Добавлено 20 декабря 2021 в 13:19
Введение
Разработчики часто сталкиваются с необходимостью разработки многопоточных приложений, поэтому вопросы многопоточности требуют детального изучения. Давайте познакомимся с основными терминами, используемыми в источниках информации о многопоточности, рассмотрим задачи и проблемы многопоточности и изучим средства стандартной библиотеки C++, которые помогут создавать многопоточные приложения.
Основные определения
Многозадачность и многопоточность
Многозадачность (multitasking) – свойство операционной системы или среды выполнения обеспечивать возможность параллельной (или псевдопараллельной) обработки нескольких задач.
Многопоточность (multithreading) – свойство платформы (например, операционной системы, виртуальной машины и т. д.) или приложения, состоящее в том, что процесс, порождённый в операционной системе, может состоять из нескольких потоков, выполняющихся «параллельно», то есть без предписанного порядка во времени. При выполнении некоторых задач такое разделение может достичь более эффективного использования ресурсов вычислительной машины.
По-настоящему параллельное выполнение задач возможно только в многопроцессорной системе, поскольку только в них присутствуют несколько системных конвейеров для исполнения команд.
В однопроцессорной многозадачной системе поддерживается так называемое псевдопараллельное исполнение, при котором создается видимость параллельной работы нескольких процессов. В таких системах, однако, процессы выполняются последовательно, занимая малые кванты процессорного времени.
Процессы и потоки
В различных источниках информации можно найти много разных определений процессов и потоков. Такой разброс определений обусловлен, во-первых, эволюцией операционных систем, которая приводила к изменению понятий о процессах и потоках, во-вторых, различием точек зрения, с которых рассматриваются эти понятия.
В рамках данной серии статей предлагаю придерживаться следующих определений…
С точки зрения пользователя:
Процесс – экземпляр программы во время выполнения;
Потоки – ветви кода, выполняющиеся «параллельно», то есть без предписанного порядка во времени.
С точки зрения операционной системы:
Процесс – это абстракция, реализованная на уровне операционной системы. Процесс был придуман для организации всех данных, необходимых для работы программы.
Процесс – это просто контейнер, в котором находятся ресурсы программы:
- адресное пространство;
- потоки;
- открытые файлы;
- дочерние процессы;
- и т.д.;
Поток – это абстракция, реализованная на уровне операционной системы. Поток был придуман для контроля выполнения кода программы.
Поток – это просто контейнер, в котором находятся:
- счётчик команд;
- регистры;
- стек.
Поток легче, чем процесс, и создание потока стоит дешевле. Потоки используют адресное пространство процесса, которому они принадлежат, поэтому потоки внутри одного процесса могут обмениваться данными и взаимодействовать с другими потоками.
Почему нужна поддержка множества потоков внутри одного процесса?
В случае, когда одна программа выполняет множество задач, поддержка множества потоков внутри одного процесса позволяет:
- разделить ответственность за разные задачи между разными потоками;
- повысить быстродействие.
Кроме того, часто задачам необходимо обмениваться данными, использовать общие данные или результаты других задач. Такую возможность предоставляют потоки внутри процесса, так как они используют адресное пространство процесса, которому принадлежат. Конечно можно было бы создать под разные задачи дополнительные процессы, но:
- у процесса будет отдельное адресное пространство и данные, что затруднит взаимодействие частей программы;
- создание и уничтожение процесса дороже, чем создание потока.
Отличие процесса от потока
Процесс рассматривается ОС, как заявка на все виды ресурсов (память, файлы и пр.), кроме одного – процессорного времени. Поток – это заявка на процессорное время. Процесс – это всего лишь способ сгруппировать взаимосвязанные данные и ресурсы, а потоки – это единицы выполнения (unit of execution), которые выполняются на процессоре.
Планирование, состояния потоков, приоритеты
Выбор текущего потока из нескольких активных потоков, пытающихся получить доступ к процессору, называется планированием. Процедура планирования обычно связана с весьма затратной процедурой диспетчеризации – переключением процессора на новый поток, поэтому планировщик должен заботиться об эффективном использовании процессора.
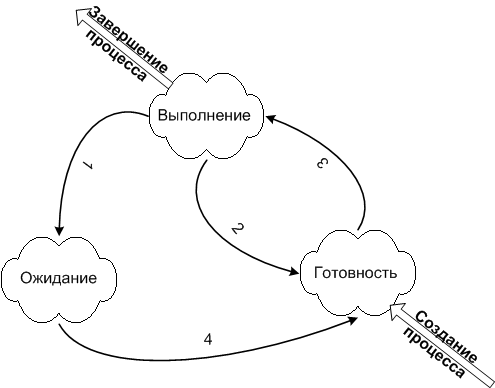
Поток может находиться в одном из трёх состояний:
- выполняемый (executing) – поток, который выполняется в текущий момент на процессоре;
- готовый (runnable) – поток ждет получения кванта времени и готов выполнять назначенные ему инструкции. Планировщик выбирает следующий поток для выполнения только из готовых потоков;
- ожидающий (waiting) – работа потока заблокирована в ожидании блокирующей операции.
В реальных задачах важность работы разных потоков может сильно различаться. Для контроля этого процесса был придуман приоритет работы. У каждого потока есть такое числовое значение приоритета. Если есть несколько спящих потоков, которые нужно запустить, то ОС сначала запустит поток с более высоким приоритетом. ОС управляет потоками так, как посчитает нужным. Потоки с низким приоритетом не будут простаивать, просто они будут получать меньше времени, чем другие, но выполняться всё равно будут. Потоки с одинаковыми приоритетами запускаются в порядке очереди. Приоритет потока может меняться в процессе выполнения. Например, после завершения операции ввода-вывода могут увеличивать приоритет потока, чтобы дать ему возможность быстрее начать выполнение и, может быть, вновь инициировать операцию ввода-вывода. Таким способом система поощряет интерактивные потоки и поддерживает занятость устройств ввода-вывода.
Потоки могут быть созданы не только в режиме ядра, но и в режиме пользователя, в зависимости от того, какой планировщик потоков используется:
- Центральный планировщик ОС режима ядра, который распределяет время между любым потоком в системе.
- Планировщик библиотеки потоков. У библиотеки потоков режима пользователя может быть свой планировщик, который распределяет время между потоками различных процессов режима пользователя.
- Планировщик потоков процесса. К примеру свой Thread Manager есть у каждого процесса Mac OS X, написанного с использованием библиотеки Carbon.
Системные вызовы, режимы доступа
Системный вызов – это вызов функции ядра, из приложения пользователя.
Чтобы защитить жизненно важные системные данные от доступа и (или) внесения изменений со стороны пользовательских приложений, в WIndows и Linux используются два процессорных режима доступа (даже если процессор поддерживает более двух режимов): пользовательский режим и режим ядра.
Код пользовательского приложения запускается в пользовательском режиме, а код операционной системы (например, системные службы и драйверы устройств) запускается в режиме ядра. Режим ядра – такой режим работы процессора, в котором предоставляется доступ ко всей системной памяти и ко всем инструкциям центрального процессора. Предоставляя программному обеспечению операционной системы более высокий уровень привилегий, нежели прикладному программному обеспечению, процессор гарантирует, что приложения с неправильным поведением не смогут в целом нарушить стабильность работы системы.
Также следует отметить, что в случае выполнения системного вызова потоком и перехода из режима пользователя, в режим ядра, происходит смена стека потока на стек ядра. При переключении выполнения потока одного процесса, на поток другого, ОС обновляет некоторые регистры процессора, которые ответственны за механизмы виртуальной памяти (например CR3), так как разные процессы имеют разное виртуальное адресное пространство. Здесь я специально не затрагиваю аспекты относительно режима ядра, так как подобные вещи специфичны для отдельно взятой ОС.
Старайтесь не злоупотреблять средствами синхронизации, которые требуют системных вызовов ядра (например мьютексы). Переключение в режим ядра – дорогостоящая операция!
Задачи и проблемы многопоточности
Какие задачи решает многопоточная система?
К достоинствам многопоточной реализации той или иной системы перед однопоточной можно отнести следующее:
- Упрощение программы в некоторых случаях, за счёт вынесения механизмов чередования выполнения различных слабо взаимосвязанных подзадач, требующих одновременного выполнения, в отдельную подсистему многопоточности.
- Повышение производительности процесса за счёт распараллеливания процессорных вычислений и операций ввода-вывода.
К достоинствам многопоточной реализации той или иной системы перед многопроцессной можно отнести следующее:
- Упрощение программы (взаимодействия её параллельных частей) в некоторых случаях за счёт использования общего адресного пространства.
- Меньшие относительно процесса временные затраты на создание потока.
Распараллеливать работу приложения бывает удобно в самых разных ситуациях. Вот несколько примеров:
- Многопоточность широко используется в приложениях с пользовательским интерфейсом. В этом случае за работу интерфейса отвечает один поток, а какие-либо вычисления выполняются в других потоках. Это позволяет пользовательскому интерфейсу не подвисать, когда приложение занято другими вычислениями.
- Многие алгоритмы легко разбиваются на независимые подзадачи, которые можно выполнять в разных потоках для повышения производительности. Например, при фильтрации изображения разные потоки могут заниматься фильтрацией разных частей изображения.
- Если некоторые части приложения вынуждены ждать ответа от сервера/пользователя/устройства, то эти операции можно выделить в отдельный поток, чтобы в основном потоке можно было продолжать работу, пока другой поток ждёт ответа.
- и т.д.
Кроме того, многопоточную систему можно реализовать с возможностью масштабирования производительности. Например, при распараллеливании алгоритма количество создаваемых потоков может зависеть от количества процессорных ядер. Это позволит ускорять работу программы в определённых пределах, улучшая железо и не изменяя код.
Какие проблемы несёт реализация многопоточных приложений?
Когда потоки должны взаимодействовать друг с другом или работать с общими данными, могут возникать проблемы. Часто проблемы многопоточности иллюстрируются на следующих задачах:
- задача об обедающих философах;
- проблема спящего парикмахера;
- задача о курильщиках;
- задача о читателях-писателях;
- другие задачи.
Рассмотрим некоторые проблемы синхронизации.
Состояние гонки (race condition)
Состояние гонки – ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода.
Состояние гонки – «плавающая» ошибка (гейзенбаг), проявляющаяся в случайные моменты времени и «пропадающая» при попытке её локализовать.
Рассмотрим пример.
Допустим, каждый из двух потоков должен увеличить значение глобальной переменной 1. В идеальной ситуации последовательность операций должна быть следующая:
| Поток 1 | Поток 2 | Целочисленное значение | |
|---|---|---|---|
| 0 | |||
| прочитать значение | ← | 0 | |
| увеличить значение | 0 | ||
| записать обратно | → | 1 | |
| прочитать значение | ← | 1 | |
| увеличить значение | 1 | ||
| записать обратно | → | 2 |
В результате мы получаем значение 2, как и ожидали. Однако, если два потока работают одновременно, и их работа не синхронизируется, результат операции может быть неправильным. Возможна следующая последовательность операций:
| Поток 1 | Поток 2 | Целочисленное значение | |
|---|---|---|---|
| 0 | |||
| прочитать значение | ← | 0 | |
| прочитать значение | ← | 0 | |
| увеличить значение | 0 | ||
| увеличить значение | 0 | ||
| записать обратно | → | 1 | |
| записать обратно | → | 1 |
В этом случае результат будет равен 1, хотя ожидалось значение 2.
Код на C++, приводящий к состоянию гонки:
#include <iostream>
#include <thread>
int main()
{
unsigned long long g_count = 0;
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
++g_count;
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
++g_count;
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}В данном примере решить проблему можно либо использованием атомарных операций вместо нескольких инструкций чтение-изменение-запись, либо ограничивая доступ потоков к переменной так, чтобы в один момент времени только один поток мог изменять переменную.
Использование атомарных операций:
#include <iostream>
#include <thread>
#include <atomic>
int main()
{
std::atomic<unsigned long long> g_count { 0 };
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
g_count.fetch_add(1);
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
g_count.fetch_add(1);
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}Подробнее про atomic:
std::atomicstd::atomic. Модель памяти C++ в примерах
Ограничение доступа к переменной так, чтобы только один поток в один момент времени мог изменять переменную:
int main()
{
unsigned long long g_count = 0;
std::mutex g_count_mutex;
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i) {
g_count_mutex.lock();
g_count += 1;
g_count_mutex.unlock();
}
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i) {
g_count_mutex.lock();
g_count += 1;
g_count_mutex.unlock();
}
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}В этом примере поток перед тем как изменить переменную захватывает mutex (устанавливает флаг о том, что переменная занята), а другой поток, пытаясь захватить тот же mutex в это же время, обнаруживает, что первый поток уже работает с переменной, и дожидается её освобождения.
Подробнее про mutex:
std::mutex
Используя mutex в примере выше, мы синхронизируем работу потоков. Mutex является примитивом синхронизации.
Примитивы синхронизации – механизмы, позволяющие реализовать взаимодействие потоков, например, единовременный доступ только одного потока к критической области.
Примитивы синхронизации преследуют различные задачи:
- Взаимное исключение потоков – примитивы синхронизации гарантируют то, что единовременно с критической областью будет работать только один поток.
- Синхронизация потоков – примитивы синхронизации помогают отслеживать наступление тех или иных конкретных событий, то есть поток не будет работать, пока не наступило какое-то событие. Другой поток в таком случае должен гарантировать наступление данного события.
Однако если взаимоотношения между потоками более сложные, то неаккуратные блокировки потоков могут приводить к новой проблеме – взаимным блокировкам (deadlock).
Взаимная блокировка (deadlock)
Deadlock – ситуация, при которой несколько потоков находятся в состоянии ожидания ресурсов, занятых друг другом, и ни один из них не может продолжать выполнение.
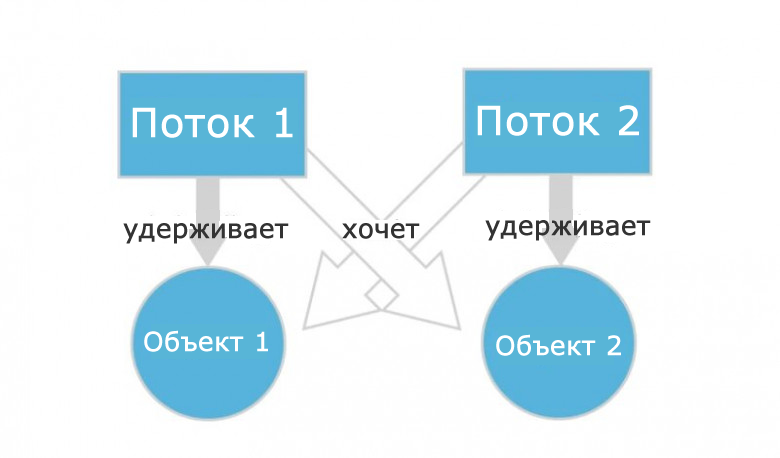
Представим, что поток 1 работает с каким-то объектом 1, а поток 2 работает с объектом 2. При этом программа написана так:
- Поток 1 перестанет работать с объектом 1 и переключится на объект 2, как только поток 2 перестанет работать с объектом 2 и переключится на объект 1.
- Поток 2 перестанет работать с объектом 2 и переключится на объект 1, как только поток 1 перестанет работать с объектом 1 и переключится на объект 2.
Даже не обладая глубокими знаниями в многопоточности, легко понять, что ничего из этого не получится. Потоки никогда не поменяются местами и будут ждать друг друга вечно. Ошибка кажется очевидной, но на самом деле это не так. Допустить ее в программе можно запросто.
Кстати, на Quora есть отличные примеры из реальной жизни, объясняющие что такое deadlock.
Пример возникновения взаимной блокировки в программе на C++:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
auto f2 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m1);
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}Менее наглядный, но более жизненный пример можно посмотреть тут.
Классический способ борьбы с взаимными блокировками состоит в том, чтобы захватывать несколько мьютексов всегда в одинаковом порядке.
Более строго, это значит, что между блокировками устанавливается отношение сравнения и вводится правило о запрете захвата «большей» блокировки в состоянии, когда уже захвачена «меньшая». Таким образом, если процессу нужно несколько блокировок, ему нужно всегда начинать с самой «большой» – предварительно освободив все захваченные «меньшие», если такие есть – и затем в нисходящем порядке. Это может привести к лишним действиям (если «меньшая» блокировка нужна и уже захвачена, она освобождается только чтобы тут же быть захваченной снова), зато гарантированно решает проблему.
С учётом этого пример принимает следующий вид:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
auto f2 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}В нашем простом примере легко было вручную задать верный порядок блокировки мьютексов, однако, это не всегда так легко. Например, в ситуации, когда два мьютекса передаются в функцию по ссылке и блокируются ею, порядок блокировки будет зависеть от порядка переданных аргументов. Поэтому для блокировки мьютексов одинаковом порядке стандартная библиотека предоставляет функцию std::lock (аналог std::mutex::lock()) и класс std::scoped_lock (аналог std::lock_guard).
std::scoped_lock – это улучшенная версия std::lock_guard, конструктор которого блокирует произвольное количество мьютексов в фиксированном порядке (как и std::lock). В новом коде следует использовать std::scoped_lock, std::lock_guard остался в языке для обратной совместимости. Пример:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::scoped_lock lg(m1, m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::scoped_lock lg(m1, m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}Аналогичный код с std::lock и std::lock_guard выглядел бы следующим образом:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock(m1, m2);
std::lock_guard<std::mutex> lk1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lk2(m2, std::adopt_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::lock(m1, m2);
std::lock_guard<std::mutex> lk1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lk2(m2, std::adopt_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}Если требуется больше гибкости, например, при использовании condition variables, можно использовать std::unique_lock:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::unique_lock<std::mutex> lk1(m1, std::defer_lock);
std::unique_lock<std::mutex> lk2(m2, std::defer_lock);
std::lock(lk1, lk2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::unique_lock<std::mutex> lk1(m1, std::defer_lock);
std::unique_lock<std::mutex> lk2(m2, std::defer_lock);
std::lock(lk1, lk2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}Подробнее про unique_lock и lock_guard.
Другие проблемы
Кроме описанных выше проблем, иногда можно столкнуться с проблемой голодания потоков и с проблемой livelock.
Голодание потоков – это ситуация, в которой поток не может получить доступ к общим ресурсам, потому что на эти ресурсы всегда претендуют какие-то другие потоки, которым отдаётся предпочтение.
Поток часто действует в ответ на действие другого потока. Если действие другого потока также является ответом на действие первого потока, то может возникнуть livelock. Потоки не блокируются – они просто слишком заняты, реагируя на действия друг друга, чтобы возобновить работу.
- Подробнее о других проблемах
- What is starvation?
Теги
C++ / CppMutex / МьютексSTL / Standard Template Library / Стандартная библиотека шаблоновВзаимная блокировка (deadlock)Многопоточность
В преддверии старта курса «C++ Developer. Professional« делимся с вами полезной статьей, автором которой является Анатолий Махаев — преподаватель данного курса.

Введение
Разработчики часто сталкиваются с необходимостью разработки многопоточных приложений, поэтому вопросы многопоточности требуют детального изучения. Давайте познакомимся с основными терминами, используемыми в источниках информации о многопоточности, рассмотрим задачи и проблемы многопоточности и изучим средства стандартной библиотеки C++, которые помогут создавать многопоточные приложения.
Основные определения
Многозадачность и многопоточность
Многозадачность (multitasking) — свойство операционной системы или среды выполнения обеспечивать возможность параллельной (или псевдопараллельной) обработки нескольких задач.
Многопоточность (multithreading) — свойство платформы (например, операционной системы, виртуальной машины и т. д.) или приложения, состоящее в том, что процесс, порождённый в операционной системе, может состоять из нескольких потоков, выполняющихся «параллельно», то есть без предписанного порядка во времени. При выполнении некоторых задач такое разделение может достичь более эффективного использования ресурсов вычислительной машины.
По-настоящему параллельное выполнение задач возможно только в многопроцессорной системе, поскольку только в них присутствуют несколько системных конвейеров для исполнения команд.
В однопроцессорной многозадачной системе поддерживается так называемое псевдопараллельное исполнение, при котором создается видимость параллельной работы нескольких процессов. В таких системах, однако, процессы выполняются последовательно, занимая малые кванты процессорного времени.
Процессы и потоки
В различных источниках информации можно найти много разных определений процессов и потоков. Такой разброс определений обусловлен, во-первых, эволюцией операционных систем, которая приводила к изменению понятий о процессах и потоках, во-вторых, различием точек зрения, с которых рассматриваются эти понятия.
В рамках данной статьи предлагаю придерживаться следующих определений…
С точки зрения пользователя:
Процесс — экземпляр программы во время выполнения.
Потоки — ветви кода, выполняющиеся «параллельно», то есть без предписанного порядка во времени.
С точки зрения операционной системы:
Процесс — это абстракция, реализованная на уровне операционной системы. Процесс был придуман для организации всех данных, необходимых для работы программы.
Процесс — это просто контейнер, в котором находятся ресурсы программы:
-
адресное пространство
-
потоки
-
открытые файлы
-
дочерние процессы
-
и т.д.
Поток — это абстракция, реализованная на уровне операционной системы. Поток был придуман для контроля выполнения кода программы.
Поток — это просто контейнер, в котором находятся:
-
Счётчик команд
-
Регистры
-
Стек
Поток легче, чем процесс, и создание потока стоит дешевле. Потоки используют адресное пространство процесса, которому они принадлежат, поэтому потоки внутри одного процесса могут обмениваться данными и взаимодействовать с другими потоками.
Почему нужна поддержка множества потоков внутри одного процесса?
В случае, когда одна программа выполняет множество задач, поддержка множества потоков внутри одного процесса позволяет:
-
Разделить ответственность за разные задачи между разными потоками
-
Повысить быстродействие
Кроме того, часто задачам необходимо обмениваться данными, использовать общие данные или результаты других задач. Такую возможность предоставляют потоки внутри процесса, так как они используют адресное пространство процесса, которому принадлежат. Конечно, можно было бы создать под разные задачи дополнительные процессы, но:
-
у процесса будет отдельное адресное пространство и данные, что затруднит взаимодействие частей программы
-
создание и уничтожение процесса дороже, чем создание потока
Отличие процесса от потока
Процесс рассматривается ОС, как заявка на все виды ресурсов (память, файлы и пр.), кроме одного — процессорного времени. Поток — это заявка на процессорное время. Процесс — это всего лишь способ сгруппировать взаимосвязанные данные и ресурсы, а потоки — это единицы выполнения (unit of execution), которые выполняются на процессоре.
Планирование, состояния потоков, приоритеты
Выбор текущего потока из нескольких активных потоков, пытающихся получить доступ к процессору называется планированием. Процедура планирования обычно связана с весьма затратной процедурой диспетчеризации — переключением процессора на новый поток, поэтому планировщик должен заботиться об эффективном использовании процессора.
Поток может находиться в одном из трёх состояний:
-
Выполняемый (Executing) — поток, который выполняется в текущий момент на процессоре.
-
Готовый (Runnable) — поток ждет получения кванта времени и готов выполнять назначенные ему инструкции. Планировщик выбирает следующий поток для выполнения только из готовых потоков.
-
Ожидающий (Waiting) — работа потока заблокирована в ожидании блокирующей операции.

В реальных задачах важность работы разных потоков может сильно различаться. Для контроля этого процесса был придуман приоритет работы. У каждого потока есть такое числовое значение приоритета. Если есть несколько спящих потоков, которые нужно запустить, то ОС сначала запустит поток с более высоким приоритетом. ОС управляет потоками так, как посчитает нужным. Потоки с низким приоритетом не будут простаивать, просто они будут получать меньше времени, чем другие, но выполняться все равно будут. Потоки с одинаковыми приоритетами запускаются в порядке очереди. Приоритет потока может меняться в процессе выполнения. Например, после завершения операции ввода-вывода могут увеличивать приоритет потока, чтобы дать ему возможность быстрее начать выполнение и, может быть, вновь инициировать операцию ввода-вывода. Таким способом система поощряет интерактивные потоки и поддерживает занятость устройств ввода-вывода.
Потоки могут быть созданы не только в режиме ядра, но и в режиме пользователя, в зависимости от того, какой планировщик потоков используется:
-
Центральный планировщик ОС режима ядра, который распределяет время между любым потоком в системе.
-
Планировщик библиотеки потоков. У библиотеки потоков режима пользователя может быть свой планировщик, который распределяет время между потоками различных процессов режима пользователя.
-
Планировщик потоков процесса. К примеру свой Thread Manager есть у каждого процесса Mac OS X, написанного с использованием библиотеки Carbon.
Системные вызовы, режимы доступа
Системный вызов — это вызов функции ядра, из приложения пользователя.
Чтобы защитить жизненно важные системные данные от доступа и (или) внесения изменений со стороны пользовательских приложений, в WIndows и Linux используются два процессорных режима доступа (даже если процессор поддерживает более двух режимов): пользовательский режим и режим ядра.
Код пользовательского приложения запускается в пользовательском режиме, а код операционной системы (например, системные службы и драйверы устройств) запускается в режиме ядра. Режим ядра — такой режим работы процессора, в котором предоставляется доступ ко всей системной памяти и ко всем инструкциям центрального процессора. Предоставляя программному обеспечению операционной системы более высокий уровень привилегий, нежели прикладному программному обеспечению, процессор гарантирует, что приложения с неправильным поведением не смогут в целом нарушить стабильность работы системы.
Также следует отметить, что в случае выполнения системного вызова потоком и перехода из режима пользователя, в режим ядра, происходит смена стека потока на стек ядра. При переключении выполнения потока одного процесса, на поток другого, ОС обновляет некоторые регистры процессора, которые ответственны за механизмы виртуальной памяти (например CR3), так как разные процессы имеют разное виртуальное адресное пространство. Здесь я специально не затрагиваю аспекты относительно режима ядра, так как подобные вещи специфичны для отдельно взятой ОС.
Старайтесь не злоупотреблять средствами синхронизации, которые требуют системных вызовов ядра (например мьютексы). Переключение в режим ядра — дорогостоящая операция!
Задачи и проблемы многопоточности
Какие задачи решает многопоточная система?
К достоинствам многопоточной реализации той или иной системы перед однопоточной можно отнести следующее:
-
Упрощение программы в некоторых случаях, за счёт вынесения механизмов чередования выполнения различных слабо взаимосвязанных подзадач, требующих одновременного выполнения, в отдельную подсистему многопоточности.
-
Повышение производительности процесса за счёт распараллеливания процессорных вычислений и операций ввода-вывода.
К достоинствам многопоточной реализации той или иной системы перед многопроцессной можно отнести следующее:
-
Упрощение программы (взаимодействия её параллельных частей) в некоторых случаях за счёт использования общего адресного пространства.
-
Меньшие относительно процесса временные затраты на создание потока.
Распараллеливать работу приложения бывает удобно в самых разных ситуациях. Вот несколько примеров:
-
Многопоточность широко используется в приложениях с пользовательским интерфейсом. В этом случае за работу интерфейса отвечает один поток, а какие-либо вычисления выполняются в других потоках. Это позволяет пользовательскому интерфейсу не подвисать, когда приложение занято другими вычислениями.
-
Многие алгоритмы легко разбиваются на независимые подзадачи, которые можно выполнять в разных потоках для повышения производительности. Например, при фильтрации изображения разные потоки могут заниматься фильтрацией разных частей изображения.
-
Если некоторые части приложения вынуждены ждать ответа от сервера/пользователя/устройства, то эти операции можно выделить в отдельный поток, чтобы в основном потоке можно было продолжать работу, пока другой поток ждёт ответа.
-
и т.д.
Кроме того, многопоточную систему можно реализовать с возможностью масштабирования производительности. Например, при распараллеливании алгоритма количество создаваемых потоков может зависеть от количества процессорных ядер. Это позволит ускорять работу программы в определённых пределах, улучшая железо и не изменяя код.
Какие проблемы несёт реализация многопоточных приложений?
Когда потоки должны взаимодействовать друг с другом или работать с общими данными, могут возникать проблемы. Часто проблемы многопоточности иллюстрируются на следующих задачах:
-
Задача об обедающих философах
-
Проблема спящего парикмахера
-
Задача о курильщиках
-
Задача о читателях-писателях
-
Другие задачи
Рассмотрим некоторые проблемы синхронизации.
Состояние гонки (race condition)
Состояние гонки — ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода.
Состояние гонки — «плавающая» ошибка (гейзенбаг), проявляющаяся в случайные моменты времени и «пропадающая» при попытке её локализовать.
Рассмотрим пример.
Допустим, каждый из двух потоков должен увеличить значение глобальной переменной 1. В идеальной ситуации последовательность операций должна быть следующая:
|
Thread 1 |
Thread 2 |
Integer value |
|
|---|---|---|---|
|
0 |
|||
|
read value |
← |
0 |
|
|
increase value |
0 |
||
|
write back |
→ |
1 |
|
|
read value |
← |
1 |
|
|
increase value |
1 |
||
|
write back |
→ |
2 |
В результате мы получаем значение 2, как и ожидали. Однако, если два потока работают одновременно, и их работа не синхронизируется, результат операции может быть неправильным. Возможна следующая последовательность операций:
|
Thread 1 |
Thread 2 |
Integer value |
|
|---|---|---|---|
|
0 |
|||
|
read value |
← |
0 |
|
|
read value |
← |
0 |
|
|
increase value |
0 |
||
|
increase value |
0 |
||
|
write back |
→ |
1 |
|
|
write back |
→ |
1 |
В этом случае результат будет равен 1, хотя ожидалось значение 2.
Код на C++, приводящий к состоянию гонки:
#include <iostream>
#include <thread>
int main()
{
unsigned long long g_count = 0;
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
++g_count;
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
++g_count;
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}
В данном примере решить проблему можно либо использованием атомарных операций вместо нескольких инструкций чтение-изменение-запись, либо ограничивая доступ потоков к переменной так, чтобы в один момент времени только один поток мог изменять переменную.
Использование атомарных операций:
#include <iostream>
#include <thread>
#include <atomic>
int main()
{
std::atomic<unsigned long long> g_count { 0 };
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
g_count.fetch_add(1);
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i)
g_count.fetch_add(1);
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}
Подробнее про atomic:
std::atomic
std::atomic. Модель памяти C++ в примерах
Ограничение доступа к переменной так, чтобы только один поток в один момент времени мог изменять переменную:
int main()
{
unsigned long long g_count = 0;
std::mutex g_count_mutex;
std::thread t1([&]()
{
for(auto i = 0; i < 1'000'000; ++i) {
g_count_mutex.lock();
g_count += 1;
g_count_mutex.unlock();
}
});
std::thread t2([&]()
{
for(auto i = 0; i < 1'000'000; ++i) {
g_count_mutex.lock();
g_count += 1;
g_count_mutex.unlock();
}
});
t1.join();
t2.join();
std::cout << g_count;
return 0;
}
В этом примере поток перед тем как изменить переменную захватывает mutex (устанавливает флаг о том, что переменная занята), а другой поток, пытаясь захватить тот же mutex в это же время, обнаруживает, что первый поток уже работает с переменной, и дожидается её освобождения.
Подробнее про mutex:
std::mutex
Используя mutex в примере выше, мы синхронизируем работу потоков. Mutex является примитивом синхронизации.
Примитивы синхронизации — механизмы, позволяющие реализовать взаимодействие потоков, например, единовременный доступ только одного потока к критической области.
Примитивы синхронизации преследуют различные задачи:
-
Взаимное исключение потоков — примитивы синхронизации гарантируют то, что единовременно с критической областью будет работать только один поток.
-
Синхронизация потоков — примитивы синхронизации помогают отслеживать наступление тех или иных конкретных событий, то есть поток не будет работать, пока не наступило какое-то событие. Другой поток в таком случае должен гарантировать наступление данного события.
Однако если взаимоотношения между потоками более сложные, то неаккуратные блокировки потоков могут приводить к новой проблеме — взаимным блокировкам (deadlock).
Взаимная блокировка (deadlock)
Deadlock — ситуация, при которой несколько потоков находятся в состоянии ожидания ресурсов, занятых друг другом, и ни один из них не может продолжать выполнение.
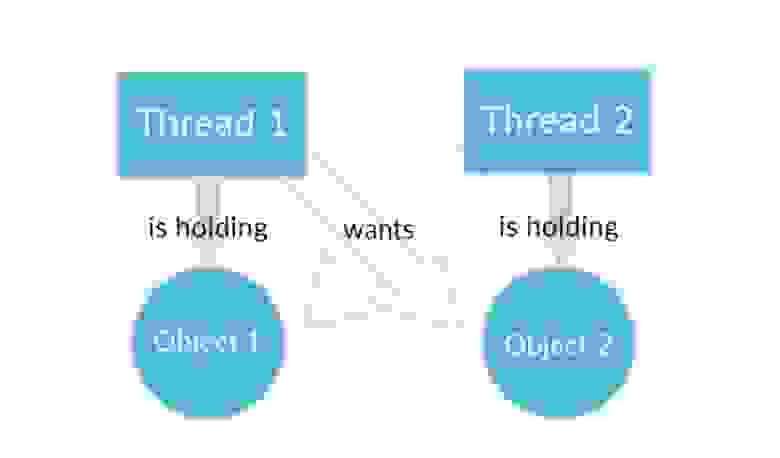
Представим, что поток-1 работает с каким-то Объектом-1, а поток-2 работает с Объектом-2. При этом программа написана так:
-
Поток-1 перестанет работать с Объектом-1 и переключится на Объект-2, как только Поток-2 перестанет работать с Объектом 2 и переключится на Объект-1.
-
Поток-2 перестанет работать с Объектом-2 и переключится на Объект-1, как только Поток-1 перестанет работать с Объектом 1 и переключится на Объект-2.
Даже не обладая глубокими знаниями в многопоточности легко понять, что ничего из этого не получится. Потоки никогда не поменяются местами и будут ждать друг друга вечно. Ошибка кажется очевидной, но на самом деле это не так. Допустить ее в программе можно запросто.
Кстати, на Quora есть отличные примеры из реальной жизни, объясняющие что такое deadlock.
Пример возникновения взаимной блокировки в программе на C++:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
auto f2 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m1);
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Менее наглядный, но более жизненный пример можно посмотреть тут.
Классический способ борьбы с взаимными блокировками состоит в том, чтобы захватывать несколько мьютексов всегда в одинаковом порядке.
Более строго, это значит, что между блокировками устанавливается отношение сравнения и вводится правило о запрете захвата «большей» блокировки в состоянии, когда уже захвачена «меньшая». Таким образом, если процессу нужно несколько блокировок, ему нужно всегда начинать с самой «большой» — предварительно освободив все захваченные «меньшие», если такие есть — и затем в нисходящем порядке. Это может привести к лишним действиям (если «меньшая» блокировка нужна и уже захвачена, она освобождается только чтобы тут же быть захваченной снова), зато гарантированно решает проблему.
С учётом этого пример принимает следующий вид:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
auto f2 = [&m1, &m2]() {
std::lock_guard<std::mutex> lg1(m1);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::lock_guard<std::mutex> lg2(m2);
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
В нашем простом примере легко было вручную задать верный порядок блокировки мьютексов, однако, это не всегда так легко. Например, в ситуации, когда два мьютекса передаются в функцию по ссылке и блокируются ею, порядок блокировки будет зависеть от порядка переданных аргументов. Поэтому для блокировки мьютексов одинаковом порядке стандартная библиотека предоставляет функцию std::lock (аналог std::mutex::lock()) и класс std::scoped_lock (аналог std::lock_guard).
std::scoped_lock — это улучшенная версия std::lock_guard, конструктор которого блокирует произвольное количество мьютексов в фиксированном порядке (как и std::lock). В новом коде следует использовать std::scoped_lock, std::lock_guard остался в языке для обратной совместимости. Пример:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::scoped_lock lg(m1, m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::scoped_lock lg(m1, m2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Аналогичный код с std::lock и std::lock_guard выглядел бы следующим образом:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::lock(m1, m2);
std::lock_guard<std::mutex> lk1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lk2(m2, std::adopt_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::lock(m1, m2);
std::lock_guard<std::mutex> lk1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lk2(m2, std::adopt_lock);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Если требуется больше гибкости, например, при использовании condition variables, можно использовать std::unique_lock:
#include <iostream>
#include <mutex>
#include <thread>
#include <mutex>
int main()
{
std::mutex m1;
std::mutex m2;
auto f1 = [&m1, &m2]() {
std::unique_lock<std::mutex> lk1(m1, std::defer_lock);
std::unique_lock<std::mutex> lk2(m2, std::defer_lock);
std::lock(lk1, lk2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
auto f2 = [&m1, &m2]() {
std::unique_lock<std::mutex> lk1(m1, std::defer_lock);
std::unique_lock<std::mutex> lk2(m2, std::defer_lock);
std::lock(lk1, lk2);
std::this_thread::sleep_for(std::chrono::milliseconds(10));
};
std::thread thread1([&f1, &f2]() {
f1();
});
std::thread thread2([&f1, &f2]() {
f2();
});
thread1.join();
thread2.join();
return 0;
}
Подробнее про unique_lock и lock_guard
Другие проблемы
Кроме описанных выше проблем, иногда можно столкнуться с проблемой голодания потоков и с проблемой livelock.
Голодание потоков — это ситуация, в которой поток не может получить доступ к общим ресурсам, потому что на эти ресурсы всегда претендуют какие-то другие потоки, которым отдаётся предпочтение.
Поток часто действует в ответ на действие другого потока. Если действие другого потока также является ответом на действие первого потока, то может возникнуть livelock. Потоки не блокируются — они просто слишком заняты, реагируя на действия друг друга, чтобы возобновить работу.
Подробнее о других проблемах
What is starvation?
Средства стандартной библиотеки C++
Управление потоками
У каждой программы на C++ есть как минимум один поток, запускаемый средой выполнения C++, — поток, выполняющий функцию main(). Затем программа может запустить дополнительные потоки, точкой входа в которые служит другая функция. После чего эти потоки и начальный поток выполняются одновременно. Аналогично завершению программы при выходе из main() поток завершается при возвращении из функции, указанной в качестве точки входа.
std::thread
Основной класс для создания новых потоков в C++ — это std::thread.
Кратко:
-
Объект класса представляет собой один поток выполнения.
-
Новый поток начинает выполнение сразу же после построения объекта
std::thread. Выполнение начинается с функции верхнего уровня, которая передаётся в качестве аргумента в конструкторstd::thread. -
Возвращаемое значение этой функции игнорируется, а если в ней будет брошено исключение, которое не будет обработано в этом же потоке, то вызовется
std::terminate. -
Передать возвращаемое значение или исключение из нового потока наружу можно через std::promise или через глобальные переменные (работа с которыми потребует синхронизации, см.
std::mutexиstd::atomic). -
Объекты std::thread также могут быть не связаны ни с каким потоком (после default construction, move from, detach или join), и поток выполнения может быть не связан ни с каким объектом std::thread (после detach).
-
Никакие два объекта std::thread не могут представлять один и тот же поток выполнения; std::thread нельзя копировать (не является CopyConstructible или CopyAssignable), но можно перемещать (является MoveConstructible и MoveAssignable).
Потоки запускаются созданием объекта std::thread, в котором определяется выполняемая в потоке задача. В простейшем случае эта задача представляет собой обычную функцию. Эта функция выполняется в собственном потоке, пока не вернет управление, после чего поток останавливается. Что бы ни собирался делать поток и откуда бы он ни запускался, его запуск с использованием стандартной библиотеки C++ всегда сводится к созданию объекта std::thread:
void do_some_work();
std::thread my_thread(do_some_work);std::thread работает с любым вызываемым типом, поэтому конструктору std::thread можно также передать экземпляр класса с оператором вызова функции:
class background_task{
public:
void operator()() const {
do_something();
do_something_else();
}
};
background_task f;
std::thread my_thread(f);
В данном случае предоставленный функциональный объект копируется в хранилище, принадлежащее вновь созданному потоку выполнения, и вызывается оттуда. Поэтому важно, чтобы копия действовала аналогично оригиналу, иначе результат может не соответствовать ожидаемому.
С помощью лямбда-выражения предыдущий пример можно записать следующим образом:
std::thread my_thread([]{
do_something();
do_something_else();
});После запуска потока, нужно принять однозначное решение, ждать ли его завершения (join) или пустить его на самотек (detach). Если не принять решение до уничтожения объекта std::thread, то программа завершится (деструктор std::thread вызовет std::terminate()). Решение нужно принимать до того, как объект std::thread будет уничтожен. Сам же поток вполне мог бы завершиться задолго до его присоединения или отсоединения. Если его отсоединить, то при условии, что он все еще выполняется, он и будет выполняться, и этот процесс может продолжаться еще долго и после уничтожения объекта std::thread. Выполнение будет прекращено, только когда в конце концов произойдет возвращение из функции потока. Если не дожидаться завершения потока, необходимо убедиться, что данные, к которым он обращается, будут действительны, пока он не закончит работать с ними.
Дождаться завершения потока можно, вызвав join() для связанного экземпляра std::thread. Вызов join() приводит к очистке объекта std::thread, поэтому объект std::thread больше не связан с завершенным потоком. Мало того, он не связан ни с одним потоком. Это означает, что join() можно вызвать для конкретного потока только один раз: как только вызван метод join(), объект std::thread утрачивает возможность присоединения, а метод joinable() вернет значение false.
Вызов метода detach() для объекта std::thread позволяет потоку выполняться в фоновом режиме, непосредственное взаимодействие с ним не требуется. Возможность дождаться завершения этого потока исчезает: если поток отсоединяется, получить ссылающийся на него объект std::thread невозможно, поэтому такой поток больше нельзя присоединить. Отсоединенные потоки фактически выполняются в фоновом режиме, владение и управление ими передаются в библиотеку среды выполнения C++, которая гарантирует правильное высвобождение ресурсов, связанных с потоком, при выходе из него. Как правило, такие потоки являются весьма продолжительными, работая в течение практически всего времени жизни приложения и выполняя фоновую задачу, например отслеживая состояние файловой системы, удаляя неиспользуемые записи из кэш-памяти объектов или оптимизируя структуры данных. Метод detach() нельзя вызывать для объекта std::thread, не имеющего связанного с ним потока выполнения. Это требование аналогично тому, которое предъявляется к вызову метода join(), и проверку можно провести точно таким же образом — вызывать для объекта t типа std::thread метод t.detach() возможно, только если метод t.joinable() вернет значение true.
Передача аргументов вызываемому объекту или функции сводится к простой передаче дополнительных аргументов конструктору std::thread. Но важно учесть, что по умолчанию аргументы копируются во внутреннее хранилище, где к ним может получить доступ вновь созданный поток выполнения, а затем передаются вызываемому объекту или функции как r-значения (rvalues), как будто они временные. Так делается, даже если соответствующий параметр в функции ожидает ссылку. Рассмотрим пример:
void f(int i,std::string const& s);
std::thread t(f,3,"hello");В результате создается новый поток выполнения, связанный с t, который вызывает функцию f(3,"hello"). Обратите внимание: даже если f в качестве второго параметра принимает std::string, строковый литерал передается как char const* и преобразуется в std::string только в контексте нового потока. Это становится особенно важным, когда, как показано далее, предоставленный аргумент является указателем на локальную переменную:
void f(int i,std::string const& s);
void oops(int some_param) {
char buffer[1024];
sprintf(buffer, "%i",some_param);
std::thread t(f,3,buffer);
t.detach();
}Здесь это указатель на буфер локальной переменной, который передается в новый поток. И высока вероятность того, что выход из функции oops произойдет, прежде чем буфер будет в новом потоке преобразован в std::string, что вызовет неопределенное поведение. Решением является приведение к типу std::string перед передачей буфера в конструктор std::thread:
void f(int i,std::string const& s);
void oops(int some_param) {
char buffer[1024];
sprintf(buffer, "%i", some_param);
std::thread t(f, 3, std::string(buffer));
t.detach();
}void update_data_for_widget(widget_id w, widget_data& data);
void oops_again(widget_id w){
widget_data data;
std::thread t(update_data_for_widget,w,data);
display_status();
t.join();
process_widget_data(data);
}Хотя update_data_for_widget ожидает, что второй параметр будет передан по ссылке, конструктор std::thread не знает об этом, он не обращает внимания на типы аргументов, которые ожидает функция, и слепо копирует предоставленные значения. Но внутренний код передает скопированные аргументы в качестве r-значений, чтобы работать с типами, предназначенными только для перемещений, и пытается таким образом вызвать update_data_for_widget с r-значением. Этот код не скомпилируется, так как нельзя передать r-значение функции, ожидающей не-const-ссылку. Для тех, кто знаком с std::bind, решение будет очевидным: аргументы, которые должны быть ссылками, следует заключать в std::ref. В этом случае при изменении вызова потока на:
std::thread t(update_data_for_widget,w,std::ref(data));update_data_for_widget будет корректно передана ссылка на данные, а не временная копия данных, и код успешно скомпилируется. Если работать с std::bind уже приходилось, то в семантике передачи параметров не будет ничего нового, поскольку и операция конструктора std::thread, и операция std::bind определены в рамках одного и того же механизма.
Чтобы вызвать в отдельном потоке метод какого-ибо объекта, нужно передать указатель на объект в качестве первого аргумента этого метода:
class X {
public:
void do_lengthy_work();
};
X my_x;
std::thread t(&X::do_lengthy_work, &my_x);Этот код вызовет my_x.do_lengthy_work() в новом потоке, поскольку в качестве указателя на объект предоставляется адрес my_x.
Еще один интересный сценарий предоставления аргументов применяется, когда аргументы нельзя скопировать, а можно только переместить. Примером может послужить тип std::unique_ptr, обеспечивающий автоматическое управление памятью для динамически выделяемых объектов. В одно и то же время на данный объект может указывать только один экземпляр std::unique_ptr, и когда этот экземпляр уничтожается, объект, на который он указывал, удаляется. Перемещающий конструктор и перемещающий оператор присваивания позволяют передавать права владения объектом между экземплярами std::unique_ptr. В результате этого исходный объект остается с нулевым указателем. Такое перемещение значений позволяет принимать объекты данного типа в качестве параметров функции или возвращать их из функций. Если исходный объект временный, перемещение выполняется автоматически, но если источником является именованное значение, передача должна быть запрошена напрямую путем вызова метода std::move(). В следующем примере показано использование std::move для передачи потоку права владения динамическим объектом:
void process_big_object(std::unique_ptr<big_object>);
std::unique_ptr<big_object> p(new big_object);
p->prepare_data(42);
std::thread t(process_big_object,std::move(p));Поскольку при вызове конструктора std::thread указан метод std::move(p), право владения big_object сначала передается внутреннему хранилищу вновь созданного потока, а затем переходит к process_big_object.
Мы разобрали основы использования класса std::thread для создания потоков. У объектов std::thread есть ещё пара полезных методов:
-
std::thread::get_id()возвращает id потока. Можно использовать для логирования или в качестве ключа ассоциативного контейнера потоков. -
std::thread::native_handle()возвращает специфичный для операционной системы handle потока, который можно передавать в методы WinAPI или pthreads для более гибкого управления потоками.
Выбор количества потоков в ходе выполнения программы
Одна из функций стандартной библиотеки C++, помогающая решить данную задачу, — std::thread::hardware_concurrency(). Она возвращает то количество потоков, которые действительно могут работать одновременно в ходе выполнения программы. Например, в многоядерной системе оно может быть увязано с числом ядер центрального процессора. Функция дает всего лишь подсказку и может вернуть 0, если информация недоступна, но ее данные способны принести пользу при разбиении задачи на потоки.
std::jthread
В С++20 появился новый класс для создания потоков и управления ими std::jthread.
Класс jthread представляет собой один поток выполнения. Он имеет то же поведение, что и std::thread, за исключением того, что jthread автоматически join’ится при уничтожении и предлагает интерфейс для остановки потока.
В отличие от std::thread, jthread содержит внутренний закрытый член типа std::stop_source, который хранит stop-state. Конструктор jthread принимает функцию, которая принимает std::stop_token в качестве своего первого аргумента. Этот аргумент передаётся в функцию из stop_source, и позволяет функции проверить, была ли запрошена остановка во время ее выполнения, и завершиться при необходимости.
Подробнее о jthread
Так же существует возможность связать callback функции с событием остановки потока
Управление текущим потоком
Стандартная библиотека предоставляет несколько методов для управления текущим потоком. Все они находятся в пространстве имён std::this_thread:
-
std::this_thread::yield()подсказывает планировщику потоков перепланировать выполнение, приостановив текущий поток и отдав преимущество другим потокам. Точное поведение этой функции зависит от реализации, в частности от механики используемого планировщика ОС и состояния системы. Например, планировщик реального времениfirst-in-first-out(SCHED_FIFO в Linux) приостанавливает текущий поток и помещает его в конец очереди потоков с одинаковым приоритетом, готовых к запуску (если нет других потоков с таким же приоритетом,yieldне делает ничего). -
std::this_thread::get_id()работает аналогичноstd::thread::get_id(). -
std::this_thread::sleep_for(sleep_duration) блокирует выполнение текущего потока на времяsleep_duration. -
std::this_thread::sleep_until(sleep_time)блокирует выполнение текущего потока до наступления момента времениsleep_time.
Взаимное исключение потоков (Mutual exclusion)
Одним из ключевых преимуществ (перед использованием нескольких процессов) применения потоков для конкурентности является возможность совместного использования (разделения) данных несколькими потоками.
Представьте на минуту, что вы живете в одной квартире с приятелем. У вас одна кухня и одна ванная на двоих. Обычно ванной не пользуются одновременно несколько человек, и то, что сосед слишком долго плещется в воде, вынуждая вас дожидаться своей очереди, не может не раздражать. Возможно, одному из вас захочется запечь в духовке колбаски, в то время как у другого там готовятся кексы, и из этого тоже не выйдет ничего хорошего. Ну и всем знакомо чувство досады, когда при совместно используемом оборудовании вы на полпути к решению какой-нибудь задачи вдруг обнаруживаете, что кто-то взял что-то нужное вам в данный момент или что-то изменил, а вы рассчитывали, что все останется в прежнем состоянии или на своих местах.
То же самое происходит и с потоками. Если они совместно используют данные, для них нужны правила, определяющие, какой поток и к каким данным может получить доступ, когда и как любые обновления данных будут передаваться другим потокам, интересующимся этими данными. Некорректная работа с общими данными — одна из основных причин ошибок, связанных с конкурентностью.
Когда дело доходит до совместной работы с данными нескольких потоков, то все проблемы возникают из-за последствий изменения этих данных. Если все совместно используемые данные доступны только для чтения, проблем не будет, поскольку данные, считываемые одним потоком, не зависят от того, читает другой поток те же данные или нет. Но если один или несколько потоков, совместно использующих данные, начинают вносить вних изменения, создаются серьезные предпосылки для возникновения проблем. В таком случае следует обеспечить приемлемость конечных результатов.
Предположим, вы покупаете билет в кино. Если кинотеатр большой, билеты будут продавать сразу несколько кассиров, обслуживая одновременно несколько человек. Если кто-то в это же время покупает билет на тот же сеанс в другой кассе, то выбор места зависит от того, кто первым его закажет, вы или другой. Если осталось всего несколько мест, очередность может стать решающей: возможна настоящая гонка за последними билетами. Это пример состояния гонки: какое место вы получите и получите ли вообще, зависит от порядка двух покупок.
При конкурентности состоянием гонки является все, что зависит от порядка выполнения операций в двух и более потоках относительно друг друга: потоки участвуют в гонке по выполнению соответствующих операций. В стандарте C++ также определяется понятие гонки за данными, обозначающее конкретный тип состояния гонки, возникающий из-за одновременного изменения одного и того же объекта. Гонки за данными вызывают опасное неопределенное поведение.
Ошибки в состоянии гонки возникают, когда для завершения операции требуется выполнение нескольких инструкций процессора. Состояние гонки зачастую трудно определить и сложно воспроизвести. Обычно, вероятность, что между последовательно выполняемыми инструкциями вклинится другой поток, невелика. По мере увеличения нагрузки на систему и количества выполнения операции возрастает и вероятность возникновения проблемной последовательности выполнения. Проблемы практически неизменно появляются в самое неподходящее время. При запуске приложения под отладчиком проблема вообще может исчезать, поскольку отладчик влияет на выполнение программы.
Есть несколько способов, позволяющих справиться с проблемными состояниями гонок. Самый простой вариант — заключить структуру данных в механизм защиты, чтобы гарантировать, что промежуточные состояния, в которых нарушены инварианты, будут видны только потоку, выполняющему изменения. С позиции других потоков, обращающихся к этой же структуре данных, такие изменения либо еще не начнутся, либо уже завершатся. Стандартная библиотека C++ предоставляет несколько таких механизмов.
Есть еще один вариант — изменить конструкцию структуры данных и ее инвариантов так, чтобы модификации вносились в виде серии неделимых изменений, каждая из которых сохраняет инварианты. Обычно это называется программированием без блокировок (lock-free programming), и реализовать ее нелегко.
Простая защита данных с помощью мьютекса
std::mutex
Основным механизмом защиты совместно используемых данных, обеспеченным стандартом C++, является мьютекс.
Итак, имеется совместно используемая структура данных, например связный список, и его нужно защитить от состояния гонки и возможных нарушений инвариантов. Наверное, неплохо было бы получить возможность помечать все фрагменты кода, обращающиеся к структуре данных, как взаимоисключающие, чтобы при выполнении одного из них каким-либо потоком любой другой поток, пытающийся получить доступ к этой структуре данных, был бы вынужден ждать, пока первый поток не завершит выполнение такого фрагмента. Тогда поток не смог бы увидеть нарушенный инвариант, кроме тех случаев, когда он сам выполнял бы модификацию. Именно это будет получено при использовании примитива синхронизации под названием «мьютекс», означающего взаимное исключение (mutual exclusion). Перед получением доступа к совместно используемой структуре данных мьютекс, связанный с ней, блокируется, а когда доступ к ней заканчивается, блокировка с него снимается. Библиотека потоков гарантирует, что, как только один поток заблокирует определенный мьютекс, все остальные потоки, пытающиеся его заблокировать, должны будут ждать, пока поток, который успешно заблокировал мьютекс, его не разблокирует. Тем самым гарантируется, что все потоки видят непротиворечивое представление совместно используемых данных без нарушенных инвариантов. Мьютексы — главный механизм защиты данных, доступный в C++, но панацеей от всех бед их не назовешь: важно структурировать код таким образом, чтобы защитить нужные данные и избежать состояний гонки, присущих используемым интерфейсам. У мьютексов имеются и собственные проблемы в виде взаимной блокировки и защиты либо слишком большого, либо слишком малого объема данных.
Класс std::mutex — это примитив синхронизации, который может использоваться для защиты общих данных от одновременного доступа нескольких потоков.
std::mutex предлагает эксклюзивную, нерекурсивную семантику владения:
-
Вызывающий поток владеет мьютексом с момента успешного вызова методов
lockилиtry_lockдо вызоваunlock. -
Когда поток владеет мьютексом, все остальные потоки блокируются (при вызове
lock) или получают false (при вызовеtry_lock), если они пытаются претендовать на владение мьютексом. -
Вызывающий поток не должен владеть мьютексом до вызова
lockилиtry_lock.
Поведение программы не определено, если мьютекс уничтожается, все еще будучи заблокированным, или если поток завершается, не разблокировав мьютекс.
std::mutex не является ни копируемым, ни перемещаемым.
Если метод lock вызывается потоком, который уже владеет мьютексом, поведение не определено: например, программа может попасть в deadlock.
Метод try_lock может ошибаться и возвращать false, даже если мьютекс в данный момент не заблокирован никаким другим потоком.
Если try_lock вызывается потоком, который уже владеет мьютексом, поведение не определено.
Мьютекс должен быть разблокирован тем потоком выполнения, который его заблокировал, в противном случае поведение не определено.
std::mutex обычно не захватывается напрямую, поскольку при этом нужно помнить о необходимости вызова unlock() на всех путях выхода из функции, в том числе возникающих из-за выдачи исключений. Стандартной библиотекой C++ предоставляются классы std::unique_lock, std::lock_guard или std::scoped_lock (начиная с C++17) для более безопасного управления захватом мьютексов.
Мьютекс является объектом операционной системы, поэтому для работы с ним через API ОС, можно получить handle с помощью метода native_handle.
Пример использования мьютекса:
#include <iostream>
#include <map>
#include <string>
#include <chrono>
#include <thread>
#include <mutex>
std::map<std::string, std::string> g_pages;
std::mutex g_pages_mutex;
void save_page(const std::string &url)
{
// simulate a long page fetch
std::this_thread::sleep_for(std::chrono::seconds(2));
std::string result = "fake content";
std::lock_guard<std::mutex> guard(g_pages_mutex);
g_pages[url] = result;
}
int main()
{
std::thread t1(save_page, "http://foo");
std::thread t2(save_page, "http://bar");
t1.join();
t2.join();
// safe to access g_pages without lock now, as the threads are joined
for (const auto &pair : g_pages) {
std::cout << pair.first << " => " << pair.second << 'n';
}
}
В примере выше используются глобальные переменные для структуры данных и мьютекса. Иногда в таком использовании глобальных переменных есть определенный смысл, однако в большинстве случаев мьютекс и защищенные данные помещаются в один класс, а не в глобальные переменные. Это соответствует стандартным правилам объектно-ориентированного проектирования: помещение их в один класс служит признаком связанности друг с другом, позволяя инкапсулировать функциональность и обеспечить защиту. В данном случае save_page станет методом класса, а мьютекс и защищаемые данные— закрытыми членами класса, что значительно упростит определение того, какой код имеет доступ к данным и, следовательно, какой код должен заблокировать мьютекс. Если все методы класса блокируют мьютекс перед доступом к защищаемым данным и разблокируют его по завершении доступа, данные будут надежно защищены от любого обращающегося к ним кода. Однако, это не всегда так: если один из методов класса возвращает указатель или ссылку на защищаемые данные, то в защите будет проделана большая дыра. Теперь обратиться к защищенным данным и, возможно, их изменить, не блокируя мьютекс, сможет любой код, имеющий доступ к этому указателю или ссылке. Поэтому защита данных с помощью мьютекса требует тщательной проработки интерфейса. Помимо проверки того, что методы не возвращают указатели или ссылки вызывающему их коду, важно также убедиться, что они не передают эти указатели или ссылки тем функциям, которые вызываются ими и не контролируются вами. Такая передача не менее опасна: эти функции могут хранить указатель или ссылку в том месте, где их позже можно использовать без защиты, предоставляемой мьютексом. В этом смысле особенно опасны функции, которые предоставляются во время выполнения программы в виде аргументов или другим способом. К сожалению, помочь справиться с проблемой такого рода библиотека потоков C++ не в состоянии, задача блокировки нужного мьютекса для защиты данных возлагается на программиста. В то же время можно воспользоваться рекомендацией, которая поможет в подобных случаях: не передавайте указатели и ссылки на защищенные данные за пределы блокировки никаким способом: ни возвращая их из функции, ни сохраняя во внешне видимой памяти, ни передавая в качестве аргументов функциям, предоставленным пользователем.
Применение мьютекса или другого механизма для защиты совместно используемых данных не дает полной гарантии защищенности от состояния гонки. Рассмотрим структуру данных стека. Пусть над нашим стеком можно проводить следующие операции: можно поместить в стек новый элемент методом push(), извлечь элемент из стека методом pop(), прочитать верхний элемент с помощью top(), проверить, не является ли стек пустым, с помощью empty(), и прочитать количество элементов стека методом size().
#include <deque>
#include <cstddef>
template<typename T,typename Container=std::deque<T> >
class stack
{
public:
explicit stack(const Container&);
explicit stack(Container&& = Container());
template <class Alloc> explicit stack(const Alloc&);
template <class Alloc> stack(const Container&, const Alloc&);
template <class Alloc> stack(Container&&, const Alloc&);
template <class Alloc> stack(stack&&, const Alloc&);
bool empty() const;
size_t size() const;
T& top();
T const& top() const;
void push(T const&);
void push(T&&);
void pop();
void swap(stack&&);
};
Даже функция top() возвращает копию, а не ссылку, и внутренние данные защищены с помощью мьютекса, этот интерфейс все равно не будет застрахован от возникновения гонки. Проблема в том, что полагаться на результаты работы функций empty() и size() нельзя. Хотя на момент вызова они, вероятно, и были достоверными, но после возврата из функции любой другой поток может обратиться к стеку и затолкнуть в него новые элементы (push()), либо забрать существующие (pop()), причем до того, как поток, вызывающий empty() или size(), сможет воспользоваться этой информацией.
Более безопасный вариант реализации стека с упрощённым интерфейсом:
#include <exception>
#include <stack>
#include <mutex>
#include <memory>
struct empty_stack: std::exception
{
const char* what() const throw()
{
return "empty stack";
}
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack(){}
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data=other.data;
}
threadsafe_stack& operator=(const threadsafe_stack&) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
std::shared_ptr<T> const res(std::make_shared<T>(data.top()));
data.pop();
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if(data.empty()) throw empty_stack();
value=data.top();
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};
int main()
{
threadsafe_stack<int> si;
si.push(5);
si.pop();
if(!si.empty())
{
int x;
si.pop(x);
}
}
std::timed_mutex
Класс timed_mutex — это примитив синхронизации, который может использоваться для защиты общих данных от одновременного доступа нескольких потоков.
Подобно мьютексу, timed_mutex предлагает эксклюзивную, нерекурсивную семантику владения. Кроме того, timed_mutex предоставляет возможность попытаться захватить timed_mutex с таймаутом с помощью методов try_lock_for() и try_lock_until().
Метод try_lock_for():
-
Пытается заблокировать мьютекс. Поток ожидает до тех пор, пока не истечет указанное время ожидания или не будет получена блокировка, в зависимости от того, что наступит раньше. При успешном получении блокировки возвращает true, в противном случае возвращает false.
-
Если timeout_duration меньше или равно timeout_duration.zero(), то функция ведет себя как try_lock().
-
Эта функция может блокировать поток дольше, чем timeout_duration, из-за задержек в работе планировщика или конкуренции за ресурсы между потоками.
-
Стандарт рекомендует использовать steady_clock для измерения длительности. Если реализация использует вместо этого system_clock, время ожидания также может быть чувствительно к корректировке часов.
-
Как и в случае с try_lock(), этой функции разрешено ложно возвращать false, даже если мьютекс не был заблокирован каким-либо другим потоком в какой-то момент во время timeout_duration.
-
Если try_lock_for вызывается потоком, который уже владеет мьютексом, поведение не определено.
Пример:
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
#include <sstream>
std::mutex cout_mutex; // control access to std::cout
std::timed_mutex mutex;
void job(int id)
{
using Ms = std::chrono::milliseconds;
std::ostringstream stream;
for (int i = 0; i < 3; ++i) {
if (mutex.try_lock_for(Ms(100))) {
stream << "success ";
std::this_thread::sleep_for(Ms(100));
mutex.unlock();
} else {
stream << "failed ";
}
std::this_thread::sleep_for(Ms(100));
}
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << "[" << id << "] " << stream.str() << "n";
}
int main()
{
std::vector<std::thread> threads;
for (int i = 0; i < 4; ++i) {
threads.emplace_back(job, i);
}
for (auto& i: threads) {
i.join();
}
}
/*
Возможный вывод:
[0] failed failed failed
[3] failed failed success
[2] failed success failed
[1] success failed success
*/
Метод try_lock_until() работает так же, как try_lock_for(), но принимает std::chrono::time_point в качестве аргумента. Если timeout_time уже прошел, эта функция ведет себя как try_lock().
Пример:
#include <thread>
#include <iostream>
#include <chrono>
#include <mutex>
std::timed_mutex test_mutex;
void f()
{
auto now=std::chrono::steady_clock::now();
test_mutex.try_lock_until(now + std::chrono::seconds(10));
std::cout << "hello worldn";
}
int main()
{
std::lock_guard<std::timed_mutex> l(test_mutex);
std::thread t(f);
t.join();
}
RAII механизмы для блокировки мьютекса
std::lock_guard
Не рекомендуется использовать класс std::mutex напрямую, так как нужно помнить о вызове unlock на всех путях выполнения функции, в том числе на тех, которые завершаются броском исключения. То есть если между вызовами lock и unlock будет сгенерировано исключение, а вы этого не предусмотрите, то мьютекс не освободится, а заблокированные потоки так и останутся ждать. Проблема безопасности блокировок мьютексов в C++ threading library решена довольно обычным для C++ способом — применением техники RAII (Resource Acquisition Is Initialization). Оберткой служит шаблонный класс std::lock_guard. Это простой класс, конструктор которого вызывает метод lock для заданного объекта, а деструктор вызывает unlock. Также в конструктор класса std::lock_guard можно передать аргумент std::adopt_lock — индикатор, означающий, что mutex уже заблокирован и блокировать его заново не надо. std::lock_guard не содержит никаких других методов, и его нельзя копировать, переносить или присваивать.
Пример:
#include <thread>
#include <mutex>
#include <iostream>
int g_i = 0;
std::mutex g_i_mutex; // protects g_i
void safe_increment()
{
const std::lock_guard<std::mutex> lock(g_i_mutex);
++g_i;
std::cout << "g_i: " << g_i << "; in thread #"
<< std::this_thread::get_id() << 'n';
// g_i_mutex is automatically released when lock
// goes out of scope
}
int main()
{
std::cout << "g_i: " << g_i << "; in main()n";
std::thread t1(safe_increment);
std::thread t2(safe_increment);
t1.join();
t2.join();
std::cout << "g_i: " << g_i << "; in main()n";
}
/*
Возможный вывод:
g_i: 0; in main()
g_i: 1; in thread #140487981209344
g_i: 2; in thread #140487972816640
g_i: 2; in main()
*/
После появления std::scoped_lock в std::lock_guard пропала необходимость, он остаётся в языке лишь для обратной совместимости.
std::unique_lock
Класс unique_lock — это универсальная оболочка владения мьютексом, предоставляющая отсроченную блокировку, ограниченные по времени попытки блокировки, рекурсивную блокировку, передачу владения блокировкой и использование с condition variables.
Ограниченные по времени попытки блокировки работают так же, как и в классе std::timed_mutex. Для этого связанный мьютекс должен быть TimedLockable.
Отсроченная блокировка:
Класс std::unique_lock обеспечивает немного более гибкий подход, по сравнению с std::lock_guard: экземпляр std::unique_lock не всегда владеет связанным с ним мьютексом. Конструктору в качестве второго аргумента можно передавать не только объект std::adopt_lock, заставляющий объект блокировки управлять блокировкой мьютекса, но и объект отсрочки блокировки std::defer_lock, показывающий, что мьютекс при конструировании должен оставаться разблокированным. Блокировку можно установить позже, вызвав функцию lock() для объекта std::unique_lock (но не мьютекса) или же передав объект std::unique_lock функции std::lock().
std::unique_lock занимает немного больше памяти и работает несколько медленнее по сравнению с std::lock_guard. За гибкость, заключающуюся в разрешении экземпляру std::unique_lock не владеть мьютексом, приходится расплачиваться тем, что информация о состоянии должна храниться, обновляться и проверяться: если экземпляр действительно владеет мьютексом, деструктор должен вызвать функцию unlock(), в ином случае — не должен. Этот флаг можно запросить, вызвав метод owns_lock(). Если передача владения блокировкой или какие-то другие действия, требующие std::unique_lock, не предусматриваются, лучше воспользоваться классом std::scoped_lock из C++17.
Пример:
#include <mutex>
#include <thread>
#include <chrono>
struct Box {
explicit Box(int num) : num_things{num} {}
int num_things;
std::mutex m;
};
void transfer(Box &from, Box &to, int num)
{
// don't actually take the locks yet
std::unique_lock<std::mutex> lock1(from.m, std::defer_lock);
std::unique_lock<std::mutex> lock2(to.m, std::defer_lock);
// lock both unique_locks without deadlock
std::lock(lock1, lock2);
from.num_things -= num;
to.num_things += num;
// 'from.m' and 'to.m' mutexes unlocked in 'unique_lock' dtors
}
int main()
{
Box acc1(100);
Box acc2(50);
std::thread t1(transfer, std::ref(acc1), std::ref(acc2), 10);
std::thread t2(transfer, std::ref(acc2), std::ref(acc1), 5);
t1.join();
t2.join();
}
Рекурсивная блокировка:
std::unique_lock можно использовать с мьютексами, поддерживающими рекурсивную блокировку. Это не значит, что для одного и того же unique_lock можно несколько раз вызвать метод lock(). Это значит, что в одном потоке несколько разных экземпляров std::unique_lock могут вызвать метод lock() для одного и того же мьютекса. Повторный же вызов метода lock() для одного и того же экземпляра std::unique_lock приводит к исключению. Подробнее про работу рекурсивных мьютексов будет написано далее.
Передача владения блокировкой:
Объекты std::unique_lock являются перемещаемыми. Владение мьютексом может передаваться между экземплярами std::unique_lock путем перемещения. В некоторых случаях, например, при возвращении экземпляра из функции, оно происходит автоматически, а в других случаях его необходимо выполнять явным образом вызовом функции std::move(). По сути, все зависит от того, является ли источник l-значением— реальной переменной или ссылкой на таковую — или r-значением— неким временным объектом. Владение передается автоматически, если источник является r-значением, или же должно передаваться явным образом, если он является l-значением, во избежание случайной передачи владения за пределы переменной. Класс std::unique_lock— это пример перемещаемого, но не копируемого типа.
Один из вариантов возможного использования заключается в разрешении функции заблокировать мьютекс, а затем передать владение этой блокировкой вызывающему коду, который впоследствии сможет выполнить дополнительные действия под защитой этой же самой блокировки. Соответствующий пример показан в следующем фрагменте кода, где функция get_lock() блокирует мьютекс, а затем подготавливает данные перед тем, как вернуть блокировку вызывающему коду:
std::unique_lock<std::mutex> get_lock() {
extern std::mutex some_mutex;
std::unique_lock<std::mutex> lk(some_mutex);
prepare_data();
return lk;
}
void process_data() {
std::unique_lock<std::mutex> lk(get_lock());
do_something();
}
Поскольку lk — локальная переменная, объявленная внутри функции, ее можно возвратить напрямую, без вызова функции std:move(). О вызове конструктора перемещения позаботится компилятор. Затем функция process_data() сможет передать владение непосредственно в собственный экземпляр std::unique_lock, а вызов функции do_something() может полагаться на правильную подготовку данных. Обычно такой шаблон следует применять, когда блокируемый мьютекс зависит от текущего состояния программы или от аргумента, переданного в функцию, возвращающую объект std::unique_lock.
Использование с condition variables:
Подробнее про использование условных переменных будет написано ниже. А пока кратко…
Есть две реализации условных переменных, доступных в заголовке <condition_variable>:
-
condition_variable: требует от любого потока перед ожиданием сначала выполнить блокировку
std::unique_lock -
condition_variable_any: более общая реализация, которая работает с любым типом, который можно заблокировать. Эта реализация может быть более дорогой (с точки зрения ресурсов и производительности), поэтому ее следует использовать только если необходимы те дополнительные возможности, которые она предоставляет
Как использовать условные переменные:
-
Должен быть хотя бы один поток, ожидающий, пока какое-то условие станет истинным. Ожидающий поток должен сначала выполнить блокировку
unique_lock. Эта блокировка передается методуwait(), который освобождает мьютекс и приостанавливает поток, пока не будет получен сигнал от условной переменной. Когда это произойдет, поток пробудится и мьютекс снова заблокируется. -
Должен быть хотя бы один поток, сигнализирующий о том, что условие стало истинным. Сигнал может быть послан с помощью notify_one(), при этом будет разблокирован один (любой) поток из ожидающих, или notify_all(), что разблокирует все ожидающие потоки.
-
В виду некоторых сложностей при создании пробуждающего условия, могут происходить ложные пробуждения (spurious wakeup). Это означает, что поток может быть пробужден, даже если никто не сигнализировал условной переменной. Поэтому необходимо проверять, верно ли условие пробуждения уже после того, как поток был пробужден.
Пример:
#include <iostream>
#include <vector>
#include <thread>
std::vector<int> data;
std::condition_variable data_cond;
std::mutex m;
void thread_func1()
{
std::unique_lock<std::mutex> lock(m);
data.push_back(10);
data_cond.notify_one();
}
void thread_func2()
{
std::unique_lock<std::mutex> lock(m);
data_cond.wait(lock, [] {
return !data.empty();
});
std::cout << data.back() << std::endl;
}
int main()
{
std::thread th1(thread_func1);
std::thread th2(thread_func2);
th1.join();
th2.join();
}
Рекурсивная блокировка мьютекса
Попытка потока заблокировать мьютекс, которым он уже владеет, приводит при использовании std::mutex к ошибке и неопределенному поведению. Но порой бывает нужно, чтобы поток многократно получал один и тот же мьютекс, не разблокируя его предварительно. Для этой цели в стандартной библиотеке C++ предусмотрен класс std::recursive_mutex. Он работает так же, как и std::mutex, за тем лишь исключением, что на один его экземпляр можно из одного и того же потока получить несколько блокировок. Прежде чем мьютекс сможет быть заблокирован другим потоком, нужно будет снять все ранее установленные блокировки, поэтому, если функция lock() вызывается три раза, то три раза должна быть вызвана и функция unlock(). При правильном применении std::lock_guard и std::unique_lock все это будет сделано за вас автоматически.
В большинстве случаев при возникновении желания воспользоваться рекурсивным мьютексом, скорее всего, требуется внести изменения в архитектуру приложения.
std::recursive_mutex
Класс recursive_mutex — это примитив синхронизации, который может использоваться для защиты общих данных от одновременного доступа нескольких потоков.
recursive_mutex предлагает эксклюзивную рекурсивную семантику владения:
-
Вызывающий поток владеет
recursive_mutexв течение периода времени, который начинается, когда он успешно вызывает либоlock, либоtry_lock. В течение этого периода поток может совершать дополнительные вызовыlockилиtry_lock. Период владения заканчивается, когда поток делает соответствующее количество вызововunlock. -
Когда поток владеет
recursive_mutex, все остальные потоки будут ждать (для lock) или получать false (для try_lock), если они попытаются захватитьrecursive_mutex. -
Максимальное количество раз, которое
recursive_mutexможет быть заблокирован, в стандарте не указано, но после достижения этого числа вызовыlockбудут бросатьstd::system_error, а вызовыtry_lockбудут возвращать false.
Поведение программы не определено, если recursive_mutex уничтожается, все еще будучи заблокированным.
Пример:
#include <iostream>
#include <thread>
#include <mutex>
class X {
std::recursive_mutex m;
std::string shared;
public:
void fun1() {
std::lock_guard<std::recursive_mutex> lk(m);
shared = "fun1";
std::cout << "in fun1, shared variable is now " << shared << 'n';
}
void fun2() {
std::lock_guard<std::recursive_mutex> lk(m);
shared = "fun2";
std::cout << "in fun2, shared variable is now " << shared << 'n';
fun1(); // recursive lock becomes useful here
std::cout << "back in fun2, shared variable is " << shared << 'n';
};
};
int main()
{
X x;
std::thread t1(&X::fun1, &x);
std::thread t2(&X::fun2, &x);
t1.join();
t2.join();
}
/*
Возможный вывод:
in fun1, shared variable is now fun1
in fun2, shared variable is now fun2
in fun1, shared variable is now fun1
back in fun2, shared variable is fun1
*/
std::recursive_timed_mutex
std::recursive_timed_mutex работает аналогично тому, как работает std::timed_mutex, но предоставляет возможность многократной блокировки одного мьютекса в одном потоке, как std::recursive_mutex.
Мьютексы чтения-записи для защиты часто читаемых и редко обновляемых структур данных
Если мы производим только чтение данных, то гонки данных не возникает. Однако, если мы хотим изменять данные, то мы вынуждены защищать их от одновременного доступа. Но что делать, если большую часть времени структура данных используется только для чтения, а в защите мы нуждаемся только при редких обновлениях этой структуры. Блокировать потоки при каждом чтении без необходимости не хотелось бы, потому что от этого пострадает производительность. Поэтому применение std::mutex для защиты такой структуры данных имеет мрачные перспективы, поскольку при этом исключается возможность реализовать конкурентность при чтении структуры данных в тот период, когда она не подвергается модификации, так что нужен другой вид мьютекса. Этот другой тип мьютекса обычно называют мьютексом чтения — записи, поскольку он допускает два различных типа использования: монопольный доступ для одного потока записи или общий одновременный доступ для нескольких потоков чтения. Стандартная библиотека C++17 предоставляет два полностью готовых мьютекса такого вида, std::shared_mutex и std::shared_timed_mutex.
Для операций записи вместо можно использовать std::lock_guard<std::shared_mutex>и std::unique_lock<std::shared_mutex>. Они обеспечивают монопольный доступ, как и при использовании std::mutex. В потоках, которым не нужно обновлять структуру данных, для получения совместного доступа вместо этого можно воспользоваться std::shared_lock<std::shared_mutex>. Этот шаблон класса RAII был добавлен в C++14 и применяется так же, как и std::unique_lock, за исключением того, что несколько потоков могут одновременно получить общую блокировку на один и тот же мьютекс std::shared_mutex. Ограничение заключается в том, что, если какой-либо имеющий shared блокировку поток попытается получить монопольную блокировку, он будет ждать до тех пор, пока все другие потоки не снимут свои блокировки. Аналогично, если какой-либо поток имеет монопольную блокировку, никакой другой поток не может получить shared или монопольную блокировку, пока не снимет свою блокировку первый поток.
std::shared_mutex
Класс shared_mutex — это примитив синхронизации, который может использоваться для защиты общих данных от одновременного доступа нескольких потоков. В отличие от других типов мьютексов, которые обеспечивают эксклюзивный доступ, shared_mutex имеет два уровня доступа:
-
общий доступ — несколько потоков могут совместно владеть одним и тем же мьютексом.
-
эксклюзивный доступ (исключительная блокировка) — только один поток может владеть мьютексом.
Если один поток получил эксклюзивный доступ (через lock, try_lock), то никакие другие потоки не могут получить блокировку (включая общую).
Если один поток получил общую блокировку (через lock_shared, try_lock_shared), ни один другой поток не может получить эксклюзивную блокировку, но может получить общую блокировку.
Только если исключительная блокировка не была получена ни одним потоком, общая блокировка может быть получена несколькими потоками.
В пределах одного потока одновременно может быть получена только одна блокировка (общая или эксклюзивная).
shared_mutex особенно полезны, когда общие данные могут быть безопасно считаны любым количеством потоков одновременно, но поток может перезаписывать данные только тогда, когда ни один другой поток не читает и не записывает в это время.
Пример использования:
#include <iostream>
#include <mutex> // For std::unique_lock
#include <shared_mutex>
#include <thread>
class ThreadSafeCounter {
public:
ThreadSafeCounter() = default;
// Multiple threads/readers can read the counter's value at the same time.
unsigned int get() const {
std::shared_lock lock(mutex_);
return value_;
}
// Only one thread/writer can increment/write the counter's value.
void increment() {
std::unique_lock lock(mutex_);
value_++;
}
// Only one thread/writer can reset/write the counter's value.
void reset() {
std::unique_lock lock(mutex_);
value_ = 0;
}
private:
mutable std::shared_mutex mutex_;
unsigned int value_ = 0;
};
int main() {
ThreadSafeCounter counter;
auto increment_and_print = [&counter]() {
for (int i = 0; i < 3; i++) {
counter.increment();
std::cout << std::this_thread::get_id() << ' ' << counter.get() << 'n';
// Note: Writing to std::cout actually needs to be synchronized as well
// by another std::mutex. This has been omitted to keep the example small.
}
};
std::thread thread1(increment_and_print);
std::thread thread2(increment_and_print);
thread1.join();
thread2.join();
}
std::shared_timed_mutex
std::shared_timed_mutex предлагает такую же семантику владения мьютексом, как std::shared_mutex.
Кроме того, std::shared_timed_mutex подобно timed_mutex предоставляет возможность попытаться претендовать на владение shared_timed_mutex с таймаутом с помощью методов try_lock_for(), try_lock_until(), try_lock_shared_for(), try_lock_shared_until().
std::shared_lock
Класс shared_lock — это аналог std::unique_lock для получения общего доступа к данным, защищаемым с помощью shared_mutex. Он позволяет отсроченную блокировку, попытку блокировки с таймаутом и передачу права владения блокировкой. Блокировка shared_lock блокирует shared_mutex в общем режиме (чтобы заблокировать его в эксклюзивном режиме, можно использовать std::unique_lock).
Класс shared_lock является перемещаемым, но не копируемым.
Для работы с условными переменными можно использовать std::condition_variable_any (std::condition_variable требует std::unique_lock и поэтому поддерживает только исключительное владение).
Захват нескольких мьютексов одновременно
std::lock
При малой глубине детализации блокировок для какой-либо операции может быть необходимо заблокировать два или более мьютекса. При этом может возникнуть еще одна проблема — взаимная блокировка. При взаимной блокировке один поток ждет завершения выполнения операции другим, поэтому ни один из потоков не выполняет работы.
Представьте себе игрушку, например, барабан с палочками. Играть с ним можно только при наличии обеих частей, из которых он состоит. А теперь представьте двух малышей, желающих с ним поиграть. Если у одного из них будут и барабан, и палочки, он сможет весело играть, пока не надоест. Если другому тоже захочется поиграть, ему, как ни досадно, придется подождать. Допустим, барабан и палочки валяются по отдельности в коробке с игрушками, а обоим малышам вдруг захотелось поиграть на барабане и они стали рыться в ней. Один нашел барабан, а другой — палочки. Возникла тупиковая ситуация: пока кто-нибудь не уступит и не даст поиграть другому, каждый останется при своем, требуя отдать ему недостающее, при этом никто не сможет играть на барабане.
Теперь представьте, что спорят не малыши из-за игрушек, а потоки из-за блокировок мьютексов: чтобы выполнить некую операцию, каждая пара потоков нуждается в блокировке каждой пары мьютексов, у каждого потока имеется один заблокированный мьютекс и он ожидает разблокировки другого мьютекса. Продолжить выполнение не может ни один из потоков, поскольку каждый ждет, когда другой разблокирует свой мьютекс. Такой сценарий называется взаимной блокировкой и представляет собой серьезную проблему при необходимости заблокировать для выполнения одной операции два мьютекса и более.
Общий совет по обходу взаимной блокировки заключается в постоянной блокировке двух мьютексов в одном и том же порядке: если всегда блокировать мьютекс А перед блокировкой мьютекса Б, то взаимной блокировки никогда не произойдет. Иногда это условие выполнить несложно, поскольку мьютексы служат разным целям, но кое-когда все гораздо сложнее, например, когда каждый из мьютексов защищает отдельный экземпляр одного и того же класса. Рассмотрим пример, в котором какая-то функция выполняет действие над двумя объектами одного класса. Чтобы обеспечить корректную работу и при этом избежать влияния изменений, вносимых в режиме конкурентности, следует заблокировать мьютексы на обоих экземплярах. Но если выбрать определенный порядок, например сначала блокировать мьютекс для экземпляра, переданного в качестве первого параметра, а затем мьютекс для экземпляра, переданного в качестве второго параметра, то можно получить обратный эффект: стоит всего другому потоку вызвать функцию с переставленными местами параметрами, и вы получите взаимную блокировку. В стандартной библиотеке C++ есть средство от этого в виде std::lock — функции, способной одновременно заблокировать два и более мьютекса, не рискуя вызвать взаимную блокировку.
#include <mutex>
#include <thread>
#include <iostream>
#include <vector>
#include <functional>
#include <chrono>
#include <string>
struct Employee {
Employee(std::string id) : id(id) {}
std::string id;
std::vector<std::string> lunch_partners;
std::mutex m;
std::string output() const
{
std::string ret = "Employee " + id + " has lunch partners: ";
for( const auto& partner : lunch_partners )
ret += partner + " ";
return ret;
}
};
void send_mail(Employee &, Employee &)
{
// simulate a time-consuming messaging operation
std::this_thread::sleep_for(std::chrono::seconds(1));
}
void assign_lunch_partner(Employee &e1, Employee &e2)
{
static std::mutex io_mutex;
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout << e1.id << " and " << e2.id << " are waiting for locks" << std::endl;
}
// use std::lock to acquire two locks without worrying about
// other calls to assign_lunch_partner deadlocking us
{
std::lock(e1.m, e2.m);
std::lock_guard<std::mutex> lk1(e1.m, std::adopt_lock);
std::lock_guard<std::mutex> lk2(e2.m, std::adopt_lock);
// Equivalent code (if unique_locks are needed, e.g. for condition variables)
// std::unique_lock<std::mutex> lk1(e1.m, std::defer_lock);
// std::unique_lock<std::mutex> lk2(e2.m, std::defer_lock);
// std::lock(lk1, lk2);
// Superior solution available in C++17
// std::scoped_lock lk(e1.m, e2.m);
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout << e1.id << " and " << e2.id << " got locks" << std::endl;
}
e1.lunch_partners.push_back(e2.id);
e2.lunch_partners.push_back(e1.id);
}
send_mail(e1, e2);
send_mail(e2, e1);
}
int main()
{
Employee alice("alice"), bob("bob"), christina("christina"), dave("dave");
// assign in parallel threads because mailing users about lunch assignments
// takes a long time
std::vector<std::thread> threads;
threads.emplace_back(assign_lunch_partner, std::ref(alice), std::ref(bob));
threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(bob));
threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(alice));
threads.emplace_back(assign_lunch_partner, std::ref(dave), std::ref(bob));
for (auto &thread : threads) thread.join();
std::cout << alice.output() << 'n' << bob.output() << 'n'
<< christina.output() << 'n' << dave.output() << 'n';
}
Корректная разблокировка мьютексов при выходе из функции в этом примере обеспечивается с помощью использования std::lock_guard. В дополнение к мьютексу предоставляется параметр std::adopt_lock, чтобы показать объектам std::lock_guard, что мьютексы уже заблокированы. Объекты должны овладеть существующей блокировкой мьютекса, а не пытаться заблокировать его в конструкторе. Следует также отметить, что блокировка одного из мьютексов внутри вызова std::lock может привести к выдаче исключения, в таком случае исключение распространяется из std::lock. Если функцией std::lock успешно заблокирован один мьютекс, а исключение выдано при попытке заблокировать другой, первый мьютекс разблокируется автоматически: в отношении блокировки предоставленных мьютексов функция std::lock обеспечивает семантику «все или ничего».
Применение std::lock позволяет избавиться от взаимных блокировок, когда нужно завладеть сразу двумя и более блокировками, однако оно не поможет, если блокировки захватываются разобщенно. В таком случае, чтобы гарантировать обход взаимных блокировок, разработчикам приходится полагаться на самодисциплину. А это не так-то просто: взаимоблокировки относятся к одной из самых неприятных проблем, с которой приходится сталкиваться в многопоточном коде, их возникновение зачастую невозможно предсказать, поскольку в большинстве случаев все работает нормально. И тем не менее существует ряд относительно простых правил, помогающих создавать код, не подверженный взаимным блокировкам.
Все рекомендации по обходу взаимных блокировок сводятся к одному: не ждать завершения операции другим потоком, если есть вероятность, что он также ждет завершения операции текущим потоком:
-
Избегайте вложенных блокировок. Не устанавливайте блокировку, если уже есть какая-либо блокировка.
-
При удержании блокировки вызова избегайте кода, предоставленного пользователем. Если при удержании блокировки вызвать пользовательский код, устанавливающий блокировку, окажется нарушена рекомендация, предписывающая избегать вложенных блокировок, и может возникнуть взаимная блокировка.
-
Устанавливайте блокировки в фиксированном порядке. Если есть настоятельная необходимость установить две и более блокировки, но в рамках единой операции с помощью std::lock это невозможно, лучшее, что можно сделать, — установить их в каждом потоке в одном и том же порядке.
-
Используйте иерархию блокировок. Являясь частным случаем определения порядка блокировок, иерархия блокировок позволяет обеспечить средство проверки соблюдения соглашения в ходе выполнения программы. Такую проверку можно произвести в ходе выполнения программы, назначив номера уровней каждому мьютексу и сохранив записи о том, какие мьютексы заблокированы каждым потоком. Этот шаблон получил очень широкое распространение, но его прямая поддержка в стандартной библиотеке C++ не обеспечивается, поэтому нужно создать собственный тип мьютекса hierarchical_mutex.
std::try_lock
Аналог std::lock для попытки блокировки нескольких мьютексов. try_lock не приведёт к взаимной блокировке, даже если не будет определённого порядка блокировок. Поэтому он пытается заблокировать каждый из переданных блокируемых объектов lock_1, lock_2, …, lock_n, вызывая их метод try_lock в том порядке, в котором они переданы.
Если вызов try_lock для какого-либо аргумента завершается неудачно, дальнейшие вызовы try_lock не выполняются, а вызывается unlock для всех заблокированных объектов и возвращается индекс объекта, который не удалось заблокировать, начиная с 0.
Если вызов try_lock для какого-либо аргумента приводит к исключению, вызывается unlock для всех заблокированных объектов перед пробросом исключения наверх.
Возвращаемое значение: -1 при успешном выполнении или 0-based индекс объекта, который не удалось заблокировать.
std::scoped_lock
В C++17 предоставляется способ блокировки нескольких мьютексов одновременно в виде нового RAII-шаблона std::scoped_lock<>. Он практически эквивалентен std::lock_guard<>, за исключением того, что является вариационным шаблоном, принимающим в качестве параметров шаблона список типов мьютексов, а в качестве аргументов конструктора — список мьютексов. Предоставленные конструктору мьютексы блокируются с использованием такого же алгоритма, как и в std::lock, и, когда конструктор завершает работу, они оказываются заблокированными, а затем разблокируются в деструкторе.
Однократный вызов функции с помощью std::call_once и std::once_flag
Предположим, что есть совместно используемый ресурс, создание которого настолько затратно, что заниматься этим хочется лишь в крайней необходимости, когда пользователь обратился к этому ресурсу: возможно, он открывает подключение к базе данных или выделяет слишком большой объем памяти. Подобная отложенная (или ленивая) инициализация (lazy initialization) довольно часто встречается в однопоточном коде — каждая операция, требующая ресурса, сначала проверяет, не был ли он инициализирован, и, если не был, прежде чем воспользоваться этим ресурсом, инициализирует его. Если совместно используемый ресурс безопасен при получении к нему конкурентного доступа, единственной частью, нуждающейся в защите при преобразовании кода в многопоточный, является инициализация. Можно было бы защитить инициализацию мьютексом в многопоточном приложении:
#include <memory>
#include <mutex>
struct some_resource
{
void do_something()
{}
};
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;
void foo()
{
std::unique_lock<std::mutex> lk(resource_mutex);
if(!resource_ptr)
{
resource_ptr.reset(new some_resource);
}
lk.unlock();
resource_ptr->do_something();
}
int main()
{
foo();
}
Но это может привести к ненужным блокировкам потоков, использующих ресурс. Причина в том, что каждый поток будет вынужден ожидать разблокировки мьютекса, чтобы проверить, не был ли ресурс уже инициализирован. Эта проблема настолько распространена, что многие пытались придумать более подходящий способ решения данной задачи, включая небезызвестный шаблон блокировки с двойной проверкой: сначала указатель считывается без получения блокировки, которая устанавливается, только если он имеет значение NULL. После получения блокировки указатель проверяется еще раз на тот случай, если между первой проверкой и получением блокировки данным потоком инициализация была выполнена каким-нибудь другим потоком:
void undefined_behaviour_with_double_checked_locking() {
if (!resource_ptr) {
std::lock_guard<std::mutex> lk(resource_mutex);
if (!resource_ptr) {
resource_ptr.reset(new some_resource);
}
}
resource_ptr->do_something();
}Чтобы справиться с данной ситуацией, стандартная библиотека C++ предоставляет компоненты std::once_flag и std::call_once. Вместо блокировки мьютекса и явной проверки указателя каждый поток может безопасно воспользоваться функцией std::call_once, зная, что к моменту возвращения управления из этой функции указатель будет инициализирован каким-либо потоком. Необходимые для этого данные синхронизации хранятся в экземпляре std::once_flag, и каждый экземпляр std::once_flag соответствует другой инициализации. Задействование функции std::call_once обычно связано с меньшими издержками по сравнению с явным использованием мьютекса, особенно когда инициализация уже была выполнена. Поэтому предпочтение следует отдавать именно ей. Пример выше можно было бы изменить так:
std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag;
void init_resource() {
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag, init_resource);
resource_ptr->do_something();
}Один из сценариев, предполагающих вероятность состояния гонки при инициализации, до C++11 был связан с применением локальной переменной, объявленной с ключевым словом static. Инициализация такой переменной определена так, чтобы она выполнялась при первом прохождении потока управления через ее объявление. Это означало, что несколько потоков, вызывающих функцию, в стремлении первыми выполнить определение могли вызвать состояние гонки. На многих компиляторах, предшествующих C++11, это создавало реальные проблемы, поскольку начать инициализацию могли сразу несколько потоков или же они могли пытаться использовать во время инициализации, запущенной в другом потоке. В C++11 эта проблема была решена: инициализация определена так, что выполняется только в одном потоке, и никакие другие потоки не будут продолжать выполнение до тех пор, пока эта инициализация не будет завершена. Когда нужна только одна глобальная переменная, этим свойством можно воспользоваться в качестве альтернативы std::call_once:
class MyClass;
MyClass& get_instance() {
static MyClass instance;
return instance;
}Итак, std::call_once:
-
Выполняет вызываемый объект f ровно один раз, даже если он вызывается одновременно из нескольких потоков.
-
Если к моменту вызова call_once флаг указывает, что f уже был вызван, call_once сразу же завершается (пассивный вызов call_once).
-
В противном случае call_once вызывает
std::forward(f)с аргументамиstd::forward(args). В отличие от конструктораstd::threadилиstd::async, аргументы не перемещаются и не копируются, поскольку их не нужно передавать в другой поток выполнения. (активный вызов call_once). -
Если вызов функции бросает исключение, оно передается в call_once, и флаг не устанавливается, чтобы был совершён другой вызов (exceptional вызов call_once).
-
Если этот вызов функции завершился успешно (returning вызов call_once), флаг устанавливается, и все остальные вызовы call_once с тем же флагом гарантированно будут пассивными.
-
Все активные вызовы с одним и тем же флагом образуют последовательность, состоящую из нуля или более exceptional вызовов, за которыми следует один returning вызов.
-
Если параллельные вызовы call_once выполняют различные функции f, то не определено, какая именно функция f будет вызвана. Выполняемая функция выполняется в том же потоке, что и call_once.
-
Инициализация локальной статической переменной гарантированно происходит только один раз, даже при вызове из нескольких потоков, и может быть более эффективной, чем эквивалентный код, использующий
std::call_once. -
POSIX-эквивалентом этой функции является
pthread_once.
Условные переменные (Condition variables)
Представьте, что вы едете в ночном поезде. Чтобы гарантированно сойти на нужной станции, придется не спать всю ночь и внимательно отслеживать все остановки. Свою станцию вы не пропустите, но сойдете с поезда уставшим. Но есть и другой способ: заглянуть в расписание, увидеть предполагаемое время прибытия поезда на нужную станцию, поставить будильник на нужное время с небольшим запасом и лечь спать. Этого будет вполне достаточно, и вы не пропустите свою станцию, но, если поезд задержится, пробуждение окажется слишком ранним. Идеальным решением было бы лечь спать, попросив проводника разбудить вас на нужной станции.
Какое отношение все это имеет к потокам? Если какой-то поток ожидает, пока другой поток завершит выполнение своей задачи, есть несколько вариантов развития событий. Во-первых, первый поток может постоянно проверять состояние флага в совместно используемых данных, защищенных мьютексом, а второй поток будет обязан установить флаг по завершении своей задачи. Это весьма накладно по двум соображениям: постоянно проверяя состояние флага, поток впустую тратит ценное процессорное время, а когда мьютекс заблокирован ожидающим потоком, его нельзя заблокировать никаким другим потоком. Второй вариант предполагает введение ожидающего потока в спящий режим на короткий промежуток времени между проверками с помощью функции std::this_thread::sleep_for(). Это уже гораздо лучше, поскольку поток, находясь в спящем режиме, не тратит процессорное время впустую, но хороший период пребывания в нем подобрать довольно трудно. Слишком короткий период спячки между проверками — и поток по-прежнему тратит впустую время процессора на слишком частые проверки, слишком длинный период спячки — и поток не выйдет из нее позже положенного, что приведет к ненужной задержке. Позднее пробуждение напрямую влияет на работу программы довольно редко, но в приложении реального времени это может быть критичным. Третьим и наиболее предпочтительным вариантом является использование средств из стандартной библиотеки C++, предназначенных для ожидания наступления какого-либо события. Основным механизмом для реализации такого ожидания является условная переменная. Концептуально она связана с каким-либо условием, и один или несколько потоков могут ожидать выполнения этого условия. Когда другой поток обнаружит, что условие выполнено, он может известить об этом один или несколько потоков, ожидающих условную переменную, чтобы разбудить их и позволить продолжить работу.
Стандартная библиотека C++ предоставляет не одну, а две реализации условной переменной: std::condition_variable и std::condition_variable_any. Обе они объявлены в заголовке <condition_variable>. В обоих случаях для соответствующей синхронизации им нужно работать с мьютексом: первая реализация ограничивается работой только с std::mutex, а вторая может работать с любыми типами, которые работают как мьютекс, о чем свидетельствует суффикс _any. Если не требуется дополнительная гибкость, предпочтение следует отдавать реализации std::condition_variable.
std::condition_variable
Класс condition_variable — это примитив синхронизации, который может использоваться для блокировки потока или нескольких потоков до тех пор, пока другой поток не изменит общую переменную (не выполнит условие) и не уведомит об этом condition_variable.
Поток, который намеревается изменить общую переменную, должен:
-
захватить
std::mutex(обычно черезstd::lock_guard) -
выполнить модификацию, пока удерживается блокировка мьютекса
-
выполнить
notify_oneилиnotify_allнаstd::condition_variable(блокировка не должна удерживаться для уведомления)
Даже если общая переменная является атомарной, всё равно требуется использовать мьютекс для корректного оповещения ожидающих потоков.
Любой поток, который ожидает наступления события от std::condition_variable, должен:
-
С помощью
std::unique_lock<std::mutex>получить блокировку того же мьютекса, который используется для защиты общей переменной. -
Проверить, что необходимое условие ещё не выпонлено.
-
Вызвать метод wait, wait_for или wait_until. Операции ожидания освобождают мьютекс и приостанавливают выполнение потока.
-
Когда получено уведомление, истёк тайм-аут или произошло ложное пробуждение, поток пробуждается, и мьютекс повторно блокируется. Затем поток должен проверить, что условие, действительно, выполнено, и возобновить ожидание, если пробуждение было ложным.
Вместо трёх последних шагов можно воспользоваться перегрузкой методов wait, wait_for и wait_until, которая принимает предикат для проверки условия и выполняет три последних шага.
std::condition_variable работает только с std::unique_lock<std::mutex>; это ограничение обеспечивает максимальную эффективность на некоторых платформах. std::condition_variable_any работает с любым BasicLockable объектом, например, с std::shared_lock.
Condition variables допускают одновременный вызов методов wait, wait_for, wait_until, notify_one и notify_all из разных потоков.
Пример использования:
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex m;
std::condition_variable cv;
std::string data;
bool ready = false;
bool processed = false;
void worker_thread()
{
// Wait until main() sends data
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, []{return ready;});
// after the wait, we own the lock.
std::cout << "Worker thread is processing datan";
data += " after processing";
// Send data back to main()
processed = true;
std::cout << "Worker thread signals data processing completedn";
// Manual unlocking is done before notifying, to avoid waking up
// the waiting thread only to block again (see notify_one for details)
lk.unlock();
cv.notify_one();
}
int main()
{
std::thread worker(worker_thread);
data = "Example data";
// send data to the worker thread
{
std::lock_guard<std::mutex> lk(m);
ready = true;
std::cout << "main() signals data ready for processingn";
}
cv.notify_one();
// wait for the worker
{
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, []{return processed;});
}
std::cout << "Back in main(), data = " << data << 'n';
worker.join();
}
/*
Возможный вывод:
main() signals data ready for processing
Worker thread is processing data
Worker thread signals data processing completed
Back in main(), data = Example data after processing
*/
std::condition_variable_any
Этот тип условной переменной имеет такой же интерфейс, как std::condition_variable, но может использоваться не только с std::unique_lock<std::mutex>, а с любым блокируемым типом. Работает медленее, чем std::condition_variable. Может использоваться, например, для работы с std::shared_lock.
std::notify_all_at_thread_exit
Стандартная библиотека предоставляет ещё одну функцию для использования в ситуациях, когда мы с помощью condition_variable хотим дождаться завершения потока.
Зачем это нужно?
N2880: C++ object lifetime interactions with the threads API
N3070 — Handling Detached Threads and thread_local Variables
Допустим, мы хотим дождаться завершения detached потока, в этом случае мы не можем использовать метод join для ожидания завершения потока. Тогда мы решаем, что нужно использовать condition_variable для уведомления о том, что поток завершается. Но если мы просто в конец функции, выполняемой в отдельном потоке, добавим cv.notify_all();, то получим поведение отличное от того, которое нам нужно. Несмотря на то, что эта команда будет последней в функции потока, поток на ней ещё не заканчивает выполнение. После вызова notify_all в этом же потоке будет происходить уничтожение thread_local переменных, будут вызываться их деструкторы и выполняться какие-либо действия. То есть, на самом деле, уведомление было отправлено ещё до того, как поток завершился.
Тогда как на самом деле дождаться полного завершения detached потока? Для этого стандартная библиотека предоставляет функцию std::notify_all_at_thread_exit. Она дожидается завершения потока, в том числе уничтожения thread_local переменных, и последними действиями в потоке выполняет:
lk.unlock();
cond.notify_all();Эквивалентный эффект может быть достигнут с помощью средств, предоставляемых std::promise или std::packaged_task.
Пример использования:
#include <mutex>
#include <thread>
#include <condition_variable>
#include <cassert>
#include <string>
std::mutex m;
std::condition_variable cv;
bool ready = false;
std::string result; // some arbitrary type
void thread_func()
{
thread_local std::string thread_local_data = "42";
std::unique_lock<std::mutex> lk(m);
// assign a value to result using thread_local data
result = thread_local_data;
ready = true;
std::notify_all_at_thread_exit(cv, std::move(lk));
} // 1. destroy thread_locals;
// 2. unlock mutex;
// 3. notify cv.
int main()
{
std::thread t(thread_func);
t.detach();
// do other work
// ...
// wait for the detached thread
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, []{ return ready; });
// result is ready and thread_local destructors have finished, no UB
assert(result == "42");
}
Семафоры (Semaphores)
В C++20 в стандартной библиотеке появились семафоры.
Семафор (semaphore) — примитив синхронизации работы процессов и потоков, в основе которого лежит счётчик, над которым можно производить две атомарные операции: увеличение и уменьшение значения на единицу, при этом операция уменьшения для нулевого значения счётчика является блокирующей. Служит для построения более сложных механизмов синхронизации и используется для синхронизации параллельно работающих задач, для защиты передачи данных через разделяемую память, для защиты критических секций, а также для управления доступом к аппаратному обеспечению.
Семафоры могут быть двоичными и вычислительными. Вычислительные семафоры могут принимать целочисленные неотрицательные значения и используются для работы с ресурсами, количество которых ограничено, либо участвуют в синхронизации параллельно исполняемых задач. Двоичные семафоры могут принимать только значения 0 и 1 и используются для взаимного исключения одновременного нахождения двух или более процессов в своих критических секциях.
Мьютексные семафоры(мьютексы) являются упрощённой реализацией семафоров, аналогичной двоичным семафорам с тем отличием, что мьютексы должны отпускаться тем же потоком, который осуществляет их захват. Мьютексы наряду с двоичными семафорами используются в организации критических участков кода. В отличие от двоичных семафоров, начальное состояние мьютекса не может быть захваченным.
С помощью семафоров можно решать много разных задач синхронизации.
Проблемы, с которыми можно столкнуться при использовании семафоров
Стандартная библиотека C++ предлагает к использованию вычислительные и двоичные семафоры, представленные классами std::counting_semaphore, std::binary_semaphore.
counting_semaphore — это примитив синхронизации, который может управлять доступом к общему ресурсу. В отличие от мьютекса std::mutex, counting_semaphore допускает более одного параллельного доступа к одному и тому же ресурсу.
counting_semaphore содержит внутренний счетчик, который инициализируется конструктором. Этот счетчик уменьшается при вызовах метода acquire() и связанных с ним методов и увеличивается при вызовах метода release(). Когда счетчик равен нулю, acquire() блокирует поток до тех пор, пока счетчик не увеличится. Кроме того, для использования доступны методы:
-
try_acquire()не блокирует поток, а возвращает вместо этого false. Подобноstd::condition_variable::wait(), методtry_acquire()может ошибочно возвращать false. -
try_acquire_for()иtry_acquire_until()блокируют до тех пор, пока счетчик не увеличится или не будет достигнут таймаут.
Семафоры нельзя копировать и перемещать.
В отличие от std::mutex, counting_semaphore не привязан к потокам выполнения — освобождение release() и захват acquire() семафора могут производиться в разных потоках (блокировка и освобождение мьютекса должны производиться одним и тем же потоком). Все операции над counting_semaphore могут выполняться одновременно и без какой-либо связи с конкретными потоками выполнения.
Семафоры также часто используются для реализации уведомлений. При этом семафор инициализируется значением 0, и потоки, ожидающие события блокируются методом acquire(), пока уведомляющий поток не вызовет release(n). В этом отношении семафоры можно рассматривать как альтернативу std::condition_variables.
Методы acquire() уменьшают значение счётчика семафора на 1. Методу release() можно передать в качестве параметра значение, на которое должен быть увеличен счётчик, по умолчанию значение равно 1.
std::counting_semaphore<std::ptrdiff_t LeastMaxValue = /* implementation-defined */> является шаблонным классом. В качестве параметра шаблона принимает значение, которое является нижней границей для максимально возможного значения счётчика. Фактический же максимум значений счётчика определяется реализацией и может быть больше, чем LeastMaxValue.
binary_semaphore — это просто псевдоним using binary_semaphore = std::counting_semaphore<1>;.
Пример использования:
#include <iostream>
#include <thread>
#include <chrono>
#include <semaphore>
// global binary semaphore instances
// object counts are set to zero
// objects are in non-signaled state
std::binary_semaphore
smphSignalMainToThread(0),
smphSignalThreadToMain(0);
void ThreadProc()
{
// wait for a signal from the main proc
// by attempting to decrement the semaphore
smphSignalMainToThread.acquire();
// this call blocks until the semaphore's count
// is increased from the main proc
std::cout << "[thread] Got the signaln"; // response message
// wait for 3 seconds to imitate some work
// being done by the thread
using namespace std::literals;
std::this_thread::sleep_for(3s);
std::cout << "[thread] Send the signaln"; // message
// signal the main proc back
smphSignalThreadToMain.release();
}
int main()
{
// create some worker thread
std::thread thrWorker(ThreadProc);
std::cout << "[main] Send the signaln"; // message
// signal the worker thread to start working
// by increasing the semaphore's count
smphSignalMainToThread.release();
// wait until the worker thread is done doing the work
// by attempting to decrement the semaphore's count
smphSignalThreadToMain.acquire();
std::cout << "[main] Got the signaln"; // response message
thrWorker.join();
}
/*
Вывод:
[main] Send the signal
[thread] Got the signal
[thread] Send the signal
[main] Got the signal
*/
Защёлки и барьеры (Latches and Barriers)
В C++20 в стандартной библиотеке появились барьеры.
Защелки latches и барьеры barriers — это механизм синхронизации потоков, который позволяет блокировать любое количество потоков до тех пор, пока ожидаемое количество потоков не достигнет барьера. Защелки нельзя использовать повторно, барьеры можно использовать повторно.
Эти механизмы синхронизации используются, когда выполнение параллельного алгоритма можно разделить на несколько этапов, разделённых барьерами. В частности, с помощью барьера можно организовать точку сбора частичных результатов вычислений, в которой подводится итог этапа вычислений. Например, если стоит задача отфильтровать изображение с помощью двух разных фильтров, и разные потоки фильтруют разные части изображения, то перед началом второй фильтрации следует дождаться, когда первая фильтрация будет полностью завершена, то есть все потоки должны дойти до барьера между двумя этапами фильтрации.
Барьер для группы потоков в исходном коде означает, что каждый поток должен остановиться в этой точке и подождать достижения барьера другими потоками группы. Когда все потоки достигли барьера, их выполнение продолжается.
std::latch
std::latch — это уменьшающийся счетчик. Значение счетчика инициализируется при создании. Потоки уменьшают значение счётчика и блокируются на защёлке до тех пор, пока счетчик не уменьшится до нуля. Нет возможности увеличить или сбросить счетчик, что делает защелку одноразовым барьером.
В отличие от std::barrier, std::latch может быть уменьшен одним потоком более одного раза.
Использовать защёлки очень просто. В нашем распоряжении несколько методов:
-
count_down(value) уменьшает значение счётчика на value (по умолчанию 1) без блокировки потока. Если значение счётчика становится отрицательным, то поведение не определено. -
try_wait() позволяет проверить, не достигло ли значение счётчика нуля. С низкой вероятностью может ложно возвращать false. -
wait()блокирует текущий поток до тех пор, пока счётчик не достигнет нулевого значения. Если значение счётчика уже равно 0, то управление возвращается немедленно. -
arrive_and_wait(value)уменьшает значение счётчика на value (по умолчанию 1) и блокирует текущий поток до тех пор, пока счётчик не достигнет нулевого значения. Если значение счётчика становится отрицательным, то поведение не определено.
Пример:
void DoWork(threadpool* pool) {
latch completion_latch(NTASKS);
for (int i = 0; i < NTASKS; ++i) {
pool->add_task([&] {
// perform work
...
completion_latch.count_down();
}));
}
// Block until work is done
completion_latch.wait();
}std::barrier
Используется почти так же, как std::latch, но является многоразовым: как только ожидающие потоки разблокируются, значение счётчика устанавливается в начальное, и тот же самый барьер может быть использован повторно.
Работу барьера можно разбить на фазы. Фаза заканчивается, когда счётчик барьера обнуляется, затем начинается новая фаза. Фазы работы имеют идентификаторы, которые возвращаются некоторыми методами. Это нужно для того, чтобы мы не ждали конца фазы, которая уже завершена.
Итак, как пользоваться барьерами? В нашем распоряжении следующие методы:
-
arrive(value)уменьшает текущее значение счётчика на value (по умолчанию 1). Поведение не определено, если значение счётчика станет отрицательным. Метод возвращает идентификатор фазы, который имеет тип arrival_token. -
wait(arrival_token)блокирует текущий поток до тех пор, пока указанная фаза не завершится. Принимает идентификатор фазы в качестве параметра. -
arrive_and_wait()уменьшает текущее значение счётчика на 1 и блокирует текущий поток до тех пор, пока счётчик не обнулится. Эквивалентно вызовуwait(arrive());. Поведение не определено, если вызов происходит, когда значение счётчика равно нулю. Поэтому количество потоков, уменьшающих счётчик барьера, не должно быть больше начального значения счётчика. -
arrive_and_drop()уменьшает на 1 начальное значение счётчика для следующих фаз, а так же текущее значение счётчика. Поведение не определено, если вызов происходит, когда значение счётчика равно нулю.
Пример:
int n_threads;
std::vector<thread*> workers;
std::barrier task_barrier(n_threads);
for (int i = 0; i < n_threads; ++i) {
workers.push_back(new thread([&] {
for(int step_no = 0; step_no < 5; ++step_no) {
// perform step
...
task_barrier.arrive_and_wait();
}
});
}Возврат значений и проброс исключений (Futures)
Предположим, что имеются какие-то длительные вычисления, которые, как ожидается, вернут со временем полезный результат, значение которого вам пригодится позже. Для выполнения вычислений можно запустить новый поток, но это будет означать, что следует позаботиться о передаче результата в основную программу, поскольку std::thread не предоставляет непосредственного механизма для выполнения этой задачи.
Стандартная библиотека предоставляет средства для получения возвращаемых значений и перехвата исключений, создаваемых асинхронными задачами (т. е. функциями, запущенными в отдельных потоках). Эти значения передаются через общие объекты состояния выполнения, в которые асинхронная задача может записать свое возвращаемое значение или сохранить исключение, и которые могут быть проверены другими потоками, содержащими экземпляры std::future или std::shared_future, ссылающиеся на это общее состояние.
Кроме непосредственно механизма возврата значений с помощью std::future и std::promise, стандартная библиотека предоставляет более высокоуровневые средства для запуска задач, которые должны вернуть значение. std::packaged_task является обёрткой для ваших функций, которая позволяет автоматизировать сохранение результата в std::promise. А std::async является наиболее высокоуровневым инструментом для автоматического запуска задачи в отдельном потоке с возможностью позже запросить результат выполнения. Начнём рассмотрение с базовых низкоуровневых инструментов, чтобы понимать механику работы.
Низкоуровневые средства: возврат значений и проброс исключений с помощью std::future и std::promise
std::promise — это базовый механизм, позволяющий передавать значение между потоками. Каждый объект std::promise связан с объектом std::future. Это пара классов, один из которых (std::promise) отвечает за установку значения, а другой (std::future) — за его получение. Первый поток может ожидать установки значения с помощью вызова метода std::future::wait или std::future::get, в то время, как второй поток установит это значение с помощью вызова метода std::promise::set_value, или передаст первому исключение вызовом метода std::promise::set_exception.
Возврат значения
Шаблон класса std::promise предоставляет средство для сохранения значения или исключения, которое позже асинхронно забирается через объект std::future, созданный объектом std::promise.
Шаблон класса std::future предоставляет механизм доступа к результату асинхронных операций.
Пара объектов std::promise и связанный с ним std::future образуют канал связи между потоками. std::promise предоставляет операцию push для этого канала связи. Значение, записанное с помощью promise, может быть прочитано с помощью объекта future.
Каждый объект promise связан с общим состоянием выполнения, которое может быть еще не установлено или может хранить значение или исключение. Когда асинхронная операция готова вернуть результат, она может сделать это, изменив общее состояние (например, с помощью метода std::promise::set_value). Объект std::future (его можно получить с помощью метода std::promise::get_future) связывается с этим же самым общим состоянием. Поток, запустивший асинхронную операцию может затем использовать различные методы для проверки, ожидания готовности или извлечения значения из std::future. Эти методы могут блокировать выполнение, если асинхронная операция еще не предоставила значение.
Сохранение результата или исключения в std::promise приводит операцию в состояние готовности. Эта операция разблокирует поток, ожидающий результата. Если объект promise был уничтожен, а результат (значение или исключение) не был сохранён, то сохраняется исключение типа std::future_error с кодом ошибки std::future_errc::broken_promise, происходит приведение в состояние готовности.
Обратите внимание:
-
объект
std::promiseпредназначен для использования только один раз, запросить значение (get()) изstd::futureможно только один раз. -
с помощью
std::futureрезультата может дожидаться только один поток.. Параллельный доступ к одному и тому же общему состоянию может приводить к конфликтам.
Итак, как этим пользоваться?
Шаблон std::promise<T> позволяет устанавливать значение (типа T), которое позже можно прочитать через связанный объект std::future<T>. Ожидающий поток может заблокироваться на фьючерсе, а поток, предоставляющий данные,— воспользоваться другой половиной пары, промисом (promise, иногда называют обещанием), для установки связанного значения и приведения фьючерса в состояние готовности. Получить объект фьючерса std::future, связанный с заданным объектом std::promise, можно вызовом метода get_future(). Когда значение в promise установлено (с помощью метода set_value()), фьючерс приводится в состояние готовности и может использоваться для извлечения сохраненного значения. Если объект std::promise уничтожить без установки значения, вместо него будет сохранено исключение.
В нашем распоряжении есть несколько методов:
-
std::promise::-
get_future()позволяет получить объект std::future, связанный с нашим объектом std::promise -
set_value(value)сохраняет значение, которое можно запросить с помощью связанного объекта std::future -
set_exception(exception)сохраняет исключение, которое будет брошено в потоке, запросившем значение из объекта std::future -
set_value_at_thread_exit()иset_exception_at_thread_exit()сохраняют значение или исключение после завершения потока аналогично тому, как работаетstd::notify_all_at_thread_exit
-
-
std::future::-
get()Дожидается, когда promise сохранит результат, и возвращает его. После вызова метода объект future удаляет ссылку на общее состояние, и метод valid() начинает возвращать false. Вызов для невалидного (valid() возвращает false) объекта приводит к неопределённому поведению или исключению (зависит от реализации). Если в promise было записано исключение, то оно будет брошено при вызове. -
valid()Проверяет, связан ли объект future с каким-то общим состоянием. Вызов других методов для невалидного объекта приводит к неопределённому поведению или исключению (зависит от реализации). -
wait()Блокирует текущий поток, пока promise не запишет значение. Вызов для невалидного (valid() возвращает false) объекта приводит к неопределённому поведению или исключению (зависит от реализации). -
wait_for()иwait_until()Работают аналогично методу wait, но с ограничением на время ожидания. Возвращают future_status. -
share()Конструирует и возвращает shared_future. Несколько объектовstd::shared_futureмогут ссылаться на одно и то же общее состояние, что невозможно для std::future. После вызова метода объект future удаляет ссылку на общее состояние, и метод valid() начинает возвращать false.
-
Пример:
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
#include <chrono>
void accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last,
std::promise<int> accumulate_promise)
{
int sum = std::accumulate(first, last, 0);
accumulate_promise.set_value(sum); // Notify future
}
int main()
{
// Demonstrate using promise<int> to transmit a result between threads.
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
std::promise<int> accumulate_promise;
std::future<int> accumulate_future = accumulate_promise.get_future();
std::thread work_thread(accumulate, numbers.begin(), numbers.end(),
std::move(accumulate_promise));
// future::get() will wait until the future has a valid result and retrieves it.
// Calling wait() before get() is not needed
//accumulate_future.wait(); // wait for result
std::cout << "result=" << accumulate_future.get() << 'n';
work_thread.join(); // wait for thread completion
}
Проброс исключения
Предположим, что вызываемая в отдельном потоке функция может выдавать исключение:
double square_root(double x){
if(x<0) {
throw std::out_of_range("x<0");
}
return sqrt(x);
}
Если в функцию square_root() передается значение –1, она выдает исключение, которое становится видимым вызывающему коду. В идеале при выполнении этой функции в отдельном потоке хотелось бы получить точно такое же поведение, как при однопоточном варианте выполнения: было бы неплохо, чтобы код, вызвавший future::get(), мог видеть исключение.
std::promise предоставляет возможности сохранить исключение. Если вместо значения требуется сохранить исключение, то вместо set_value() вызывается метод set_exception(). Исключение сохраняется во фьючерсе на месте сохраненного значения, фьючерс приводится в состояние готовности и вызов get() бросает сохраненное исключение. (Примечание: в стандарте не указано, является ли повторно выдаваемое исключение исходным объектом исключения или его копией, разные компиляторы и библиотеки делают выбор по своему усмотрению.)
Обычно для исключения, выдаваемого в качестве части алгоритма, это делается в блоке catch:
extern std::promise<double> some_promise;
try{
some_promise.set_value(square_root(x));
}
catch(...){
some_promise.set_exception(std::current_exception());
}some_promise.set_exception(std::make_exception_ptr(std::logic_error("foo ")));Такой код выглядит намного понятнее, чем код с применением блока try-catch, — это не только упрощает код, но и расширяет возможности компилятора в области оптимизации кода.
То же самое происходит, если функция заключена в std::packaged_task: когда при вызове задачи этой функцией выдается исключение, оно сохраняется во фьючерсе на месте результата, готового к выдаче при вызове функции get().
Аналогичное поведение может быть достигнуто с помощью std::async:
std::future<double> f = std::async(square_root, -1);
double y = f.get();Еще один способ сохранения исключения во фьючерсе заключается в уничтожении связанного с фьючерсом объекта std::promise или объекта std::packaged_task без вызова каких-либо set-функций в отношении promise или без обращения к упакованной задаче. В этом случае деструктор std::promise или std::packaged_task сохранит исключение std::future_error с кодом ошибки std::future_errc::broken_promise в связанном состоянии, если фьючерс еще не перешел в состояние готовности: созданием фьючерса дается обещание предоставить значение или исключение, а уничтожением источника этого значения или исключения без их предоставления это обещание нарушается. Если бы компилятор в таком случае ничего не сохранял во фьючерсе, ожидающие потоки могли бы ожидать бесконечно.
Передача событий без состояния
promise-future можно использовать не только для передачи значения, но и просто для уведомления (хотя для этого можно использовать condition variables), если сохранить тип void. Например, можно сделать барьер (в С++20 для этого есть специальные средства).
Пример:
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
#include <chrono>
void do_work(std::promise<void> barrier)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
barrier.set_value();
}
int main()
{
// Demonstrate using promise<void> to signal state between threads.
std::promise<void> barrier;
std::future<void> barrier_future = barrier.get_future();
std::thread new_work_thread(do_work, std::move(barrier));
barrier_future.wait();
new_work_thread.join();
}
Среднеуровневые средства: обёртка для функций и callable объектов std::packaged_task
Использование promise — это не единственный способ возврата значения из функции, выполняемой в другом потоке. Сделать это можно также заключением задачи в экземпляр std::packaged_task<>. Шаблон класса std::packaged_task является абстракцией более высокого уровня, чем std::promise.
Шаблон класса std::packaged_task обёртывает любую вызываемую цель (функцию, лямбда-выражение, bind expression или другой callable объект), чтобы ее можно было вызвать асинхронно с получением возвращаемого значения или исключения. Возвращаемое значение или вызванное исключение хранится в общем состоянии, доступ к которому можно получить через объекты std::future.
std::packaged_task работает так же, как если бы мы создали объект std::promise и сохранили в него результат работы функции.
Шаблон класса std::packaged_task<> привязывает фьючерс к функции или вызываемому объекту. Когда вызывается объект std::packaged_task<>, он вызывает связанную функцию или объект и приводит фьючерс в состояние готовности после возврата функцией значения или броска исключения. Этим классом можно воспользоваться как строительным блоком для пула потоков или других схем управления задачами, например, для запуска всех задач в специально выделенном потоке, работающем в фоновом режиме. Таким образом удается абстрагироваться от подробностей задач — диспетчер имеет дело только с экземплярами std::packaged_task, а не с отдельно взятыми функциями.
Параметром шаблона для std::packaged_task<> является сигнатура функции, например void() для функции, не получающей параметры и не имеющей возвращаемых значений, или int(std::string&,double*) для функции, получающей не-const-ссылку на std::string и указатель на double и возвращающей значение типа int. При создании экземпляра std::packaged_task ему следует передать функцию или вызываемый объект, принимающий указанные параметры, а затем возвращающий тип, который можно преобразовать в указанный тип возвращаемого значения. Точного совпадения типов не требуется, можно сконструировать объект std::packaged_task<double(double)> из функции, принимающей значение типа int и возвращающей значение типа float, поскольку возможно неявное приведение типов. Тип возвращаемого значения, указанный в сигнатуре функции, определяет тип объекта std::future<>, возвращаемого методом get_future(), а заданный в сигнатуре список аргументов используется для определения сигнатуры оператора вызова в классе packaged_task.
Объект std::packaged_task является вызываемым, значит, его можно обернуть объектом std::function или передать конструктору std::thread в качестве функции потока, или даже вызвать напрямую.
Когда std::packaged_task вызывается, аргументы, предоставленные оператору вызова функции, передаются содержащейся в этом объекте функции, а возвращаемое значение сохраняется в качестве результата в объекте std::future, полученном от get_future().Таким образом, задачу можно заключить в объект std::packaged_task и извлечь фьючерс перед передачей объекта std::packaged_task в отдельный поток. Когда понадобится результат, можно будет дождаться готовности фьючерса.
Итак, как это использовать?
В нашем распоряжении несколько методов:
-
get_future()позволяет получить связанный с состоянием задачи объект std::future, с помощью которого можно получить возвращаемое значение функции или брошенное исключение -
operator()позволяет вызвать обёрнутую функцию, нужно передать аргументы функции -
make_ready_at_thread_exit()позволяет дождаться полного завершения потока перед тем, как привести future в состояние готовности -
reset()очищает результаты предыдущего запуска задачи
Пример:
#include <iostream>
#include <cmath>
#include <thread>
#include <future>
#include <functional>
// unique function to avoid disambiguating the std::pow overload set
int f(int x, int y) { return std::pow(x,y); }
void task_lambda()
{
std::packaged_task<int(int,int)> task([](int a, int b) {
return std::pow(a, b);
});
std::future<int> result = task.get_future();
task(2, 9);
std::cout << "task_lambda:t" << result.get() << 'n';
}
void task_bind()
{
std::packaged_task<int()> task(std::bind(f, 2, 11));
std::future<int> result = task.get_future();
task();
std::cout << "task_bind:t" << result.get() << 'n';
}
void task_thread()
{
std::packaged_task<int(int,int)> task(f);
std::future<int> result = task.get_future();
std::thread task_td(std::move(task), 2, 10);
task_td.join();
std::cout << "task_thread:t" << result.get() << 'n';
}
int main()
{
task_lambda();
task_bind();
task_thread();
}
Пример с ожиданием полного завершения потока:
#include <future>
#include <iostream>
#include <chrono>
#include <thread>
#include <functional>
#include <utility>
void worker(std::future<void>& output)
{
std::packaged_task<void(bool&)> my_task{ [](bool& done) { done=true; } };
auto result = my_task.get_future();
bool done = false;
my_task.make_ready_at_thread_exit(done); // execute task right away
std::cout << "worker: done = " << std::boolalpha << done << std::endl;
auto status = result.wait_for(std::chrono::seconds(0));
if (status == std::future_status::timeout)
std::cout << "worker: result is not ready yet" << std::endl;
output = std::move(result);
}
int main()
{
std::future<void> result;
std::thread{worker, std::ref(result)}.join();
auto status = result.wait_for(std::chrono::seconds(0));
if (status == std::future_status::ready)
std::cout << "main: result is ready" << std::endl;
}
Пример со сбросом результатов предыдущего выполнения:
#include <iostream>
#include <cmath>
#include <thread>
#include <future>
int main()
{
std::packaged_task<int(int,int)> task([](int a, int b) {
return std::pow(a, b);
});
std::future<int> result = task.get_future();
task(2, 9);
std::cout << "2^9 = " << result.get() << 'n';
task.reset();
result = task.get_future();
std::thread task_td(std::move(task), 2, 10);
task_td.join();
std::cout << "2^10 = " << result.get() << 'n';
}Высокоуровневые средства: запуск задач асинхронно с помощью std::async
Всё, что было описано выше — это хорошо, но может казаться слишком сложным для того, чтобы просто запустить задачу в отдельном потоке и получить значение. Иногда хочется иметь ещё более высокоуровневые инструменты и запускать задачи в одну строчку кода. Стандартная библиотека C++ предоставляет такую возможность.
std::async запускает функцию f асинхронно (потенциально в отдельном потоке, который может быть частью пула потоков) и возвращает std::future, который в конечном итоге будет содержать результат вызова этой функции.
std::async позволяет установить политику запуска задачи:
-
std::launch::asyncвыполняет вызываемый объект f в новом потоке выполнения, как если бы он был запущен с помощьюstd::thread(std::forward<F>(f), std::forward<Args>(args)...), за исключением того, что если функция f возвращает значение или создает исключение, то оно хранится в общем состоянии, доступном через std::future, которое async возвращает вызывающей стороне. -
std::launch::deferredне порождает новый поток выполнения. Вместо этого функция выполняется лениво: первый вызов несинхронной функции ожидания в std::future, возвращенном вызывающему объекту, вызовет копию f (как rvalue) с копиями args… (также передается как rvalues) в текущем потоке (который не обязательно должен быть потоком, который изначально вызывал std::async). Результат или исключение помещается в общее состояние, объект future приводится в состояние готовности. Дальнейший запрос результата из того же std::future немедленно вернёт результат. -
std::launch::async|std::launch::deferredв зависимости от реализации, производится или асинхронное выполнение, или ленивое -
Если ни
std::launch::async, ниstd::launch::deferredне установлен, то задаётся политика по умолчаниюstd::launch::async|std::launch::deferred
std::async возвращает объект std::future для получения значения.
std::async бросает исключение std::system_error, если политика запуска равна std::launch::async, но реализация не может запустить новый поток, или std::bad_alloc, если память для внутренних структур данных не может быть выделена.
Если std::future, полученный из std::async, не сохраняется, деструктор std::future блокирует поток до завершения асинхронной операции, как при синхронном выполнении:
std::async(std::launch::async, []{ f(); }); // temporary's dtor waits for f()
std::async(std::launch::async, []{ g(); }); // does not start until f() completesОбратите внимание, что деструкторы объектов std::future, полученных не из std::async, не блокируют поток.
Пример:
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <future>
#include <string>
#include <mutex>
std::mutex m;
struct X {
void foo(int i, const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << ' ' << i << 'n';
}
void bar(const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << 'n';
}
int operator()(int i) {
std::lock_guard<std::mutex> lk(m);
std::cout << i << 'n';
return i + 10;
}
};
template <typename RandomIt>
int parallel_sum(RandomIt beg, RandomIt end)
{
auto len = end - beg;
if (len < 1000)
return std::accumulate(beg, end, 0);
RandomIt mid = beg + len/2;
auto handle = std::async(std::launch::async,
parallel_sum<RandomIt>, mid, end);
int sum = parallel_sum(beg, mid);
return sum + handle.get();
}
int main()
{
std::vector<int> v(10000, 1);
std::cout << "The sum is " << parallel_sum(v.begin(), v.end()) << 'n';
X x;
// Calls (&x)->foo(42, "Hello") with default policy:
// may print "Hello 42" concurrently or defer execution
auto a1 = std::async(&X::foo, &x, 42, "Hello");
// Calls x.bar("world!") with deferred policy
// prints "world!" when a2.get() or a2.wait() is called
auto a2 = std::async(std::launch::deferred, &X::bar, x, "world!");
// Calls X()(43); with async policy
// prints "43" concurrently
auto a3 = std::async(std::launch::async, X(), 43);
a2.wait(); // prints "world!"
std::cout << a3.get() << 'n'; // prints "53"
} // if a1 is not done at this point, destructor of a1 prints "Hello 42" here
/*
Возможный вывод:
The sum is 10000
43
world!
53
Hello 42
*/
Ожидание результата в нескольких потоках с помощью std::shared_future
До сих пор во всех примерах использовался объект std::future. Но у него есть ограничения, в частности, результата может дожидаться только один поток. Если наступления одного и того же события нужно дожидаться сразу из нескольких потоков, следует воспользоваться std::shared_future.
Хотя std::future вполне справляется со всей синхронизацией, необходимой для переноса данных из одного потока в другой, вызовы методов std::future не синхронизированы друг с другом. Если обращаться к одному и тому же объекту std::future из нескольких потоков без дополнительной синхронизации, возникнет состояние гонки за данными и неопределенное поведение. std::future моделирует исключительное владение результатом асинхронных вычислений, а одноразовая природа функции get() лишает конкурентный доступ всякого смысла — значение можно извлечь только одним потоком, поскольку после первого же вызова get() значения для извлечения уже не останется.
Если же ваш проект требует, чтобы ожидать результата выполнения функции могли сразу несколько потоков, нужно использовать std::shared_future. Если std::future допускает только перемещение (чтобы право владения передавалось между экземплярами, но чтобы в конкретный момент только один экземпляр ссылался на конкретный результат асинхронного вычисления), экземпляры std::shared_future допускают копирование, поэтому могут существовать сразу несколько объектов, ссылающихся на одно и то же связанное состояние.
Однако работа с одним и тем же объектом std::shared_future из разных потоков по прежнему не синхронизирована, и во избежание проблем, следует передать каждому заинтересованному потоку собственную копию объекта std::shared_future, тогда все внутренние операции будут корректно синхронизированы средствами библиотеки. Таким образом, безопасность доступа к асинхронному состоянию из нескольких потоков обеспечивается, если каждый поток обращается к этому состоянию посредством собственного объекта std::shared_future.
Сконструировать объект std::shared_future можно либо передав право собственности его конструктору из std::future с помощью std::move:
std::shared_future sf(std::move(future));Для r-value вызов std::move не требуется:
std::promise<int> p;
std::shared_future<int> sf(p.get_future());std::promise<int> p;
auto sf = p.get_future().share();Пример использования std::shared_future для реализации барьера:
#include <iostream>
#include <future>
#include <chrono>
int main()
{
std::promise<void> ready_promise, t1_ready_promise, t2_ready_promise;
std::shared_future<void> ready_future(ready_promise.get_future());
std::chrono::time_point<std::chrono::high_resolution_clock> start;
auto fun1 = [&, ready_future]() -> std::chrono::duration<double, std::milli>
{
t1_ready_promise.set_value();
ready_future.wait(); // waits for the signal from main()
return std::chrono::high_resolution_clock::now() - start;
};
auto fun2 = [&, ready_future]() -> std::chrono::duration<double, std::milli>
{
t2_ready_promise.set_value();
ready_future.wait(); // waits for the signal from main()
return std::chrono::high_resolution_clock::now() - start;
};
auto fut1 = t1_ready_promise.get_future();
auto fut2 = t2_ready_promise.get_future();
auto result1 = std::async(std::launch::async, fun1);
auto result2 = std::async(std::launch::async, fun2);
// wait for the threads to become ready
fut1.wait();
fut2.wait();
// the threads are ready, start the clock
start = std::chrono::high_resolution_clock::now();
// signal the threads to go
ready_promise.set_value();
std::cout << "Thread 1 received the signal "
<< result1.get().count() << " ms after startn"
<< "Thread 2 received the signal "
<< result2.get().count() << " ms after startn";
}
/*
Возможный вывод:
Thread 1 received the signal 0.072 ms after start
Thread 2 received the signal 0.041 ms after start
*/Что почитать?
Thread support library
Энтони Уильямс. C++. Практика многопоточного программирования
The Little Book of Semaphores
20 типичных ошибок многопоточности в C++
Добро пожаловать в параллельный мир. Часть 1: Мир многопоточный
Потоки, блокировки и условные переменные в C++11 [Часть 1]
Потоки, блокировки и условные переменные в C++11 [Часть 2]
Различные заметки по изучению устройства операционных систем
Процессы и потоки
Операционные системы. Процессы и потоки.
Процессы и потоки in-depth. Обзор различных потоковых моделей
В чем разница между потоком и процессом?
Лекция — Процессы и потоки (нити)
Процесс
Поток выполнения
Многозадачность
Многопоточность
Разница понятий
Пользовательский режим (user mode) и режим ядра (kernel mode)
Сравнение режима ядра и пользовательского режима
What is the difference between user and kernel modes in operating systems?
Планирование потоков
Многопоточность в Java: суть, «плюсы» и частые ловушки
Race condition Состояние гонки
Взаимная блокировка
C++ Deadlocks
C++11/C++14 9. Deadlocks — 2020
Узнать подробнее о курсе «C++ Developer. Professional«.
Аннотация: В этой лекции завершается описание ключевых особенностей Java. Последняя тема раскрывает особенности создания многопоточных приложений — такая возможность присутствует в языке, начиная с самых первых версий.
Первый вопрос — как на много- и, самое интересное, однопроцессорных
машинах выполняется несколько потоков одновременно и для чего они
нужны в программе. Затем описываются классы, необходимые для создания,
запуска и управления потоками в Java. При одновременной работе с
данными из нескольких мест возникает проблема синхронного доступа,
блокировок и, как следствие, взаимных блокировок. Изучаются все
механизмы, предусмотренные в языке для корректной организации такой логики работы.
Введение
До сих пор во всех рассматриваемых примерах подразумевалось, что в один момент времени исполняется лишь одно выражение или действие. Однако начиная с самых первых версий, виртуальные машины Java поддерживают многопоточность, т.е. поддержку нескольких потоков исполнения ( threads ) одновременно.
В данной лекции сначала рассматриваются преимущества такого подхода, способы реализации и возможные недостатки.
Затем описываются базовые классы Java, которые позволяют запускать потоки исполнения и управлять ими. При одновременном обращении нескольких потоков к одним и тем же данным может возникнуть ситуация, когда результат программы будет зависеть от случайных факторов, таких как временное чередование исполнения операций несколькими потоками. В такой ситуации становятся необходимыми механизмы синхронизации, обеспечивающие последовательный, или монопольный, доступ. В Java этой цели служит ключевое слово synchronized. Предварительно будет рассмотрен подход к организации хранения данных в виртуальной машине.
В заключение рассматриваются методы wait(), notify(), notifyAll() класса Object.
Многопоточная архитектура
Не претендуя на полноту изложения, рассмотрим общее устройство многопоточной архитектуры, ее достоинства и недостатки.
Реализацию многопоточной архитектуры проще всего представить себе для системы, в которой есть несколько центральных вычислительных процессоров. В этом случае для каждого из них можно выделить задачу, которую он будет выполнять. В результате несколько задач будут обслуживаться одновременно.
Однако возникает вопрос – каким же тогда образом обеспечивается многопоточность в системах с одним центральным процессором, который, в принципе, выполняет лишь одно вычисление в один момент времени? В таких системах применяется процедура квантования времени ( time-slicing ). Время разделяется на небольшие интервалы. Перед началом каждого интервала принимается решение, какой именно поток выполнения будет отрабатываться на протяжении этого кванта времени. За счет частого переключения между задачами эмулируется многопоточная архитектура.
На самом деле, как правило, и для многопроцессорных систем применяется процедура квантования времени. Дело в том, что даже в мощных серверах приложений процессоров не так много (редко бывает больше десяти), а потоков исполнения запускается, как правило, гораздо больше. Например, операционная система Windows без единого запущенного приложения инициализирует десятки, а то и сотни потоков. Квантование времени позволяет упростить управление выполнением задач на всех процессорах.
Теперь перейдем к вопросу о преимуществах – зачем вообще может потребоваться более одного потока выполнения?
Среди начинающих программистов бытует мнение, что многопоточные программы работают быстрее. Рассмотрев способ реализации многопоточности, можно утверждать, что такие программы работают на самом деле медленнее. Действительно, для переключения между задачами на каждом интервале требуется дополнительное время, а ведь они (переключения) происходят довольно часто. Если бы процессор, не отвлекаясь, выполнял задачи последовательно, одну за другой, он завершил бы их заметно быстрее. Стало быть, преимущества заключаются не в этом.
Первый тип приложений, который выигрывает от поддержки многопоточности, предназначен для задач, где действительно требуется выполнять несколько действий одновременно. Например, будет вполне обоснованно ожидать, что сервер общего пользования станет обслуживать несколько клиентов одновременно. Можно легко представить себе пример из сферы обслуживания, когда имеется несколько потоков клиентов и желательно обслуживать их все одновременно.
Другой пример – активные игры, или подобные приложения. Необходимо одновременно опрашивать клавиатуру и другие устройства ввода, чтобы реагировать на действия пользователя. В то же время необходимо рассчитывать и перерисовывать изменяющееся состояние игрового поля.
Понятно, что в случае отсутствия поддержки многопоточности для реализации подобных приложений потребовалось бы реализовывать квантование времени вручную. Условно говоря, одну секунду проверять состояние клавиатуры, а следующую – пересчитывать и перерисовывать игровое поле. Если сравнить две реализации time-slicing, одну – на низком уровне, выполненную средствами, как правило, операционной системы, другую – выполняемую вручную, на языке высокого уровня, мало подходящего для таких задач, то становится понятным первое и, возможно, главное преимущество многопоточности. Она обеспечивает наиболее эффективную реализацию процедуры квантования времени, существенно облегчая и укорачивая процесс разработки приложения. Код переключения между задачами на Java выглядел бы куда более громоздко, чем независимое описание действий для каждого потока.
Следующее преимущество проистекает из того, что компьютер состоит не только из одного или нескольких процессоров. Вычислительное устройство – лишь один из ресурсов, необходимых для выполнения задач. Всегда есть оперативная память, дисковая подсистема, сетевые подключения, периферия и т.д. Предположим, пользователю требуется распечатать большой документ и скачать большой файл из сети. Очевидно, что обе задачи требуют совсем незначительного участия процессора, а основные необходимые ресурсы, которые будут задействованы на пределе возможностей, у них разные – сетевое подключение и принтер. Значит, если выполнять задачи одновременно, то замедление от организации квантования времени будет незначительным, процессор легко справится с обслуживанием обеих задач. В то же время, если каждая задача по отдельности занимала, скажем, два часа, то вполне вероятно, что и при одновременном исполнении потребуется не более тех же двух часов, а сделано при этом будет гораздо больше.
Если же задачи в основном загружают процессор (например, математические расчеты), то их одновременное исполнение займет в лучшем случае столько же времени, что и последовательное, а то и больше.
Третье преимущество появляется из-за возможности более гибко управлять выполнением задач. Предположим, пользователь системы, не поддерживающей многопоточность, решил скачать большой файл из сети, или произвести сложное вычисление, что занимает, скажем, два часа. Запустив задачу на выполнение, он может внезапно обнаружить, что ему нужен не этот, а какой-нибудь другой файл (или вычисление с другими начальными параметрами). Однако если приложение занимается только работой с сетью (вычислениями) и не реагирует на действия пользователя (не обрабатываются данные с устройств ввода, таких как клавиатура или мышь), то он не сможет быстро исправить ошибку. Получается, что процессор выполняет большее количество вычислений, но при этом приносит гораздо меньше пользы.
Процедура квантования времени поддерживает приоритеты (priority) задач. В Java приоритет представляется целым числом. Чем больше число, тем выше приоритет. Строгих правил работы с приоритетами нет, каждая реализация может вести себя по-разному на разных платформах. Однако есть общее правило – поток с более высоким приоритетом будет получать большее количество квантов времени на исполнение и таким образом сможет быстрее выполнять свои действия и реагировать на поступающие данные.
В описанном примере представляется разумным запустить дополнительный поток, отвечающий за взаимодействие с пользователем. Ему можно поставить высокий приоритет, так как в случае бездействия пользователя этот поток практически не будет занимать ресурсы машины. В случае же активности пользователя необходимо как можно быстрее произвести необходимые действия, чтобы обеспечить максимальную эффективность работы пользователя.
Рассмотрим здесь же еще одно свойство потоков. Раньше, когда рассматривались однопоточные приложения, завершение вычислений однозначно приводило к завершению выполнения программы. Теперь же приложение должно работать до тех пор, пока есть хоть один действующий поток исполнения. В то же время часто бывают нужны обслуживающие потоки, которые не имеют никакого смысла, если они остаются в системе одни. Например, автоматический сборщик мусора в Java запускается в виде фонового (низкоприоритетного) процесса. Его задача – отслеживать объекты, которые уже не используются другими потоками, и затем уничтожать их, освобождая оперативную память. Понятно, что работа одного потока garbage collector ‘а не имеет никакого смысла.
Такие обслуживающие потоки называют демонами ( daemon ), это свойство можно установить любому потоку. В итоге приложение выполняется до тех пор, пока есть хотя бы один поток не- демон.
Рассмотрим, как потоки реализованы в Java.
уважаемые посетители блога, если Вам понравилась, то, пожалуйста, помогите автору с лечением. Подробности тут.
Часто различные потоки в приложении используют разделяемые (общие для всех) ресурсы. Например, несколько потоков могут использовать один и тот же файл для записи лога или несколько потоков используют список List для чтения/записи элементов и так далее. Как только два и более потоков обращаются к одному и тому же ресурсу приложения, у них возникает конкуренция и предугадать в какой последовательности сработают потоки — не возможно. Итог работы будет зависеть от самой операционной системы и того, как система будет выделять ресурсы потокам. Даже вызов метода Start и Thread не дает гарантии того, что поток моментально запустится до следующей за Start строки кода.
Пример работы нескольких потоков
Рассмотрим следующий пример:
internal class Program
{
static int x;
static void Main(string[] args)
{
for (int i = 1; i < 6; i++)
{
Thread thread = new Thread(new ThreadStart(Func));
thread.Name = i.ToString();
thread.Start();
}
}
public static void Func()
{
x = 0;
for (int i = 0; i < 10; i++)
{
x++;
Console.WriteLine($"Поток {Thread.CurrentThread.Name} вывел число {x}");
Thread.Sleep(100);
}
}
}
В этом примере в методе Main создаются пять потоков, каждый из которых получает собственное имя и, затем, выполняет метод Func в котором обращается к общей для всех потоков переменной x, увеличивая её значение на 1. По сути, мы ожидаем того, что каждый поток от 1 до 5 выведет в консоль значение x от 1 до 10. По факту же — мы не можем угадать в какой последовательности будут выводиться значения x, так как очередность выполнения функции потоками определяет за нас операционная система. Чтобы наши потоки работали так как мы того ожидаем, мы может синхронизировать их работу.
Оператор lock
Оператор lock имеет следующий синтаксис:
lock (x)
{
// Your code...
}
Основная идея использования оператора lock заключается в том, что блок кода заключенный в этот оператор в один момент времени может выполняться только одним потоком (т.н. идея критической секции). Остальные потоки будут ожидать пока текущий поток не выполнит код и блокировка не будет снята. При этом, в качестве x у оператора lock может выступать только объект ссылочного типа.
Попробуем переписать наш пример следующим образом:
internal class Program
{
static int x = 0;
static object locker = new object();
static void Main(string[] args)
{
for (int i = 1; i < 6; i++)
{
Thread thread = new Thread(new ThreadStart(Func));
thread.Name = i.ToString();
thread.Start();
}
}
public static void Func()
{
lock (locker)
{
x = 0;
for (int i = 0; i < 10; i++)
{
x++;
Console.WriteLine($"Поток {Thread.CurrentThread.Name} вывел число {x}");
Thread.Sleep(100);
}
}
}
}
}
Теперь, если запустить приложение, то мы увидим, что каждый поток последовательно выводит значения x от 1 до 10. Здесь следует отметить следующий момент:
Несмотря на то, что в качестве объекта-заглушки у оператора lock может выступать любой объект ссылочного типа, НЕ СТОИТ использовать в операторе ключевое слово this.
То есть, в нашем случае, вот такая конструкция lock сработала бы без проблем (при условии, что мы работаем с не статическими методами):
lock (this)
{
<--тут выполнение кода-->
}
но таким же образом (с использованием this) могут одновременно происходить блокировки и в других частях программы, что может привести к взаимному блокированию нескольких потоков и программа «зависнет». Поэтому лучше потратить несколько секунд времени и одну строку кода и определить для оператора lock свой объект-заглушку.
Смысл использования критических секций
В целом, идея использования lock показана в примере выше — мы запрещаем всем прочим потокам работать с общим ресурсом до тех пор, пока текущий поток не выйдет из критической секции. В связи с этим, может возникнуть резонный вопрос — какой смысл использовать критические секции, если они тормозят работу всех потоков? Если одна задача выполняется 1 секунду, то 10 таких задач в 10 потоках тоже будут выполняться тоже за 1 секунду, а, используя lock мы, фактически, возвращаемся к однопоточной схеме и ждем выполнение всех потоков 10 секунд. На первый взгляд, может показаться именно так, но не все так просто.
Во-первых, использование lock (критических секций) дает нам гарантию того, что состояние общего ресурса не будет нарушено и потоки отработают так, как мы того от них ожидаем. Например, один поток пишет в список имена файлов из директории, а второй — выводит этот список на экран. Если потоки не синхронизировать, то может случится ситуация, когда второй поток выведет не полный список файлов, т.е. выдаст недостоверную информацию, в то время, как первый поток будет продолжать работать, но уже вхолостую (второй-то уже всю свою работы выполнил — список на экран вывел).
Во-вторых, мы можем «завернуть» в lock не весь код метода, а только его критическую часть, т.е. ту, в которой используется разделяемый ресурс. В этом случае, потери времени, связанные с синхронизацией будут меньше и те же 10 однотипных задач могут выполняться не 10, а, скажем, 5 и 3 секунды. Например, каждый поток скачивает из сети файлы различного объема и увеличивает счётчик полученных файлов на 1 при каждой удачной загрузке и выводит имя файла на экран. Загрузку файла из сети можно не блокировать — у каждого потока свой файл, а вот наращивание счётчика на 1 и вывод на экран можно «завернуть» в lock.
Итого
Сегодня мы познакомились с тем, как можно организовать синхронизацию нескольких потоков в приложении с использованием оператора lock. На этом тема синхронизации потоков не завершается и в следующих разделах мы рассмотрим другие способы синхронизации.
уважаемые посетители блога, если Вам понравилась, то, пожалуйста, помогите автору с лечением. Подробности тут.
Функции синхронизации
Функции, ожидающие единственный объект
Функции, ожидающие несколько объектов
Прерывание ожидания по запросу на завершение операции ввода-вывода
или APC
Объекты синхронизации
Event (событие)
Mutex (Mutually Exclusive)
Semaphore (семафор)
Waitable timer (таймер ожидания)
Дополнительные объекты синхронизации
Сообщение об изменении
папки (change notification)
Устройство стандартного
ввода с консоли (console input)
Задание (Job)
Процесс (Process)
Поток (thread)
Дополнительные механизмы синхронизации
Критические секции
Защищенный доступ к переменным (Interlocked Variable Access)
Резюме
При
одновременном доступе нескольких
процессов (или нескольких потоков одного
процесса) к какому-либо ресурсу возникает
проблема синхронизации. Поскольку поток в Win32
может быть остановлен в любой, заранее ему
неизвестный момент времени, возможна
ситуация, когда один из потоков не успел
завершить модификацию ресурса (например,
отображенной на файл области памяти), но был
остановлен, а другой поток попытался
обратиться к тому же ресурсу. В этот момент
ресурс находится в несогласованном
состоянии, и последствия обращения к нему
могут быть самыми неожиданными — от порчи
данных до нарушения защиты памяти.
Главной идеей, заложенной в основе
синхронизации потоков в Win32,
является использование объектов
синхронизации и функций ожидания. Объекты
могут находиться в одном из двух состояний —
Signaled
или Not
Signaled. Функции
ожидания блокируют выполнение потока до
тех пор, пока заданный объект находится в
состоянии Not Signaled. Таким
образом, поток, которому необходим
эксклюзивный доступ к ресурсу, должен
выставить какой-либо объект синхронизации
в несигнальное состояние, а по окончании —
сбросить его в сигнальное. Остальные
потоки должны перед доступом к этому
ресурсу вызвать функцию ожидания, которая
позволит им дождаться освобождения ресурса.
Рассмотрим,
какие объекты и функции синхронизации
предоставляет нам Win32 API.
Функции синхронизации
Функции синхронизации делятся на две
основные категории: функции, ожидающие
единственный объект, и функции, ожидающие
один из нескольких объектов.
Функции, ожидающие единственный объект
Простейшей функцией ожидания является
функция WaitForSingleObject:
function WaitForSingleObject( hHandle: THandle; // идентификатор объекта dwMilliseconds: DWORD // период ожидания ): DWORD; stdcall;
Функция ожидает перехода объекта hHandle в сигнальное состояние в течение dwMilliseconds
миллисекунд. Если в качестве параметра dwMilliseconds передать значение INFINITE,
функция будет ждать в течение неограниченного времени. Если dwMilliseconds равен
0, то функция проверяет состояние объекта и немедленно возвращает управление.
Функция
возвращает одно из следующих значений:
WAIT_ABANDONED |
Поток, владевший объектом, завершился, не переведя объект в сигнальное состояние |
WAIT_OBJECT_0 |
Объект перешел в сигнальное состояние |
WAIT_TIMEOUT |
Истек срок ожидания. Обычно в этом случае генерируется ошибка либо функция вызывается в цикле до получения другого результата |
WAIT_FAILED |
Произошла ошибка (например, получено неверное значение hHandle). Более подробную информацию можно получить, вызвав GetLastError |
Следующий фрагмент кода запрещает доступ
к Action1
до перехода объекта ObjectHandle
в сигнальное состояние (например, таким
образом можно дожидаться завершения
процесса, передав в качестве ObjectHandle
его идентификатор, полученный функцией CreateProcess):
var Reason: DWORD; ErrorCode: DWORD; Action1.Enabled := FALSE; try repeat Application.ProcessMessages; Reason := WailForSingleObject(ObjectHandle, 10); if Reason = WAIT_FAILED then begin ErrorCode := GetLastError; raise Exception.CreateFmt( ‘Wait for object failed with error: %d’, [ErrorCode]); end; until Reason <> WAIT_TIMEOUT; finally Actionl.Enabled := TRUE; end;
В случае когда одновременно с ожиданием объекта требуется перевести в сигнальное
состояние другой объект, может использоваться функция SignalObjectAndWait:
function SignalObjectAndWait( hObjectToSignal: THandle; // объект, который будет переведен в // сигнальное состояние hObjectToWaitOn: THandle; // объект, который ожидает функция dwMilliseconds: DWORD; // период ожидания bAlertable: BOOL // задает, должна ли функция возвращать // управление в случае запроса на // завершение операции ввода-вывода ): DWORD; stdcall;
Возвращаемые значения аналогичны функции WaitForSingleObject.
! В модуле Windows.pas эта функция ошибочно объявлена как возвращающая
значение BOOL. Если вы намерены ее использовать – объявите ее корректно
или используйте приведение типа возвращаемого значения к DWORD.
Объект hObjectToSignal может быть семафором, событием (event) либо мьютексом.
Параметр bAlertable определяет, будет ли прерываться ожидание объекта в случае,
если операционная система запросит у потока окончание операции асинхронного
ввода-вывода либо асинхронный вызов процедуры. Более подробно это будет рассматриваться
ниже.
Функции, ожидающие несколько объектов
Иногда требуется задержать выполнение
потока до срабатывания одного или сразу
всех из группы объектов. Для решения
подобной задачи используются следующие
функции:
type TWOHandleArray = array[0..MAXIMUM_WAIT_OBJECTS - 1] of THandle; PWOHandleArray = ^TWOHandleArray; function WaitForMultipleObjects( nCount: DWORD; // Задает количество объектов lpHandles: PWOHandleArray; // Адрес массива объектов bWaitAll: BOOL; // Задает, требуется ли ожидание всех // объектов или любого dwMilliseconds: DWORD // Период ожидания ): DWORD; stdcall;
Функция возвращает одно из следующих значений:
|
Число в диапазоне от WAIT_OBJECT_0 до
WAIT_OBJECT_0 + nCount – 1
|
Если bWaitAll равно TRUE, то это число означает, что все объекты перешли в сигнальное состояние. Если FALSE — то, вычтя из возвращенного значения WAIT_OBJECT_0, мы получим индекс объекта в массиве lpHandles |
|
Число в диапазоне от WAIT_ABANDONED_0 до
WAIT_ABANDONED_0 + nCount – 1
|
Если bWaitAll равно TRUE, это означает, что все объекты перешли в сигнальное состояние, но хотя бы один из владевших ими потоков завершился, не сделав объект сигнальным Если FALSE — то, вычтя из возвращенного значения WAIT_ABANDONED_0, мы получим в массиве lpHandles индекс объекта, при этом поток, владевший этим объектом, завершился, не сделав его сигнальным |
WAIT_TIMEOUT |
Истек период ожидания |
WAIT_FAILED |
Произошла ошибка |
Например, в следующем фрагменте кода
программа пытается модифицировать два
различных ресурса, разделяемых между
потоками:
var Handles: array[0..1] of THandle; Reason: DWORD; RestIndex: Integer; ... Handles[0] := OpenMutex(SYNCHRONIZE, FALSE, ‘FirstResource’); Handles[1] := OpenMutex(SYNCHRONIZE, FALSE, ‘SecondResource’); // Ждем первый из объектов Reason := WaitForMultipleObjects(2, @Handles, FALSE, INFINITE); case Reason of WAIT_FAILED: RaiseLastWin32Error; WAIT_OBJECT_0, WAIT_ABANDONED_0: begin ModifyFirstResource; RestIndex := 1; end; WAIT_OBJECT_0 + 1, WAIT_ABANDONED_0 + 1: begin ModifySecondResource; RestIndex := 0; end; // WAIT_TIMEOUT возникнуть не может end; // Теперь ожидаем освобождения следующего объекта if WailForSingleObject(Handles[RestIndex], INFINITE) = WAIT_FAILED then RaiseLastWin32Error; // Дождались, модифицируем оставшийся ресурс if RestIndex = 0 then ModifyFirstResource else ModifySecondResource;
Описанную выше технику можно применять,
если вы точно знаете, что задержка ожидания
объекта будет незначительной. В противном
случае ваша программа окажется «замороженной»
и не сможет даже перерисовать свое окно. Если
период задержки может оказаться
значительным, то необходимо дать программе
возможность реагировать на сообщения Windows. Выходом
может стать использование функций с
ограниченным периодом ожидания (и
повторный вызов — в случае возврата WAIT_TIMEOUT)
либо функции MsgWaitForMultipleObjects:
function MsgWaitForMultipleObjects( nCount: DWORD; // количество объектов синхронизации var pHandles; // адрес массива объектов fWaitAll: BOOL; // Задает, требуется ли ожидание всех // объектов или любого dwMilliseconds, // Период ожидания dwWakeMask: DWORD // Тип события, прерывающего ожидание ): DWORD; stdcall;
Главное отличие этой функции от
предыдущей — параметр dwWakeMask,
который является комбинацией битовых
флагов QS_XXX
и задает типы сообщений, прерывающих
ожидание функции независимо от состояния
ожидаемых объектов. Например, маска QS_KEY
позволяет прервать ожидание при появлении
в очереди сообщений WM_KEYUP,
WM_KEYDOWN,
WM_SYSKEYUP
или WM_SYSKEYDOWN,
а маска QS_PAINT
— сообщения WM_PAINT.
Полный список значений, допустимых для dwWakeMask,
имеется в документации по Windows
SDK. При
появлении в очереди потока, вызвавшего
функцию, сообщений, соответствующих
заданной маске, функция возвращает
значение WAIT_OBJECT_0
+ nCount.
Получив это значение, ваша программа может
обработать его и снова вызвать функцию
ожидания. Рассмотрим пример с запуском
внешнего приложения (необходимо, чтобы на время его работы
вызывающая программа не реагировала на
ввод пользователя, однако ее окно должно
продолжать перерисовываться):
procedure TForm1.Button1Click(Sender: TObject); var PI: TProcessInformation; SI: TStartupInfo; Reason: DWORD; Msg: TMsg; begin // Инициализируем структуру TStartupInfo FillChar(SI, SizeOf(SI), 0); SI.cb := SizeOf(SI); // Запускаем внешнюю программу Win32Check(CreateProcess(NIL, 'COMMAND.COM', NIL, NIL, FALSE, 0, NIL, NIL, SI, PI)); //************************************************** // Попробуйте заменить нижеприведенный код на строку // WaitForSingleObject(PI.hProcess, INFINITE); // и посмотреть, как будет реагировать программа на // перемещение других окон над ее окном //************************************************** repeat // Ожидаем завершения дочернего процесса или сообщения // перерисовки WM_PAINT Reason := MsgWaitForMultipleObjects(1, PI.hProcess, FALSE, INFINITE, QS_PAINT); if Reason = WAIT_OBJECT_0 + 1 then begin // В очереди сообщений появился WM_PAINT – Windows // требует обновить окно программы. // Удаляем сообщение из очереди PeekMessage(Msg, 0, WM_PAINT, WM_PAINT, PM_REMOVE); // И перерисовываем наше окно Update; end; // Повторяем цикл, пока не завершится дочерний процесс until Reason = WAIT_OBJECT_0; // Удаляем из очереди накопившиеся там сообщения while PeekMessage(Msg, 0, 0, 0, PM_REMOVE) do; CloseHandle(PI.hProcess); CloseHandle(PI.hThread) end;
Если в потоке, вызывающем функции
ожидания, явно (функцией CreateWindow)
или неявно (используя TForm, DDE, COM)
создаются окна Windows
— поток должен
обрабатывать сообщения. Поскольку
широковещательные сообщения посылаются
всем окнам в системе, то поток, не
обрабатывающий сообщения, может вызвать
взаимоблокировку (система ждет, когда поток
обработает сообщение, поток — когда
система или другие потоки освободят объект)
и привести к зависанию Windows.
Если в вашей программе имеются подобные
фрагменты, необходимо использовать MsgWaitForMultipleObjects
или MsgWaitForMultipleObjectsEx
и позволять прервать ожидание для
обработки сообщений. Алгоритм
аналогичен вышеприведенному примеру.
Прерывание ожидания по запросу на завершение операции ввода-вывода
или APC
Windows
поддерживает асинхронные вызовы процедур.
При создании каждого потока (thread) с ним
ассоциируется очередь асинхронных вызовов
процедур (APC queue). Операционная
система (или приложение пользователя — при
помощи функции QueueUserAPC)
может помещать в нее запросы на выполнение
функций в контексте данного потока. Эти
функции не могут быть выполнены немедленно,
поскольку поток может быть занят. Поэтому
операционная система вызывает их, когда
поток вызывает одну из следующих функций
ожидания:
function SleepEx( dwMilliseconds: DWORD; // Период ожидания bAlertable: BOOL // задает, должна ли функция возвращать // управление в случае запроса на // асинхронный вызов процедуры ): DWORD; stdcall;
function WaitForSingleObjectEx( hHandle: THandle; // Идентификатор объекта dwMilliseconds: DWORD; // Период ожидания bAlertable: BOOL // задает, должна ли функция возвращать // управление в случае запроса на // асинхронный вызов процедуры ): DWORD; stdcall;
function WaitForMultipleObjectsEx( nCount: DWORD; // количество объектов lpHandles: PWOHandleArray;// адрес массива идентификаторов объектов bWaitAll: BOOL; // Задает, требуется ли ожидание всех // объектов или любого dwMilliseconds: DWORD; // Период ожидания bAlertable: BOOL // задает, должна ли функция возвращать // управление в случае запроса на // асинхронный вызов процедуры ): DWORD; stdcall;
function SignalObjectAndWait( hObjectToSignal: THandle; // объект, который будет переведен в // сигнальное состояние hObjectToWaitOn: THandle; // объект, которого ожидает функция dwMilliseconds: DWORD; // период ожидания bAlertable: BOOL // задает, должна ли функция возвращать // управление в случае запроса на // асинхронный вызов процедуры ): DWORD; stdcall;
function MsgWaitForMultipleObjectsEx( nCount: DWORD; // количество объектов синхронизации var pHandles; // адрес массива объектов fWaitAll: BOOL; // Задает, требуется ли ожидание всех // объектов или любого dwMilliseconds, // Период ожидания dwWakeMask: DWORD // Тип события, прерывающего ожидание dwFlags: DWORD // Дополнительные флаги ): DWORD; stdcall;
Если параметр bAlertable
равен TRUE
(либо если dwFlags
в функции MsgWaitForMultipleObjectsEx
содержит MWMO_ALERTABLE),
то при появлении в очереди APC
запроса на
асинхронный вызов процедуры операционная
система выполняет вызовы всех имеющихся в
очереди процедур, после чего функция
возвращает значение WAIT_IO_COMPLETION.
Такой
механизм позволяет реализовать, например,
асинхронный ввод-вывод. Поток может
инициировать фоновое выполнение одной или
нескольких операций ввода-вывода функциями
ReadFileEx или WriteFileEx, передав им адреса функций-обработчиков
завершения операции. По завершении вызовы
этих функций будут поставлены в очередь
асинхронного вызова процедур. В свою
очередь, инициировавший операции поток,
когда он будет готов обработать результаты,
может, используя одну из вышеприведенных
функций ожидания, позволить операционной
системе вызвать функции-обработчики. Поскольку
очередь APC
реализована на уровне ядра ОС, она более
эффективна, чем очередь сообщений, и
позволяет реализовать гораздо более
эффективный ввод-вывод.
Объекты синхронизации
Объектами
синхронизации называются объекты Windows,
идентификаторы которых могут
использоваться в функциях синхронизации. Они делятся на две группы: объекты,
использующиеся только для синхронизации, и
объекты, которые используются в других
целях, но могут вызывать срабатывание
функций ожидания. К первой
группе относятся:
Event (событие)
Event
позволяет
известить один или несколько ожидающих
потоков о наступлении события. Event
бывает:
|
Отключаемый |
Будучи |
|
Автоматически |
Автоматически |
Для создания объекта используется функция CreateEvent:
function CreateEvent( lpEventAttributes: PSecurityAttributes; // Адрес структуры // TSecurityAttributes bManualReset, // Задает, будет Event переключаемым // вручную (TRUE) или автоматически (FALSE) bInitialState: BOOL; // Задает начальное состояние. Если TRUE - // объект в сигнальном состоянии lpName: PChar // Имя или NIL, если имя не требуется ): THandle; stdcall; // Возвращает идентификатор созданного // объекта
Структура TSecurityAttributes описана, как:
TSecurityAttributes = record nLength: DWORD; // Размер структуры, должен // инициализироваться как // SizeOf(TSecurityAttributes) lpSecurityDescriptor: Pointer; // Адрес дескриптора защиты. В // Windows 95 и 98 игнорируется // Обычно можно указывать NIL bInheritHandle: BOOL; // Задает, могут ли дочерние // процессы наследовать объект end;
Если не требуется задание особых прав
доступа под Windows
NT или
возможности наследования объекта
дочерними процессами, в качестве параметра lpEventAttributes
можно передавать NIL.
В этом случае объект не может
наследоваться дочерними процессами и ему
задается дескриптор защиты «по умолчанию».
Параметр
lpName позволяет разделять объекты между
процессами. Если lpName совпадает с именем уже существующего
объекта типа Event,
созданного текущим или любым другим
процессом, то функция не
создает нового объекта, а возвращает
идентификатор уже существующего. При этом
игнорируются параметры bManualReset, bInitialState и lpSecurityDescriptor.
Проверить, был ли объект создан или
используется уже существующий, можно
следующим образом:
hEvent := CreateEvent(NIL, TRUE, FALSE, ‘EventName’); if hEvent = 0 then RaiseLastWin32Error; if GetLastError = ERROR_ALREADY_EXISTS then begin // Используем ранее созданный объект end;
Если объект используется для
синхронизации внутри одного процесса, его
можно объявить как глобальную переменную и
создавать без имени.
Имя
объекта не должно совпадать с именем любого
из существующих объектов типов Semaphore, Mutex, Job,
Waitable Timer или FileMapping. В случае совпадения имен функция
возвращает ошибку.
Если известно, что Event
уже создан, для получения доступа к нему
можно вместо CreateEvent воспользоваться функцией OpenEvent:
function OpenEvent( dwDesiredAccess: DWORD; // Задает права доступа к объекту bInheritHandle: BOOL; // Задает, может ли объект наследоваться // дочерними процессами lpName: PChar // Имя объекта ): THandle; stdcall;
Функция возвращает идентификатор
объекта либо 0 — в случае ошибки. Параметр
dwDesiredAccess может принимать одно из следующих
значений:
EVENT_ALL_ACCESS |
Приложение |
EVENT_MODIFY_STATE |
Приложение |
SYNCHRONIZE |
Только для Windows |
После получения идентификатора можно
приступать к его использованию. Для
этого имеются следующие функции:
function SetEvent(hEvent: THandle): BOOL; stdcall;
— устанавливает объект в сигнальное состояние
function ResetEvent(hEvent: THandle): BOOL; stdcall;
— сбрасывает объект, устанавливая его в несигнальное состояние
function PulseEvent(hEvent: THandle): BOOL; stdcall
— устанавливает объект в сигнальное
состояние, дает отработать всем функциям
ожидания, ожидающим этот объект, а затем
снова сбрасывает его.
В Windows API
события используются для выполнения
операций асинхронного ввода-вывода.
Следующий пример показывает, как
приложение инициирует запись одновременно
в два файла, а затем ожидает завершения
записи перед продолжением работы; такой подход
может обеспечить более высокую
производительность при высокой
интенсивности ввода-вывода, чем
последовательная запись:
var Events: array[0..1] of THandle; // Массив объектов синхронизации Overlapped: array[0..1] of TOverlapped; ... // Создаем объекты синхронизации Events[0] := CreateEvent(NIL, TRUE, FALSE, NIL); Events[1] := CreateEvent(NIL, TRUE, FALSE, NIL); // Инициализируем структуры TOverlapped FillChar(Overlapped, SizeOf(Overlapped), 0); Overlapped[0].hEvent := Events[0]; Overlapped[1].hEvent := Events[1]; // Начинаем асинхронную запись в файлы WriteFile(hFirstFile, FirstBuffer, SizeOf(FirstBuffer), FirstFileWritten, @Overlapped[0]); WriteFile(hSecondFile, SecondBuffer, SizeOf(SecondBuffer), SecondFileWritten, @Overlapped[1]); // Ожидаем завершения записи в оба файла WaitForMultipleObjects(2, @Events, TRUE, INFINITE); // Уничтожаем объекты синхронизации CloseHandle(Events[0]); CloseHandle(Events[1])
По завершении работы с объектом он должен
быть уничтожен функцией CloseHandle.
Delphi
предоставляет класс TEvent,
инкапсулирующий функциональность объекта Event.
Класс расположен в модуле
SyncObjs.pas и объявлен следующим образом:
type TWaitResult = (wrSignaled, wrTimeout, wrAbandoned, wrError); TEvent = class(THandleObject) public constructor Create(EventAttributes: PSecurityAttributes; ManualReset, InitialState: Boolean; const Name: string); function WaitFor(Timeout: DWORD): TWaitResult; procedure SetEvent; procedure ResetEvent; end;
Назначение методов очевидно следует из
их названий. Использование
этого класса позволяет не вдаваться в
тонкости реализации вызываемых функций
Windows API. Для простейших случаев объявлен еще один
класс с упрощенным конструктором:
type TSimpleEvent = class(TEvent) public constructor Create; end; … constructor TSimpleEvent.Create; begin FHandle := CreateEvent(nil, True, False, nil); end;
Mutex (Mutually Exclusive)
Мьютекс — это объект синхронизации,
который находится в сигнальном состоянии
только тогда, когда не принадлежит ни
одному из процессов. Как только хотя бы один
процесс запрашивает владение мьютексом, он
переходит в несигнальное состояние и
остается таким до тех пор, пока не будет
освобожден владельцем. Такое поведение
позволяет использовать мьютексы для
синхронизации совместного доступа
нескольких процессов к разделяемому
ресурсу. Для создания мьютекса
используется функция:
function CreateMutex( lpMutexAttributes: PSecurityAttributes; // Адрес структуры // TSecurityAttributes bInitialOwner: BOOL; // Задает, будет ли процесс владеть // мьютексом сразу после создания lpName: PChar // Имя мьютекса ): THandle; stdcall;
Функция возвращает идентификатор
созданного объекта либо 0. Если мьютекс с
заданным именем уже был создан,
возвращается его идентификатор. В
этом случае функция GetLastError вернет код
ошибки ERROR_ALREDY_EXISTS. Имя
не должно совпадать с именем уже
существующего объекта типов Semaphore,
Event, Job,
Waitable
Timer или
FileMapping.
Если неизвестно, существует ли уже
мьютекс с таким именем, программа не должна
запрашивать владение объектом при создании
(то есть должна передать в качестве bInitialOwner значение FALSE).
Если мьютекс уже существует, приложение
может получить его идентификатор функцией OpenMutex:
function OpenMutex( dwDesiredAccess: DWORD; // Задает права доступа к объекту bInheritHandle: BOOL; // Задает, может ли объект наследоваться // дочерними процессами lpName: PChar // Имя объекта ): THandle; stdcall;
Параметр dwDesiredAccess
может принимать одно из следующих значений:
MUTEX_ALL_ACCESS |
Приложение получает полный доступ к объекту |
SYNCHRONIZE |
Только для Windows NT — приложение может использовать объект только в функциях ожидания и функции ReleaseMutex |
Функция возвращает идентификатор
открытого мьютекса либо 0 — в случае ошибки.
Мьютекс переходит в сигнальное состояние
после срабатывания функции ожидания, в
которую был передан его идентификатор. Для
возврата в несигнальное состояние служит
функция ReleaseMutex:
function ReleaseMutex(hMutex: THandle): BOOL; stdcall;
Если несколько процессов обмениваются
данными, например через файл, отображенный
на память, то каждый из них должен содержать
следующий код для обеспечения корректного
доступа к общему ресурсу:
var Mutex: THandle; // При инициализации программы Mutex := CreateMutex(NIL, FALSE, ‘UniqueMutexName’); if Mutex = 0 then RaiseLastWin32Error; ... // Доступ к ресурсу WaitForSingleObject(Mutex, INFINITE); try // Доступ к ресурсу, захват мьютекса гарантирует, // что остальные процессы, пытающиеся получить доступ, // будут остановлены на функции WaitForSingleObject ... finally // Работа с ресурсом окончена, освобождаем его // для остальных процессов ReleaseMutex(Mutex); end; ... // При завершении программы CloseHandle(Mutex);
Подобный код удобно инкапсулировать в
класс, который создает защищенный ресурс.
Мьютекс имеет свойства и методы для
оперирования ресурсом, защищая их при
помощи функций синхронизации.
Разумеется,
если работа с ресурсом может потребовать
значительного времени, то необходимо либо
использовать функцию MsgWaitForSingleObject, либо
вызывать WaitForSingleObject в цикле с нулевым
периодом ожидания, проверяя код возврата. В
противном случае ваше
приложение окажется замороженным. Всегда
защищайте захват-освобождение объекта
синхронизации при помощи блока try … finally,
иначе ошибка во время работы с ресурсом
приведет к блокированию работы всех
процессов, ожидающих его освобождения.
Semaphore (семафор)
Семафор представляет собой счетчик,
содержащий целое число в диапазоне от 0 до максимальной величины, заданной при его создании. Счетчик
уменьшается каждый раз, когда поток успешно
завершает функцию ожидания, использующую
семафор, и увеличивается путем вызова
функции ReleaseSemaphore.
При достижении семафором значения 0 он
переходит в несигнальное состояние, при
любых других значениях счетчика его
состояние — сигнальное. Такое
поведение позволяет использовать семафор в
качестве ограничителя доступа к ресурсу,
поддерживающему заранее заданное
количество подключений.
Для создания семафора служит функция CreateSemaphore:
function CreateSemaphore( lpSemaphoreAttributes: PSecurityAttributes; // Адрес структуры // TSecurityAttributes lInitialCount, // Начальное значение счетчика lMaximumCount: Longint; // Максимальное значение счетчика lpName: PChar // Имя объекта ): THandle; stdcall;
Функция возвращает идентификатор
созданного семафора либо 0, если создать
объект не удалось.
Параметр
lMaximumCount задает максимальное значение
счетчика семафора, lInitialCount задает начальное
значение счетчика и должен быть в диапазоне
от 0 до lMaximumCount. lpName задает имя семафора. Если
в системе уже есть семафор с таким именем,
то новый не создается, а возвращается
идентификатор существующего семафора. В
случае если семафор используется внутри
одного процесса, можно создать его без
имени, передав в качестве lpName значение NIL. Имя
семафора не должно совпадать с именем уже
существующего объекта типов event,
mutex, waitable
timer, job
или file-mapping.
Идентификатор ранее созданного семафора
может быть также получен функцией OpenSemaphore:
function OpenSemaphore( dwDesiredAccess: DWORD; // Задает права доступа к объекту bInheritHandle: BOOL; // Задает, может ли объект наследоваться // дочерними процессами lpName: PChar // Имя объекта ): THandle; stdcall;
Параметр dwDesiredAccess
может принимать одно из следующих значений:
SEMAPHORE_ALL_ACCESS |
Поток |
SEMAPHORE_MODIFY_STATE |
Поток |
SYNCHRONIZE |
Только для Windows |
Для увеличения счетчика семафора
используется функция ReleaseSemaphore:
function ReleaseSemaphore( hSemaphore: THandle; // Идентификатор семафора lReleaseCount: Longint; // Счетчик будет увеличен на эту величину lpPreviousCount: Pointer // Адрес 32-битной переменной, // принимающей предыдущее значение // счетчика ): BOOL; stdcall;
Если значение счетчика после выполнения
функции превысит заданный для него
функцией CreateSemaphore максимум, то ReleaseSemaphore
возвращает FALSE
и значение семафора не изменяется. В
качестве параметра lpPreviousCount можно передать
NIL, если это значение нам не нужно.
Рассмотрим
пример приложения, запускающего на
выполнение несколько заданий в отдельных
потоках (например, программа для фоновой
загрузки файлов из Internet). Если количество
одновременно выполняющихся заданий будет
слишком велико, то это приведет к
неоправданной загрузке канала. Поэтому
реализуем потоки, в которых будет
выполняться задание, таким образом, чтобы
когда их количество превышает заранее
заданную величину, то поток бы
останавливался и ожидал завершения работы
ранее запущенных заданий:
unit LimitedThread; interface uses Classes; type TLimitedThread = class(TThread) procedure Execute; override; end; implementation uses Windows; const MAX_THREAD_COUNT = 10; var Semaphore: THandle; procedure TLimitedThread.Execute; begin // Уменьшаем счетчик семафора. Если к этому моменту уже запущено // MAX_THREAD_COUNT потоков — счетчик равен 0 и семафор в // несигнальном состоянии. Поток будет заморожен до завершения // одного из запущенных ранее. WaitForSingleObject(Semaphore, INFINITE); // Здесь располагается код, отвечающий за функциональность потока, // например загрузка файла ... // Поток завершил работу, увеличиваем счетчик семафора и позволяем // начать обработку другим потокам. ReleaseSemaphore(Semaphore, 1, NIL); end; initialization // Создаем семафор при старте программы Semaphore := CreateSemaphore(NIL, MAX_THREAD_COUNT, MAX_THREAD_COUNT, NIL); finalization // Уничтожаем семафор по завершении программы CloseHandle(Semaphore); end;
![]()
Синхронизация потоков
Иногда при работе с несколькими потоками
или процессами появляется необходимость
синхронизировать выполнениедвух
или более из них. Причина этого чаще
всего заключается в том, что два или
более потоков могут требовать доступ
к разделяемому ресурсу, которыйреальноне может быть предоставлен сразу
нескольким потокам. Разделяемым
называется ресурс, доступ к которому
могут одновременно получать несколько
выполняющихся задач.
Механизм, обеспечивающий процесс
синхронизации, называется ограничением
доступа.Необходимость в нем возникает
также в тех случаях, когда один поток
ожидает события, генерируемого другим
потоком. Естественно, должен существовать
какой-то способ, с помощью которого
первой поток будет приостановлен до
совершения события. После этого поток
должен продолжить свое выполнение.
Имеется два общих состояния, в которых
может находиться задача. Во-первых,
задача может выполняться(или быть
готовой к выполнению, как только получит
доступ к ресурсам процессора). Во-вторых,
задача может бытьблокирована.В
этом случае ее выполнение приостановлено
до тех пор, пока не освободится нужный
ей ресурс или не произойдет определенное
событие.
В Windows имеется специальные сервисы,
которые позволяют определенным образом
ограничить доступ к разделяемым ресурсам,
ведь без помощи операционной системы
отдельный процесс или поток не может
сам определить, имеет ли он единоличный
доступ к ресурсу. Операционная система
Windows содержит процедуру, которая в
течении одной непрерывной операции
проверяет и, если это возможно,
устанавливает флаг доступа к ресурсу.
На языке разработчиков операционной
системы такая операция называется
операцией проверки и установки.
Флаги, используемые для обеспечения
синхронизации и управления доступом к
ресурсам, называютсясемафорами(semaphore). Интерфейс Win32 API обеспечивает
поддержку семафоров и других объектов
синхронизации. Библиотека MFC также
включает поддержку данных объектов.
Объекты синхронизации и классы mfc
Интерфейс Win32 поддерживает четыре типа
объектов синхронизации — все они так
или иначе основаны на понятии семафора.
Первым типом объектов является собственно
семафор, или классический (стандартный)
семафор. Он позволяет ограниченному
числу процессов и потоков обращаться
к одному ресурсу. При этом доступ к
ресурсу либо полностью ограничен (один
и только один поток или процесс может
обратиться к ресурсу в определенный
период времени), либо одновременный
доступ получает лишь малое количество
потоков и процессов. Семафоры реализуются
с помощью счетчика, значение которого
уменьшается, когда задаче выделяется
семафор, то увеличивается, когда задача
освобождает семафор.
Вторым типом объектов синхронизации
является исключающий ( mutex) семафор.
Он предназначен для полного ограничения
доступа к ресурсу, чтобы в любой момент
времени к ресурсу мог обратиться только
один процесс или поток. Фактически, это
особая разновидность семафора.
Третьим типом объектов синхронизации
является событие, илиобъект
события ( event object).Он используется для
блокирования доступа к ресурсу до тех
пор, пока какой-нибудь другой процесс
или поток не заявит о том, что данный
ресурс может быть использован. Таким
образом, данный объект сигнализирует
о выполнении требуемого события.
При помощи объекта синхронизации
четвертого типа можно запрещать
выполнения определенных участков кода
программы несколькими потоками
одновременно. Для этого данные участки
должны быть объявлены как критический
раздел ( critical section). Когда в этот раздел
входит один поток, другим потокам
запрещается делать тоже самое до тех
пор, пока первый поток не выйдет из
данного раздела.
Критические разделы, в отличие от других
типов объектов синхронизации, применяются
только для синхронизации потоков внутри
одного процесса. Другие же типы объектов
могут быть использованы для синхронизации
потоков внутри процесса или для
синхронизации процессов.
В MFC механизм синхронизации, обеспечиваемый
интерфейсом Win32 , поддерживается с
помощью следующих классов, порожденных
от класса CSyncObject:
-
CCriticalSection— реализует критический
раздел. -
CEvent— реализует объект события
-
CMutex— реализует исключающий семафор.
-
CSemaphore— реализует классический
семафор.
Кроме этих классов в MFC определены также
два вспомогательных класса синхронизации
: CSingleLock иCMultiLock. Они контролируют
доступ к объекту синхронизации и содержат
методы, используемы для предоставления
и освобождения таких объектов. КлассCSingleLockуправляет доступом к одному
объекту синхронизации, а классCMultiLock— к нескольким объектам. Далее будем
рассматривать только классCSingleLock.
Когда какой-либо объект синхронизации
создан, доступ к нему можно контролировать
с помощью класса CSingleLock. Для этого
необходимо сначала создать объект типаCSingleLockс помощью конструктора :
CSingleLock( CSyncObject* pObject, BOOL bInitialLock = FALSE
);
Через первый параметр передается
указатель на объект синхронизации,
например семафор. Значение второго
параметра определяет, должен ли
конструктор попытаться получить доступ
к данному объекту. Если этот параметр
не равен нулю, то доступ будет получен,
в противном случае попыток получить
доступ не будет. Если доступ получен,
то поток, создавший объект класса
CSingleLock, будет остановлен до
освобождения соответствующего объекта
синхронизации методомUnlockклассаCSingleLock.
Когда объект типа CSingleLock создан, доступ
к объекту, на который указывал параметр
pObject , может контролироваться с помощью
двух функций : Lock иUnlockклассаCSingleLock.
Метод Lockпредназначен для получения
доступа к объекту к объекту синхронизации.
Вызвавший его поток приостанавливается
до завершения данного метода, то есть
до тех пор, пока не будет получен доступ
к ресурсу. Значение параметра определяет,
как долго функция будет ожидать получения
доступа к требуемому объекту. Каждый
раз при успешном завершении метода
значение счетчика, связанного с объектом
синхронизации, уменьшается на единицу.
Метод Unlockосвобождает объект
синхронизации, давая возможность другим
потокам использовать ресурс. В первом
варианте метода значение счетчика,
связанного с данным объектом, увеличивается
на единицу. Во втором варианте первый
параметр определяет, на сколько это
значение должно быть увеличено. Второй
параметр указывает на переменную, в
которую будет записано предыдущее
значение счетчика.
При работе с классом CSingleLockобщая
процедура управления доступом к ресурсу
такова :
-
создать объект типа CSyncObj (например,
семафор), который будет использоваться
для управления доступом к ресурсу ; -
с помощью созданного объекта синхронизации
создать объект типа CSingleLock; -
для получения доступа к ресурсу вызвать
метод Lock; -
выполнить обращение к ресурсу ;
-
вызвать метод Unlock , чтобы освободить
ресурс.
Далее описывается, как создавать и
использовать семафоры и объекты событий.
Разобравшись с этими понятиями, можно
достаточно просто изучить и использовать
два других типа объектов снхронизации
: критические секции и мьютексы.
Соседние файлы в папке Параллельные Процессы и Параллельное Программирование
- #
- #
- #
- #
- #
- #
26.03.20154.77 Mб14Кормен-Алгоритмы. Постоение и анализ.pdf
- #
In progress
Отличие между конкурентностью, параллелизмом и многопоточностю (Differences between concurrency, parallelism, and multithreading)
Materials from book by Riccardo Terrell. Concurrency in .NET. Modern patterns of concurrent and parallel programming. Publishing Hous «Manning», 2018

Source code for «Concurrency in .NET» book Manning publisher
- Последовательное программирование выполняет одну задачу в один момент времени
- Конкурентное (Concurrency) программирование одновременно запускает несколько задач
- Параллельное программирование выполняет одновременно несколько задач
- Многозадачность выполняет несколько задач одновременно со временем
- Многопоточность для повышения производительности
- Итоги
- Зачем нужна параллельность?
- Ловушки параллельного программирования
- Проблемы с параллелизмом
- Простой пример в реальном мире: параллельная быстродействующая сортировка
- Глоссарий
Последовательное программирование выполняет одну задачу в один момент времени
Для каждого человека в очереди бариста последовательно повторяет один и тот же набор инструкций (измельчить кофе, варить кофе, подогреть молоко, вспенить молоко и объединить кофе и молоко, чтобы приготовить капучино).
Рисунок является примером последовательной работы, когда одна задача должна быть завершена до выполнения следующей. Это подход с четким набором систематических (поэтапных) инструкций о том, что делать и когда это делать. В этом примере бариста, вероятно, не запутается и не допустят ошибок при подготовке капучино, потому что шаги ясны и упорядочены. Недостатком подготовки капучино поэтапно является то, что бариста должна ждать при выполнении отдельных частей процесса. Пока ожидается, что кофе будет измельчен или молоко будет вспениваться, бариста эффективно неактивен (заблокирован). Такая же концепция применяется к последовательным и параллельным моделям программирования.

Как показано на рисунке, последовательное программирование включает последовательное, постепенно упорядоченное выполнение процессов, по одной инструкции в единицу времени линейным способом.
В императивном и объектно-ориентированном программировании (ООП) мы склонны писать код, который ведет себя последовательно, при этом все внимание и ресурсы сосредоточены на текущей задаче. Мы моделируем и выполняем программу, выполняя упорядоченный набор утверждений одно за другим.
Up
Конкурентное (Concurrency) программирование одновременно запускает несколько задач

Бариста переключается между операциями (многозадачность) приготовления кофе (молоть и варить) и готовит молоко (пар и пену). В результате, бариста выполняет чередование нескольких задач чередующимся образом, создавая иллюзию многозадачности. Но за один раз из-за совместного использования общих ресурсов выполняется только одна операция.
Конкурентность (Concurrency) описывает возможность одновременного запуска нескольких программ или нескольких частей программы. В компьютерном программировании использование конкурентности в приложении обеспечивает актуальную многозадачность, деление приложения на несколько и независимых процессов, которые выполняются в один момент времени (одновременно, синхронно) в разных потоках. Это может произойти либо в одном ядре процессора, либо параллельно, если доступно несколько ядер процессора. Пропускная способность (скорость, с которой процессор обрабатывает вычисление) и отзывчивость программы могут быть улучшены посредством асинхронного или параллельного (parallel) выполнения задачи. Например, приложение, которое передает видеоконтент, работает одновременно, поскольку оно одновременно считывает цифровые данные из сети, распаковывает его и обновляет свою презентацию на экране.
Конкурентность создает впечатление, что эти потоки работают параллельно и что разные части программы могут работать одновременно. Но в одноядерной среде выполнение одного потока временно приостанавливается и переключается на другой поток, как в случае с бариста на рисунке. Если бариста хочет ускорить производство, одновременно выполняя несколько задач, то имеющиеся ресурсы должны быть увеличены. В компьютерном программировании этот процесс называется параллелизмом.
Up
Параллельное программирование выполняет одновременно несколько задач
Из перспективы разработчика мы думаем о параллелизме, когда мы рассматриваем вопросы: «Как может моя программа выполнять сразу несколько вещей?» Или «Как моя программа может решить одну проблему быстрее?» Параллелизм — это концепция выполнения нескольких задач в момент времени одновременно, буквально в то же время, на разных ядрах, для повышения скорости приложения. Хотя все параллельные программы являются синхронными, не все синхронные параллельны. Это связано с тем, что параллелизм зависит от реальной среды выполнения, и для этого требуется аппаратная поддержка (несколько ядер). Параллелизм реализуется только в многоядерных устройствах и является средством повышения производительности и пропускной способности программы.

Только многоядерные машины позволяют параллелизму одновременно выполнять разные задачи. На этом рисунке каждое ядро выполняет самостоятельную задачу.
Если вернуться к примеру в кафе, можно представить, что менеджер хочет сократить время ожидания клиентов, ускорив производство напитков. Интуитивное решение — нанять второго бариста и создать вторую кофейную станцию. С двумя бариста, работающими одновременно, две очереди клиентов могут обрабатываться независимо и параллельно, а подготовка капучино ускоряется.

Производство капучино быстрее, потому что два бариста могут работать параллельно с двумя кофейными станциями.
Параллелизм может быть достигнут, когда одна задача разбивается на несколько независимых подзадач, которые затем запускаются с использованием всех доступных ядер. На рисунке многоядерная машина (две кофейные станции) позволяет параллелизировать одновременное выполнение различных задач (двух занятых баристо) без перерыва.
Концепция синхронизации является фундаментальной для одновременного выполнения операций параллельно. В такой программе операции синхронны, если они могут выполняться параллельно, и эти операции параллельны, если выполнение перекрывается во времени (Рисунок).

Параллельные вычисления — это тип вычислений, при котором выполняется много вычислений одновременно, работая по принципу, что большие задачи часто можно разделить на более мелкие, которые затем решаются одновременно.
Параллелизм и синхронность — это связанные модели программирования. Параллельная программа также синхронна, но синхронная программа не всегда параллельна, причем параллельное программирование является подмножеством синхронного программирования. Синхронность относится к дизайну системы, параллелизм относится к исполнению. Синхронные и параллельные модели программирования напрямую связаны с локальной аппаратной средой, где они выполняются.
Up
Многозадачность выполняет несколько задач одновременно со временем
Многозадачность — это концепция выполнения нескольких задач в течение определенного периода времени, выполняя их одновременно. Мы многозадачно работаем в нашей повседневной жизни. Например, ожидая, пока бариста подготовит наш cappuccino, мы используем наш смартфон для проверки наших писем или сканирования новостей. Мы делаем две вещи одновременно: ожидание и использование смартфона.
Компьютерная многозадачность была разработана в те времена, когда компьютеры имели один процессор для одновременного выполнения множества задач при совместном использовании одних и тех же вычислительных ресурсов. Вначале только одна задача могла выполняться за раз, используя временную разбивку CPU. (Временной срез относится к сложной логике планирования, которая координирует выполнение между несколькими потоками.) Время, в течение которого планировщик позволяет потоку запускаться до расписания другого потока, называется квантом потока. CPU срезается так, чтобы каждый поток получал одну операцию до того, как контекст выполнения переключился на другой поток. Контекстное переключение — это процедура, выполняемая операционной системой для многозадачности для оптимизации производительности. Но в одноядерном компьютере возможно, что многозадачность может замедлить производительность программы, введя дополнительные накладные расходы для переключения контекста между потоками.

Каждая задача имеет разный оттенок, что указывает на то, что переключатель контекста в одноядерном компьютере создает иллюзию параллельной работы нескольких задач, но одновременно обрабатывается только одна задача.
Существует два вида многозадачных операционных систем:
- Совместные многозадачные системы (Cooperative multitasking systems), в которых планировщик позволяет каждой задаче запускатьcся до тех пор, пока она не завершит или явно не вернет управление выполнением в планировщик
- Упреждающие многозадачные системы (Preemptive multitasking systems) (например, Microsoft Windows), где планировщик приоритизирует выполнение задач, а базовая система, учитывая приоритетность задач, переключает последовательность выполнения после завершения распределения времени, получая управление другими задачами
Большинство операционных систем, разработанных в последнее десятилетие, обеспечили упреждающую многозадачность. Многозадачность полезна для обеспечения пользовательского интерфейса, чтобы избежать замораживания пользовательского интерфейса во время длительных операций.
Up
Многопоточность для повышения производительности
Многопоточность — это расширение концепции многозадачности, целью которой является повышение производительности программы за счет максимизации и оптимизации компьютерных ресурсов. Многопоточность — это форма параллелизма, которая использует несколько потоков выполнения. Многопоточность подразумевает параллелизм, но параллелизм необязательно подразумевает многопоточность. Многопоточность позволяет приложению явно подразделять конкретные задачи на отдельные потоки, которые работают параллельно в одном и том же процессе.
ПРИМЕЧАНИЕ. Процесс является экземпляром программы, работающей в компьютерной системе. Каждый процесс имеет один или несколько потоков выполнения, и ни один поток не может существовать вне процесса.
Поток — это единица вычисления (независимый набор инструкций программирования, предназначенных для достижения определенного результата), который планировщик операционной системы независимо выполняет и управляет. Многопоточность отличается от многозадачности: в отличие от многозадачности, при многопоточности потоки совместно используют ресурсы. Но этот проект «совместного использования ресурсов» представляет больше проблем программирования, чем многозадачность.
Концепции параллельного и многопоточного программирования тесно связаны. Но в отличие от параллелизма многопоточность является аппаратно-агностической, а это означает, что ее можно выполнять независимо от количества ядер. Параллельное программирование — это надмножество многопоточности. Вы можете использовать многопоточность для параллелизации программы путем совместного использования ресурсов в одном процессе, например, но вы также можете распараллелить программу, выполнив вычисления в нескольких процессах или даже на разных компьютерах. На рисунке показана зависимость между этими терминами.

Взаимосвязь между синхронностью (concurrency), параллелизмом (parallelism), многопоточностью (multithreading) и многозадачностью (multitasking) в одно- и многоядерном устройстве
Up
Итоги:
-
Последовательное программирование относится к набору упорядоченных инструкций, выполняемых по одному на одном (единственном) процессоре.
-
Конкурентностное программирование обрабатывает несколько операций за один раз и не требует аппаратной поддержки (с использованием одного или нескольких ядер).
Конкурентность(*)(concurrency) — это наиболее общий термин, который говорит, что одновременно выполняется более одной задачи. Например, вы можете одновременно смотреть телевизор и комментить фоточки в фейсбуке. Винда, даже 95-я могла (**) одновременно играть музыку и показывать фотки.
(*) К сожалению, вменяемого русскоязычного термина я не знаю. Википедия говорит, что concurrent computing — это параллельные вычисления, но как тогда будет parallel computing по русски?
(**) Да, вспоминается анекдот про Билла Гейтса и многозадачность винды, но, теоретически винда могла делать несколько дел одновременно. Хотя и не любых.
Конкурентное исполнение — это самый общий термин, который не говорит о том, каким образом эта конкурентность будет получена: путем приостановки некоторых вычислительных элементов и их переключение на другую задачу, путем действительно одновременного исполнения, путем делегации работы другим устройствам или еще как-то. Это не важно.
Конкурентное исполнение говорит о том, что за определенный промежуток времени будет решена более, чем одна задача. Точка.
Сергей Тепляков
-
Параллельное программирование одновременно выполняет несколько операций на нескольких процессорах. Все параллельные программы синхронны, работают одновременно, но не все синхронные параллельны. Причина в том, что параллелизм возможен только на многоядерных устройствах.
Параллельное исполнение (parallel computing) подразумевает наличие более одного вычислительного устройства (например, процессора), которые будут одновременно выполнять несколько задач.
Параллельное исполнение — это строгое подмножество конкурентного исполнения. Это значит, что на компьютере с одним процессором параллельное программирование — невозможно

Сергей Тепляков
-
Многозадачность одновременно выполняет несколько потоков из разных процессов. Многозадачность не обязательно означает параллельное выполнение, которое достигается только при использовании нескольких процессоров.
-
Многопоточность расширяет идею многозадачности; это форма параллелизма, которая использует несколько независимых потоков выполнения из одного и того же процесса. Каждый поток может работать синхронно или параллельно, в зависимости от поддержки оборудования.
Многопоточность — это один из способов реализации конкурентного исполнения путем выделения абстракции «рабочего потока» (worker thread).
Потоки «абстрагируют» от пользователя низкоуровневые детали и позволяют выполнять более чем одну работу «параллельно». Операционная система, среда исполнения или библиотека прячет подробности того, будет многопоточное исполнение конкурентным (когда потоков больше чем физических процессоров), или параллельным (когда число потоков меньше или равно числу процессоров и несколько задач физически выполняются одновременно).
Сергей Тепляков
-
Асинхронность Асинхронное программирование подразумевает инициацию некоторой операцию, об окончании которой поток, который ее инициировал узнает спустя некоторое время. Обычно это применяется для работы с системой ввода-вывода: диски, сеть и т.д. При этом, если это все сделано правильно, никакого потока нет.
Асинхронность (asynchrony) подразумевает, что операция может быть выполнена кем-то на стороне: удаленным веб-узлом, сервером или другим устройством за пределами текущего вычислительного устройства.
Основное свойство таких операций в том, что начало такой операции требует значительно меньшего времени, чем основная работа. Что позволяет выполнять множество асинхронных операций одновременно даже на устройстве с небольшим числом вычислительных устройств.
CPU-bound и IO-Bound операции: Еще один важный момент, с точки зрения разработчика — разница между CPU-bound и IO-bound операциями. CPU-Bound операции нагружают вычислительные мощности текущего устройства, а IO-Bound позволяют выполнить задачу вне текущей железки. Разница важна тем, что число одновременных операций зависит от того, к какой категории они относятся. Вполне нормально запустить параллельно сотни IO-Bound операций, и надеяться, что хватит ресурсов обработать все результаты. Запускать же параллельно слишком большое число CPU-bound операций (больше, чем число вычислительных устройств) бессмысленно.
Возвращаясь к исходному вопросу: нет смысла выполнять в 1000 потоков метод Calc, если он является CPU-Intensive (нагружает центральный процессор), поскольку это приведет к падению общей эффективности вычислений. ОС-ке придется переключать несколько доступных ядер для обслуживания сотен потоков. А этот процесс не является дешевым.
Самым простым и эффективным способом решения CPU-Intensive задачи, заключается в использовании идиомы Fork-Join: задачу (например, входные данные) нужно разбить на определенное число подзадач, которые можно выполнить параллельно. Каждая подзадача должна быть независимой и не обращаться к разделяемым переменным/памяти. Затем, нужно собрать промежуточные результаты и объединить их.
Именно на этом принципе основан PLINQ. О чем можно почитать тут: Джозеф Албахари. Параллельное программирование. Выглядит это очень интересно:IEnumerable<Data> yourData = GetYourData(); var result = yourData.AsParallel() // начинаем обрабатывать параллельно .Select(d => ComputeMD5(d)) // Вычисляем параллельно .Where(md5 => IsValid(md5)) .ToArray(); // Возврвщаемся к синхронной моделиВ этом случае, число потоков будет контролироваться библиотечным кодом в недрах CLR/TPL и метод ComputeMD5 будет вызван параллельно N-раз на компьютере с N-процессорами (ядрами).
Сергей Тепляков

Up
Зачем нужна параллельность?
Параллельность — естественная часть жизни, в которой люди привыкли к многозадачности. Мы можем прочитать электронное письмо, выпивая чашку кофе или набирать, слушая нашу любимую песню. Основной причиной использования параллелизма в приложении является повышение производительности и отзывчивости и достижение низкой латентности. Считается, что если один человек выполняет две задачи одину за другой, это занимает больше времени, чем если бы два человека выполняли те же две задачи одновременно.
То же самое и с приложениями. Проблема в том, что большинство приложений не записываются для равномерного разделения задач, требуемых среди доступных процессоров. Компьютеры используются во многих областях, таких как аналитика, финансы, наука и здравоохранение. Количество анализируемых данных увеличивается с каждым годом.
Две хорошие иллюстрации — Google и Pixar. В 2012 году Google получал более 2 миллионов поисковых запросов в минуту; в 2014 году это число более чем удвоилось. В 1995 году Pixar выпустил первый полностью созданный компьютером фильм «История игрушек». В компьютерной анимации для каждого изображения должно быть представлено множество деталей и информации, таких как затенение и освещение. Вся эта информация изменяется со скоростью 24 кадра в секунду. В трехмерном фильме требуется экспоненциальное увеличение изменения информации.
Создатели «Истории игрушек» использовали 100 подключенных двухпроцессорных машин для создания своего фильма, а использование параллельных вычислений было незаменимым. Инструменты Pixar развивались для «Истории игрушек 2»; компания использовала 1400 компьютерных процессоров для цифрового редактирования фильмов, тем самым значительно улучшая качество цифрового видео и время редактирования. В начале 2000 года мощность компьютера Pixar увеличилась еще больше, до 3500 процессоров. Шестнадцать лет спустя компьютерная мощность, используемая для обработки полностью анимационного фильма, достигла абсурдных 24 000 ядер. Потребность в параллельных вычислениях продолжает экспоненциально возрастать.
Рассмотрим процессор с N (любое число) работающих ядер. В однопоточном приложении выполняется только одно ядро. То же самое приложение, выполняющее несколько потоков, будет быстрее, и по мере роста спроса на производительность, также будет возрастать спрос на N, что сделает параллельные программы стандартной модельной моделью выбора в будущем.
Если вы запускаете приложение на многоядерной машине, которая не была разработана с учетом синхронности, вы теряете производительность компьютера, потому что приложение, которое последовательно проходит через процессы, будет использовать только часть доступной мощности компьютера. В этом случае, если вы откроете диспетчер задач или любой счетчик производительности процессора, вы заметите, что только одно ядро работает высоко, возможно, на 100%, тогда как все остальные ядра недоиспользуются или простаивают. В машине с восемью ядрами выполнение неконкурентных программ означает, что общее использование ресурсов может составлять всего 15%.

Диспетчер задач Windows показывает программу, которая плохо использует ресурсы CPU.
Такая трата вычислительной мощности недвусмысленно иллюстрирует, что последовательный код не является правильной моделью программирования для многоядерных обработчиков. Чтобы максимально использовать доступные вычислительные ресурсы, платформа Microsoft .NET обеспечивает параллельное выполнение кода посредством многопоточности. Используя параллелизм, программа может в полной мере использовать имеющиеся ресурсы, о чем свидетельствует счетчик производительности процессора на рисунке ниже, где заметно, что все ядра процессора работают высоко, возможно, на 100%. Текущие тенденции оборудования предсказывают больше ядер вместо более высоких тактовых частот; поэтому разработчикам не остается иного выбора, кроме как охватить эту эволюцию и стать параллельными программистами.

Программа, написанная с учетом параллелизма, может максимизировать ресурсы CPU, возможно, до 100%
Up
Ловушки параллельного программирования
Синхронное и параллельное программирование, без сомнения, полезно для быстрой реагирования и быстрого выполнения данного вычисления. Но этот выигрыш производительности и реактивный опыт не дается дешево. Используя последовательные программы, выполнение кода идет по счастливому путь предсказуемости и детерминизма. И наоборот, многопоточное программирование требует приверженности и усилий для достижения правильности. Кроме того, рассуждение о нескольких запусках, выполняемых одновременно, затруднено, потому что мы привыкли думать последовательно.
Детерминизм является основополагающим требованием для создания программного обеспечения, поскольку часто предполагается, что компьютерные программы возвращают одинаковые результаты от одного запуска к другому. Но это свойство трудно решить параллельно. Внешние обстоятельства, такие как планировщик операционной системы или когерентность кеша, могут влиять на время выполнения и, следовательно, порядок доступа для двух или более потоков и изменять одну и ту же ячейку памяти. Этот вариант времени может повлиять на результат программы.
Процесс разработки параллельных программ предполагает не только создание нескольких потоков. Написание программ, которые выполняются параллельно, требует продуманного дизайна. Вы должны учитывать следующие вопросы:
- Как можно использовать синхронность и параллелизм для достижения невероятной вычислительной производительности и высокочувствительного приложения?
- Как такие программы могут в полной мере использовать возможности, предоставляемые многоядерным компьютером?
- Как можно согласовывать связь с одним и тем же местом памяти между потоками, обеспечивая при этом безопасность потока? (Метод называется потокобезопасным, когда данные и состояние не повреждаются, если два или более потока пытаются получить доступ и изменить данные или состояние в одно и то же время.)
- Как программа может гарантировать детерминированное исполнение?
- Как можно раскрыть выполнение программы, не подвергая риску качество конечного результата?
Up
Проблемы с параллелизмом
Написание параллельных программ непросто, и во время разработки программы необходимо учитывать множество сложных элементов. Создание новых потоков или очередность нескольких заданий в пуле потоков относительно просто, но как обеспечить правильность в программе? Когда многие потоки постоянно обращаются к общим данным, нужно подумать о том, как защитить структуру данных, чтобы гарантировать ее целостность. Поток должен записывать и изменять местоположение памяти атомарно, без помех другими потоками. Реальность заключается в том, что программы, написанные на императивных языках программирования или на языках с переменными, значения которых могут меняться (изменяемые переменные), всегда будут уязвимы для расчётов данных независимо от уровня синхронизации памяти или используемых параллельных библиотек.
ПРИМЕЧАНИЕ Гонки данных возникают, когда два или более потоков в одном процессе одновременно обращаются к одному и тому же местоположению памяти, и по меньшей мере один из доступа обновляет слот памяти, в то время как другие потоки считывают одно и то же значение, не используя какие-либо исключительные блокировки для управления их доступом к этому месту памяти.
Рассмотрим случай двух потоков (Thread 1 и Thread 2), работающих параллельно, оба пытаются получить доступ и изменить общее значение x, как показано на рисунке. Потоку Thread 1 для изменения переменной требуется более одной инструкции CPU: значение должно быть считано из памяти, затем изменено и в конечном итоге записано обратно в память. Если Thread 2 пытается прочитать из той же ячейки памяти, пока Thread 1 записывает обновленное значение, значение x изменилось. Точнее, возможно, что Thread 1 и Thread 2 одновременно считывают значение x, тогда Thread 1 изменяет значение x и записывает его обратно в память, а Thread 2 также изменяет значение x. Результатом является повреждение данных. Это явление называется состояние гонки.

Два потока (Thread 1 и Thread 2) работают параллельно, оба пытаются получить доступ и изменить общее значение x. Если Thread 2 пытается прочитать из того же места в памяти, а Thread 1 записывает обновленное значение, значение x изменяется. Результатом этого является повреждение данных или состояние гонки.
Сочетание изменчивого состояния и параллелизма в программе является синонимом проблем. Решение с точки зрения императивной парадигмы заключается в защите изменяемого состояния путем блокировки доступа нескольким потокам. Этот метод называется взаимным исключением, поскольку доступ одного потока к определенному месту памяти предотвращает доступ к другим потокам в то время. Концепция синхронизации является центральной, поскольку несколько потоков должны одновременно получать одни и те же данные, чтобы воспользоваться этой технологией. Введение блокировок для синхронизации доступа несколькими потоками к общим ресурсам решает проблему повреждения данных, но вводит больше осложнений, которые могут привести к тупиковой ситуации.
Рассмотрим случай на рисунке, где Thread 1 и Thread 2 ждут друг друга для завершения работы и блокируются на неопределенное время в ожидании. Thread 1 получает Lock A, и сразу после Thread 2 получает Lock B. В этот момент оба потока ожидают блокировки, которая никогда не будет выпущена. Это случай взаимной блокровки (deadlock).

В этом случае Thread 1 получает Lock A, а Thread 2 получает Lock B. Затем Thread 2 пытается получить Lock A, а Thread 1 пытается получить Lock B, который уже был приобретен Thread 2, который ожидает получения Lock A до освобождая Lock B. В этот момент оба потока ожидают блокировки, которые никогда не будут выпущены. Это случай взаимной блокровки.
Ниже приведен краткий перечень факторов риска параллелизма.
- Состояние гонки — это состояние, которое возникает, когда совместно используемый изменяемый ресурс (например, файл, изображение, переменная или коллекция) используется одновременно многочисленными потоками, оставляя несогласованное состояние. Повреждение данных делает программу ненадежной и непригодной для использования.
- Снижение производительности является общей проблемой, когда несколько потоков разделяющих состояний требующие методов синхронизации. Взаимные блокировки (или мьютексы), как следует из названия, предотвращают параллельный запуск кода, заставляя несколько потоков останавливать работу для связи и синхронизации доступа к памяти. Приобретение и освобождение блокировок происходит со снижением производительности, замедляя все процессы. По мере того как количество ядер становится больше, затраты на блокировку могут потенциально увеличиваться. По мере ввода большего количества задач для совместного использования одних и тех же данных накладные расходы, связанные с блокировками, могут негативно повлиять на вычисление.
- Тупик (Deadlock) — это проблема параллелизма, возникающая из-за использования блокировок. Это происходит, когда существует цикл задач, в котором каждая задача блокируется в ожидании продолжения работы. Поскольку все задачи ждут выполнения другой задачи, они блокируются на неопределенный срок. Чем больше ресурсов распределяется между потоками, тем больше блокировок необходимо, чтобы избежать состояния гонки, и тем выше риск блокировок.
- Отсутствие композиции — проблема дизайна, возникающая из-за введения блокировок в код. Блоктровк не сочитаются. Композиция способствует устранению проблем, разбивая сложную задачу на более мелкие кусочки, которые легче решить, а затем склеивают их вместе. Композиция является фундаментальным принципом в FP.
Up
Простой пример в реальном мире: параллельная быстродействующая сортировка
src
Алгоритмы сортировки обычно используются в технических вычислениях и могут быть узким местом. Рассмотрим алгоритм Quicksort, вычисление, связанное с CPU, поддающееся распараллеливанию, которое упорядочивает элементы массива. Этот пример призван продемонстрировать подводные камни преобразования последовательного алгоритма в параллельную версию и указывает, что введение параллелизма в код требует дополнительного мышления, прежде чем принимать какие-либо решения. В противном случае производительность может иметь противоположный результат.
Quicksort — это алгоритм «Разделяй и властвуй»; он сначала делит большой массив на два меньших подмассива с меньшими элементами и большими элементами. Quicksort может затем рекурсивно сортировать подмассивы и поддается параллелизации. Он может работать на месте массива, требуя небольших дополнительных объемов памяти для выполнения сортировки. Алгоритм состоит из трех простых шагов, как показано на рисунке:
- выберать pivot-элемент
- разделить последовательность на подпоследовательности в соответствии с их порядком относительно вершины
- отсортировать подпоследовательности.

Рекурсивная функция «Разделяет и властвует». Каждый блок делится на равные половины, где pivot-элемент должен быть медианой последовательности, пока каждая часть кода не будет выполнена независимо. Когда все отдельные блоки завершены, они отправляют результат обратно предыдущему вызывающему агенту для агрегирования. Quicksort основан на идее выбора точки поворота и разбиения последовательности на элементы подпоследовательности, меньшие, чем точка поворота, и больше, чем опорные элементы, прежде чем рекурсивно сортировать две меньшие последовательности.
Рекурсивные алгоритмы, особенно те, которые основаны на принципе «Разделяй и властвуй», являются отличным кандидатом для распараллеливания и вычислений, связанных с CPU. Библиотека Microsoft Task Parallel Library (TPL), представленная после выпуска .NET 4.0, упрощает реализацию и использование параллелизма для этого типа алгоритма. Используя TPL, можно разделить каждый шаг алгоритма и выполнить каждую задачу параллельно, рекурсивно. Это простая реализация, но нужно быть осторожным с уровнем глубины, с которым создаются потоки, чтобы не добавлять больше задач, чем необходимо.
Up
Глоссарий
- Асинхронность (Asynchronicity) — Когда программа выполняет запросы, которые не выполняются немедленно, но которые выполняются позже, и где программа, выдающая запрос, должна делать тем временем значительную работу.
- Конкурентность (Concurrency) — Когда нескольких вещей происходит одновременно. Обычно, конкурентные программы имеют несколько потоков выполнения, каждый из которых обычно выполняет разный код.
- Параллелизм (Parallelism) — Состояние программы, когда одновременно выполняется несколько потоков, чтобы ускорить выполнение программы.
- Процесс (Process) — стандартный процесс операционной системы. Каждый экземпляр .NET CLR работает в своем собственном процессе. Процессы обычно независимы.
- Поток (Thread) — Самая маленькая последовательность запрограммированных команд, которыми ОС может управлять независимо. Каждый процесс .NET имеет много потоков, работающих в рамках одного процесса и использующих одну и ту же кучу.