartner является отличной пищей к размышлению, а в некоторых случаях он может сыграть важную роль при принятии стратегических решений. Для того, чтобы оставаться в курсе основных трендов и в то же время не тратить ресурсы на собственный анализ, уберечься от ошибок субъективного мнения, удобно пользоваться предоставленным отчетом, перевод которого и предлагается в этой статье.

Источник
Коротко о трендах
В предложенном материале Gartner выделяет ряд трендов в индустрии, связанной с машинным обучением и искусственным интеллектом. Не стоит ожидать, что статья откроет новые горизонты: в ней собраны те особенности и тренды, которые уже прошли этап новаторства, а также этап привлечения ранних последователей, однако если не обратить должного внимания на отмеченные тенденции, то можно опоздать даже попасть в категорию отстающих последователей. Кроме того, в статье явно прослеживаются рекламные и побудительные элементы, нацеленные на аудиторию, влияющую на инновации в своей области бизнеса, т.е. на основную аудиторию Gartner. В процессе перевода не удалось уйти от упомянутых элементов, однако рекомендуется к ним относиться снисходительно, т.к. эти рекламные вставки перемежаются ценной информацией. Некоторые из трендов напрямую связаны с изменениями в индустрии, к которым привела эпидемиологическая обстановка. Другие — с растущей популярностью систем автоматического принятия решений и использованию ИИ в бизнес-аналитике. Отдельно хочется отметить тренд, связанный с графовыми методами, которые быстро развиваются и набирают все большую популярность. Тем не менее, некоторые из них носят скорее номинальный характер. Одним из таких номинальных трендов на первый взгляд кажется термин XOps, в котором Gartner объединяет направления DataOps, ModelOps и DevOps, комментируя свое видение следующим образом: «Умножение дисциплин Ops, вытекающих из лучших практик DevOps, вызвало значительную путаницу на рынке. Тем не менее, их согласование может принести значительные преимущества организациям, которые способны гармонизировать эти дисциплины… Практики XOps объединяют разработку, развертывание и обслуживание, чтобы создать общее понимание требований, передачу навыков и процессов для мониторинга и поддержки аналитики и артефактов ИИ». В этом, казалось бы, номинальном тренде, прослеживается мысль, отсылающая к теме Франкенштейна: мало состыковать отдельные рабочие части компании, т.к. они будут функционировать хаотично и не согласовано, жизнь и полезная активность начнется после того, как эти разрозненные части будут синхронизированы и гармонизированы. Но не буду раскрывать все карты сразу, предлагаю читателю самостоятельно ознакомиться с находками Gartner далее.
Как изменилась работа data-специалистов
По словам экспертов Gartner, на фоне COVID-19 организации, использующие традиционные методы аналитики, которые в значительной степени полагаются на большие объемы исторических данных, осознали одну важную вещь: многие из этих моделей больше не актуальны. По сути, пандемия изменила все, сделав множество данных бесполезными. В свою очередь, «прогрессивные» команды, занимающиеся обработкой данных и аналитикой, все больше переходят от традиционных методов искусственного интеллекта, основанных на больших данных, к классу аналитики, использующей «малые» или более разнообразные данные.
Переход от больших данных к малым и широким данным – одна из главных тенденций в области данных и аналитики на 2021 год, которую выделяет Gartner. Этот тренд отражает динамику бизнеса, рынка и технологий, которую лидеры, работающие в области данных и аналитики, не могут позволить себе игнорировать, отмечают эксперты компании.
«Данные тенденции могут помочь организациям и обществу справиться с разрушительными изменениями, радикальной неопределенностью и реализовать возможности, которые они открывают, в течение следующих трех лет», – говорит Рита Саллам, вице-президент Gartner по исследованиям. – Руководители отдела обработки данных и аналитики должны заранее изучить, как использовать эти тенденции в критически важных инвестициях, которые увеличивают их возможности для прогнозирования, изменений и реагирования».
Каждая из тенденций соответствует одной из трех основных тем:
- Ускорение изменений в данных и аналитике: использование инноваций в области искусственного интеллекта, улучшенная возможность по компоновке, а также более гибкая и эффективная интеграция разнообразных источников данных.
- Операционализация ценности бизнеса посредством более эффективного использования XOps: позволяет лучше принимать решения и превращать данные и аналитику в неотъемлемую часть бизнеса.
- Принцип «все распределено»: предполагает гибкое соотнесение данных и идей для расширения возможностей более широкой аудитории людей и объектов.
Тренд № 1. Продвинутый, ответственный, масштабируемый ИИ
Более умный, ответственный, масштабируемый ИИ позволит улучшить алгоритмы обучения, интерпретируемых систем и сократить время оценки. Организации начнут требовать гораздо большего от систем искусственного интеллекта, и им нужно будет выяснить, как масштабировать технологии — до сих пор это было сложной задачей.
Хотя традиционные методы ИИ могут в значительной степени полагаться на исторические данные, учитывая, как COVID-19 изменил бизнес-ландшафт, исторические данные могут больше не иметь значения. Это означает, что технология ИИ должна быть способна работать с меньшим количеством данных с помощью методов «малых данных» и адаптивного машинного обучения. Эти системы ИИ также должны защищать приватность, соблюдать федеральные правила и минимизировать предвзятость для поддержки этичного ИИ.
Тренд № 2. Составные данные и аналитика
Целью составных данных и аналитики является использование компонентов из множества данных, аналитики и решений ИИ для создания гибкого, удобного, адаптированного под потребности пользователей интерфейса, который позволит руководителям связывать аналитические данные с бизнес-действиями. Запросы клиентов Gartner показывают, что в большинстве крупных организаций имеется более одного «стандартного корпоративного» инструмента аналитики и бизнес-аналитики.
Составление новых приложений на основе комплексных бизнес-возможностей каждой компании способствует повышению производительности и гибкости. Составные данные и аналитика не только будут способствовать сотрудничеству и развитию аналитических возможностей организации, но и расширят доступ к аналитике.
Тренд № 3. Матрица данных как основа
По мере того, как данные становятся все более сложными, а цифровой бизнес ускоряется, матрица данных представляет собой архитектуру, которая будет поддерживать составные данные и аналитику, а также ее различные компоненты.
Матрица данных сокращает время на проектирование интеграции на 30%, развертывание на 30% и поддержку на 70%, поскольку технологические разработки основаны на возможности использования / повторного использования и комбинирования различных стилей интеграции данных. Кроме того, матрицы данных могут использовать существующие навыки и технологии из data-хабов (data hubs), озер данных (data lakes) и хранилищ данных (data warehouses), а также внедрять новые подходы и инструменты для будущего.
Тренд № 4. От больших данных – к малым и широким данным
Малые и широкие данные, в отличие от больших данных, решают ряд проблем для организаций, которые сталкиваются со все более сложными вопросами, касающимися ИИ, и проблемами, связанными с редкими вариантами использования данных. Широкие данные — с использованием методов «X-аналитики» — позволяют анализировать и объединять многообразие малых и широких, неструктурированных и структурированных источников данных для повышения осведомленности о контексте и принимаемых решениях. Малые данные, как следует из названия, могут использовать модели данных, которые требуют меньше данных, но все же предлагают полезные инсайты.

Источник
Тренд № 5. XOps
Целью XOps (данные, машинное обучение, модель, платформа) является достижение эффективности и экономии за счет масштаба с использованием передовых практик DevOps, а также обеспечение надежности, повторного использования и повторяемости при одновременном сокращении дублирования технологий и процессов и обеспечении автоматизации.

Тренд 5. XOps. Источник
Эти технологии позволят масштабировать прототипы и обеспечить гибкий дизайн и гибкую оркестровку управляемых систем принятия решений. В целом, XOps позволит организациям использовать данные и аналитику для повышения ценности бизнеса.
Тренд № 6. Проектирование интеллекта принятия решений
Интеллект при принятии решений — это дисциплина, которая включает в себя широкий спектр решений, в том числе традиционную аналитику, искусственный интеллект и сложные адаптивные системные приложения. Инженерная аналитика решений применяется не только к отдельным решениям, но и к последовательностям решений, группируя их в бизнес-процессы и даже сети принятия срочных решений.
Это позволяет организациям быстрее получать информацию, необходимую для стимулирования действий для бизнеса. В сочетании с возможностью компоновки и общей структурой данных инженерный анализ решений открывает новые возможности для переосмысления или перестройки того, как организации оптимизируют решения и делают их более точными, воспроизводимыми и отслеживаемыми.
Тренд № 7. Данные и аналитика как ключевая бизнес-функция
Руководители бизнеса начинают понимать важность использования данных и аналитики для ускорения инициатив цифрового бизнеса. Вместо того, чтобы быть второстепенной задачей, выполняемой отдельной командой, данные и аналитика переключаются на основную функцию. Однако руководители предприятий часто недооценивают сложность данных и в конечном итоге упускают возможности. Если директора по данным (CDO) участвуют в постановке целей и стратегий, они могут увеличить стабильное производство стоимости бизнеса в 2,6 раз.
Тренд № 8. Графы в основе всего
Графовые подходы формируют основу современных данных и аналитики, предоставляя возможности для усиления и улучшения взаимодействия c пользователями, моделей машинного обучения и интерпретируемого ИИ. Хотя графические технологии не новы для данных и аналитики, произошел сдвиг в мышлении вокруг них, поскольку организации выявляют все больше вариантов их использования. Фактически, до 50% запросов клиентов Gartner о ИИ связаны с обсуждением использования graph-технологий.

Источник
Тренд № 9. Расширение пользовательского опыта
Традиционно бизнес-пользователи были ограничены использованием преднастроенных панелей аналитики (dashboard) и ручных инструментов исследования данных. Чаще всего это предполагало, что панели аналитики ограничивались работой дата-аналитиков или гражданских специалистов по данным, которые изучали заранее определенные вопросы.
Однако Gartner полагает, что в дальнейшем эти информационные панели будут заменены автоматизированными, интерактивными, мобильными и динамически генерируемыми аналитическими данными, адаптированными к потребностям пользователей и доставляемыми в их точку потребления. И это, в свою очередь, означает переход знаний от ограниченного круга специалистов в области данных к любому сотруднику организации.
Тренд № 10. Данные и аналитика «впереди планеты всей»
По мере того, как все больше технологий анализа данных начинает существовать за пределами традиционных центров обработки данных и облачных сред, они все больше приближаются к физическим активам. Это уменьшает непрозрачность решений, построенных на данных, что и обеспечивает их большую ценность в реальном времени.
Перенос данных и аналитики на периферию позволит группам специалистов по работе с данными расширить возможности и влияние на различные части бизнеса. Также это позволит предоставить решения в ситуациях, когда данные не могут быть перемещены из определенных регионов по юридическим или нормативным причинам.
В заключение
Сложно переоценить слова Gartner: наблюдаемые тренды, безусловно, играют немаловажную роль в дальнейшей судьбе индустрии. В отмеченных трендах явно выделяется фокус на инженерную составляющую индустрии ИИ: поддержка и контроль качества моделей машинного обучения, ответственность и масштабируемость ИИ, повсеместность использования и т.д. Это наблюдение лишний раз подтверждает то, что долина разочарования, связанная с проектами по применению ИИ уже пройдена, мир принял технологию и теперь более актуальными становятся вопросы интеграции, оптимизации, контроля качества и надежности.
Нас, представителей компании CleverDATA, активно использующих ИИ в повседневной работе, отчасти уже коснулись упомянутые в статье тренды: мы пришли к аналогичным выводам через собственный опыт. Благодаря выделенным в статье тенденциям, у читателей есть возможность подготовиться к переменам в индустрии ИИ, например, освоить методы работы с графовыми нейронными сетями или взяться за освоение элементов профессии Data Engineer. Предусмотрительный работник готовит не только сани летом, но и актуальные в будущем навыки уже сейчас.
Консалтинговая компания Gartner представила топ технологий и стратегий 2022 года, которые окажут значительное влияние на бизнес-среду в ближайшие пять-десять лет
Консалтинговая компания Gartner в рамках симпозиума Gartner IT Symposium / Xpo Americas анонсировала основные стратегические и технологические тенденции, которые компаниям необходимо изучить в 2022 году.
Генеративный искусственный интеллект (Generative Artificial Intelligence)
Генеративные модели ИИ представляют собой методы машинного обучения, которые изучают контент или объекты и используют их для создания новых, полностью оригинальных данных. Они могут использоваться для создания программных кодов, разработки лекарств, а также в рамках целевого маркетинга. По оценкам Gartner, к 2025 году на генеративный искусственный интеллект будут приходиться около 10% всех производимых данных.
Фабрики данных (Data Fabric)
За последнее десятилетие число разрозненных хранилищ данных и приложений резко выросло, в то время как количество персонала в командах по обработке данных и аналитике либо осталось неизменным, либо сократилось. В связи с этим в мире появляется спрос на фабрики данных — гибкие, но устойчивые интеграции между платформами и бизнес-пользователями. За счет встроенной аналитики с их помощью можно улучшить обработку информации, сократив усилия по управлению данными до 70% и при этом снизить время окупаемости.
Территориально-распределенные предприятия (Distributed Enterprise)
С распространением удаленных и гибридных моделей работы традиционные офисно-ориентированные предприятия, состоящие из географически разбросанных сотрудников, отходят на задний план. Безусловно, подобные перемены требуют серьезных изменений, однако Gartner прогнозирует, что в 2023 году доходы 75% предприятий, использующих преимущества территориально-распределенной модели работы, будут расти на 25% быстрее, чем у их конкурентов.

Облачные платформы (Cloud-Native Platforms)
Облачные платформы необходимы для обеспечения цифрового услуг в любой точке мира. Они предоставляют масштабируемые и эластичные ИТ-возможности для создания технологий, что сокращает время их окупаемости и снижает затраты. По прогнозам Gartner, облачные платформы будут служить основой для более чем 95% новых цифровых инициатив к 2025 году по сравнению с менее чем 40% в 2021 году.

Автономные системы (Autonomic Systems)
Автономные системы заявили о себе уже в 2021 году, — благодаря способности динамически изменять свои собственные алгоритмы без внешнего обновления ПО они могут быстро адаптироваться к новым условиям, как то делают люди. Gartner прогнозирует, что автономные системы станут обычным явлением в области роботов, дронов и производственных машин.
Интеллект в принятии решений (Decision Intelligence)
Интеллект в принятии решений — это практическая дисциплина, используемая для улучшения процесса принятия решений путем четко разработанной системы decision-making, оценки результатов, их управления и улучшения с помощью обратной связи. По предварительным оценкам, в ближайшие два года треть крупных организаций будут использовать данный метод для структурированного принятия решений с целью повышения конкурентного преимущества.
Составные приложения (Composable Applications)
В турбулентные времена в компаниях растет потребность в адаптации к постоянно меняющемуся бизнес-контексту, — для этого необходима такая технологическая архитектура, которая поддерживает быстрое, безопасное и эффективное изменение приложений. Архитектура составного приложения обеспечивает такую адаптируемость, а компания, которые имплементируют данный подход, опередят конкурентов на 80% по скорости реализации новых функций.

Гиперавтоматизация (Hyperautomation)
Гиперавтоматизация обеспечивает ускоренный рост и повышение устойчивости бизнеса за счет быстрой идентификации, проверки и автоматизации как можно большего числа процессов. Исследование Gartner показывает, что наиболее эффективные группы гиперавтоматизации сосредоточены на трех ключевых приоритетах:
- повышение качества работы,
- ускорение бизнес-процессов,
- повышение гибкости принятия решений.
Вычисления, укрепляющие конфиденциальность (Privacy-Enhancing Computation, PEC)
Методы PEC, которые защищают личную и конфиденциальную информацию на уровне данных, программного или аппаратного обеспечения, обеспечивают безопасный обмен, объединение и анализ данных без ущерба для конфиденциальности. Gartner ожидает, что к 2025 году 60% крупных компаний будут использовать один или несколько методов вычислений, укрепляющих защиту данных пользователей.

Сеть кибербезопасности (Cybersecurity Mesh)
Архитектура сетей кибербезопасности (CSMA) — распределенный архитектурный подход к гибкому и надежному управлению кибербезопасностью. Она позволяет обеспечить интегрированную структуру безопасности и защиты всех активов, независимо от местонахождения. К 2024 году компании, внедряющие CSMA в свои экосистемы, сократят финансовые потери от определенных инцидентов безопасности на 90%.
Разработка искусственного интеллекта (AI Engineering)
Разработка систем на основе искусственного интеллекта — это комплексный подход к реализации моделей ИИ. К 2025 году 10% предприятий, внедряющих передовые методы разработки ИИ, будут приносить как минимум в три раза больше прибыли от своих усилий в области ИИ, чем 90% предприятий, которые этого не делают.
Совокупный опыт (Total Experience, TX)
Совокупный опыт — это бизнес-стратегия, сочетающая в себе такие элементы как мультиопыт, опыт клиентов, сотрудников и пользователей. Основная цель данного подхода — повысить доверие, удовлетворенность, лояльность и поддержку клиентов и сотрудников. Организации будут увеличивать выручку и прибыль за счет достижения адаптивных и устойчивых бизнес-результатов TX.
Большие данные представляют собой массивы информации, характеризующиеся колоссальными объемами, стремительно растущей скоростью накопления, разнообразием их формата представления как в виде структурированной, так и неструктурированной информации. Big Data также включают в себя комплекс инновационных методов и способов хранения и обработки информации с целью автоматизации, оптимизации бизнес-процессов, обеспечения принятия наиболее эффективных решений на основе накопленной информации.

Таким образом, большие данные характеризуются тремя основными признаками:
-
большой объем информации,
-
высокая скорость изменения информации,
-
разнообразие и разнородность данных.
Ниже представлены ключевые элементы, составляющие аналитику больших данных.
Рис. 1. Ключевые элементы, составляющие аналитику больших данных

Источник:
https://rubda.ru
Структура и объем рынка больших данных
В 2018 году объем глобального рынка Big Data и бизнес-аналитики (global big data and business analytics market) достиг 168,8 млрд долл. В соответствии с оценкой IDC, по итогам 2019 года объем глобального рынка больших данных увеличился на 12%, по сравнению с показателями предыдущего года, и достиг 189,1 млрд долл. Кроме того, в период 2018-2022 гг. предполагается рост рынка со среднегодовым темпом (CAGR) на уровне 13,2%. Таким образом, объем рынка может увеличиться до 274,3 млрд долл. к 2022 году.
ResearchAndMarkets прогнозирует возможные темпы роста глобального рынка Big data на уровне 19,7% ежегодно на период 2019-2025 гг.
Рис. 2. Динамика роста рынка больших данных, млрд долл.

Источник: Global big data and business analytics revenue from 2015 to 2022:
https://www.statista.com
В 2018 году выручка на рынке программного обеспечения больших данных составила 60,7 млрд долл. На конец 2019 года более половины выручки BDA обеспечили доходы, полученные от IT- и бизнес-сервисов – 77,5 млрд долл. и 20,7 млрд долл. соответственно. Размер выручки в сегменте аппаратного обеспечения составил около 23,7 млрд долл. Доход от программного обеспечения больших данных достиг 67,2 млрд долл. По данным IDC, ожидаемые темпы роста (CAGR) в период с 2018-2023 гг. в этом сегменте поднимутся до отметки в 12,5%.
Согласно исследованию Fortune Business Insights, объем глобального рынка технологий Big Datа, оцененный в 2018 году в 38,6 млрд долл., увеличится к 2026 году до 104,3 млрд долл., демонстрируя темпы роста (CAGR) на уровне 14% в период с 2019 по 2026 гг.
Рис. 3. Доля сегментов рынка в общем объеме выручки, %

Источник: Big Data Technology Market Size, Share, Demand & rowth:
https://www.fortunebusinessinsights.com
По данным Grand View Research, к 2025 году глобальный рынок Big Data как услуги (global big data as a service (BDaaS)) достигнет 51,9 млрд долл., при этом CAGR составит 38,7% в период 2019-2025 гг.
География рынка Big Data
С географической точки зрения по результатам 2019 года наиболее крупным стал рынок США с объемом доходов в 100 млрд долл. Второе и третье место по объему заняли Япония (9,6 млрд долл.) и Великобритания (9,2 млрд долл). Также в пятерку крупнейших рынков вошли КНР (8,6 млрд долл.) и Германия (7,9 млрд долл.).
В Аргентине и Вьетнаме наблюдаются наиболее высокие показатели прироста за пятилетний период (CAGRs – 23,1% и 19,4%). Третье место по уровню CAGR занял Китай (19,2%), что к 2022 году может обеспечить выход этой страны на второе место по уровню доходов.
Рис. 4. Доля стран-лидеров в общем объеме рынка больших данных, %

Источник: 9 IDC Forecasts Revenues for Big Data and Business Analytics Solutions Will Reach $189.1 Billion This Year with Double-Digit Annual Growth Through 2022:
https://www.idc.com
Драйверами рынка больших данных и бизнес-аналитики выступают 5 отраслей, на которые, по оценке IDC, приходится около половины инвестиций (91,4 млрд долл.):
-
банковская сфера,
-
дискретное производство,
-
специализированные услуги,
-
непрерывное производство,
-
федеральное/центральное правительство.
При этом наибольший рост рынка в будущем обеспечат такие направления, как розничная торговля (15,2% CAGR), а также операции с ценными бумагами и инвестиционные услуги (15,3% CAGR).
Рис. 5. Инвестиции в технологии больших данных по отраслям, %

Источник: 9 IDC Forecasts Revenues for Big Data and Business Analytics Solutions Will Reach $189.1 Billion This Year with Double-Digit Annual Growth Through 2022:
https://www.idc.com
Крупнейшие поставщики на рынке больших данных
Согласно отчету Wikibon (2018 Big Data and Analytics Market Share Report), в 2018 году (по данным 2017 года) в пятерку крупнейших поставщиков решений на рынке Big Data вошли такие компании, как IBM, Splunk, Dell, Oracle и AWS. И, по данным исследования Global Big Data Market Forecast 2019-2027, проведенного Inkwoodresearch, в 2019 году эти компании сохранили свои позиции в качестве лидеров рынка.
Российский рынок пока занимает незначительную долю в мировом предложении и потреблении информационных технологий. Однако в 2018-2019 гг. было принято немало решений и реализовано достаточное количество законодательных инициатив, способствующих развитию отечественного рынка Big Data.
По результатам опроса, проведенного International Data Corporation (IDC) и Hitachi Vantara в ходе исследования «Аналитика больших данных как инструмент бизнес-инноваций», более 55% российских организаций выделяют бюджет на внедрение технологий больших данных (участие приняли более 100 компаний со штатом от 500 чел.).
По состоянию на конец 2019 год Boston Consulting Group оценивает объем российского рынка больших данных в 45 млрд руб. с темпом прироста 12% в течение последних пяти лет.
Крупнейшие российские игроки рынка больших данных
В Ассоциацию больших данных (АБД), образованную в 2018 году, входят организации, представляющие собой наиболее крупных участников российского рынка Big Data:
-
ПАО «Сбербанк»,
-
АО «Газпромбанк»,
-
АО «Тинькофф Банк»,
-
АО «КИВИ Банк» (QIWI),
-
ООО «Яндекс»,
-
ООО «Мэйл.ру»,
-
ПАО «Мегафон»,
-
ООО «Единыйфактор» («oneFactor»),
-
ПАО «Ростелеком».
В июле 2019 года было объявлено о присоединении к Ассоциации Аналитического центра при Правительстве РФ.
Объем российского рынка больших данных
Согласно данным, приведенным Ассоциацией участников рынка больших данных, объем рынка Big Data в России составляет 10-30 млрд руб. При этом, в соответствии с усредненными прогнозами отечественных и иностранных экспертов, предполагается рост этого показателя в 10 раз – до отметки 300 млрд руб. к 2024 году.
Основные потребители технологий Big Data в России
Сегодня лидерами по внедрению технологий в российских компаниях являются такие инструменты цифровизации, как роботизированная автоматизация бизнес-процессов, использование чат-ботов, инструментов анализа больших данных и предиктивной аналитики.
Технология анализа больших данных является наиболее часто внедряемой технологией среди российских компаний: 68% организаций на конец 2019 года уже опробовали внедрение инструментов анализа больших данных.
Рис. 6. Технологии, используемые среди российских компаний, %

Перечень инструментов, используемых для анализа больших данных, формируется в зависимости от отрасли компании.
Рис. 7. Индустрии использования больших данных в России, %

Сценарии развития рынка Big Data в России
В 2019 году участниками Ассоциации совместно с привлеченными внешними специалистами (в т.ч. Boston Consulting Group) была разработана стратегия развития рынка до 2024 года, включающая 5 возможных сценариев:
-
пессимистичный,
-
сценарий «бездействия»,
-
базовый,
-
оптимистичный,
-
«сценарий мечты».
В соответствии с разными вариантами прогноза рынок больших данных может обеспечить от 0,3% до 2,4% прироста ВВП, а объемы отрасли могут увеличиться на сумму от 20 до 230 млрд руб., по сравнению с показателями 2019 года.
Таблица 1. Сценарии развития рынка больших данных в России
|
Доступность данных |
Исследования и идеи |
Масштабирование |
Вклад БД в ВВП, 2024 г. против 2019 г. |
Отрасль БД в 2024 г. против 2019 г., млрд руб. |
|
|
Пессимистичный сценарий |
Активные ограничения на использование данных |
Отсутствует адресная поддержка |
Отсутствует адресная поддержка |
+0,3% |
+20 |
|
Сценарий бездействия |
Установленные регулятором ограничивающие прецеденты |
Отсутствует адресная поддержка |
Отсутствует адресная поддержка |
+0,5% |
+40 |
|
Базовый сценарий |
1.Упрощенный доступ и обработка |
3. R&D – «песочницы» для исследования БД |
5.Стратегия БД традиционных индустрий |
+1,2% |
+100 |
|
Оптимистичный сценарий |
2.Обеспечение возможности обмена/обогащения данных |
4.Финансирование инноваций и ресурсная экосистема |
6.Внутренние стимулы для инновационных отраслей |
+1,8% |
+160 |
|
Сценарий мечты |
Платформы для крупномасштабного обмена данными |
Специализированные государственные инвестиционные программы |
Финансовая поддержка экспорта |
+2,4% |
+230 |
Источник: Российские сценарии для Big Data:
https://rspectr.com
Реализация стратегии развития российского рынка Big Data
АБД будет продвигать 6 инициатив: 3 дадут умеренный эффект, остальные – более агрессивные по сложности имплементации и эффекту от БД.
Умеренный эффект:
1. Упрощенный доступ и обработка данных
-
Позволить пользователям одновременно и дистанционно давать согласие на несколько целей использования их данных;
-
Позволить компаниям обрабатывать персональные данные для широкого круга целей при соблюдении определенных требований;
-
Запустить массовую государственную цифровизацию в областях, релевантных для БД, с фокусом на стандартизацию данных.
3. R&D песочницы для исследования Больших Данных
- Определить законом контролируемую среду экспериментирования с ослабленным регулированием;
- Обеспечить вовлечение регуляторов для оптимизации одобрений при последующем крупномасштабном развертывании;
- Обеспечить «озера данных» со стандартизированными данными и технологические библиотеки.
5. Стратегии Больших Данных традиционных индустрий
- Создать стандарт для внедрения Больших Данных в компании с государственным участием;
- Ввести ориентированные на результат стимулы для компаний частного сектора;
- Создать проектный и технический кадровый резерв, чтобы помочь компаниям внедрять Большие Данные и обучать их команды.
Агрессивный эффект:
2. Обеспечение возможности обмена/обогащения данных
-
Позволить игрокам делиться анонимными персональными данными на коммерческой основе;
-
Поощрять обмен отраслевыми данными внутри и между отраслями через саморегулируемые стандарты;
-
Позволить государству делиться определенными типами релевантных данных с частным сектором.
4. Финансирование инноваций и ресурсная экосистема
-
Обеспечить инновационные команды выделенным доступом к «озерам данных» с труднодоступной отраслевой информацией;
-
Оптимизировать процессы бэк-офисного типа путем предоставления доступа к юристам, бухгалтерам и специалистам по патентам;
-
Внедрить инвестиционную платформу, соединяющую квалифицированных инвесторов с отобранными инициативами.
6. Внутренние стимулы для инновационных отраслей
-
Внедрить упрощенный процесс получения необходимых сертификатов и патентов для продуктов и услуг на основе Больших Данных;
-
Устранить выборочные барьеры для экспорта продуктов и сервисов, построенных на технологиях Больших Данных;
-
Провести кампании по повышению осведомленности об экспортном потенциале продуктов на технологиях Больших Данных.
Согласно базовому сценарию, в 2024 году в России эффект от внедрения продуктов и технологий больших данных увеличится на 1,2% как доля от ВВП.
Рис. 8. Базовый сценарий эффективности внедрения инструментов больших данных

Источник: Минэкономразвития РФ
Меры, направленные на реализацию стратегии, объединены в три основных блока:
-
повышение доступности данных,
-
проведение исследований в области больших данных (R&D),
-
масштабирование рынка.
Стратегия предусматривает создание R&D – «песочницы» для проведения экспериментов, внедрения мер по изменению законодательства, центра компетенций и др.
Согласно прогнозу IDC, к 2025 году общий объем цифровых данных, генерируемых во всем мире, вырастет более чем вчетверо – до 175 Зеттабайт с 40 Зеттабайт в 2020 году, в том числе благодаря растущему количеству IoT-устройств и датчиков. В соответствии с описанием главных атрибутов больших данных как «трех «V» (объем, многообразие, скорость), которое дает Gartner, эта нарастающая лавина данных будет все больше характеризоваться разнообразием типов информации, причем большая часть будет представлять собой постоянно меняющиеся потоки данных в реальном времени. Как результат, задача управления данными и их анализа значительно затрудняется. И это обусловливает многие из трендов, которые, по всей видимости, будут преобладать в ближайшие три года.
Ключевые технологические тренды Big Data
Gartner отмечает следующие 11 технологических трендов в области данных и аналитики, которые потенциально окажут значительное влияние на дальнейшее развитие рынка в течение последующих 3-5 лет:
| Технологический тренд | Описание |
| «Расширенная» (дополненная) аналитика (Augmented analytics) | Совершенствование процесса анализа за счет автоматизации процесса поиска, обработки данных с использованием технологий машинного обучения (Machine Learning (ML)) и искусственного интеллекта (Artificial Intelligence (AI)). Отмечается, что к 2020 году расширенная аналитика станет драйвером в области закупок инструментов бизнес-аналитики, а также платформ обработки информации. По данным ResearchAndMarkets, ожидается, что рынок расширенной аналитики вырастет с 4,8 млрд долл. в 2018 году до 18,4 млрд долл. к 2023 году при совокупном годовом темпе роста (CAGR) 30,6%. |
| «Расширенное» (дополненное) управление данными (Augmented data management) | Применение технологий AI и ML, позволяющих осуществлять автоматизацию и самонастройку процесса управления корпоративными данными (включая управление метаданными, качеством данных, интеграцию данных и баз данных). К 2022 году предполагается снижение объема «ручного» управления данными компаний на 45%. |
| Технологии обработки естественного языка (Natural language processing (NLP) and conversational analytics) | Согласно прогнозу экспертов, к 2021 году внедрение средств NLP повысит уровень распространения технологий интеллектуального анализа данных с 35% до 50%. Технология обработки естественного языка позволяет компьютерам понимать человека. Как результат, рядовые бизнес-пользователи смогут делать запросы к сложным массивам данных обычными словами и фразами – голосом или вводом с клавиатуры и получать такие же легко понимаемые результаты бизнес-анализа. По прогнозу Gartner, к концу 2020 года 50% аналитических запросов будут делаться на естественном языке или с помощью привычного поиска либо генерироваться автоматически. А по данным Ventana Research, 33% организаций ожидают, что к 2021 году запросы и ответы на естественном языке будут стандартной функцией инструментов бизнес-анализа. |
| Аналитика графов (Graph analytics) | По оценке Gartner, применение методов обработки графической информации и графических баз данных будет увеличиваться на 100% ежегодно в течение последующих 5 лет. Бизнес-аналитики создают все более сложные запросы к структурированным и неструктурированным данным, часто из нескольких приложений и источников. Выполнение таких сложных запросов в больших масштабах с использованием традиционных инструментов и языков запросов представляет собой очень трудную задачу. Графовые базы данных и инструменты аналитики и визуализации помогают справиться с этой задачей, показывая связи, существующие между узлами — людьми, локациями и объектами материального мира. Gartner прогнозирует, что использование графовой обработки и графовых баз данных будет удваиваться ежегодно в последующие несколько лет, что позволит «ускорить подготовку данных и создать более сложные и адаптивные методы анализирования данных». |
| Коммерческие инструменты искусственного интеллекта и машинного обучения (Commercial AI and machine learning) | Переход от использования платформ с открытым исходным кодом к применению специально разработанных коннекторов, подключающихся к open-source экосистеме, позволит реализовать функции управления моделями, проектами, а также предоставит возможность для преобразования и многократного использования данных, обеспечит интеграцию и прозрачность, недоступные в рамках open-source платформ. Разработчики ПО анализа данных всегда стремились предоставить возможности своей технологии более широкой аудитории обычных бизнес-пользователей и всех работающих с информацией. И это уже происходит благодаря так называемой интеллектуальной (augmented) аналитике. Gartner определяет интеллектуальную аналитику как использование технологий искусственного интеллекта, машинного обучения и обработки естественного языка для содействия в подготовке данных, понимании и трактовке результатов анализа, то есть в качестве расширения возможностей человека и традиционных способов формирования и использования аналитического контента. Интеллектуальная аналитика поможет специалистам и обычным сотрудникам, работающим с информацией, автоматизировать многие аспекты изучения данных, а также разработки и использования моделей данных. К 2022 году 75% решений для конечных пользователей будут создаваться с использованием коммерческих, а не открытых платформ. |
| Матрица данных (Data fabric) | Подходы к интеграции данных в виде логически организованной структуры для облегченного доступа и обмена в распределенной среде данных. |
| Объясняемый искусственный интеллект (Explainable AI) | Возможность формирования описательной модели на естественном языке, позволяющей обосновать автоматически сгенерированные решения и результаты, полученные на базе технологий AI. К 2023 году более 75% крупных организаций будут нанимать специалистов по поведению AI, обеспечению конфиденциальности и доверительных отношений с клиентом для снижения репутационных рисков. |
| Блокчейн в области данных и аналитики | Реализует взаимосвязь транзакций, активов, обеспечивает прозрачность и гарантии в сложных сетях взаимодействия участников. |
| Непрерывная интеллектуальная обработка данных (Continuous Intelligence) | Подход, при котором результаты аналитики в реальном времени интегрируются в бизнес-операции, происходит обработка потоковой контекстной информации, поступающей с датчиков IoT, и исторических данных, позволяющий моментально реагировать на изменения и предписывать поведение моделей. К 2020 году прогнозируется наличие функции непрерывного интеллектуального анализа в более чем 50% бизнес-систем. |
| Серверы «постоянной» памяти (Persistent memory servers) | Tехнология сохранения данных при отключении питания позволяет решить проблему ограниченности объемов памяти при возрастающем количестве данных; предоставляет возможность анализировать больше данных в оперативной памяти и в режиме реального времени; повышает энергоэффективность, операции с данными становятся более рациональными за счет уменьшения дублирования. |
| Ужесточение регулирования в сфере обращения с данными | Многие компании уже ощутили на себе ужесточение регулирования в обращении с данными с вступлением в силу Генерального регламента о защите данных (GDPR) в Евросоюзе в мае 2018 года. В 2020 году, с вводом Закона штата Калифорния о защите конфиденциальности потребителей (CCPA) и в свете растущих призывов ввести такие правила в масштабах всей страны, компании и организации в США встанут перед необходимостью внедрить строгий контроль за данными, обеспечением их защищенности и конфиденциальности. Все это окажет влияние на практику сбора, обработки, хранения и использования данных компаниями, и, в первую очередь, это касается данных потребителей. К 2021 году 25% организаций создадут новые центры передовых технологий управления данными и безопасности, что поможет снизить риск неправомерного использования или утечки, по прогнозу Ventana Research. Исследователи в сфере технологий управления данными и бизнес-анализа призваны сыграть ключевую роль в разработке и внедрении эффективных и надежных методов. |



