Привет, Вы узнаете про машинное обучение, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
машинное обучение, задача регрессии , стекинг, беггинг, бустинг, задача классификации, задача кластеризации, задача уменьшения размерности , задача выявления аномалий , машинное обучение с учителем, машинное обучение без учителя, дерево принятия решений, наивная байесовская классификация, метод наименьших квадратов, логистическая регрессия, метод опорных векторов (svm), метод ансамблей, метод главных компонент (pca), сингулярное разложение, анализ независимых компонент (ica), школы машинного обучения , настоятельно рекомендую прочитать все из категории Машинное обучение.
Основные
школы машинного обучения
машинное обучение (Machine Learning) — подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться. Различают два типа обучения. Обучение по прецедентам, или индуктивное обучение, основано на выявлении общих закономерностей по частным эмпирическим данным.
Поиски Верховного алгоритма сложны, но их оживляет соперничество разных научных школ, действующих в области машинного обучения. Важнейшие из них — символисты, коннекционисты, эволюционисты, байесовцы и аналогисты.
Символизм — поиск логических закономерностей Deision Tree, Rule Indution, Assoiation Rules
Для символистов интеллект сводится к манипулированию символами — так математики решают уравнения, заменяя одни выражения другими
Коннекционизм — искуственные нейронные сети BakPropagation, Deep Belief Nets, Deep Learning
Для коннекционистов обучение — то, чем занимается головной мозг, и поэтому они считают, что этот орган надо воспроизвести путем обратной инженерии
Эволюционизм (генетические алгоритмы ) Geneti Algorithms, Geneti Programming
Эволюционисты верят, что мать учения — естественный отбор
Байеосионизм( оценивание апостериорных распределений ) Naive Bayes, Bayesian Networks, Graphial Models
Байесовцы озабочены прежде всего неопределенностью
Аналогизм (гипотеза непрерывности и компактности)kNN, RBF, SVM, Kernel Regression, Kernel Density Estimation
Для аналогистов ключ к обучению — находить сходства между разными ситуациями и тем самым логически выводить другие сходства
Композиционизм Voting, Boosting, Bagging, Staking, RF, MatrixNet, CatBoost
1.1 Введение
Благодаря машинному обучению программист не обязан писать инструкции, учитывающие все возможные проблемы и содержащие все решения. Вместо этого в компьютер (или отдельную программу) закладывают алгоритм самостоятельного нахождения решений путем комплексного использования статистических данных, из которых выводятся закономерности и на основе которых делаются прогнозы.
Технология машинного обучения на основе анализа данных берет начало в 1950 году, когда начали разрабатывать первые программы для игры в шашки. За прошедшие десятилетий общий принцип не изменился. Зато благодаря взрывному росту вычислительных мощностей компьютеров многократно усложнились закономерности и прогнозы, создаваемые ими, и расширился круг проблем и задач, решаемых с использованием машинного обучения.
Чтобы запустить процесс машинного обучение, для начала необходимо загрузить в компьютер Датасет(некоторое количество исходных данных), на которых алгоритм будет учиться обрабатывать запросы. Например, могут быть фотографии собак и котов, на которых уже есть метки, обозначающие к кому они относятся. После процесса обучения, программа уже сама сможет распознавать собак и котов на новых изображениях без содержания меток. Процесс обучения продолжается и после выданных прогнозов, чем больше данных мы проанализировали программой, тем более точно она распознает нужные изображения.
Благодаря машинному обучению компьютеры учатся распознавать на фотографиях и рисунках не только лица, но и пейзажи, предметы, текст и цифры. Что касается текста, то и здесь не обойтись без машинного обучения: функция проверки грамматики сейчас присутствует в любом текстовом редакторе и даже в телефонах. Причем учитывается не только написание слов, но и контекст, оттенки смысла и другие тонкие лингвистические аспекты. Более того, уже существует программное обеспечение, способное без участия человека писать новостные статьи (на тему экономики и, к примеру, спорта).
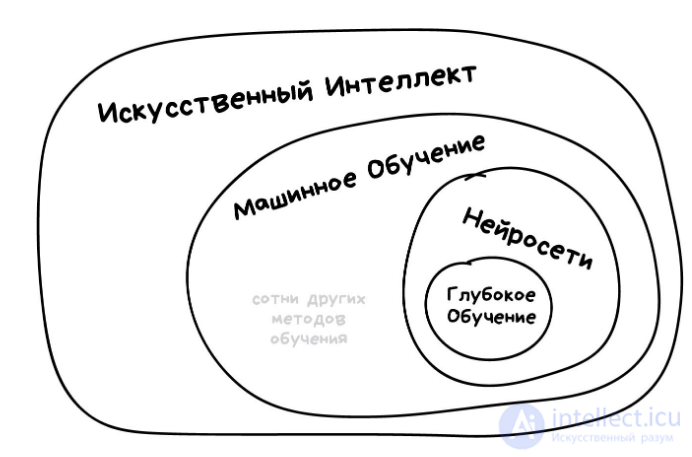
1.2 Типы задач машинного обучения
Все задачи, решаемые с помощью ML, относятся к одной из следующих категорий.
1)
задача регрессии – прогноз на основе выборки объектов с различными признаками. На выходе должно получиться вещественное число (2, 35, 76.454 и др.), к примеру цена квартиры, стоимость ценной бумаги по прошествии полугода, ожидаемый доход магазина на следующий месяц, качество вина при слепом тестировании.
2)
задача классификации – получение категориального ответа на основе набора признаков. Имеет конечное количество ответов (как правило, в формате «да» или «нет»): есть ли на фотографии кот, является ли изображение человеческим лицом, болен ли пациент раком.
3)
задача кластеризации – распределение данных на группы: разделение всех клиентов мобильного оператора по уровню платежеспособности, отнесение космических объектов к той или иной категории (планета, звезда, черная дыра и т. п.).
4)
задача уменьшения размерности – сведение большого числа признаков к меньшему (обычно 2–3) для удобства их последующей визуализации (например, сжатие данных).
5)
задача выявления аномалий – отделение аномалий от стандартных случаев. На первый взгляд она совпадает с задачей классификации, но есть одно существенное отличие: аномалии – явление редкое, и обучающих примеров, на которых можно натаскать машинно обучающуюся модель на выявление таких объектов, либо исчезающе мало, либо просто нет, поэтому методы классификации здесь не работают. На практике такой задачей является, например, выявление мошеннических действий с банковскими картами.
Как определиь какая задача нужна?
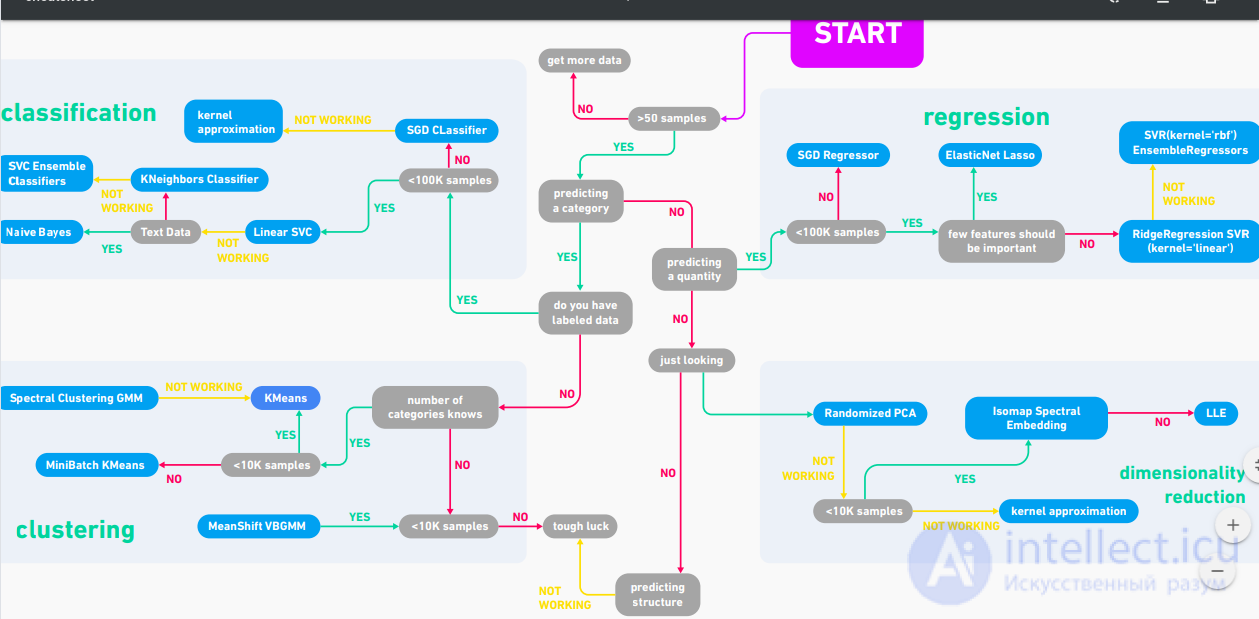
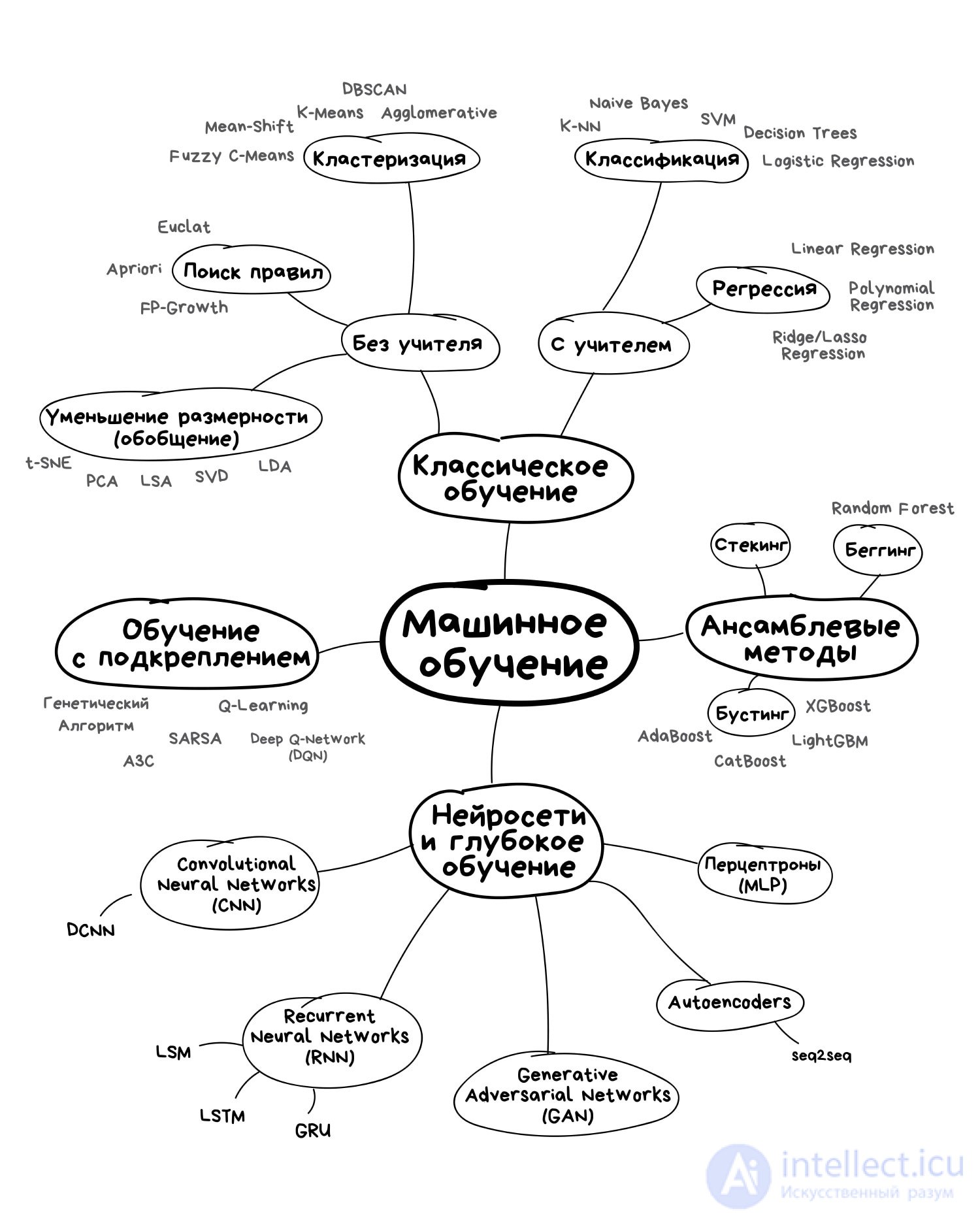
Рисунок Виды машинного обучения
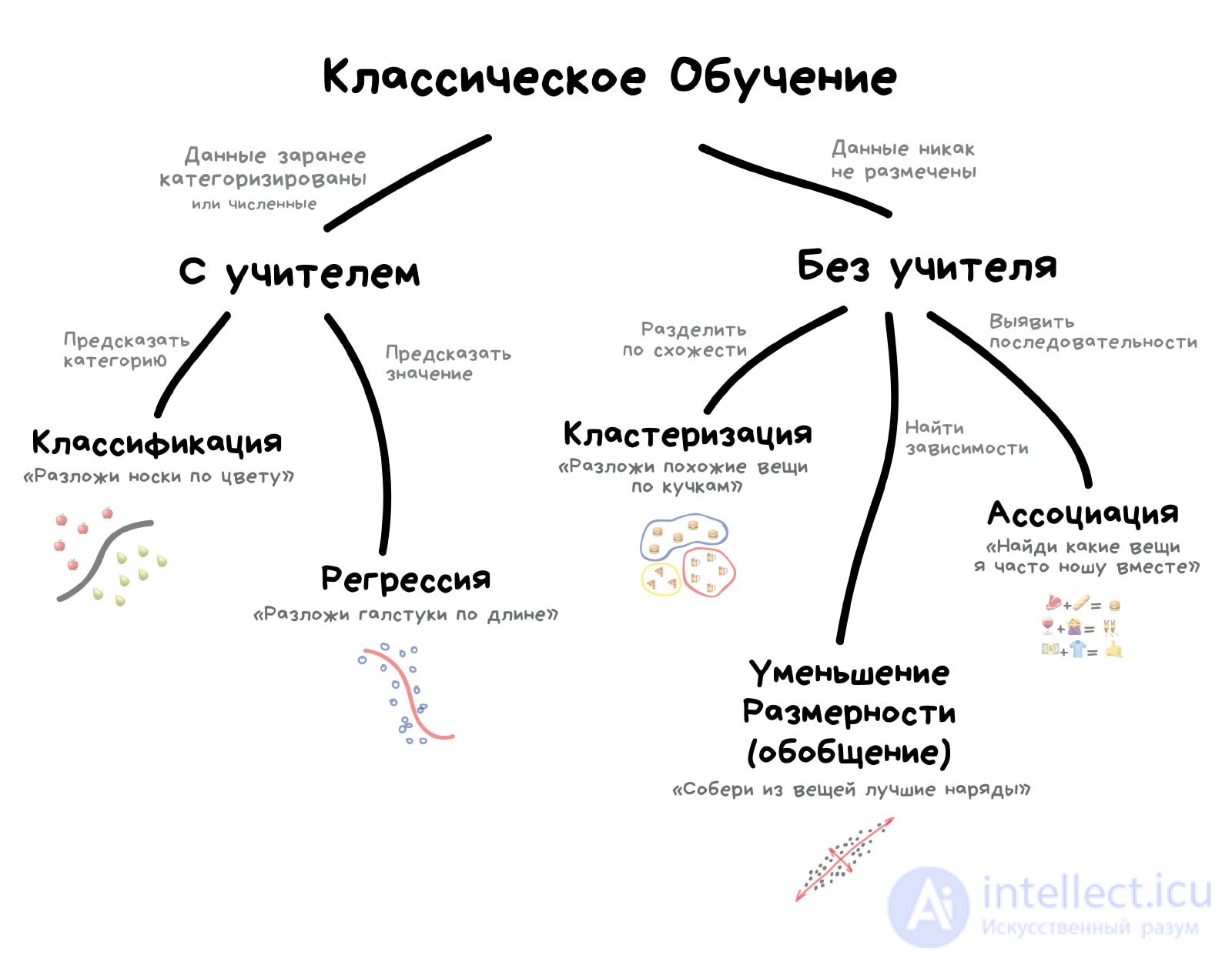
1.3 Основные виды машинного обучения
Основная масса задач, решаемых при помощи методов машинного обучения, относится к двум разным видам: обучение с учителем (supervised learning) либо без него (unsupervised learning). Однако этим учителем вовсе не обязательно является сам программист, который стоит над компьютером и контролирует каждое действие в программе. «Учитель» в терминах машинного обучения – это само вмешательство человека в процесс обработки информации. В обоих видах обучения машине предоставляются исходные данные, которые ей предстоит проанализировать и найти закономерности. Различие лишь в том, что при обучении с учителем есть ряд гипотез, которые необходимо опровергнуть или подтвердить. Эту разницу легко понять на примерах.
машинное обучение с учителем
Предположим, в нашем распоряжении оказались сведения о десяти тысячах московских квартир: площадь, этаж, район, наличие или отсутствие парковки у дома, расстояние от метро, цена квартиры и т. п. Нам необходимо создать модель, предсказывающую рыночную стоимость квартиры по ее параметрам. Это идеальный пример машинного обучения с учителем: у нас есть исходные данные (количество квартир и их свойства, которые называются признаками) и готовый ответ по каждой из квартир – ее стоимость. Программе предстоит решить задачу регрессии.
Еще пример из практики: подтвердить или опровергнуть наличие рака у пациента, зная все его медицинские показатели. Выяснить, является ли входящее письмо спамом, проанализировав его текст. Это все задачи на классификацию.
машинное обучение без учителя
В случае обучения без учителя, когда готовых «правильных ответов» системе не предоставлено, все обстоит еще интереснее. Например, у нас есть информация о весе и росте какого-то количества людей, и эти данные нужно распределить по трем группам, для каждой из которых предстоит пошить рубашки подходящих размеров. Это задача кластеризации. В этом случае предстоит разделить все данные на 3 кластера (но, как правило, такого строгого и единственно возможного деления нет).
Если взять другую ситуацию, когда каждый из объектов в выборке обладает сотней различных признаков, то основной трудностью будет графическое отображение такой выборки. Поэтому количество признаков уменьшают до двух или трех, и становится возможным визуализировать их на плоскости или в 3D. Это – задача уменьшения размерности.

1.4 Основные алгоритмы моделей машинного обучения
1.
дерево принятия решений
Это метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчетом вероятности наступления того или иного события), эффективность, ресурсозатратность.
Для бизнес-процессов это дерево складывается из минимального числа вопросов, предполагающих однозначный ответ — «да» или «нет» . Об этом говорит сайт https://intellect.icu . Последовательно дав ответы на все эти вопросы, мы приходим к правильному выбору. Методологические преимущества дерева принятия решений – в том, что оно структурирует и систематизирует проблему, а итоговое решение принимается на основе логических выводов.
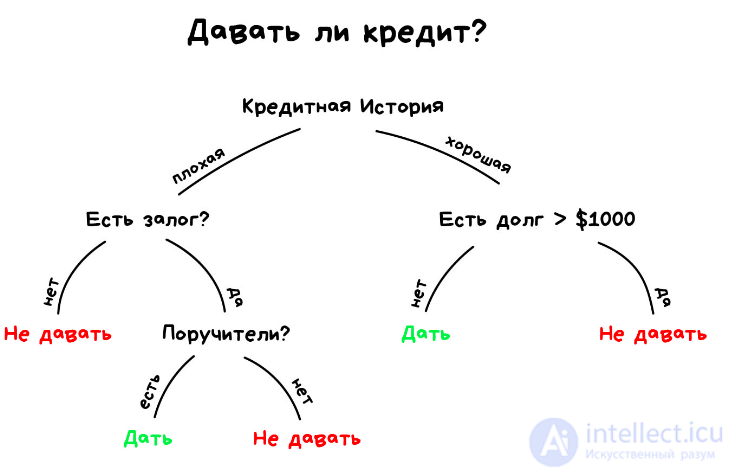
Возьмем другой пример полезной классификации. Вот берете вы кредит в банке. Как банку удостовериться, вернете вы его или нет? Точно никак, но у банка есть тысячи профилей других людей, которые уже брали кредит до вас. Там указан их возраст, образование, должность, уровень зарплаты и главное — кто из них вернул кредит, а с кем возникли проблемы.
Да, все догадались, где здесь данные и какой надо предсказать результат. Обучим машину, найдем закономерности, получим ответ — вопрос не в этом. Проблема в том, что банк не может слепо доверять ответу машины, без объяснений. Вдруг сбой, злые хакеры или бухой админ решил скриптик исправить.
Для этой задачи придумали Деревья Решений. Машина автоматически разделяет все данные по вопросам, ответы на которые «да» или «нет». Вопросы могут быть не совсем адекватными с точки зрения человека, например «зарплата заемщика больше, чем 2300 долларов?», но машина придумывает их так, чтобы на каждом шаге разбиение было самым точным.
Так получается дерево вопросов. Чем выше уровень, тем более общий вопрос. Потом даже можно загнать их аналитикам, и они навыдумывают почему так.
Деревья нашли свою нишу в областях с высокой ответственностью: диагностике, медицине, финансах.
2.
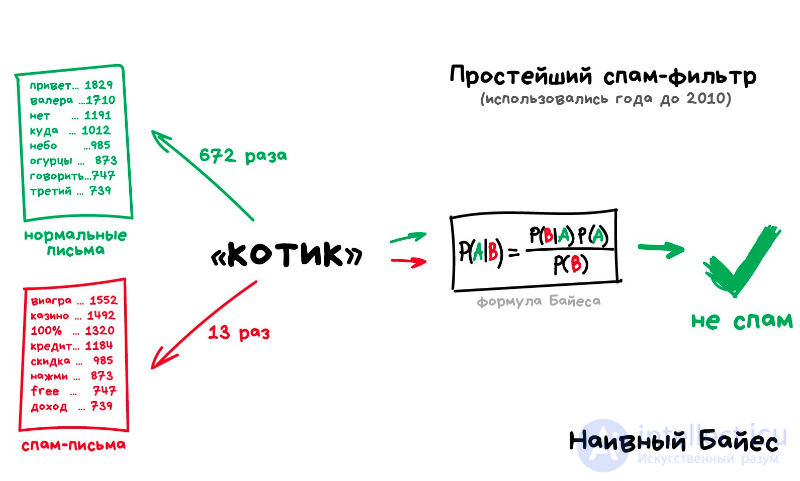
наивная байесовская классификация
Наивные байесовские классификаторы относятся к семейству простых вероятностных классификаторов и берут начало из теоремы Байеса, которая применительно к данному случаю рассматривает функции как независимые (это называется строгим, или наивным, предположением). На практике используется в следующих областях машинного обучения:
- определение спама, приходящего на электронную почту;
- автоматическая привязка новостных статей к тематическим рубрикам;
- выявление эмоциональной окраски текста;
- распознавание лиц и других паттернов на изображениях.
3.
метод наименьших квадратов
Всем, кто хоть немного изучал статистику, знакомо понятие линейной регрессии. К вариантам ее реализации относятся и наименьшие квадраты. Обычно с помощью линейной регрессии решают задачи по подгонке прямой, которая проходит через множество точек. Вот как это делается с помощью метода наименьших квадратов: провести прямую, измерить расстояние от нее до каждой из точек (точки и линию соединяют вертикальными отрезками), получившуюся сумму перенести наверх. В результате та кривая, в которой сумма расстояний будет наименьшей, и есть искомая (эта линия пройдет через точки с нормально распределенным отклонением от истинного значения).
Линейная функция обычно используется при подборе данных для машинного обучения, а метод наименьших квадратов – для сведения к минимуму погрешностей путем создания метрики ошибок.
4. Метод К-средних (K-Means)

Проблема только, как быть с цветами типа Cyan — вот он ближе к зеленому или синему? Тут нам поможет популярный алгоритм кластеризации — Метод К-средних (K-Means). Мы случайным образом бросаем на палитру цветов наши 32 точки, обзывая их центроидами. Все остальные точки относим к ближайшему центроиду от них — получаются как бы созвездия из самых близких цветов. Затем двигаем центроид в центр своего созвездия и повторяем пока центроиды не перестанут двигаться. Кластеры обнаружены, стабильны и их ровно 32 как и надо было.

5.
логистическая регрессия
Логистическая регрессия – это способ определения зависимости между переменными, одна из которых категориально зависима, а другие независимы. Для этого применяется логистическая функция (аккумулятивное логистическое распределение). Практическое значение логистической регрессии заключается в том, что она является мощным статистическим методом предсказания событий, который включает в себя одну или несколько независимых переменных. Это востребовано в следующих ситуациях:
- кредитный скоринг;
- замеры успешности проводимых рекламных кампаний;
- прогноз прибыли с определенного товара;
- оценка вероятности землетрясения в конкретную дату.

5.
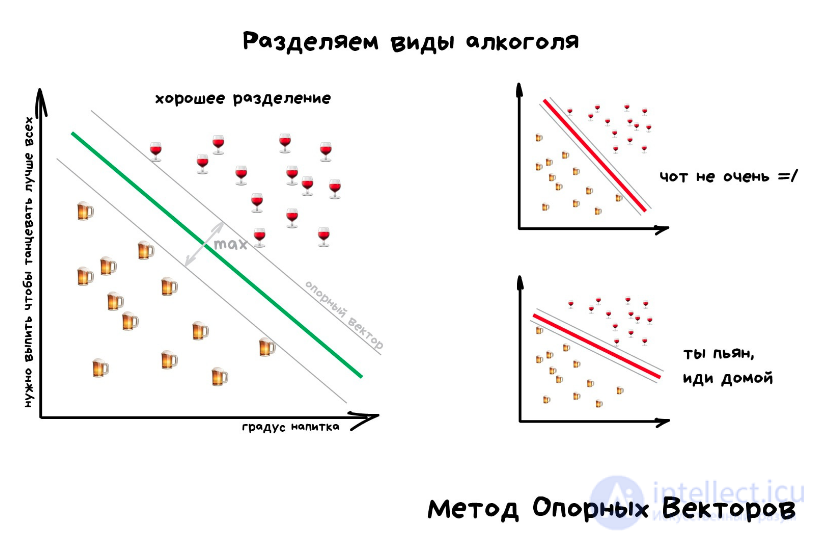
метод опорных векторов (svm)
Это целый набор алгоритмов, необходимых для решения задач на классификацию и регрессионный анализ. Исходя из того что объект, находящийся в N-мерном пространстве, относится к одному из двух классов, метод опорных векторов строит гиперплоскость с мерностью (N – 1), чтобы все объекты оказались в одной из двух групп. На бумаге это можно изобразить так: есть точки двух разных видов, и их можно линейно разделить. Кроме сепарации точек, данный метод генерирует гиперплоскость таким образом, чтобы она была максимально удалена от самой близкой точки каждой группы.
SVM и его модификации помогают решать такие сложные задачи машинного обучения, как сплайсинг ДНК, определение пола человека по фотографии, вывод рекламных баннеров на сайты.
6.
метод ансамблей
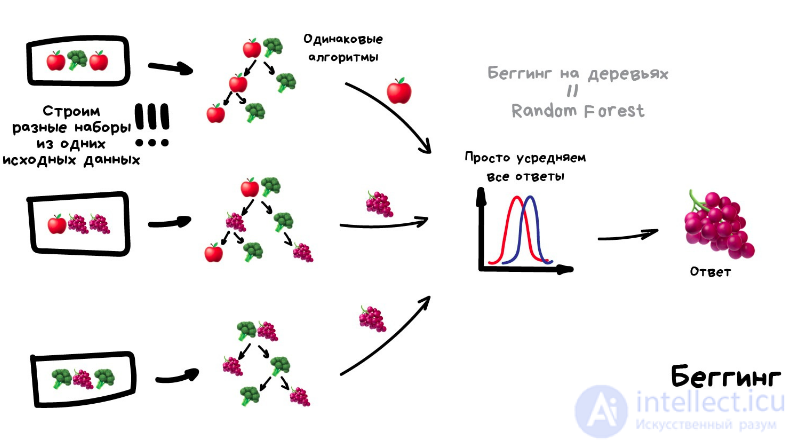
Он базируется на алгоритмах машинного обучения, генерирующих множество классификаторов и разделяющих все объекты из вновь поступающих данных на основе их усреднения или итогов голосования.
Оказывается, если взять несколько не очень эффективных методов обучения и обучить исправлять ошибки друг друга, качество такой системы будет аж сильно выше, чем каждого из методов по отдельности.
Причем даже лучше, когда взятые алгоритмы максимально нестабильны и сильно плавают от входных данных. Поэтому чаще берут Регрессию и Деревья Решений, которым достаточно одной сильной аномалии в данных, чтобы поехала вся модель. А вот Байеса и K-NN не берут никогда — они хоть и тупые, но очень стабильные.
Изначально метод ансамблей был частным случаем байесовского усреднения, но затем усложнился и оброс дополнительными алгоритмами:
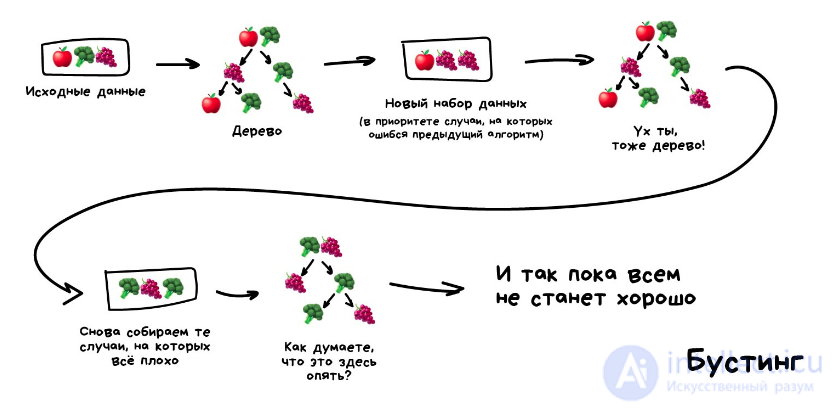
бустинг (boosting) – преобразует слабые модели в сильные посредством формирования ансамбля классификаторов (с математической точки зрения это является улучшающим пересечением);- бэггинг (bagging) – собирает усложненные классификаторы, при этом параллельно обучая базовые (улучшающее объединение);
- корректирование ошибок выходного кодирования.
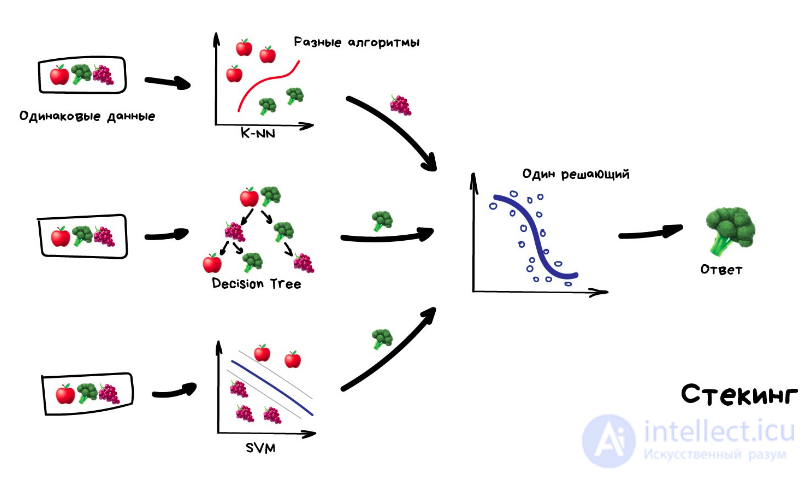
стекинг Обучаем несколько разных алгоритмов и передаем их результаты на вход последнему, который принимает итоговое решение. Типа как девочки сначала опрашивают всех своих подружек, чтобы принять решение встречаться с парнем или нет.
Метод ансамблей – более мощный инструмент по сравнению с отдельно стоящими моделями прогнозирования, поскольку:
- он сводит к минимуму влияние случайностей, усредняя ошибки каждого базового классификатора;
- уменьшает дисперсию, поскольку несколько разных моделей, исходящих из разных гипотез, имеют больше шансов прийти к правильному результату, чем одна отдельно взятая;
- исключает выход за рамки множества: если агрегированная гипотеза оказывается вне множества базовых гипотез, то на этапе формирования комбинированной гипотезы оно расширяется при помощи того или иного способа, и гипотеза уже входит в него.
7. Алгоритмы кластеризации
Кластеризация заключается в распределении множества объектов по категориям так, чтобы в каждой категории – кластере – оказались наиболее схожие между собой элементы.
Кластеризировать объекты можно по разным алгоритмам. Чаще всего используют следующие:
- на основе центра тяжести треугольника;
- на базе подключения;
- сокращения размерности;
- плотности (основанные на пространственной кластеризации);
- вероятностные;
- машинное обучение, в том числе нейронные сети.
Алгоритмы кластеризации используются в биологии (исследование взаимодействия генов в геноме, насчитывающем до нескольких тысяч элементов), социологии (обработка результатов социологических исследований методом Уорда, на выходе дающим кластеры с минимальной дисперсией и примерно одинакового размера) и информационных технологиях.
8.
метод главных компонент (pca)
Метод главных компонент, или PCA, представляет собой статистическую операцию по ортогональному преобразованию, которая имеет своей целью перевод наблюдений за переменными, которые могут быть как-то взаимосвязаны между собой, в набор главных компонент – значений, которые линейно не коррелированы.
Практические задачи, в которых применяется PCA, – визуализация и большинство процедур сжатия, упрощения, минимизации данных для того, чтобы облегчить процесс обучения. Однако метод главных компонент не годится для ситуаций, когда исходные данные слабо упорядочены (то есть все компоненты метода характеризуются высокой дисперсией). Так что его применимость определяется тем, насколько хорошо изучена и описана предметная область.
9.
сингулярное разложение
В линейной алгебре сингулярное разложение, или SVD, определяется как разложение прямоугольной матрицы, состоящей из комплексных или вещественных чисел. Так, матрицу M размерностью [m*n] можно разложить таким образом, что M = UΣV, где U и V будут унитарными матрицами, а Σ – диагональной.
Одним из частных случаев сингулярного разложения является метод главных компонент. Самые первые технологии компьютерного зрения разрабатывались на основе SVD и PCA и работали следующим образом: вначале лица (или другие паттерны, которые предстояло найти) представляли в виде суммы базисных компонент, затем уменьшали их размерность, после чего производили их сопоставление с изображениями из выборки. Современные алгоритмы сингулярного разложения в машинном обучении, конечно, значительно сложнее и изощреннее, чем их предшественники, но суть их в целом нем изменилась.
10.
анализ независимых компонент (ica)
Это один из статистических методов, который выявляет скрытые факторы, оказывающие влияние на случайные величины, сигналы и пр. ICA формирует порождающую модель для баз многофакторных данных. Переменные в модели содержат некоторые скрытые переменные, причем нет никакой информации о правилах их смешивания. Эти скрытые переменные являются независимыми компонентами выборки и считаются негауссовскими сигналами.
В отличие от анализа главных компонент, который связан с данным методом, анализ независимых компонент более эффективен, особенно в тех случаях, когда классические подходы оказываются бессильны. Он обнаруживает скрытые причины явлений и благодаря этому нашел широкое применение в самых различных областях – от астрономии и медицины до распознавания речи, автоматического тестирования и анализа динамики финансовых показателей.
1.5 Примеры применения в реальной жизни. Практические сферы применения
Целью машинного обучения является частичная или полная автоматизация решения сложных профессиональных задач в самых разных областях человеческой деятельности.
Машинное обучение имеет широкий спектр приложений
- Распознавание речи
- Распознавание жестов
- Распознавание рукописного ввода
- Распознавание образов
- Техническая диагностика
- Медицинская диагностика
- Прогнозирование временных рядов
- Биоинформатика
- Обнаружение мошенничества
- Обнаружение спама
- Категоризация документов
- Биржевой технический анализ
- Финансовый надзор (см. Финансовые преступления)
- Кредитный скоринг
- Прогнозирование ухода клиентов
- Хемоинформатика
- Обучение ранжированию в информационном поиске
Сфера применений машинного обучения постоянно расширяется. Повсеместная информатизация приводит к накоплению огромных объемов данных в науке, производстве, бизнесе, транспорте, здравоохранении. Возникающие при этом задачи прогнозирования, управления и принятия решений часто сводятся к обучению по прецедентам. Раньше, когда таких данных не было, эти задачи либо вообще не ставились, либо решались совершенно другими методами.
Пример 1. Диагностика заболеваний
Пациенты в данном случае являются объектами, а признаками – все наблюдающиеся у них симптомы, анамнез, результаты анализов, уже предпринятые лечебные меры (фактически вся история болезни, формализованная и разбитая на отдельные критерии). Некоторые признаки – пол, наличие или отсутствие головной боли, кашля, сыпи и иные – рассматриваются как бинарные. Оценка тяжести состояния (крайне тяжелое, средней тяжести и др.) является порядковым признаком, а многие другие – количественными: объем лекарственного препарата, уровень гемоглобина в крови, показатели артериального давления и пульса, возраст, вес. Собрав информацию о состоянии пациента, содержащую много таких признаков, можно загрузить ее в компьютер и с помощью программы, способной к машинному обучению, решить следующие задачи:
- провести дифференциальную диагностику (определение вида заболевания);
- выбрать наиболее оптимальную стратегию лечения;
- спрогнозировать развитие болезни, ее длительность и исход;
- просчитать риск возможных осложнений;
- выявить синдромы – наборы симптомов, сопутствующие данному заболеванию или нарушению.
Ни один врач не способен обработать весь массив информации по каждому пациенту мгновенно, обобщить большое количество других подобных историй болезни и сразу же выдать четкий результат. Поэтому машинное обучение становится для врачей незаменимым помощником.
Пример 2. Поиск мест залегания полезных ископаемых
В роли признаков здесь выступают сведения, добытые при помощи геологической разведки: наличие на территории местности каких-либо пород (и это будет признаком бинарного типа), их физические и химические свойства (которые раскладываются на ряд количественных и качественных признаков).
Для обучающей выборки берутся 2 вида прецедентов: районы, где точно присутствуют месторождения полезных ископаемых, и районы с похожими характеристиками, где эти ископаемые не были обнаружены. Но добыча редких полезных ископаемых имеет свою специфику: во многих случаях количество признаков значительно превышает число объектов, и методы традиционной статистики плохо подходят для таких ситуаций. Поэтому при машинном обучении акцент делается на обнаружение закономерностей в уже собранном массиве данных. Для этого определяются небольшие и наиболее информативные совокупности признаков, которые максимально показательны для ответа на вопрос исследования – есть в указанной местности то или иное ископаемое или нет. Можно провести аналогию с медициной: у месторождений тоже можно выявить свои синдромы. Ценность применения машинного обучения в этой области заключается в том, что полученные результаты не только носят практический характер, но и представляют серьезный научный интерес для геологов и геофизиков.
Пример 3. Оценка надежности и платежеспособности кандидатов на получение кредитов
С этой задачей ежедневно сталкиваются все банки, занимающиеся выдачей кредитов. Необходимость в автоматизации этого процесса назрела давно, еще в 1960–1970-е годы, когда в США и других странах начался бум кредитных карт.
Лица, запрашивающие у банка заем, – это объекты, а вот признаки будут отличаться в зависимости от того, физическое это лицо или юридическое. Признаковое описание частного лица, претендующего на кредит, формируется на основе данных анкеты, которую оно заполняет. Затем анкета дополняется некоторыми другими сведениями о потенциальном клиенте, которые банк получает по своим каналам. Часть из них относятся к бинарным признакам (пол, наличие телефонного номера), другие — к порядковым (образование, должность), большинство же являются количественными (величина займа, общая сумма задолженностей по другим банкам, возраст, количество членов семьи, доход, трудовой стаж) или номинальными (имя, название фирмы-работодателя, профессия, адрес).
Для машинного обучения составляется выборка, в которую входят кредитополучатели, чья кредитная история известна. Все заемщики делятся на классы, в простейшем случае их 2 – «хорошие» заемщики и «плохие», и положительное решение о выдаче кредита принимается только в пользу «хороших».
Более сложный алгоритм машинного обучения, называемый кредитным скорингом, предусматривает начисление каждому заемщику условных баллов за каждый признак, и решение о предоставлении кредита будет зависеть от суммы набранных баллов. Во время машинного обучения системы кредитного скоринга вначале назначают некоторое количество баллов каждому признаку, а затем определяют условия выдачи займа (срок, процентную ставку и остальные параметры, которые отражаются в кредитном договоре). Но существует также и другой алгоритм обучения системы – на основе прецедентов.
Тесты
1 Выберите верное утверждение.
1.1 Тестовую выборку характеризует ее недоступность в ходе обучения алгоритма(+)
1.2 Для корректного тестирования алгоритма необходимо, чтобы тестовая выборка содержалась в обучающей
1.3 Время работы ноутбука от аккумулятора — это категориальный признак для задачи машинного обучения
1.4 Наиболее близкая к истине оценка работы модели — это ее средний показатель качества на обучающей и тестовой выборках
2 Среди предложенных задач машинного обучения укажите задачи регрессии
Выберите все подходящие ответы из списка
2.1 Поиск “токсичных” комментариев в социальной сети
2.2 Предсказание заработной платы клиента банка(+)
2.3 Поиск мошеннических транзакций
2.4 Алгоритм фильтрации спама
2.5 Предсказание месячного количества осадков(+)
3 Укажите модуль библиотеки sklearn, в котором находится функция train_test_split
Выберите один вариант из списка
3.1 model_selection(+)
3.2 datasets
3.3 neighborspre
3.4 processing
4 Показатель качества работы алгоритма как правило
Выберите один вариант из списка
4.1 Выше на тестовой выборке
4.2 Одинаковый
4.3 Выше на обучающей выборке(+)
4.4 Невозможно определить
5. Чем отличается задачи классификации от задач регрессии?
6. чем отличаются задачи классификации от задач кластеризации?
В общем, в классификации у вас есть набор предопределенных классов и вы хотите знать, к какому классу принадлежит новый объект.
Кластеризация пытается сгруппировать набор объектов и определить, существует ли some взаимосвязь между объектами.
В контексте машинного обучения классификация контролируемого обучения и кластеризация неконтролируемое обучение .
Также посмотрите определения Классификация и Кластеризация .


+ Классификация: вам даются новые данные, вы должны установить для них новую метку.
Например, компания хочет классифицировать своих потенциальных клиентов. Когда приходит новый клиент, они должны определить, является ли это заказчиком, который собирается покупать свою продукцию или нет.
«Когда приходит новый клиент, они должны определить, является ли это заказчиком, который собирается покупать свою продукцию или нет». является лучшим кандидатом на логистическую регрессию. Примером классификации может быть предсказание того, собирается ли покупатель покупать «премиум», «стандартную» или «экономичную» модель. Пример авиакомпании: тренер, тренер с ранним посадкой, тренер с дополнительным местом для ног.Я бы сказал, что «Когда приходит новый клиент, они должны определить, является ли это заказчиком, который собирается покупать свою продукцию или нет». является лучшим кандидатом на логистическую регрессию. Примером классификации может быть предсказание того, собирается ли покупатель покупать «премиум», «стандартную» или «экономичную» модель. Пример авиакомпании: тренер, тренер с ранним посадкой, тренер с дополнительным местом для ног.
+ Кластеризация: вам дается набор транзакций истории, в которых записано, кто что купил.
Используя методы кластеризации, вы можете рассказать сегментацию своих клиентов.
См. также
- Глубокое обучение
- Квантовое машинное обучение
- Искусственный интеллект
- обучение с учителем
- обучение без учителя
- виды нейросетей
- нейросеть
- искуственный нерон
- активное обучение , active learning , машинное обучение , сокращение дисперсии ,
В общем, мой друг ты одолел чтение этой статьи об машинное обучение. Работы в переди у тебя будет много. Смело пишикоментарии, развивайся и счастье окажется в ваших руках.
Надеюсь, что теперь ты понял что такое машинное обучение, задача регрессии , стекинг, беггинг, бустинг, задача классификации, задача кластеризации, задача уменьшения размерности , задача выявления аномалий , машинное обучение с учителем, машинное обучение без учителя, дерево принятия решений, наивная байесовская классификация, метод наименьших квадратов, логистическая регрессия, метод опорных векторов (svm), метод ансамблей, метод главных компонент (pca), сингулярное разложение, анализ независимых компонент (ica), школы машинного обучения
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Машинное обучение
Ответы на вопросы для самопроверки пишите в комментариях, мы проверим, или же задавайте свой вопрос по данной теме.
Категориальные признаки в машинном обучении
Существует несколько способов преобразовать категории в числа, каждый из них имеет свои плюсы и минусы. Выбор метода зависит от типа и смысла ваших данных, мощности множества категорий, алгоритма машинного обучения.
Ниже приведена схема, как выбрать подходящий метод кодирования.

Рассмотрим наиболее популярные методы преобразования категорий в числа.
Самый простой способ – обычная нумерация значений (0, 1, 2, …). У данного подхода есть существенный недостаток. Обычно он ведет к плохому результату так как, алгоритмы начинают учитывать бессмысленную упорядоченность значений признаков. Однако данный метод имеет преимущество с точки зрения памяти.
Метод реализован в классе sklearn.preprocessing.LabelEncoder.

Следующий способ – dummy-кодирование, также называемое — one-hot. Суть заключается в создании дополнительных N признаков (столбцов), где N – количество уникальных категорий. Новые признаки принимают значения 0 или 1 в зависимости от принадлежности к категории. One-hot encoder значительно увеличивает объем данных, что делает его неэффективным с точки зрения памяти, частично эту проблему решает применение разреженных матриц. Метод реализован в классе sklearn.preprocessing.OneHotEncoder.

Далее рассмотрим метод среднего кодирования (Mean/Target Encoding). Метод предполагает кодирование категорий средним арифметическим от суммы целевых меток (Target). Вариация этого метода рассматривалась нами ранее в задаче предсказания спроса, вместо целевых меток, мы брали другой признак — цену на товар, таким образом категории товаров упорядочивались их дороговизной. Однако, при кодировании средним по Target велика вероятность переобучения модели, эту проблему поможет решить регуляризация.
Простейший вариант Mean Encoding представлен ниже.

Подводя итоги, напомню, что методов кодирования существует гораздо больше, и среди них нет универсальных. Выбирая метод, стоит отталкиваться от ваших данных, мощности множества категорий и алгоритма машинного обучения.
Источник
Введение в машинное обучение
1.1 Введение
Благодаря машинному обучению программист не обязан писать инструкции, учитывающие все возможные проблемы и содержащие все решения. Вместо этого в компьютер (или отдельную программу) закладывают алгоритм самостоятельного нахождения решений путём комплексного использования статистических данных, из которых выводятся закономерности и на основе которых делаются прогнозы.
Технология машинного обучения на основе анализа данных берёт начало в 1950 году, когда начали разрабатывать первые программы для игры в шашки. За прошедшие десятилетий общий принцип не изменился. Зато благодаря взрывному росту вычислительных мощностей компьютеров многократно усложнились закономерности и прогнозы, создаваемые ими, и расширился круг проблем и задач, решаемых с использованием машинного обучения.
Чтобы запустить процесс машинного обучение, для начала необходимо загрузить в компьютер Датасет(некоторое количество исходных данных), на которых алгоритм будет учиться обрабатывать запросы. Например, могут быть фотографии собак и котов, на которых уже есть метки, обозначающие к кому они относятся. После процесса обучения, программа уже сама сможет распознавать собак и котов на новых изображениях без содержания меток. Процесс обучения продолжается и после выданных прогнозов, чем больше данных мы проанализировали программой, тем более точно она распознает нужные изображения.
Благодаря машинному обучению компьютеры учатся распознавать на фотографиях и рисунках не только лица, но и пейзажи, предметы, текст и цифры. Что касается текста, то и здесь не обойтись без машинного обучения: функция проверки грамматики сейчас присутствует в любом текстовом редакторе и даже в телефонах. Причем учитывается не только написание слов, но и контекст, оттенки смысла и другие тонкие лингвистические аспекты. Более того, уже существует программное обеспечение, способное без участия человека писать новостные статьи (на тему экономики и, к примеру, спорта).
1.2 Типы задач машинного обучения
Все задачи, решаемые с помощью ML, относятся к одной из следующих категорий.
1)Задача регрессии – прогноз на основе выборки объектов с различными признаками. На выходе должно получиться вещественное число (2, 35, 76.454 и др.), к примеру цена квартиры, стоимость ценной бумаги по прошествии полугода, ожидаемый доход магазина на следующий месяц, качество вина при слепом тестировании.
2)Задача классификации – получение категориального ответа на основе набора признаков. Имеет конечное количество ответов (как правило, в формате «да» или «нет»): есть ли на фотографии кот, является ли изображение человеческим лицом, болен ли пациент раком.
3)Задача кластеризации – распределение данных на группы: разделение всех клиентов мобильного оператора по уровню платёжеспособности, отнесение космических объектов к той или иной категории (планета, звёзда, чёрная дыра и т. п.).
4)Задача уменьшения размерности – сведение большого числа признаков к меньшему (обычно 2–3) для удобства их последующей визуализации (например, сжатие данных).
5)Задача выявления аномалий – отделение аномалий от стандартных случаев. На первый взгляд она совпадает с задачей классификации, но есть одно существенное отличие: аномалии – явление редкое, и обучающих примеров, на которых можно натаскать машинно обучающуюся модель на выявление таких объектов, либо исчезающе мало, либо просто нет, поэтому методы классификации здесь не работают. На практике такой задачей является, например, выявление мошеннических действий с банковскими картами.
1.3 Основные виды машинного обучения
Основная масса задач, решаемых при помощи методов машинного обучения, относится к двум разным видам: обучение с учителем (supervised learning) либо без него (unsupervised learning). Однако этим учителем вовсе не обязательно является сам программист, который стоит над компьютером и контролирует каждое действие в программе. «Учитель» в терминах машинного обучения – это само вмешательство человека в процесс обработки информации. В обоих видах обучения машине предоставляются исходные данные, которые ей предстоит проанализировать и найти закономерности. Различие лишь в том, что при обучении с учителем есть ряд гипотез, которые необходимо опровергнуть или подтвердить. Эту разницу легко понять на примерах.
Машинное обучение с учителем
Предположим, в нашем распоряжении оказались сведения о десяти тысячах московских квартир: площадь, этаж, район, наличие или отсутствие парковки у дома, расстояние от метро, цена квартиры и т. п. Нам необходимо создать модель, предсказывающую рыночную стоимость квартиры по её параметрам. Это идеальный пример машинного обучения с учителем: у нас есть исходные данные (количество квартир и их свойства, которые называются признаками) и готовый ответ по каждой из квартир – её стоимость. Программе предстоит решить задачу регрессии.
Ещё пример из практики: подтвердить или опровергнуть наличие рака у пациента, зная все его медицинские показатели. Выяснить, является ли входящее письмо спамом, проанализировав его текст. Это всё задачи на классификацию.
Машинное обучение без учителя
В случае обучения без учителя, когда готовых «правильных ответов» системе не предоставлено, всё обстоит ещё интереснее. Например, у нас есть информация о весе и росте какого-то количества людей, и эти данные нужно распределить по трём группам, для каждой из которых предстоит пошить рубашки подходящих размеров. Это задача кластеризации. В этом случае предстоит разделить все данные на 3 кластера (но, как правило, такого строгого и единственно возможного деления нет).
Если взять другую ситуацию, когда каждый из объектов в выборке обладает сотней различных признаков, то основной трудностью будет графическое отображение такой выборки. Поэтому количество признаков уменьшают до двух или трёх, и становится возможным визуализировать их на плоскости или в 3D. Это – задача уменьшения размерности.
1.4 Основные алгоритмы моделей машинного обучения
1. Дерево принятия решений
Это метод поддержки принятия решений, основанный на использовании древовидного графа: модели принятия решений, которая учитывает их потенциальные последствия (с расчётом вероятности наступления того или иного события), эффективность, ресурсозатратность.
Для бизнес-процессов это дерево складывается из минимального числа вопросов, предполагающих однозначный ответ — «да» или «нет». Последовательно дав ответы на все эти вопросы, мы приходим к правильному выбору. Методологические преимущества дерева принятия решений – в том, что оно структурирует и систематизирует проблему, а итоговое решение принимается на основе логических выводов.
2. Наивная байесовская классификация
Наивные байесовские классификаторы относятся к семейству простых вероятностных классификаторов и берут начало из теоремы Байеса, которая применительно к данному случаю рассматривает функции как независимые (это называется строгим, или наивным, предположением). На практике используется в следующих областях машинного обучения:
- определение спама, приходящего на электронную почту;
- автоматическая привязка новостных статей к тематическим рубрикам;
- выявление эмоциональной окраски текста;
- распознавание лиц и других паттернов на изображениях.
3. Метод наименьших квадратов
Всем, кто хоть немного изучал статистику, знакомо понятие линейной регрессии. К вариантам её реализации относятся и наименьшие квадраты. Обычно с помощью линейной регрессии решают задачи по подгонке прямой, которая проходит через множество точек. Вот как это делается с помощью метода наименьших квадратов: провести прямую, измерить расстояние от неё до каждой из точек (точки и линию соединяют вертикальными отрезками), получившуюся сумму перенести наверх. В результате та кривая, в которой сумма расстояний будет наименьшей, и есть искомая (эта линия пройдёт через точки с нормально распределённым отклонением от истинного значения).
Линейная функция обычно используется при подборе данных для машинного обучения, а метод наименьших квадратов – для сведения к минимуму погрешностей путем создания метрики ошибок.
4. Логистическая регрессия
Логистическая регрессия – это способ определения зависимости между переменными, одна из которых категориально зависима, а другие независимы. Для этого применяется логистическая функция (аккумулятивное логистическое распределение). Практическое значение логистической регрессии заключается в том, что она является мощным статистическим методом предсказания событий, который включает в себя одну или несколько независимых переменных. Это востребовано в следующих ситуациях:
- кредитный скоринг;
- замеры успешности проводимых рекламных кампаний;
- прогноз прибыли с определённого товара;
- оценка вероятности землетрясения в конкретную дату.
5. Метод опорных векторов (SVM)
Это целый набор алгоритмов, необходимых для решения задач на классификацию и регрессионный анализ. Исходя из того что объект, находящийся в N-мерном пространстве, относится к одному из двух классов, метод опорных векторов строит гиперплоскость с мерностью (N – 1), чтобы все объекты оказались в одной из двух групп. На бумаге это можно изобразить так: есть точки двух разных видов, и их можно линейно разделить. Кроме сепарации точек, данный метод генерирует гиперплоскость таким образом, чтобы она была максимально удалена от самой близкой точки каждой группы.
SVM и его модификации помогают решать такие сложные задачи машинного обучения, как сплайсинг ДНК, определение пола человека по фотографии, вывод рекламных баннеров на сайты.
6. Метод ансамблей
Он базируется на алгоритмах машинного обучения, генерирующих множество классификаторов и разделяющих все объекты из вновь поступающих данных на основе их усреднения или итогов голосования. Изначально метод ансамблей был частным случаем байесовского усреднения, но затем усложнился и оброс дополнительными алгоритмами:
- бустинг (boosting) – преобразует слабые модели в сильные посредством формирования ансамбля классификаторов (с математической точки зрения это является улучшающим пересечением);
- бэггинг (bagging) – собирает усложнённые классификаторы, при этом параллельно обучая базовые (улучшающее объединение);
- корректирование ошибок выходного кодирования.
Метод ансамблей – более мощный инструмент по сравнению с отдельно стоящими моделями прогнозирования, поскольку:
- он сводит к минимуму влияние случайностей, усредняя ошибки каждого базового классификатора;
- уменьшает дисперсию, поскольку несколько разных моделей, исходящих из разных гипотез, имеют больше шансов прийти к правильному результату, чем одна отдельно взятая;
- исключает выход за рамки множества: если агрегированная гипотеза оказывается вне множества базовых гипотез, то на этапе формирования комбинированной гипотезы оно расширяется при помощи того или иного способа, и гипотеза уже входит в него.
7. Алгоритмы кластеризации
Кластеризация заключается в распределении множества объектов по категориям так, чтобы в каждой категории – кластере – оказались наиболее схожие между собой элементы.
Кластеризировать объекты можно по разным алгоритмам. Чаще всего используют следующие:
- на основе центра тяжести треугольника;
- на базе подключения;
- сокращения размерности;
- плотности (основанные на пространственной кластеризации);
- вероятностные;
- машинное обучение, в том числе нейронные сети.
Алгоритмы кластеризации используются в биологии (исследование взаимодействия генов в геноме, насчитывающем до нескольких тысяч элементов), социологии (обработка результатов социологических исследований методом Уорда, на выходе дающим кластеры с минимальной дисперсией и примерно одинакового размера) и информационных технологиях.
8. Метод главных компонент (PCA)
Метод главных компонент, или PCA, представляет собой статистическую операцию по ортогональному преобразованию, которая имеет своей целью перевод наблюдений за переменными, которые могут быть как-то взаимосвязаны между собой, в набор главных компонент – значений, которые линейно не коррелированы.
Практические задачи, в которых применяется PCA, – визуализация и большинство процедур сжатия, упрощения, минимизации данных для того, чтобы облегчить процесс обучения. Однако метод главных компонент не годится для ситуаций, когда исходные данные слабо упорядочены (то есть все компоненты метода характеризуются высокой дисперсией). Так что его применимость определяется тем, насколько хорошо изучена и описана предметная область.
9. Сингулярное разложение
В линейной алгебре сингулярное разложение, или SVD, определяется как разложение прямоугольной матрицы, состоящей из комплексных или вещественных чисел. Так, матрицу M размерностью [m*n] можно разложить таким образом, что M = UΣV, где U и V будут унитарными матрицами, а Σ – диагональной.
Одним из частных случаев сингулярного разложения является метод главных компонент. Самые первые технологии компьютерного зрения разрабатывались на основе SVD и PCA и работали следующим образом: вначале лица (или другие паттерны, которые предстояло найти) представляли в виде суммы базисных компонент, затем уменьшали их размерность, после чего производили их сопоставление с изображениями из выборки. Современные алгоритмы сингулярного разложения в машинном обучении, конечно, значительно сложнее и изощрённее, чем их предшественники, но суть их в целом нем изменилась.
10. Анализ независимых компонент (ICA)
Это один из статистических методов, который выявляет скрытые факторы, оказывающие влияние на случайные величины, сигналы и пр. ICA формирует порождающую модель для баз многофакторных данных. Переменные в модели содержат некоторые скрытые переменные, причем нет никакой информации о правилах их смешивания. Эти скрытые переменные являются независимыми компонентами выборки и считаются негауссовскими сигналами.
В отличие от анализа главных компонент, который связан с данным методом, анализ независимых компонент более эффективен, особенно в тех случаях, когда классические подходы оказываются бессильны. Он обнаруживает скрытые причины явлений и благодаря этому нашёл широкое применение в самых различных областях – от астрономии и медицины до распознавания речи, автоматического тестирования и анализа динамики финансовых показателей.
1.5 Примеры применения в реальной жизни
Пример 1. Диагностика заболеваний
Пациенты в данном случае являются объектами, а признаками – все наблюдающиеся у них симптомы, анамнез, результаты анализов, уже предпринятые лечебные меры (фактически вся история болезни, формализованная и разбитая на отдельные критерии). Некоторые признаки – пол, наличие или отсутствие головной боли, кашля, сыпи и иные – рассматриваются как бинарные. Оценка тяжести состояния (крайне тяжёлое, средней тяжести и др.) является порядковым признаком, а многие другие – количественными: объём лекарственного препарата, уровень гемоглобина в крови, показатели артериального давления и пульса, возраст, вес. Собрав информацию о состоянии пациента, содержащую много таких признаков, можно загрузить её в компьютер и с помощью программы, способной к машинному обучению, решить следующие задачи:
- провести дифференциальную диагностику (определение вида заболевания);
- выбрать наиболее оптимальную стратегию лечения;
- спрогнозировать развитие болезни, её длительность и исход;
- просчитать риск возможных осложнений;
- выявить синдромы – наборы симптомов, сопутствующие данному заболеванию или нарушению.
Ни один врач не способен обработать весь массив информации по каждому пациенту мгновенно, обобщить большое количество других подобных историй болезни и сразу же выдать чёткий результат. Поэтому машинное обучение становится для врачей незаменимым помощником.
Пример 2. Поиск мест залегания полезных ископаемых
В роли признаков здесь выступают сведения, добытые при помощи геологической разведки: наличие на территории местности каких-либо пород (и это будет признаком бинарного типа), их физические и химические свойства (которые раскладываются на ряд количественных и качественных признаков).
Для обучающей выборки берутся 2 вида прецедентов: районы, где точно присутствуют месторождения полезных ископаемых, и районы с похожими характеристиками, где эти ископаемые не были обнаружены. Но добыча редких полезных ископаемых имеет свою специфику: во многих случаях количество признаков значительно превышает число объектов, и методы традиционной статистики плохо подходят для таких ситуаций. Поэтому при машинном обучении акцент делается на обнаружение закономерностей в уже собранном массиве данных. Для этого определяются небольшие и наиболее информативные совокупности признаков, которые максимально показательны для ответа на вопрос исследования – есть в указанной местности то или иное ископаемое или нет. Можно провести аналогию с медициной: у месторождений тоже можно выявить свои синдромы. Ценность применения машинного обучения в этой области заключается в том, что полученные результаты не только носят практический характер, но и представляют серьёзный научный интерес для геологов и геофизиков.
Пример 3. Оценка надёжности и платёжеспособности кандидатов на получение кредитов
С этой задачей ежедневно сталкиваются все банки, занимающиеся выдачей кредитов. Необходимость в автоматизации этого процесса назрела давно, ещё в 1960–1970-е годы, когда в США и других странах начался бум кредитных карт.
Лица, запрашивающие у банка заём, – это объекты, а вот признаки будут отличаться в зависимости от того, физическое это лицо или юридическое. Признаковое описание частного лица, претендующего на кредит, формируется на основе данных анкеты, которую оно заполняет. Затем анкета дополняется некоторыми другими сведениями о потенциальном клиенте, которые банк получает по своим каналам. Часть из них относятся к бинарным признакам (пол, наличие телефонного номера), другие — к порядковым (образование, должность), большинство же являются количественными (величина займа, общая сумма задолженностей по другим банкам, возраст, количество членов семьи, доход, трудовой стаж) или номинальными (имя, название фирмы-работодателя, профессия, адрес).
Для машинного обучения составляется выборка, в которую входят кредитополучатели, чья кредитная история известна. Все заёмщики делятся на классы, в простейшем случае их 2 – «хорошие» заёмщики и «плохие», и положительное решение о выдаче кредита принимается только в пользу «хороших».
Более сложный алгоритм машинного обучения, называемый кредитным скорингом, предусматривает начисление каждому заёмщику условных баллов за каждый признак, и решение о предоставлении кредита будет зависеть от суммы набранных баллов. Во время машинного обучения системы кредитного скоринга вначале назначают некоторое количество баллов каждому признаку, а затем определяют условия выдачи займа (срок, процентную ставку и остальные параметры, которые отражаются в кредитном договоре). Но существует также и другой алгоритм обучения системы – на основе прецедентов.
Источник
Предварительный анализ и обработка данных
82 мин на чтение
(106.554 символов)
До сих пор мы предполагали, что датасет для машинного обучения уже имеется и удовлетворяет всем необходимым условиям, представлен в нужной нам форме, не имеет ошибок и аномалий. Но на практике вы не встретите таких идеальных данных. Как же подготовить данные для машинного обучения? В этом разделе мы ответим на вопросы, связанные со сбором, анализом и предварительной обработкой данных.
Еще в самом начале книги мы говорили о том, что в машинном обучении самый главный и критичный компонент — сами данные, на которых проводится обучение. Качество данных напрямую влияет на эффективность и надежность получаемых моделей. Поэтому значительная часть работы аналитика — это сбор, очистка, анализ и улучшение данных. В реальных проектах на это уходит до 80% всего времени, затраченного на проект. И лишь оставшиеся 20% — это обучение и выбор моделей, диагностика и повышение их эффективности.
Конечно, работа с данными предваряет непосредственно моделирование. Поэтому во многих курсах с этого как раз начинают. Но как показывает опыт преподавания машинного обучения, очень сложно понять некоторые аспекты, важные для процесса предварительной обработки данных, без понимания того, для чего эти данные будут использоваться, каковы особенности разных моделей, то есть тех тем, которые мы рассматривали в предыдущих главах. Именно поэтому в этой главе ма познакомимся с процессами и методами, которые предшествуют построению моделей машинного обучения. Здесь мы поговорим о сборе, анализе и обработке данных для моделирования.
Надо сказать, что мы не сможем описать все многообразие методов анализа данных. Здесь мы поговорим именно про подготовку данных для машинного обучения и про типичные задачи, которые надо решить для этого, главные вопросы, на которые нужно ответить. Но анализ данных в широком смысле гораздо обширнее и глубже этого, это целая отдельная дисциплина, основанная на математической статистике, численных методах и алгоритмах. Конечно, в первую очередь данные нужно собрать, а для этого нужно понять, какие данные нужны для решения конкретной задачи, определить требования к ним. Так что начнем мы с самого первого шага — сбора данных.
Сбор данных для обучения
Понятие чистых данных
А что вообще значит “качество данных”? В чем оно измеряется и для чего нужно? И в какой форме данные нужно иметь для начала их использования в машинном обучении? В этой главе мы рассмотрим требования, которым данные должны удовлетворять для того, чтобы считаться “хорошими” и подходить для машинного обучения.
В первую очередь необходимо зафиксировать, в какой форме собираются и хранятся данные для машинного обучения. Многое их этого мы уже видели и на примерах, и немного определяли математически, но сейчас пора явно сформулировать требования к представлению данных и их структуре. Обработка и анализ неструктурированной информации — это отдельная тема, которой мы не будем касаться. Для классического машинного обучения данные должны иметь вполне определенную структуру — чаще всего табличную.
Датасет — набор данных для машинного обучения — состоит из описания некоторого конечного множества объектов, экспериментов и измерений. Так как машинное обучение не привязано к какой-то определенной предметной области, данные могут описывать все, что угодно. Объекты недвижимости, определенных людей, финансовые транзакции, фотографии каких-то объектов, данные с телеметрии спутников. Но главное — что эта информация описывает набор каких-то отдельных объектов реального мира, элементарных сущностей той предметной области, которую мы моделируем. Еще эти объекты называют точками данных, или строками, так как в таблицах они всегда отображаются именно по строкам.
У каждого из этих объектов есть некоторые характеристики, которые описаны в датасете. Для всех объектов набор этих характеристик должен быть одинаковый. Эти характеристики реальных объектов называются атрибутами или колонками, опять же потому, что в табличном представлении они располагаются по столбцам. Иногда они же называются переменными, либо факторами. Соответственно, на пересечении столбца и строки находятся значения соответствующих характеристик определенного объекта.

По сути такое представление информации очень похоже на реляционную форму, которая используется в базах данных. Главное различие в том, что в машинном обучении датасет представляется в виде единой таблицы, а не набора связанных, как в реляционных базах данных. Такая таблица должна иметь внутреннюю согласованность, то есть описывать один вид наблюдений или экспериментов. Причем внутренняя согласованность должна проявляться и в содержании данных. В датасете должны использоваться одни обозначения, сокращения, форматы. Мало толку от таблицы, в которой часть объектов измерена в метрах, а остальные в футах. Если мы анализируем экономические показатели, то агрегаты должны измеряться за одни и те же периоды и так далее. Таких маленьких нюансов в данных может быть очень много и для их отслеживания необходимо знание предметной области.
Если датасет удовлетворяет этим базовым требованиям, то такие данные можно называть чистыми (tidy data). На практике к базовым добавляются еще два требований, которые почти всегда нужно соблюдать, иначе большинство моделей машинного обучения не смогут работать с такими данными. Во-первых, данные должны быть выражены в численном виде. Про то, как преобразовать данные в численный вид мы поговорим чуть позже, в разделе про предобработку данных. Это требование объясняется тем, что большинство моделей основаны на численных функциях и математических преобразованиях. Поэтому на вход надо подавать набор численных значений, или вектор.
Во-вторых, в данных не должно быть отсутствующих значений, то есть пропусков. Все “ячейки” таблицы должны быть заполнены. Это тоже обосновано применением математических моделей, которые не умеют работать с отсутствием значения. Заполнению пропущенных значений тоже посвящена большая часть предобработки данных. Вообще, приведение данных к такому чистому виду — это основная цель предварительной обработки данных как этапа проекта по машинному обучению.
Чистые данные — это набор данных, который представлен в форме реляционной таблицы, все значения в которой выражены числом, не имеет пропущенных значений, имеет внутреннюю согласованность. Такие данные формально можно применять для использования в любых моделей машинного обучения.
Конечно, на практике бывают и исключения из этих правил. Существуют специальные области, в которых данные представляются в особой структуре и в особых форматах. Типичный пример — временные ряды. Это ряд чисел, которые характеризуют динамику одного и того же показателя во времени. То есть датасет в таком случае представляется не как набор взаимонезависимых объектов. Элементы в таком временном ряду имеют строгую последовательность, которую нельзя нарушать. В предыдущей главе мы уже говорили, что временные ряды нельзя разбивать на обучающую и тестовую выборки случайным образом. Точно также следует учитывать особенности природы исследуемых данных и в других случаях.
Еще один распространенный пример — нестандартные форматы данных. В машинном обучении часто встречается ситуация, когда отдельная точка данных представляет собой не численный вектор, а, например, картинку, текст, видеофрагмент или аудиоданные. Но и в таком случае, для моделирования эти данные преобразуются к численным векторам. Этот процесс называется векторизацией. Так можно векторизовать текст, для этого есть много разных методов. Картинки, очень естественно представляются как массив яркости пикселей, подобным же образом преобразуются и другие типы данных. Просто преобразование данных в этом случае не так тривиально и может быть предметом отдельного исследования.
Надо отметить, что в подобных задачах алгоритм векторизации данных может быть даже более важным для моделирования, чем сами модели машинного обучения. Так, в обработке текстов на естественных языках, существуют разные методы преобразования текста в вектор. Самые простые подсчитывают количество и наличие слов в тексте, более продвинутые — учитывают грамматическую форму и смысл слов и предложений текста. Так вот, для совершенно разных задач обработки текстов — будь то машинный перевод или вопрос-ответные системы, гораздо большее влияние на эффективность модели оказываем именно метод векторизации. Поэтому создание так называемых глубоких текстовых моделей, которые позволяют преобразовать текст в вектор так, чтобы в этом векторе сохранилась максимум информация о смысле текста, привело к одновременному прогрессу во многих прикладных задачах.
Вообще, для анализа такой специфической информации существуют и специальные методы и модели. Например, для анализа графической информации традиционно применяются так называемые алгоритмы сверток, которые учитывают пространственное расположение информации на картинке. А анализ временных рядов — это вообще отдельная дисциплина в математической статистике, эконометрике и анализе данных. Но мы в этой книге сконцентрируемся на анализе более традиционной, табличной формы данных. Тем более, что она наиболее распространена в прикладных экономических, производственных и технических задачах.
Итак, мы сформулировали основные требования к форме предоставления данных, которые мы можем использовать для моделирования. В следующих главах мы поговорим о том, как привести данные в соответствие с этими требованиями чистоты — то есть об очистке данных. Здесь мы говорим только о формальных вещах, не касаясь смысла данных. А это тоже важная часть — данные должны подходить под решаемую задачу, быть релевантными изучаемой предметной области. Но это очень индивидуально для каждой прикладной задачи.
Выводы:
- Датасет — это набор данных, используемый для обучения моделей. Данные представлены в виде единой таблицы.
- Объекты — это элементарные сущности, которые мы изучаем, объекты реального мира, измерения, наблюдения. В датасете представляются строками.
- Каждый объект характеризуется набором атрибутов. В датасете атрибуты представляются столбцами.
- Каждая таблица, файл представляет собой данные об одном виде наблюдений или экспериментов и должна иметь внутреннюю согласованность.
- Дополнительно: Все данные должны быть выражены в численном виде.
- Дополнительно: В данных не должно быть отсутствующих (пропущенных) значений.
- Существуют специальные структуры данных и форматы.
Оценка источников и объемов данных
А откуда данные вообще берутся? Как создать собственный датасет или воспользоваться готовым? На эти вопросы надо ответить вначале любого проекта по машинному обучению, которое невозможно без данных. В этой главе поговорим о самом первом этапе решения прикладной задачи при помощи машинного обучения — сбора данных.
Теперь, когда мы понимаем, в какой форме нам нужных данные пора задуматься о том, сколько их требуется и откуда их брать. Оценка необходимых объемов данных — очень сложная задача. Тем более, что этот вопрос очень напрашивается перед началом работы — сколько именно данных нужно для эффективного моделирования. Но ответить на него очень сложно, ведь алгоритмы машинного обучения не предъявляют требований к размеру выборки. Самый универсальный ответ, который можно использовать — чем больше, тем лучше. Мы уже знакомы с недо- и переобучением моделей, и поэтому знаем, что добавление большего количества точек данных может помочь в первом случае, но при этом во втором тоже не пойдет во вред. Поэтому если заранее не знать, то добавление данных — в любом случае не повредит. Но обычно нам доступны лишь ограниченные данные, а если нам нужно больше — придется прилагать определенные усилия по их поиску, добычи или генерации. Поэтому вопрос необходимого объема — не праздный. Если собрать маленькую выборку может быть относительно просто и быстро, то увеличить ее в сто раз может стоить очень дорого, как по ресурсам, так и по времени.
Под объемом датасета мы будем понимать количество точек в данных, а не объем информации в байтах. Количество точек или объектов — это ключевая характеристика наборов данных для машинного обучения.
В оценке требуемого объема данных следует в первую очередь ориентироваться на порядок сложности задачи, которую мы пытаемся решить. Чем задача сложнее, тем больше данных нам потребуется. Это интуитивно понятно — для описания принципов решения сложной задачи может понадобится больше примеров, чем для простой, чтобы модель смогла обобщить эти примеры и выдавать приемлемый результат. Проблема в том, что порядок сложности задачи тоже нелегко определить заранее. Тут поможет только сравнительный анализ. Прикладные задачи машинного обучения можно сравнивать между собой по сути моделируемого вопроса. Например, известно, что задача машинного перевода — достаточно сложная и требует очень сложной и вариативной модели и, как следствие, огромного количества данных. Поэтому если вы строите модель, которая решает сходные задачи, следует ожидать, что парой тысяч примеров не отделаться. С другой стороны, задача распознавания простых визуальных образов — существенно более простая, и здесь может не понадобится гигантских объемов выборки, можно для начала ограничится парой тысяч точек.
Тут загвоздка еще в том, что сложность задачи сама по себе зависит от состава имеющихся данных. Если какой-то атрибут позволяет с высокой долей уверенности предсказывать значение целевой переменной, это сильно понижает уровень сложности задачи. И, как следствие, может хватить гораздо меньшего по объему датасета. Если же между признаками и целевой переменная связь очень слабая, то сложность наоборот, растет, как растет и требование к количеству данных. Поэтому большие усилия исследователей направлены на повышение информативности и полезности признаков, извлекаемых из данных.
Соображения, учитывающие сложность задачи, кажутся запутанными и неконкретными. Поэтому есть еще один ориентир, который может помочь в оценке необходимого объема данных. Выборка должна быть репрезентативной, то есть представлять все возможные случаи из генеральной совокупности. Если известно, хотя бы примерно, какую именно информацию об объектах предметной области можно собирать (то есть, какие атрибуты будут в датасете), то можно порассуждать, какие комбинации значений этих атрибутов встречаются в реальной жизни. Они все должны быть представлены в наборе данных, причем, желательно, по нескольку раз, так как набор данных будет подвергаться дроблению и разделению.
Например, рассмотрим задачу определения эмоций по звуку голоса человека. Как может рассуждать исследователь, перед которым стоит задача сбора данных? Во-первых, нам нужно собрать в датасет образцы голоса для разных эмоций. При этом не существует какого-то единого классификатора или набора эмоций, здесь надо исходить из контекста задачи и доступных источников данных. Во-вторых, нужны образцы разных голосов — женские, мужские, высокие, низкие. Причем, на каждый голос нужно несколько примеров со всеми эмоциями. Нужны ли записи на разных языках? Можно выдвинуть гипотезу, что проявления эмоций в голосе не зависят от языка, поэтому можно ограничиться одним или двумя языками. Итого у нас получается, что надо собрать максимальное количество голосов разных людей и для каждого голоса включить в выборку несколько примеров на разные эмоции. Допустим, мы решили выбрать голоса 20 человек. В нашем исследовании мы распознаем 8 эмоций. И для надежности нужно по 10 звуковых фрагментов на каждую комбинацию. Получается 1600 фрагментов. Если добавить второй язык, то желаемый объем датасета приблизится к трем тысячам точек.
И это не значит, что при таком объеме модель точно будет работать эффективно, это лишь необходимый минимум, с которого можно начать. При таком подходе мы обеспечиваем минимальную репрезентативность выборки, а уже после первоначального обучения, проведя диагностику модели, можно сделать вывод, хватает нам данных или нужно собрать кратно больше. Это такой быстрый черновой расчет, который может подсказать хотя бы примерный порядок количества точек, при которых вообще может идти речь о целесообразности моделирования. Иначе вся дальнейшая работа будет просто бессмысленной: если мы оценили требуемый объем в миллион точек, а нам доступны только пять тысяч, то даже не стоит и начинать более глубокий анализ.
На практике стоит учитывать не только пожелания к объему данных, но и имеющиеся в распоряжении аналитика источники. Подбор и поиск источников данных тоже очень важен для любого практического проекта. В самой первой главе мы говорили, что поиск данных является основным сдерживающим фактором, который не позволяет использовать машинное обучение в некоторых сферах. Поэтому перед началом анализа и моделирования следует определить, откуда можно будет брать те самые данные. Причем эту работу стоит проводить параллельно с оценкой объемов, так как именно доступные источники подскажут, какую именно информацию удастся собрать, а это может повлиять на сложность задачи.
При поиске данных нужно учитывать, что возможно комбинировать данные из разных датасетов. При этом можно использовать данные по немного другой задаче, смежной с решаемой, а затем дообучить модель на нужной задаче. Такой подход называется трансфер обучения, это одна из продвинутых техник, но имейте в виду, что такое в принципе возможно.
В первую очередь стоит помнить, что источники данных могут быть внешние и внутренние. Внутренние источники — это различные корпоративные информационные система, базы данных, базы знаний, хранилища данных. В первую очередь следует подумать, какие данные по стоящей перед нами задачи уже имеются у организации и могут быть использованы. Зачастую этого бывает вполне достаточно. Если же нет, то тогда приходится обращаться к внешним источникам. Существует огромное количество готовых датасетов для решения типичных задач машинного обучения — от распознавания картинок до моделирования временных рядов цен активов. Можно попробовать найти датасет по нужной или сходной тематике на таких сайтах ка Kaggle или PapersWithCode, где публикуются целые библиотеки датасетов по рубрикам. Также часто датасеты публикуются на сайтах образовательных, научных организаций и подразделений, которые ведут исследовательскую работу. В конце концов можно искать ссылки на данные в научных публикациях, которые можно найти в специализированных системах научного цитирования типа Google Scholar.
Особенной проблемой корпоративных хранилищ данных, тем более в крупных организациях, является непоследовательность наименований, сокращений, условных обозначений. Это большая проблема при интеграции данных и она отнимает огромное количество сил именно на этапе предобработки, а также может приводить к большому количеству ошибок в данных.
При этом внешние источники информации могут быть в ограниченном доступе — например, платные или по подписке. Достоинство внешних источников данных в том, что обычно там публикуются уже готовые датасеты, которые не требуют интенсивной очистки и анализа, возможно только минимальной доводки и проверки на чистоту. В то время как информация из внутренних баз данных обычно не предназначается для машинного обучения, поэтому ее обработка может занять большое количество времени.
При сборе данных следует разделять потоковые и статические данные. Статические, или пакетные данные — это информация, которая дана в полном объеме сразу. С ней работать гораздо легче. Потоковые данные — генерируются в реальном времени с определенной скоростью. Если вам необходимо работать именно с потоковыми данными, то для этого существуют специальные техники, такие как онлайн обучение, пассивно-агрессивные модели и конвейеризация обработки данных.
Данные вообще можно не только собирать. Довольно часто по какой-то конкретной задаче вообще нет необходимых данных, либо они присутствуют в совершенно недостаточном количестве. Тогда приходится задумываться о самостоятельной генерации таких данных. Например, если вы занимаетесь распознаванием определенной категории товаров по картинке для магазина, вполне можно сделать большое количество фотографий самостоятельно. Генерация данных — процесс, конечно, более трудоемкий, чем сбор уже существующих данных, но зато в итоге может получиться датасет, который специально подходит для поставленной конкретной задачи, и он позволит строить более точные модели именно для этой задачи.
Довольно часто бывает, что собранных данных категорически недостаточно для проведения моделирования. В таком случае может помочь один прием, которых называется аугментацией данных (data augmentation). Он позволяет из одной точки данных потенциально получить несколько и таким образом кратно увеличить объем имеющегося датасета. Например, мы рассматриваем задачу распознавания рукописных символов и собрали небольшой датасет из таких картинок, но пришли к выводу, что нам нужно в разы больше данных. Каждую картинку в датасете можно повернуть на небольшой угол, изменить размер, сместить. То есть придумать какие-то небольшие изменения, модификации, которые позволяют из одной имеющейся картинки получить, потенциально, несколько десятков вариантов. Если мы применим эти модификации, то увеличим количество точек данных в датасете в такое количество раз, сколько модификаций можно применить к каждой точке. Этот прием имеет еще один положительный эффект на процесс моделирования: если модель обучается на датасете, в котором присутствуют разные варианты одной и той же картинки с разными сдвигами, то модель получается более устойчива к таким сдвигам. То есть мы не просто увеличиваем объем датасета, но еще и получаем более надежные и качественные модели. Понятно, что стратегия аугментации данных очень сильно зависит от конкретной решаемой задачи: для распознавания картинок и определения цен на сложные товары сами модификации будут принципиально разные. Но на практике аугментация данных — это очень полезный прием.
Аугментация данных — это набор методов и приемов управляемой модификации объектов обучающей выборки для увеличения объема или обобщения моделей машинного обучения на новые свойства этих объектов.
Еще одна задача, с которой часто сталкиваются при сборе данных для моделирования — разметка данных. Для обучения с учителем, как мы знаем, в датасете должны присутствовать “правильные ответы” для каждой точки выборки. Но мы можем иметь доступ к таким данным, которые очень подходят для решения задачи, но в них отсутствует именно значения целевой переменной, или такие значения имеются лишь частично. Например, решаем задачу определения мошеннических транзакций. В организации есть достаточно большая история транзакций, которую можно было бы использовать для обучения. Но в ней нет информации, какие именно транзакции считаются “подозрительными”. Такие данные называются неразмеченными (unlabelled). Было бы жалко не использовать такие прекрасные данных. В таком случае можно задуматься о ручной разметке данных — то есть специалист, эксперт предметной области, должен указать, какие транзакции считаются подозрительными, а какие — обычными. Ручная разметка данных это очень трудозатратный процесс, который зачастую требует работы нескольких экспертов. Также следует помнить, что любые экспертные оценки могут содержать ошибки. Но в некоторых случаях ручная разметка данных — единственный способ получить необходимую обучающую выборку для решения определенной задачи.
В итоге можно назвать основные способы получения данных для машинного обучения. В качестве рекомендации приведем ориентировочный порядок, в котором имеет смысл рассматривать эти способы в решении прикладной задачи:
- Сбор данных из внешних открытых источников
- Сбор данных из внутренних источников
- Аугментация данных
- Разметка данных
- Сбор данных из внешних закрытых и платных источников
- Генерация данных
В этом списке способы выстроены от менее затратных к более. Поэтому целесообразно рассматривать сначала первый вариант из списка и переходить к следующим только если он не дает нужного результата — достаточного количества данных. Конечно, этот список примерный, в реальных задачах порядок этих способов может меняться.
Сбор данных можно назвать принципиально важным этапом решению любой задачи по машинному обучению. Ведь если что-то пойдет не так здесь, все остальное может просто не состояться. Либо, что еще хуже, состоится, но будет полностью неэффективно. Поэтому именно на этом этапе большинство реальных проектов сразу заканчиваются. Невозможность собрать нужные и качественные данные, необходимые для решения поставленной задачи моделирования — основная причина провала большинства проектов.
Выводы:
- После постановки задачи машинного обучения первый этап моделирования — определение источников и объема данных, необходимых для эффективного обучения.
- Объем данных определяется порядком сложности задачи: чем больше данных, тем более сложные модели можно на них строить.
- В целом, чем больше данных можно собрать, тем лучше.
- Данные в датасете должны быть репрезентативной выборкой генеральной совокупности.
- Источники данных могут быть открытые и закрытые, платные, по подписке, внутренние и внешние.
- Данные могут быть пакетные и потоковые, с ними надо работать по разному.
- Данные можно не только собирать, но еще генерировать и модифицировать.
- Существующие данные может потребоваться размечать.
Интеграция данных
Чаще всего данные можно найти не в одном источнике, а в разных. Но для машинного обучения нужна одна таблица. Как же объединить разные данные в единый датасет? Этот, казалось бы, тривиальный вопрос не так прост, на этом этапе есть некоторые подводные камни и неочевидные решения, о которых мы и поговорим в этой главе.
Как мы говорили, для машинного обучения чем больше данных мы соберем, тем потенциально лучшие модели мы сможем получать. Поэтому следует собрать всю информацию о предметной области, которую возможно. При этом, напоминаем, что датасет для обучения модели должен быть представлен в виде одной таблицы. А после сбора информации мы можем иметь множество таблиц, особенно, если собирали информацию из разных источников. Но даже в одном источнике нужная информация может быть разнесена по нескольким таблицам, как в реляционной базе данных. Поэтому после сбора данных у нас может быть множество разных таблиц, файлов и хранилищ данных, которые потенциально могут быть полезны. Поэтому следующий этап — это интеграция данных, то есть сведение всех разрозненных кусочков информации в единый датасет.
Объединение множества таблиц можно рассматривать поэтапно. На каждом этапе две таблицы объединяются в одну. Следуем в первую очередь объединять таблицы, наиболее близкие по смыслу и происхождению. При этом каждое такое объединение может быть двух видов: объединение по вертикали и по горизонтали. Рассмотрим эти две элементарные операции по отдельности.
Интеграция данных — это процесс в составе предварительной обработки данных, направленный на объединение данных, представленных в разных формах в единый датасет с максимально возможным соблюдением требований чистых данных. Интеграция данных чаще всего происходит попарно — два датасета объединяются в один.
Вертикальное объединение данных нужно тогда, когда в двух талицах имеется примерно одна и та же информация, но про разные объекты. То есть в двух таблицах разные строчки данных, но примерно одинаковые столбцы. И в таком случае нужно “склеить” эти две таблицы по вертикали, вот так:
|
+ |
|
= |
|
В этом примере мы склеиваем две таблицы по вертикали. При этом получается талица, которая состоит из всех строк первой плюс из всех строк второй. А что происходит со столбцами? Для общих столбцов, то есть таких, которые есть в обеих таблицах все просто — они переносятся в таблицу-результат. А что делать со столбцами, которые присутствуют только в одной из двух таблиц-“слагаемых”, надо решать аналитику. По умолчанию, в получившейся таблице будут присутствовать все столбцы из обеих исходных таблиц. Но в ячейках, которые относились к той таблице, в которой такого столбца нет, будут записаны пропуски. В нашем примере такой столбец один — “weight” из второй таблицы. В результате в тех ячейках этого столбца, который относились к первой таблице записано специальное значение “NaN” (Not a number) — специальное обозначение пропущенного значения.
В библиотеках работы с табличной и статистической информацией для простого склеивания таблиц, нужного для вертикального объединения данных существуют специальные методы, такие как append() или concat() в pandas.
Конечно, можно представить ситуацию, когда такие “непарные” столбцы имеются в обеих исходных таблицах. По сути такая ситуация происходит, когда в разных таблицах отражена немного разная информация об объектах предметной области. Такое постоянно случается при интеграции данных из разных источников. По желанию аналитика можно настроить метод объединения таблиц таким образом, чтобы такие “спорные” столбцы вообще не включались в итоговую таблицу. То есть в результате она будет содержать только те атрибуты, которые присутствовали в обеих исходных таблицах, но зато в ней гарантировано не будет пропусков (если только их не было в исходных таблицах).
Горизонтальное объединение данных нужно, когда в исходных таблицах содержится разная информация о примерно тех же объектах предметной области. То есть в исходных таблицах примерно те же строки, но совершенно разные столбцы. Такая ситуация тоже часто случается, но обычно при объединении данных из одного источника. Например, из корпоративных реляционных хранилищ данных.
Горизонтальное объединение данных более сложно по своей природе, чем вертикальное. Дело в том, что так таблицы нельзя просто склеить — надо следить за соответствием строк. Ведь в разных таблицах могут присутствовать немного разные строки, а те, что есть в обоих — храниться в разном порядке. В реляционных базах данных для таких случаев есть специальная операция — соединение таблиц (join). Рассмотрим в качестве примера две таблицы с информацией о ценах и объемах торгов двух разных акций на бирже:
|
+ |
|
= |
|
заметим, что если мы просто склеим эти две таблицы горизонтально, то в одной строке получится информация за две разные даты, что, очевидно, неправильно. Для того, чтобы в итоговой таблице получилась правильная информация, надо. чтобы в обеих исходных таблицах присутствовал атрибут (столбец), который позволяет однозначно идентифицировать объект данных. В данном случае таким атрибутом выступит дата (выделена жирным). В реляционной алгебре это общее поле называется ключом, по которому происходит соединение таблиц.
Никогда не используйте простое склеивание (append() или concat() в pandas) для горизонтального объединения датасетов, только специальные реляционный оператор соединения, который в SQL называется JOIN. В том же pandas его аналоги — join() или merge().
Существует много разных видов соединений таблиц по ключу — внутреннее, внешнее, левое, правое, перекрестное. Самое консервативное (в том смысле, что не удаляет никакую информацию) — внешнее полное соединение. В результирующую таблицу будет записана информация по каждому значению ключа, который присутствует хотя бы в одной таблице. Также в нее войдут все столбцы из обеих таблиц (кроме ключа, который как общая часть войдет в результат только один раз). В ячейки таблицы будет записана информация, либо специальный индикатор отсутствия значения. На примере выше показано как раз полное внешнее соединение двух таблиц. Обратите внимание, что в итоге получилось больше строк, чем в исходных таблицах, а также в некоторых ячейках стоит специальное значение “NaN”. Затем эти пропуски можно уделить.
Если в результате горизонтального или вертикального объединения данных получается большое количество пропусков, это может происходить от того, что в таблицах присутствует очень разная информация о разных объектах. То есть мало совпадений как по строкам, так и по столбцам. В таком случае стоит задуматься о том, имеет ли смысл вообще объединять такие таблицы. Или, может быть, если у вас есть еще много других таблиц, вы выбрали неоптимальный порядок их объединения.
С помощью этих двух видов объединения данных можно практически любой разрозненное множество датасетов привести к форме из единой таблицы. Конечно, придется принять множество решений по сохранению или удалению части данных, выбрать оптимальный порядок объединения таблиц, поработать потом с отсутствующими значениями, которые появились в результате объединения.
Но самое сложное в процессе интеграции данных — следить за их соответствием и цельностью. В разных датасетах могут использоваться разные единицы измерения, разные обозначениях одних и тех же объектов, разные периоды измерений. Такие несоответствия — главная головная боль аналитика по данным. Чего стоит одна лишь работа с датами. В разных таблицах даты могут обозначаться тысячью разных способов. И если за этим не следить, то в итоге получится совершенно неприменимый на практике датасет. Существует множество типичных проблем, которые часто встречаются в данных, особенно в корпоративной среде. По опыту выполнения практических проектов можно выделить такие самые типичные примеры:
- Разные обозначения и сокращения в данных. Например, номенклатура продукции может записываться в разных справочниках по-разному. Самое противное в этой проблеме, что ее приходится решать, руками записывая таблицы соответствия разных обозначений, что очень долго.
- Разные группировки объектов. Например, в одном справочнике клиенты объединены по географическому принципу, а в другом — по суммарному чеку. В одной таблице могут быть сгруппированы объекты, которые в другой относятся к разным группам. В одной базе данных три наименее малочисленные группы объединены в “другое”, в соседней — десять товаров, которые имеют менее 1% объема продаж — объединены в “остальные”.
- Иерархические справочники. Очень многие объекты группируются в разные иерархии. Например, та же номенклатура продукции может группироваться в группы, которые объединяются в категории и классы. Проблема в том, что не каких-то таблицах идет разбивка по конкретным товарам, в других — по категориям, в третьих — суммарные или средние значения по товарным группам. Наверное, хорошо для учета, но очень неудобно для аналитики и машинного обучения.
- Разные периоды наблюдений. Как в примере выше — временные ряды могут часто не соотноситься по датам и времени измерений. В одной таблице измерения идут каждый день, в другой — только в рабочие дни. И приходится либо дополнять данные, либо выкидывать большой объем информации.
- Разные временные базы измерений. Даже в пределах одной организации повсеместно встречается, что некоторые параметры измеряются посуточно, другие — суммарно за неделю, а третьи — раз в месяц. Понятно, что без специальной обработки их нельзя просто сводить вместе.
- Отдельная проблема — всякие цифровые коды, индексы и классификаторы. Особенно — какие-нибудь 20-значные цифровые номера счетов, которые имеют определенную внутреннюю структуру. Эта структура обычно “очевидна” для специалистов, которые с ней работают, но совершенно секретна для аналитиков. Из-за этого приходится “парсить” численные значения, работать с ними как со строками. Но самое неприятное в том, что такие системы кодификации могут меняться со временем, что заставляет опять вводить сложные таблицы соответствия, причем это соответствие не всегда однозначно. Причем в разных таблицах опять же могут использоваться разные классификаторы, которые как-то “очевидно” между собой соотносятся. Кому интересно, можете познакомиться с такими понятиями, как ОГРН, ОКВЭД и ОКПО. А в специальных предметных отраслях подобных обозначений еще больше.
- Просто разные единицы измерений и обозначения дат. Это относительно простая проблема, потому что она решается автоматической конвертацией. Главное — вовремя ее заметить.
Это может касаться как технических деталей, так и сутевых, предметных аспектов. Например, при анализе эмоций в речи можно столкнуться с тем, что в разных наборах данных, которые можно собрать по данной теме, используется разный набор эмоций. То есть в разных датасетах разный набор значений целевой переменной. Это значит, что нельзя просто объединить их, нужно что-то делать с согласованностью значений. По сути, придется частично переразметить датасет. Конечно, это можно сделать автоматически, но важно просто не забыть про это, не пропустить этот этап. И ни в коем случае, нельзя предполагать, что в данных все хорошо и нет проблем. Это всегда надо проверять и тестировать.
В этом разделе мы не рассматривали различные стратегии преобразования и парсинга данных которые требуются, если исходная информация существует в виде, сильно отличном от табличной или реляционной формы. Это уже предмет не аналитики данных, а общего программирования — преобразовать данные в той форме, которая необходима для анализа.
Именно за счет таких мелких деталей, интеграция данных считается самым сложным и трудозатратным этапом машинного обучения. Несмотря на то, что здесь не используется крутая математика, этот этап не требует огромных вычислительных мощностей, на практике, он занимает до 80% всего времени работы над проектом по машинному обучению. Кроме того на этом этапе возникают большинство ошибок и артефактов в данных, которые критично сказываются на эффективности моделей. Поэтому не нужно недооценивать важность и продолжительность этого этапа. На сбор и интеграцию данных не стоит жалеть усилия и экономить ресурсы. Всегда помните про принцип “мусор на входе — мусор на выходе”, ведь объем и качество данных — самое важное для машинного обучения.
Чтобы иметь возможность исправить ошибки, которые неизбежно могут возникнуть на этом этапе, всегда сохраняйте исходные данные, даже после проведенной интеграции. По возможности можно хранить и промежуточные датасеты. Это будет критически важно, когда в результате последующего анализа вскроются какие-то ошибки и неточности, допущенные при интеграции.
Правильно проведенная интеграция данных способна сильно облегчить их дальнейшую обработку, очистку и анализ. И наоборот, ошибки, допущенные на этом этапе могут сильна “загрязнить” данные, вплоть до их полной непригодности для дальнейшего использования. Поэтому интеграция данных зачастую выполняется итеративно, несколько раз, пока не будет найден такой оптимальный способ интеграции, который дает наилучшее представление данных в итоге.
Выводы:
- Интеграция данных — это процесс объединения данных из нескольких источников в единый датасет.
- Объединение датасетов может происходить по горизонтали и по вертикали.
- Вертикальное объединение датасетов — это по сути просто склеивание двух однотипных наборов данных в один.
- Горизонтальное объединение датасетов происходит обязательно через аналог операции JOIN по ключу.
- При объединении данных из разных источников необходимо особенно тщательно следить за обозначениями, соглашениями, датами.
- Интеграция данных — самая трудная часть работы с машинным обучением.
Предварительная обработка данных
Описательный анализ данных (EDA)
Можно ли использовать данные после сбора и интеграции? Еще нет, их обязательно надо проанализировать. На этом этапе надо проверить, удовлетворяют ли они всем требованиям чистых данных, обнаружить все возможные проблемы в них и исправить все, что обнаружили. Как это сделать, что именно искать и какие конкретно действия над данными нужно произвести, мы и поговорим в этой главе.
После завершения сбора и интеграции данных, то есть когда у вас уже есть единый датасет, который планируется использовать как обучающую выборку, приходит пора заняться его анализом и обработкой. Конечно, отдельные элементы анализа данных стоит проводить и на этапе сбора информации из различных источников, чтобы обнаружить критичные проблемы в данных, из-за которых данный источник стоит вообще “забраковать”. Но именно после получения готового датасета стоит заняться анализом и обработкой более системно, так как вы будете видеть всю доступную информацию и не придется повторять одни и те же процедуры на разных данных.
Многие термины, используемые в этом разделе взаимозаменяемо, могут запутать читателя. В машинном обучении этап после завершения формирования датасета и до начала непосредственно обучения моделей состоит вперемешку из операций анализа и преобразования данных. Поэтому он может называться описательный анализ данных, предварительный анализ, предварительная обработка данных, преобразование данных, очистка данных. Конечно, между этими терминами можно провести формальное разграничение, но для целей машинного обучения нет анализа без обработки и обработки без анализа.
В первую очередь надо определиться, зачем вообще нужен предварительный анализ данных? Разве мы не говорили, что если информация подходит по форме под определение “чистых данных”, то ее можно использовать для моделирования? Да, но при сборе и интеграции данных можно обеспечить выполнение только основных требований чистых данных. Кроме этих обязательных, есть еще два условия, которые почти всегда стоит соблюсти. Это требование к отсутствию пропусков и требование к численному представлению данных.
Вообще, данные, полученные из реального мира могут содержать всяческие проблемы и ошибки, которые почти всегда негативно сказываются на эффективности применяемых моделей машинного обучения. Кроме пропусков и неправильных типов данных могут присутствовать просто ошибки, опечатки, некорректные данные, аномальные, непоказательные объекты и еще много всего. Так что главная цель предварительной обработки и анализа данных в первую очередь состоит в том, чтобы еще больше очистить данные, устранить все возможные проблемы (“артефакты”) в них.
Но механическая очистка данных — это еще не ве и не решение всех проблем. Мы уже несколько раз упоминали, что эффективная работа с данными невозможна без их глубокого понимания, погружения в предметную область. И поэтому вторая главная задача предварительного анализа данных — ближе познакомиться с этой самой информацией. Такой анализ может дать подсказки, какие именно методы предобработки лучше использовать. Ведь с теми же пропущенными значениями можно бороться несколькими принципиально разными способами. И вообще на этапе очистки данных приходится принимать множество потенциально важных для моделирования решений. Глубокий анализ данных позволяет выбрать наиболее эффективные методы как обработки данных, так и непосредственно моделирования.

Даже такая простая информация, как диапазон измерения тех или иных атрибутов, которую в pandas можно получить одной строкой может многое прояснить — шкалы измерения разных атрибутов, возможные ошибки в данных, значения, которые лежат вне разумных диапазонов, количество значений категориальных переменных. И это все может в будущем повлиять на методы обработки этих данных.
Еще раз подчеркнем, что в данной главе мы сосредоточимся на рассмотрении только главных этапов так называемого описательного анализа данных (exploratory data analysis, EDA) и предварительной обработки данных для их подготовки к использованию в моделях машинного обучения. Конечно, мы не можем даже обзорно рассмотреть все многообразие методов анализа и обработки данных. Поэтому далее рассмотрим шаги, которые являются критичными и самыми распространенными при анализе практически любых реальных данных. А при необходимости можно и даже нужно проводить более глубокий анализ данных, возможно, с привлечением статистических методов и критериев, проверки гипотез, математических доказательств и прочей тяжелой артиллерии.
Вообще, чем глубже проводить анализ данных, тем лучше. В большинстве случаем временные затраты на анализ используемой информации с лихвой компенсируются тем, что в процессе этого анализа можно обнаружить скрытые зависимости, тенденции, которые невозможно заметить при обычном беглом осмотре данных, а тем более при слепом использовании датасета в моделях. В конечном итоге подробный анализ данных приводит к получению более качественной информации. А в машинном обучении качество данных гораздо важнее “продвинутости” моделей и алгоритмов. Даже простые модели на хороших, подготовленных данных будут демонстрировать качественно боле высокую эффективность, чем самые крутые и глубокие нейросети на “грязных”, неочищенных и нерелевантных датасетах.
В данном разделе мы будем рассматривать типичные задачи предварительного анализа и обработки данных отдельно. Но в реальности, это более взаимосвзяанный, итеративный процесс. Поэтому нет смысла рассматривать отдельно сначала анализ, затем обработку данных. Эти процессы переплетаются, ведь анализ может выявить проблемы в данных, которые нужно устранить, соответствующим образом преобразовав датасет. А преобразования данных зачастую требуют повторения определенных шагов анализа. Поэтому важно помнить про основные задачи этого этапа и решать их последовательно, перемежая исследование и изменение данных.
Выводы:
- Описательный анализ данных нужен для обнаружения проблем (артефактов) в данных и для выбора метода их устранения.
- EDA также может дать информацию о структуре данных, шкалах измерения переменных, которые потом повлияют на методы обработки данных.
- Также EDA может помочь при выборе признаков, выявлении зависимостей в данных.
- EDA — это обзорный анализ данных именно при их подготовке к процессу машинного обучения.
- При необходимости, можно провести более глубокий статистический анализ данных.
- Анализ и обработку данных обычно производят параллельно, это не изолированные процессы.
Описание шкалы измерения атрибутов
Как начать анализ данных? В первую очередь на сами данные обязательно надо посмотреть — вывести первые несколько строк, познакомиться со структурой датасета — количеством строк и столбцов, названиями атрибутов. Для понимания всего набора данных в первую очередь необходимо понимать каждый атрибут в отдельности. Об этом и поговорим в этой главе.
Самый простой этап анализа данных — индивидуальное рассмотрение каждого атрибута в датасете. Для эффективной работы с информацией аналитик должен понимать смысл каждого столбца датасета, что он измеряет, какие значения может принимать, какие операции и преобразования с ним имеет смысл производить. Повторимся, что для моделирования важно понимать именно смысл используемых данных, не стоит ограничиваться формальным описанием.
Конечно, когда мы говорим про анализ каждого атрибута, имеется в виду каждый значимый атрибут. В простых задачах, когда количество столбцов в датасете ограничено единицами или максимум, десятками, можно подробно поработать с каждой колонкой, провести небольшой статистический анализ абсолютно каждого атрибута. В реальных задачах часто количество атрибутов идет на сотни и тысячи, что делает такую индивидуальную работу невозможной. Конечно, надо исходить из конкретной задачи. Во многих проектах можно сильно сократить количество атрибутов, удалив лишние просто по смыслу. В других — атрибуты представляют собой какие-то однородные данные. Как, например, в картинках, где каждый пиксель — это отдельный признак. Конечно, не идет речь о том, чтобы анализировать каждый пиксель картинки отдельно.
Пре работе в конкретными атрибутами самое главное, что нужно понимать — это различные типы шкал. Типы шкал активно изучаются в таком разделе науки, как метрология. Общепринято различают четыре главных типа шкал по Стивенсу. Для анализа данных очень полезно охарактеризовать шкалу измерения каждого атрибута. А особенно — понять тип этой шкалы. Но для этого надо уметь различать эти типы на практике, исходя из смысла каждого атрибута как характеристики объекта предметной области. Поэтому рассмотрим основные типы и их отличительные черты.
Шкала — это множество возможных значений переменной и совокупность операций и отношений, которые имеют смысл применительно к этой переменной.

Самое главное разделение, которое надо знать — это разница между численными и категориальными атрибутами (признаками). Категориальный признак может принимать только одно из конечного набора значений. Категориальные признаки — это как классы в задачах классификации. Они часто выражаются каким-то текстовым называнием, меткой, обозначением. Численные признаки, соответственно, могут принимать значения из некоторого непрерывного интервала и всегда могут быть выражены числом. Категориальные переменные еще называются иногда дискретными, качественными или неметрическими, а численные — непрерывными, количественными или метрическими.
Мы уже говорили про разницу между этими типами шкал, когда определяли задачу регрессии и классификации. Но категориальной или численной может быть не только целевая переменная, а любой атрибут или признак в данных. Это разделение так важно потому, что работа с категориальными и численными данными принципиально различается. В частности, все категориальные признаки перед началом машинного обучения нужно будет обязательно преобразовать в численные.
Важно не путать тип шкалы измерения атрибута и тип данных в языке программирования. Это схожие вещи, но если вы будете полагаться на анализ только по типу данных, вы будете совершать существенные ошибки в анализе. Численные атрибуты спокойно могут существовать в данных в виде строки, например просто потому, что где-то в процессе получения данных они так считались. Уже не будем говорить о любимых в некоторых сферах суммах прописью. А категориальные атрибуты вполне могут быть выражены числом (как, например, класс обслуживания в знаменитом датасете “Титаник”).
Пойдем немного дальше. Категориальные шкалы измерения признаков, в свою очередь, делятся на номинальные и порядковые шкалы. Номинальная шкала (ее еще называют шкалой наименований) — это такая, про каждые два значения которой можно только сказать, равны они или нет. То есть единственная операция, которая имеет смысл с переменной, выраженной в номинальной шкале — это операция проверки на равенство. Более математически выражаясь, можно сказать, что в номинальной шкале определено только отношение эквивалентности (тождества). Номинальные шкалы — это почти самый простой тип шкалы, это именно такие шкалы, про которые люди интуитивно думают, когда представляют себе категориальную переменную.
Примером номинальной шкалы можно назвать различные объекты, которые можно распознавать на изображении, названия стран, марки телефонов, вообще любые названия — организаций, производителей, товаров, различные типы объектов. Кстати, не всегда категориальные или номинальные переменные обозначаются числом. Типичный пример — номера маршрутов общественного транспорта. Несмотря на то, что это именно номер, тип шкалы такой переменной — номинальная.
Порядковые шкалы (их еще называют ординальные или ранговые) — это тоже категориальные переменные, то есть принимающие определенные значения из конечного набора, но между значениями которых есть отношение как тождества, так и порядка. Другими словами, про каждые два значения из этой шкалы можно сказать, какое из них больше (либо они равны друг другу). Еще говорят, что значения из этой шкалы можно ранжировать — выстроить по порядку. Еще раз обращаем ваше внимание, что тип шкалы — это не про какие-то конкретные значения, это про смысл данной переменной, признака, характеристики. Типичными примерами порядковой шкалы будут балльные оценки: удовлетворительно, хорошо, отлично; уровень образования — начальный, средний, высший. Несмотря на то, что значения этой характеристики обозначаются текстом, их можно сравнивать между собой. То есть можно сказать, что высшее образование — это больше, чем среднее, а среднее — это больше, чем начальное. Кстати, отношение порядка по определению транзитивно. Так что из этого следует, что высшее — больше, чем начальное.
Среди категориальных шкал особое значение имеют так называемые бинарные переменные. Это такие атрибуты, которые могут принимать всего два значения. Они могут быть как порядковые, так и номинальные. Хотя отношение порядка в таких переменных носит довольно уловный характер. Типичный пример такой бинарной шкалы — пол. Почему эта шкала особенная? Именно в машинном обучении и анализе данных ее можно преобразовывать особым образом — представлять в виде булевой переменной со значениями 0 и 1. Причем порядок этих значений не играет роли. Вспомните бинарную классификацию и то, какую особую роль она играет. Бинарная шкала — это действительно самый простой тип шкалы.
Ключевое различие между порядковыми (ординальными) признаками и номинальными в том, как их можно преобразовывать в численную форму. Делов том, что номинальные признаки нельзя просто поименовать числами, как многие делают в анализе данных. Это большая ошибка, так как это преобразование привносит в данные искусственный порядок, которого в них не было (по определению номинальной шкалы). Допустим, у нас в датасете есть колонка “производитель телефона”. И для того, чтобы преобразовать эту категориальную переменную в число мы просто обозначили разные значения числами, например “Apple” — 0, “Samsung” — 1, “Sony” — 2 и так далее. После такого преобразования модель будет воспринимать эту переменную как численную. А это значит, что модель может в своих расчетах полагаться на то, что Sony — это в два раза больше, чем Samsung, что, очевидно, абсурд. Как именно преобразовывать такие переменные мы расскажем в следующих главах.
Здесь надо отметить, что часто к какой шкале отнести переменную зависит и от интерпретации задачи. Опять же, здесь надо исходить из смысла, а не формы. В том же примере с производителями телефонов можно придумать пример, в котором нам важна, например, рыночная доля каждого производителя. Тогда между ними действительно можно выстроить некоторый порядок. Так и в других примерах, в зависимости от нашего понимания и контекста задачи одна и та же характеристика объекта может быть отнесена к разным типам шкал. Но, надо признать, это довольно редкий и экзотический случай. Обычно тип шкалы полностью очевиден из смысла данной переменной.
Переходим к численным шкалам. Различие между конкретными видами численных шкал гораздо менее важно для машинного обучения, чем между номинальной и порядковой. Но для полноты изложения, приведем и их характеристики. Тем более, что они все-так могут пригодиться на практике. Среди численных шкал выделяют интервальную и абсолютную шкалу. Интервальная шкала (она же шкала разностей) — это такая, про два значения из которой всегда можно сказать, на сколько одно больше другого (кроме сравнения и эквивалентности, как в предыдущих шкалах). То есть в ней имеют смысл разницы между значениями. Типичный пример — даты. Для данной шкалы имеют смысл такие преобразования, как сдвиги. То есть можно, например, из даты рождения получить возраст человека. А вот умножать даты и возраст некорректно.
Наконец, абсолютная шкала (ее также называют шкалой отношений) — это такая, для любых двух значений которой можно еще сказать, во сколько раз одно значение больше другого. Опять же, именно эту шкалу интуитивно представляют, когда говорят о численных переменных. Это свойство шкале придает наличие абсолютного нуля — точки отсчета. Данная шкала допускает, кроме вех предыдущих еще и умножение на константу. Именно по абсолютной шкале измеряются все физические величины — вес, рост, длина, напряжение, а также стоимость, цена. Вообще, абсолютная шкала очень распространена.
Надо отметить еще один специальный тип шкалы, с которым надо работать особо, хотя формально, по Стивенсону, он относится к абсолютной шкале. Очень часто в экономических и физических задачах встречаются величины, которые могут принимать только положительные значения, от нуля до бесконечности и при этом их значения покрывают несколько порядков величины. У таких переменных имеет очень небольшой смысл разница между значениями, чаще нам важнее именно отношение. За счет того, что абсолютные значения в таких переменных очень сильно разнятся по величине, на практике очень удобно рассматривать логарифм этих значений. Поэтому такую шкалу будем называть логарифмической. Мы уже сталкивались с такой проблемой, когда рассматривали метрики эффективности регрессии.
Определение типа шкалы это важная часть работы с каждым отдельным атрибутом датасета. Но шкала измерения переменной не ограничивается только типом. Разные переменные могут измеряться по разным шкалам, даже относящимся к одному типу. Поэтому кроме типа необходимо рассмотреть еще несколько ключевых характеристик шкал. Во-первых, это так называемая мера центрального элемента или, простыми словами, среднее значение данной переменной. Проблема в том, что по разным типам шкал центральный элемент нужно определять разными способами. Для номинальных шкал единственное, что можно определить — моду, то есть такое значение, которое встречается в выборке чаще других. Для порядковой шкалы можно посчитать медиану — значение, больше которого и меньше которого одинаковое количество объектов в датасете. По шкале отношений самой адекватной мерой центрального элемента будет простое среднее арифметическое. Оно же часто используется и для абсолютной шкалы, но если мы имеем дело с логарифмической переменной, то более грамотно будет воспользоваться средним геометрическим.
Кроме центрального элемента интерес представляет в целом вопрос, как объекты выборки распределяются по разным значениям из шкалы данной переменной. Для категориальных признаков можно узнать все значения (их же конечное количество) то, сколько объектов датасета имеет каждое конкретное значение. Это и есть дискретное распределение (причем эмпирическое, ведь мы говорим о реальных данных). А для численных шкал очень полезно узнать диапазон значений (минимальное и максимальное значение) и то, какие интервалы внутри него более “популярны”, а какие менее. Для этого можно строить таблицы, процентили и квартили. Но самым удобным и наглядным инструментом будет гистограмма. Она покажет общий вид распределения объектов выборки по значениям любого признака — как категориального, так и численного. Но надо помнить, что для переменных, в которых присутствует порядок (то есть с порядковых и дальше) значения в гистограмме было бы логично и более наглядно упорядочить именно в этом, естественном порядке. Что, в общем, справедливо и для других инструментов анализа — и графических и табличных.
Простая гистограмма настолько популярный и полезный инструмент анализа, что ее построение встроено в библиотеку pandas и может быть сделано вызовом всего одного метода у столбца (то есть серии):
1
training_set['Age'].plot.hist(bins=30)
Это гистограмма распределения пассажиров по возрасту в популярном тренировочном наборе данных “Титаник”. По ней мы видим, что явно аномальных значений нет. Средний возраст — 20-30 лет, минимальный — 0, максимальный — 80 лет. Присутствует небольшой всплеск на малых значениях возраста, что вполне объяснимо тем, что люди предпочитают путешествовать с детьми. В остальном можно предполагать, что данные распределены близко к нормальному закону.

Даже простой анализ шкалы распределения может показать очень многое — можно выявить аномалии в данных, значения вне разумного диапазона, банальные опечатки или артефакты преобразования данных (в программном коде, который осуществляет сбор, интеграцию и преобразование данных тоже могут содержаться ошибки). Можно сделать предположение о виде распределения каждой переменной — равномерное ли оно, похоже ли на нормальное, экспоненциальное или какое-то другое из известных статистических распределений. Особенно странно смотрятся мультимодальные распределения, а также необъяснимые “провалы” на гистограммах. Все такие аномалии и странности нужно попытаться проинтерпретировать, объяснить. Самые странные артефакты — ошибки, опечатки, “странные” единичные значения можно попробовать удалить из датасета. Но опять же, в каждом конкретном случае надо руководствоваться пониманием предметной области и контекста задачи.
Выводы:
- Шкалы атрибутов показывают, какие значения может принимать этот атрибут и как его можно интерпретировать и сравнивать.
- Все атрибуты подразделяются на численные (непрерывные) и категориальные (дискретные).
- Категориальные переменные потом придется преобразовать в численные.
- Номинальная шкала — это признак, для которого имеет смысл только равенство. Пример — метка класса.
- Порядковая шкала — это когда наряду с равенством мы можем выстроить значения по порядку, который имеет смысл. Пример — класс обслуживания.
- Интервалая шкала — это когда еще имеет смысл говорить о разнице между двумя значениями. Пример — даты.
- Абсолютная шкала — это когда еще можно говорить о том, во сколько раз одно значение больше другого. Пример — сумма денег.
- Особенные типы шкал — бинарная и логарифмическая.
- Кроме типа шкала характеризуется диапазоном или набором значений, мерой центрального элемента и разброса, распределением.
- Самый полезный инструмент для характеристики шкалы — гистограммы.
Заполнение отсутствующих значений
Самая распространенная проблема в данных, с которой приходится бороться при их подготовке к машинному обучению — отсутствующие значения или пропуски в данных. Пропуски могут возникать по самым разным причинам. Часто просто нет информации о значении данной характеристики у данного объекта — это точечные пропуски. Часто пропуски возникают вследствие программной ошибки или потере данных. Причиной пропусков может стать и человеческий фактор, ведь иногда данных заполняются, перепечатываются или переносятся вручную. Мы видели, что пропуски также могут возникать и в процессе интеграции данных из разных источников.
Пропуски в данных — это прямое нарушение требований чистоты данных. Что же с ними делать? Есть много путей решения этой проблемы и в этой главе мы как раз поговорим о том, как их применять и как выбрать наилучший в каждой конкретной ситуации.
Помните, что пропуски нужно исправлять во всех частях датасета — и в обучающем и в тестовом наборе. Вообще, это, как и другие действия с данными, которые описываются в этой главе, нужно делать на общем датасете. Разделение выборки на обучающую, тестовую и валидационную, применение кросс-валидации происходит непосредственно перед или уже во время машинного обучения
В любом случае, для использования данных как обучающей выборки, в них не должно быть отсутствующих значений. Не зря одно из условий чистоты данных — отсутствие пропусков. Поэтому с этим артефактом данных надо бороться. Существует несколько применяемых на практике способов исправления пропущенных значений. Среди них нет одного, самого лучшего во всех ситуациях. Для выбора метода борьбы с пропусками необходимо знать, сколько их, где и как они расположены в датасете.
Для начала следует обнаружить пропуски в данных, либо убедиться, что таковых нет. Это обязательная часть подготовки данных, которую нужно проводить абсолютно всегда. Чаще всего пропуски в данных существуют просто как отсутствие значения. В pandas для обнаружения таких отсутствующих значений можно применять специальный метод is_na(), который подсчитывает количество пропущенных значений в каждом столбце. Еще существует метод info(), который показывает, наоборот, количество имеющихся данных в каждой колонке датасета:

Некоторые пропуски не отображаются так просто при автоматизированном анализе. Иногда они “зашифрованы” в данных через какие-то специальные значения. Например часто встречаются значения “N/A” (Not available), “-“ (прочерк), все варианты слов “нет” и “неизвестно” на разных языках, а также строки, обозначающие отсутствие значения в разных языках программирования: “None”, “Null”, “undefined” и так далее. Поэтому важно проверять имеющиеся значения каждого атрибута в датасете. Часто такие специальные значения обнаруживаются только при построении гистограмм, когда становится понятно по смыслу, что в данных, оказывается, есть пропущенные значения. В особо коварных случаях пропуски могут обозначаться просто численным нулем. Это обнаружить сложнее всего.

Источник: Data Analytics.
Визуально оценить распределение пропущенных значений можно с помощью тепловой карты, которую можно построить, например так:
1
sns.heatmap(training_set.isnull(), yticklabels=False, cbar=False, cmap='viridis')
Этот график покажет не только, в каких столбцах больше всего пропусков, но и то, как они располагаются по строкам:

Эта информация очень важна для выбора способа исправления этих отсутствующих значений. Напомним, что в итоге, после очистки данных ни одного пропуска в них не должно остаться. Значит с каждым их них нужно что-то сделать. На графике выше мы видим, что большинство пропущенных значений расположено в одном столбце. В таком случае нужно задуматься, так ли он нужен для моделирования. В данном примере в этом столбце неизвестна большая часть значений, даже больше, чем заполненных. Надо полагать, что такой признак не будет очень эффективен для предсказания целевой переменной. Поэтому можно удалить весь этот столбец.
В других случая часто бывает так, что много пропусков, наоборот у какого-то одного объекта. Или в датасете присутствует несколько объектов, про которых известно меньше, чем про остальные. В таком случае, можно предложить удалить такие объекты как непоказательные. Опять же, как и в первом случае, при принятии решения об удалении данных их датасета всегда следует исходить их контекста задачи. Но объект, про которого практически ничего не известно вряд ли будет ценным обучающим примером.
Удаление строк и столбцов с отсутствующими значениями, конечно, самый простой способ борьбы с пропусками данных. Но его нельзя применять механически. Часто бывает, что если удалить из датасета все проблемные строки и столбцы, в нем вообще мало что останется. На практике встречались случаи, когда обучающая выборка сокращалась после удаления пропусков в сотни раз. Это очень неэффективно. Но если не удалять пропуски, их нужно чем-то заполнять.
Самый простой способ, который чаще всего применяется на практике — заполнение средним значением. Логично рассуждать, что раз мы не знаем значение признака в данной точке, то предположим, что его значение не сильно отклоняется от среднего значения. Это среднее рассчитывается по всем объектам, для которых известно (то есть заполнено) значение данного признака.
У этого простого метода есть только один недостаток: он сильно изменяет форму распределения данного признака. Для примера приведем гистограмму того же признака “возраст”, что и в предыдущей главе. Как можно видеть на одном из предыдущих рисунков, более 150 из почти 900 значений возраста не заполнены. Здесь мы все отсутствующие значения заполнили средним:

Очевидно, как сильно исказилось распределение теперь мы наблюдаем совершенно искусственный огромный пик на значении около 30 лет. Это и есть тот самый средний возраст. Теперь распределение очень далеко от нормального. Такая ситуация плохо скажется на эффективности модели, так как теперь она будет полагаться на тот факт, что почти все пассажиры одного возраста. А в реальности это не так.
Получается, что заполнение средним может использоваться только если пропусков в данном столбце очень мало. А что делать, если их достаточно много, чтобы заполнение средним уже было вредным, но не настолько много, чтобы удалять весь столбец? Можно заполнить случайным значением. Кажется, что это не имеет смысла, но на самом деле случайно значение также не несет никакой информации, как и пропущенное. Но в отличие от заполнения средним оно не приведет к появлению искажений распределения. Особенно если генерировать это случайное значение из распределения, близкого к имеющихся в данных значениям. Например, если на предыдущем этапе анализа данных мы пришли к выводу, что признак распределен примерно нормально, то и генерировать случайные значения для заполнения пропусков можно их нормального распределения с выборочным средним и дисперсией. Если же признак распределен равномерно — то из равномерного распределения с известными минимумом и максимумом.
Еще один прием, который применяется на практике — заполнение групповым средним. Делов том, что среди объектов обучающей выборки можно выделить определенные группы (по значениям других признаков), в которых можно посчитать средние значения данного признака для заполнения. Например, в том же датасете “Титаник” в имени пассажира есть так называемая именная форма, вежливое обращение. Его можно использовать для заполнения возраста. Если пассажир, у которого неизвестен возраст, именуется “Миссис”, мы заполняем это значение не средним возрастом всех пассажиров, а средним возрастом всех Миссис. И для других категорий: возраст “Мистеров” заполняем средним для “Мистеров”, также для “Мисс”, “Мастеров” (в викторианские времена так обращались к маленьким детям). Этот способ даже точнее “угадывает” пропущенное, так как это вежливое обращение коррелирует с возрастом. И чем больше взаимосвязь между признаком группировки и признаком, который ма заполняем, тем лучше. Этот способ также частично решает проблему искусственного пика. Один огромный пик на гистограмме по сути заменяется несколькими пиками поменьше, соответствующим групповым средним.
При заполнении пропусков в категориальных переменных можно воспользоваться простым, но действенным приемом — использованием специального значения, которое обозначает “отсутствие значения”. Этот, казалось бы примитивный способ, является самым грамотным решением с точки зрения теории информации. Он не привносит никакой новой информации в данные, никак не искажает имеющиеся распределения. Он лишь сообщает модели, что имеется особый класс объектов. К сожалению этот способ не подходит для численных признаков, потому что какое бы специальное значение мы бы не выбрали, оно всегда будет находиться в отношении порядка с другими значениями. Поэтому численные признаки всегда надо заполнять каким-то числом, которое максимально близко к возможному истинному значению данной характеристики объекта.
Выводы:
- При выборе стратегии борьбы с пропусками в данных следует проанализировать, сколько пропусков и где они расположены.
- Пропуски могут “маскироваться”, их нужно обнаруживать анализируя данные, в том числе вручную.
- Если по одному из признаков большинство значений пропущено, можно задуматься об удалении этого признака из датасета.
- Если наоборот, по одному объекту много неизвестных атрибутов, можно удалить объект.
- Следует следить, чтобы от датасета что-то осталось после массового удаления.
- Самый простой способ заполнить пропуски — заполнить их средним значением, но это сильно искажает форму распределения признака.
- Зачастую можно считать групповое среднее, более “индивидуальную” оценку атрибута данного объекта, с учетом значений других атрибутов.
- Иногда применяют заполнение случайным значением. Его лучше всего генерировать из распределения данного признака.
- Самое корректное решение по категориальным признакам — заполнение специальным значением.
Оценка влияния атрибутов на целевую переменную
При решении задач обучения с учителем весьма полезно оценить форму совместного распределения целевой переменной с каждым признаком в отдельности. Это позволяет сделать первичное эмпирическое предположение о влиянии каждого фактора на результирующую переменную. Если распределение какого-то конкретного признака разное при разных значениях целевой переменной — это точный индикатор того, что признак влияет на значение целевой переменной
Здесь, как и в статистике, мы понимаем понятие “влияние” в чисто математическом, количественном смысле. Говорят, что переменная А влияет на переменную В, если при разных значениях переменной А переменная В принимает в среднем также разные значения. Это совершенно не подразумевает влияния в повседневном смысле, когда изменение одной величины является причиной изменения другой. Как говорят в статистике, “корреляция не подразумевает причинности”.
Для того, чтобы визуально оценить степень влияния каждого атрибута на целевую переменную, необходимо построить визуализацию их совместного распределения. Для этого используют разные виды диаграмм и графиков. Какой именно вид диаграммы лучше всего использовать прежде всего зависит от типа шкал измерения данного признака и целевой переменной.
Если и признак и целевая переменная носят категориальный характер, то можно построить обычную таблицу, в которой по строкам будут перечисленны все возможные значения целевой переменной, а по столбцам — признака (можно и наоборот, это не принципиально). В ячейках нужно привести количество объектов обучающей выборки, обладающих такой комбинацией значений. Вместо абсолютного количества еще удобнее изображать долю, но считать ее только из количества объектов с данным значением признака. При этом ячейки в таблице можно автоматически раскрасить, чтобы различия в значениях были еще более заметны.

Если при разных значениях целевой переменной эти доли отличаются, это указывает на наличие связи между признаком и целевой переменной. Причем чем больше отличие, тем сильнее связь. Если значений не очень много, то очень наглядно будет изобразить это распределение на гистограмме с несколькими столбцами. Для примера приведет совместное распределение пассажиров все того же “Титаника” по полу и целевой переменной, которая характеризует, выжил пассажир или нет:

На этом графике мы ясно видим, что распределение выживаемости сильно отличается в зависимости от пола. Среди женщин выживших гораздо больше выживших, чем среди мужчин и в целом по выборке. Это, конечно, вполне объяснимо. Но для нас важен вывод, что такой признак как пол оказывает серьезное влияние на значение целевой переменной.
Если же признак и целевая переменная имеют разные типы шкал, например, признак — количественный, а целевая переменная — категориальная, то можно строить оценки плотности. Это график наподобие гистограммы, только сглаженный и представленный в виде линии. Он показывает, сколько объектов выборки лежат в данном диапазоне значений. Вот пример распределения пассажиров по возрасту в зависимости от того, выжил пассажир или нет:

Из этой визуализации видно, что два распределения в целом похожи (их относительная высота не очень важна, имеет значение именно форма распределения), но среди выживших значительно больше детей — в возрасте до 10 лет. Это тоже вполне объяснимо, учитывая что речь идет о кораблекрушении. Поэтому мы можем сделать вывод, что возраст пассажира тоже оказывает некоторое влияние на целевую переменную, хотя и не такое явное как возраст, в значительно меньшей степени.
Если же оба показателя выражаются по непрерывной шкале, то очевидным выбором визуализации может служить диаграмма рассеяния, например, такая:

В таком графике очень легко обнаружить наличие связи между изображенными переменными. Если связи нет, то облако точек будет иметь круглую форму, либо вытянутую в направлении одной из осей. Если же облако имеет выраженный тренд, то это говорит о наличии связи. Достоинством анализа графика совместного распределения является то, что на ней можно увидеть не только линейную, но и более сложные типы связей.
Совершенно не нужно ограничиваться именно упомянутыми здесь типами визуализаций. Это всего лишь советы для начинающих, какие типы графиков можно использовать в разных ситуациях. На самом деле же их гораздо больше и выбирать следует ту, которая наиболее явно выражает нужную зависимость в данных. Важную роль играет и разнообразие средств визуализации. Помните, что любое графическое представление информации нужно только для того, чтобы более ясно увидеть что-то, скрытое в данных. За подробным описанием различных типов графиков и диаграмм следует обратиться к документации к таким библиотекам как matplotlib и seaborn.
В дополнении к построению совместного распределения отдельных признаков и целевой переменной иногда следует построить совместное распределение пары признаков и целевой переменной. Может быть такое, что каждый признак в отдельности не сильно влияет на целевую переменную, а они два вместе — влияют явно. Это, конечно, более сложный случай и анализировать это уже не так интуитивно понятно и очевидно. В качестве простого инструмента такого многомерного анализа можно посоветовать уже упомянутые таблицы с группировками:

Также можно экспериментировать с разными типами графиков, которые наглядно изображают одновременно три переменные. Опять же, приходится учитывать тип этих переменных. Нет смысла перечислять рекомендуемые типы визуализаций при всех возможных комбинациях типов шкал трех и более признаков. Даже сам поиск необходимой визуализации может привести к тому, что на каких-то графиках открываются неожиданные аспекты данных, поэтому такой поиск ценен сам по себе.

Ну и конечно же не стоит относиться к визуализации данных механически, формально. Нет никакого смысла строить кучу однотипных графиков, просто чтобы охватить все комбинации признаков и целевой переменной. К анализу данных надо подходить вдумчиво и осознанно, ни на секунду не забывая про предметную область и реальный смысл исследуемых данных и признаков. В таком случае и результаты анализа будут более содержательны и полезны, и само моделирование будет более эффективным. Ведь в результате предварительного анализа данных часто возникаю идеи, как наилучшим образом эти данные преобразовать, какие признаки добавить, какие исключить, какие атрибуты переделать, модифицировать и как именно. Эта деятельность называется инжиниринг признаков. И в сложных задачах именно работа с признаками может дать наибольшее увеличение эффективности моделей машинного обучения.
Инжиниринг признаков — это преобразование данных, направленной на создание из атрибутов таких признаков, которые будут наиболее полезны и релевантны при моделировании.
Очень полезный и часто применяемый метод исследования влияния признаков — корреляционная матрица. Это матрица, в которой по горизонтали и по вертикали отложены столбцы набора данных (как правило вместе с целевой переменной). В ячейках матрицы указаны коэффициенты парной линейной корреляции между данными величинами.
Корреляция — это статистическая взаимосвязь нескольких (как правило двух) переменных, когда изменения значения одной из них сопутствуют изменению другой (в среднем). Коэффициент корреляции выражает силу этой взаимосвязи численно. Измеряется в диапазоне от -1 до 1, где 0 — полное отсутствие связи, 1 — полная прямая связь, -1 — полная обратная связь (увеличение одной переменной влечет уменьшение другой).
Корреляционная матрица показывает сразу очень большой объем информации обо всех признаках, входящих в датасет. А с помощью современных библиотечных средств ее можно построить буквально в одну строку кода. Поэтому ее так часто применяют в анализе данных для машинного обучения. Вот как корреляционная матрица выглядит для датасета “Титаник”:

При анализе корреляционной матрицы нам интересны ячейки, которые сильно отличаются от 0, то есть близки к -1, либо 1. Вообще, знак коэффициента корреляции нам здесь не важен, так как он показывает именно направление связи. Можно легко заметить, что матрица корреляции симметрична относительно своей главной диагонали. А на самой главной диагонали все коэффициенты равны 1. Это очевидно, так как корреляция любой переменной с самой собой всегда стопроцентная.
Что же интересного мы видим в этой матрице? Какие пары столбцов коррелируют сильнее других? В первую очередь нужно обратить внимание на строку (или столбец), соответствующий целевой переменной. Высокие корреляции с ней показывают признаки, демонстрирующие большое влияние, а следовательно, значимость для модели. В нашем примере это пол, класс обслуживания, цена билета.
Еще стоит обратить внимание на признаки, которые сильно коррелируют друг с другом. Это явление называется мультиколлинеарность признаков и для некоторых моделей как раз, скорее, негативно сказывается на эффективности моделей. В примере мы можем обнаружить высокую корреляцию между классом обслуживания и ценой билета. Это очень понятно по смыслу. Причем связь именно обратная: чем класс выше (то есть число меньше, ведь первый класс — самый высокий), тем выше и цена. В таком случае стоит задуматься об исключении одного из таких признаков из модели, так как они по сути взаимозаменяемы. Причем чем выше корреляция, тем скорее можно выбросить один из признаков.
Главным недостатком корреляционной матрицы является то, что она способна показать наличие только линейной связи между переменными. Если предполагается, что может быть сильная, но нелинейная связь, можно воспользоваться следующим методом.
При анализе важности признаков применяют еще один прием, который называется feature_importance. Он заключается в обучении простой интерпретируемой модели на имеющихся данных для того, что бы получить вектор относительной важности всех признаков. Обучение модели здесь проводится не для того, чтобы получить эффективную модель, которая может качественно предсказывать целевую переменную, а лишь для того, чтобы модель показала, какие признаки были ей полезны при построении предсказания, а какие — не очень. Вот пример обучения такой вспомогательной модели для извлечения feature_importance:
1
2
3
4
5
from sklearn.ensemble import RandomForestClassifier
importances = RandomForestClassifier().fit(X, y).feature_importances_
forest_importances = pd.Series(importances, index=X.columns).sort_values()
forest_importances.plot.bar(yerr=std, ax=ax)
Не всякая модель подойдет для такого. Для анализа относительной важности признаков используют именно интерпретируемые модели, после обучения которых, по внутренним параметрам можно проанализировать эту самую важность признаков. Для этих целей чаще всего применяют линейную либо логистическую регрессию, деревья решений или случайный лес (это ансамбль из нескольких деревьев). Конечно, интерпретировать модель вручную не нужно, библиотечные реализации включают в себя специальный атрибут, в который записывается эта относительная важность. Относительную важность обычно изображают на гистограмме:

В этом очень показательном примере мы видим, что три признака оказывают очень сильное влияние на целевую переменную — это возраст, пол и цена билета. Эта информация в общем-то согласуется с смыслом данных характеристик, анализом предметной области и здравым смыслом. Но можно заметить некоторые противоречия с корреляционной матрицей. Например, по матрице, класс обслуживания сильнее влиял на целевую переменную. А возраст — вообще не показывал взаимосвязи. Это можно объяснить тем, что эта взаимосвязь получилась нелинейной. Поэтому в целом вектору относительной важность доверять можно чуть больше, чем матрице корреляций.
Выводы:
- Очень полезно оценить влияние каждого атрибута на целевую переменную.
- Для этого обычно строят совместное распределение атрибута и целевой переменной. Какой тип визуализации использовать — зависит от шкал.
- Если обе переменные численные — строят диаграмму рассеяния.
- Если обе переменные категориальные — можно строить гистограммы с несколькими столбцами или таблицы (часто раскрашивают).
- При необходимости можно строить графики совместного распределения двух атрибутов и целевой переменной. Но они уже более сложные.
- Этот этап может дать информацию о том, какие атрибуты важны, а какие можно и удалить из модели.
- Очень полезно строить корреляционную матрицу и оценивать по ней взаимовлияние признаков и целевой переменной.
- Можно строить простые модели, чтобы анализировать feature importance.
Преобразование категориальных атрибутов
Еще одно требование к чистоте данных, которое обязательно должно быть удовлетворено для использования датасета для машинного обучения — все признаки должны быть выражены в численном виде. В реальности же достаточно часто встречаются категориальные атрибуты. Они могут быть выражены как угодно, но чаще всего — текстом, то есть строкой, которая характеризует название класса, конкретное значение признака. Такие атрибуты не могут быть использованы во многих моделях, так как эти самые модели совершают арифметические операции над признаками. Поэтому такие признаки обязательно надо преобразовывать в численный вид. Есть несколько способов такого преобразования и в каждом случае нужно использовать наиболее подходящий.
Кроме категориальных признаков преобразованию в численный вид подлежат все другие типы данных. В машинном обучении часто идет речь об анализе графической информации, текстов на естественных языках, видео, звукового потока. Все это в конечном итоге представляется в виде численных векторов. Эта операция называется векторизация. Здесь мы подробно про нее не будет говорить, потому что это очень обширная тема. Здесь мы сконцентрируемся на анализе табличных данных. Тем более, что такое представление информации чаще других встречается в экономических и технических приложениях.
Существует два принципиально разных подхода к кодированию категориальных признаков в численные. Первый более прост — он заключается в том, что разным значениям категориального признака ставятся в соответствие разные числа. По сути, мы просто пронумеровываем значения и заменяем его номером. В библиотеке sklearn такое преобразование называется LabelEncoder. Этот метод читает датасет построчно и присваивает первому встреченному значению данного признака номер 0, второму — 1 и так далее:
|
→ |
|
Но этим способом надо пользоваться аккуратнее. Дело в том, что такое изменение шкалы измерения признака вносит в него новую информацию — порядок значений. Как мы говорили, в номинальных шкалах отношения порядка не существует, есть только равенство или неравенство. Поэтому когда мы преобразуем, например, названия производителей телефонов в числа, у нас получается, что одни производители как бы “больше” других. Эта новая информация может существенно исказить результаты моделирования, так как численные модели работают с арифметическими операциями и полагаются на упорядоченность числовых значений.
Но в ординальных шкалах присутствует естественный порядок. Получается, что признаки, выраженные по порядковой шкале можно преобразовывать таким образом? Вообще да, но здесь есть нюанс. Дело в том, что в автоматическом режиме LabelEncoder расставляет номера в порядке упоминания значений в датасете. Обратите внимание в примере выше, что значению “excellent” соответствует 1, “good” — 0 а “poor” — 2. Это не соответствует тому самому естественному порядку, который присутствует в значениях данного атрибута. Преобразование нужно делать именно в нужном порядке, например так:
|
→ |
|
Или наоборот, в обратном порядке, это не имеет значения. Важно лишь то, что порядок численных значений должен соответствовать смыслу этих значений, а не порядку появления в датасете. К сожалению, это означает, что такое преобразование скорее всего придется делать руками, с помощью такого метода как replace(), что может быть неудобно, если в атрибуте очень много значений.
Самый простой случай — бинарная шкала. Вот ее можно преобразовывать и автоматически, потому как для двух значений их порядок обычно не очень осмыслен. Самый типичный пример — пол. Как бы он не был обозначен в исходных данных, его можно обозначать 0 или 1 (причем неважно, какой пол обозначать 0, а какой — 1):
|
→ |
|
А что делать с категориальными атрибутами с номинальной шкалой? Такие тоже очень часто встречаются. С ними сложнее, ведь их вообще нельзя просто заменить на какие-то числа, это неизбежно привнесет несвойственный данным порядок в значения. Рассмотрим для примера один из атрибутов в датасете “Титаник” — порт отправки. Пассажиры Титаника садились на борт в одном из трех городов, что и записано в данном признаке
| PassengerId | Embarked |
| 1 | S |
| 2 | C |
| 3 | S |
| 4 | S |
| 5 | S |
| 6 | Q |
| 7 | S |
| 8 | S |
| 9 | S |
| 10 | C |
Для преобразования подобных данных используется другой метод кодировки — в sklearn он называется OneHotEncoder. В датасете вместо одного столбца данного признака создается по одному на каждое его значение. И для конкретного объекта в столбце, соответствующем значению атрибута для этого объекта ставится 0, а в остальных — 1. Вот как это выглядит:
| PassengerId | Embarked_S | Embarked_C | Embarked_Q |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 |
| 5 | 1 | 0 | 0 |
| 6 | 0 | 0 | 1 |
| 7 | 1 | 0 | 0 |
| 8 | 1 | 0 | 0 |
| 9 | 1 | 0 | 0 |
| 10 | 0 | 1 | 0 |
Получается, что атрибут разбивается сразу на несколько бинарных признаков. Причем только в одном из них может стоять 1, а в остальных будут нули. Именно поэтому такой способ кодирования называется “One hot”. Такие новые суррогатные признаки еще называются “dummy”, то есть глупые признаки. В pandas есть специальный метод, который позволяет автоматически кодировать все текстовые столбцы датафрейма — get_dummies().
Надо только помнить, что не всегда численный тип переменной означает численный тип шкалы данного признака. Поэтому get_dummies() надо использовать с осторожностью и всегда проверять, правильно ли произошло преобразование. Да, в 90% случаев категориальные признаки выражаются строками, а численные — числами. Но именно за счет оставшихся 10% возникают ошибки и потери в эффективности моделей. Помните, что вдумчивый анализ и преобразование данных более результативно, чем крутые сложные модели.
Метод OneHotEncoder является универсальным. Так можно преобразовывать любые категориальные переменные. Даже порядковые или бинарные. Но для этих типов шкал такое преобразование просто излишне. Например, вот как преобразовывается бинарная переменная методом OneHotEncoder:
|
→ |
|
Очевидно, что последний столбец является просто инверсией предыдущего. То есть по значению одного столбца однозначно можно вычислить значение другого. Это означает, что эти столбцы полностью коррелируют друг с другом (коэффициент будет равен 1). А значит, как мы говорили в предыдущем пункте, один из них можно удалить. Причем в таком случае абсолютной связи убрать можно и даже нужно абсолютно любой из них, потому что один столбец уже несет полную информацию о значении признака. А оставляя один из этих двух столбцов — это практически то же самое, что поименовать значения этого бинарного признака числами.
Вообще, при использовании OneHotEncoder неизбежно возникает некоторое дублирование данных. Как в нашем примере с портами отплытия Титаника — по любым двум столбцам можно однозначно вычислить третий. Это значит, что любой из этих трех столбцов можно безболезненно удалить. Но на практике это обычно не делают, так как наличие этого столбца никак не вредит модели.
Использование OneHotEncoder имеет один очевидный существенный недостаток — после него количество столбцов в датасете может многократно вырасти. Особенно это проявляется, если в данных есть признаки с очень большим количеством значений. Почему это может быть проблемой? Во-первых, сложность анализа и визуализации данных. Поэтому большую часть предварительного анализа предпочитают делать до такого преобразования. Во-вторых, большое количество малозначащих признаков может привести к переобучению модели. Но с этой проблемой мы знаем как бороться — используя регуляризацию, отбор признаков и другие техники, которые мы обсуждали в предыдущей главе.
Но все равно, неконтролируемый рост количества признаков надо стремиться ограничить. Помогает опять же вдумчивый анализ тех атрибутов, которые порождают большое количество признаков. Возможно некоторые значения можно объединить, то есть провести группировку по данному атрибуту. Особенно это целесообразно в том случае, когда распределение значений очень неравномерно и на маленькую часть объектов приходится огромное количество вариантов значений. Тогда можно их объединить в одно значение “Другое”. Это очень распространенный прием обработки данных.
Выводы:
- Категориальные признаки часто выражаются строковыми данными и не подходят для использования в машинном обучении, их преобразуют в численные.
- Самый простой кодировщик — LabelEncoder — просто нумерует все значения категориального признака.
- Он вводит порядок в значения категорий, которого раньше не было, поэтому можно исказить результаты обучения.
- Исключение — бинарные признаки, их можно кодировать как 0 и 1.
- Более продвинутый кодировщик — OneHotEncoder — преобразует один признак во множество.
- Новые признаки соответствуют значениям исходного и кодируются бинарно. Этот способ более универсален и рекомендуется применять по умолчанию.
- В принципе, один из получившихся признаков можно удалить, но это не обязательно.
- Да, из одного признака может получиться тысяча.
В данной главе мы рассмотрели только самые критически важные аспекты предварительного анализа и преобразования данных для целей машинного обучения. Анализ данных в широком смысле — это очень обширная дисциплина, основывающаяся на математической статистике. Невозможно в этой книге описать все приемы анализа и обработки данных. Но те методы и приемы, которые мы изучили, являются необходимым минимумом для любого проекта по машинному обучению.
Главное при анализе данных — учитывать специфику предметной области, обращать внимание на малейшие странности, аномалии, несоответствия. Как мы уже говорили не раз, именно качественный анализ данных является самой важной частью работы специалиста по машинному обучению.
Реальные данные всегда содержат ошибки, аномалии, пропуски, и прочие артефакты. Данные могут быть нерелевантны, искажены и просто неверны. Качество данных очень разнится от одного набора данных к другому, от одной задачи к другой. Поэтому не рассчитывайте, что данные будут хорошими и причесанными. Чем хуже качество данных, тем больше усилий и времени придется потратить на их анализ и очистку. И в любом случае, необходимо проверить данные. Даже если они идеальны, в этом надо убедиться, провести все необходимые проверки. Но хорошие качественные данные стоят всех этих усилий, именно качество данных — залог эффективного моделирования.
With the Rise in Machine Learning and Deep Learning in every sector. Be it a well-known MNC or any Startup. The need for Machine Learning is there and companies usually don’t pay much attention to the fact that any normal laptop that is being used by Software Developers and Support people are not suitable for Machine Learning.
This is curated from Machine Learning Python Course expert trainers and experienced AI Engineers. You can visit the training material and get certified!
So, let’s get started and find out the Best laptop for Machine Learning.
- Factors Affecting Portability
- Minimum Requirements
- Best Laptop for Machine Learning
- Building a Custom PC
Factors Affecting Portability
To find the best Laptop for Machine Learning, Portability is one of the key factors that anyone looks for in a laptop, otherwise, if portability is not the issue then you can go for custom PC, which I’ll discuss in the later part of this article.
The Higher the Processing Power, the Heavier is the Laptop. Now, this can mean a lot of things.
- More RAM leads to More Weight
- More Battery leads to More Weight
- Larger Screen Size leads to More Weight
- Higher the Power Lower the Battery Life.
Find out our Machine Learning Certification Training Course in Top Cities
| India | United States | Other Countries |
| Machine Learning Training in Hyderabad | Machine Learning Course in Dallas | Machine Learning Course in Melbourne |
| Machine Learning Certification in Bangalore | Machine Learning Course in Charlotte | Machine Learning Course in London |
| Machine Learning Course in Mumbai | Machine Learning Certification in NYC | Machine Learning Course in Dubai |
Minimum Requirements
Before Buying the Best Laptop for Machine Learning you Must have a look at the Minimum Requirements to look for in a Laptop. This can also be useful if you are building a custom PC.
RAM: A minimum of 16 GB is required, but I would advise using 32 GB RAM if you can as training any algorithm will require some heavy Lifting. Less than 16 GB can cause problems while Multitasking.

CPU: Processors above Intel Corei7 7th Generation is advised as it is more powerful and delivers High Performance.

GPU: This is the most important aspect as Deep Learning, which is a Sub-Field of Machine Learning requires neural networks to work and are computationally expensive. Working on Images or Videos require heavy amounts of Matrix Calculations. GPU’s enables parallel processing of these matrices. Without GPU the process might take days or months. But with it, your Best Laptop for Machine Learning can perform the same task in hours.
 NVIDIA has started making GeForce 10 series for Laptops. These are one of the best GPU’s to work with select the one which suits your Price Range. Although they have the RTX 20 Series as well, But it’s way too costly. You can also go for AMD Radeon.
NVIDIA has started making GeForce 10 series for Laptops. These are one of the best GPU’s to work with select the one which suits your Price Range. Although they have the RTX 20 Series as well, But it’s way too costly. You can also go for AMD Radeon.
Storage: A minimum of 1TB HDD is required as the datasets tend to get larger and larger by the day. If you have a system with SSD a minimum of 256 GB is advised. Then again if you have less storage you can opt for Cloud Storage Options. There you can get machines with high GPUs even.

Operating System: Mostly People go for Linux, but Windows and MacOS can both run Virtual Linux Environment and you can work on those systems too.
Check out the Artificial Intelligence Course by E & ICT Academy NIT Warangal, India.
-
Tensorbook

The TensorBook by Lambda Labs would be my #1 Choice when it comes to machine learning and deep learning purposes as this Laptop is specifically designed for this purpose.
| Feature | Specification |
| Graphics(GPU) | NVIDIA 2070/2080 (8GB) |
| Processing(CPU) | Intel i7-8750H (6 cores, 16x PCI-e lanes) |
| RAM | Up to 32GB (2666 MHz) |
| Storage | Up to 1TB NVME SSD (4-5x faster than normal SSD) |
| Display | 16.1″ FHD (1920×1080) Display, Matte Finished |
Pros: Specially Built for Deep Learning with pre-installed Deep Learning Libraries.
Cons: Nothing as such, apart from pricing.
-
Apple MacBook Pro 15″

One of the best Laptops for Multi-tasking and for Machine Learning. This is a good option for Apple fans who don’t want to shift to another platform.
| Feature | Specification |
| Graphics(GPU) | Radeon Pro 555X with 4GB of GDDR5 – Intel UHD Graphics 630 |
| Processing(CPU) | 2.6GHz 6-core Intel Core i7, Turbo Boost up to 4.5GHz, with 12MB shared L3 cache |
| RAM | 16GB of 2400MHz DDR4 onboard memory |
| Storage | 256GB SSD |
| Display | 15.4″ Retina Display IPS Technology 2880×1800 |
Pros: Gorgeous Retina Display (2880×1800)
Cons: Too expensive, RAM is not upgradable.
-
ASUS ROG Strix GL702VS

It’s an unusual Laptop, from outside it looks like any other heavy-duty gaming laptop. It powered by some of AMD’s finest desktop hardware – and a price that’s surprisingly low.
| Feature | Specification |
| Graphics(GPU) | AMD Radeon RX 580 4GB |
| Processing(CPU) | 3GHz AMD Ryzen 7 1700 (8-core, 16MB cache) |
| RAM | 16GB DDR4 |
| Storage | 256GB SanDisk SSD , 1TB hard disk |
| Display | 17.3″, 1,920 x 1,080 non-touch IPS |
Pros: Great value for money, Superb performance with excellent thermal management, Value for Money
Cons: The battery could be better
-
ASUS ROG Zephyrus S

The Asus ROG Zephyrus S GX531GX is a stunning 15-inch gaming laptop that has the svelte design of an ultrabook but packs powerful GPU components.
| Feature | Specification |
| Graphics(GPU) | NVIDIA GeForce RTX 2080 Max-Q |
| Processing(CPU) | 2.2GHz Intel Core i7-8750H (Hexa-core, 9MB cache, up to 4.1GHz) |
| RAM | 16GB DDR4 (2,666MHz) |
| Storage | 1TB M.2 PCIe x4 SSD |
| Display | 15.6″, Full HD (1920 x 1080) IPS – 144Hz refresh rate |
Pros: Powerful, Slim design, Great performance, Innovative cooling
Cons: Very expensive, Screen isn’t HDR.
-
Dell XPS 15 9560

The Dell XPS 15 is an amazingly flexible laptop, despite looking like an ordinary high-end one on the surface. It’s very powerful but has unusually good battery life for its class.
| Feature | Specification |
| Graphics(GPU) | NVIDIA GTX 1050 GPU with 4GB RAM |
| Processing(CPU) | 2.8GHz Intel Core i7-7700HQ (3.8GHz boost) 4 cores, 8 threads |
| RAM | Up to 32GB 2400MHz DDR4 RAM |
| Storage | Up to 1TB SSD |
| Display | 15.6″(3840 x 2160) 4K 282ppi IPS LCD glossy |
Pros: Fast, amazing battery life, 4k Display
Cons: Pricey, Heavy and no webcam
-
Razer Blade 15

The Razer Blade is one of the best laptops you can get for machine and deep learning. It basically checks all the boxes for it to handle your projects and some more. The performance is top-notch.
| Feature | Specification |
| Graphics(GPU) | NVIDIA GeForce® RTX™ 2060 – 2080 MaxQ |
| Processing(CPU) | 8th Gen Intel® Core™ i7-8750H 6 Core (2.2GHz/4.1GHz) |
| RAM | 16GB Dual-Channel (8GB x 2) DDR4 2667MHz |
| Storage | 512GB SSD (NVMe) |
| Display | 15.6″ 4K Touch 60Hz, 100% Adobe RGB |
Pros: Excellent Performance, Great Build Quality, and Design, Light And Portable
Cons: Pricey
-
MSI GS65

The MSI GS65 is once again, a thin and lightweight gaming laptop which is aimed for power users working on Deep Neural Networks.
| Feature | Specification |
| Graphics(GPU) | NVIDIA GeForce GTX 1070 (8GB GDDR5, Max-Q) |
| Processing(CPU) | 3.9GHz Intel Core i7-8750H (quad-core, 9MB cache, up to 4.2GHz) |
| RAM | 16GB DDR4 (8GB x 2, 2,400MHz) |
| Storage | 512GB SSD (M.2) |
| Display | 15.6″ FHD (1,920 x 1,080) – 144Hz, 7ms response |
Pros: Attractive, subtle design, Gorgeous, a fast display, Excellent performance, Effective thermal management
Cons: Underside gets burning hot, Forthcoming Biometric login, Poor Native Audio
-
Acer Predator (Helios 300 and Triton 700)

Both the Helios and Triton 700 are amazing Laptops with amazing power and speed. Triton is the latest and more costly one. But even Helios can do your Job.
| Feature | Specification (Helios) |
| Graphics(GPU) | Intel UHD Graphics 630; Nvidia GeForce GTX 1060 (6GB GDDR5) |
| Processing(CPU) | 2.2GHz Intel Core i7-8750H (hexa-core, 9MB cache, up to 4.1GHz) |
| RAM | 16GB DDR4 (2,666MHz) |
| Storage | 256GB PCIe SSD |
| Display | 15.6-inch FHD (1,920 x 1,080) ComfyView IPS (144Hz refresh rate) |
Pros: For an affordable laptop, it performs excellently. It also has enough space for data storage.
Cons: The screen display could be better.
-
Dell Alienware 15 R4

One of the Cheapest Laptops that can get your work done, if not multitasking much. Good for students who cannot spend much on a new Laptop.
| Feature | Specification |
| Graphics(GPU) | NVIDIA GeForce GTX 1080 Max-Q (8GB GDDR5X) |
| Processing(CPU) | Intel Core i9-8950HK |
| RAM | 8GB DDR4, 2666 MHz – RAM can be an issue(But it can be upgraded) |
| Storage | 256GB SSD + 1000GB HDD |
| Display | 15.6”, 4K UHD (3840 x 2160), IPS |
Pros: Cheap, gets the work done.
Cons: More RAM and hence performance.
-
Gigabyte Aero 15X

The Gigabyte Aero 15X is a fantastic laptop for tasks beyond gaming like Machine learning while maintaining its excellent battery life, making for a more versatile laptop than previous versions.
| Feature | Specification |
| Graphics(GPU) | NVIDIA GeForce GTX 1070 (Max-Q, 8GB GDDR5 RAM) |
| Processing(CPU) | 2.2GHz Intel Core i7-8750H (Hexa-core, 9MB cache, up to 4.1GHz with Turbo Boost) |
| RAM | 16GB DDR4 (2,666MHz, 8GB x 2) |
| Storage | 512GB SSD (M.2 NVMe PCIe) |
| Display | 15.6″ UHD 4K (3,840 x 2,160) IPS LCD |
Pros: Excellent performance, Fantastic battery life, Gorgeous screen, Plenty of ports
Cons: Chin-facing Webcam, Not super premium for the price.
Building a Custom PC
If Portability is not an issue, you can build a custom PC. There are a lot of places where you can build a custom PC. Here is one of few PC’s that you can customize too on iBuyPower. You can also assemble one yourself. Just make sure you check the minimum requirement boxes and you are good to go.
You can use Cloud Support for GPU’s if you don’t want to spend so much. Here you can go for either AWS or Microsoft Azure. Azure is cheaper and better in some ways for analytics purpose. But I would advise you to Save money and buy the GPU as it will be cheaper for Long Run.
With this, we come to an end of the quest for Finding the Best Laptop for Machine Learning. I hope you have made up your mind on which Laptop to get according to your budget. Don’t spend too much on Displays or GPU’s if you aren’t a gaming person. Go with mid-range or cheap Laptops.
Are you wondering how to advance once you know the basics of what Machine Learning is? Take a look at Edureka’s Machine Learning Python Training, which will help you get on the right path to succeed in this fascinating field. Learn the fundamentals of Machine Learning, machine learning steps and methods that include unsupervised and supervised learning, mathematical and heuristic aspects, and hands-on modeling to create algorithms. You will be prepared for the position of Machine Learning engineer. You can also take a Machine Learning Course Masters Program. The program will provide you with the most in-depth and practical information on machine-learning applications in real-world situations. Additionally, you’ll learn the essentials needed to be successful in the field of machine learning, such as statistical analysis, Python, and data science.
Also, If you’re trying to grow your career in Deep learning, check out our Deep Learning Course. This course equips students with information about the tools, techniques, and tools they require to advance their careers.
Сообщество Open Data Science приветствует участников курса!
В рамках курса мы уже познакомились с несколькими ключевыми алгоритмами машинного обучения. Однако перед тем как переходить к более навороченным алгоритмам и подходам, хочется сделать шаг в сторону и поговорить о подготовке данных для обучения модели. Известный принцип garbage in – garbage out на 100% применим к любой задаче машинного обучения; любой опытный аналитик может вспомнить примеры из практики, когда простая модель, обученная на качественно подготовленных данных, показала себя лучше хитроумного ансамбля, построенного на недостаточно чистых данных.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.

В рамках сегодняшней статьи хочется обзорно описать три похожих, но разных задачи:
- feature extraction and feature engineering – превращение данных, специфических для предметной области, в понятные для модели векторы;
- feature transformation – трансформация данных для повышения точности алгоритма;
- feature selection – отсечение ненужных признаков.
Отдельно отмечу, что в этой статье почти не будет формул, зато будет относительно много кода.
В некоторых примерах будет использоваться датасет от компании Renthop, используемого в соревновании Two Sigma Connect: Rental Listing Inquires на Kaggle. В этой задаче нужно предсказать популярность объявления об аренде недвижимости, т.е. решить задачу классификации на три класса ['low', 'medium', 'high']. Для оценки решения используется метрика log loss (чем меньше — тем лучше). Тем, у кого еще нет аккаунта на Kaggle, придется зарегистрироваться; также для скачивания данных нужно принять правила соревнования.
# перед началом работы не забудьте скачать файл train.json.zip с Kaggle и разархивировать его
import json
import pandas as pd
# сразу загрузим датасет от Renthop
with open('train.json', 'r') as raw_data:
data = json.load(raw_data)
df = pd.DataFrame(data)
- Извлечение признаков (Feature Extraction)
- Тексты
- Изображения
- Геоданные
- Дата и время
- Временные ряды, веб и прочее
- Преобразования признаков (Feature transformations)
- Нормализация и изменение распределения
- Взаимодействия (Interactions)
- Заполнение пропусков
- Выбор признаков (Feature selection)
- Статистические подходы
- Отбор с использованием моделей
- Перебор
- Домашнее задание
В жизни редко данные приходят в виде готовых матриц, потому любая задача начинается с извлечения признаков. Иногда, конечно, достаточно прочитать csv файл и сконвертировать его в numpy.array, но это счастливые исключения. Давайте посмотрим на некоторые популярные типы данных, из которых нужно извлекать признаки.
Тексты
Текст – самый очевидный пример данных в свободном формате; методов работы с текстом достаточно, чтобы они не уместились в одну статью. Тем не менее, обзорно пройдем по самым популярным.
Перед тем как работать с текстом, его необходимо токенизировать. Токенизация предполагает разбиение текста на токены – в самом простом случае это просто слова. Но, делая это слишком простой регуляркой («в лоб»), мы можем потерять часть смысла: «Нижний Новгород» это не два токена, а один. Зато призыв «воруй-убивай!» можно напрасно разделить на два токена. Существуют готовые токенайзеры, которые учитывают особенности языка, но и они могут ошибаться, особенно если вы работаете со специфическими текстами (профессиональная лексика, жаргонизмы, опечатки).
После токенизации в большинстве случаев нужно задуматься о приведении к нормальной форме. Речь идет о стемминге и/или лемматизации – это схожие процессы, используемые для обработки словоформ. О разнице между ними можно прочитать здесь.
Итак, мы превратили документ в последовательность слов, можно начинать превращать их в вектора. Самый простой подход называется Bag of Words: создаем вектор длиной в словарь, для каждого слова считаем количество вхождений в текст и подставляем это число на соответствующую позицию в векторе. В коде это выглядит даже проще, чем на словах:
Bag of Words без лишних библиотек
from functools import reduce
import numpy as np
texts = [['i', 'have', 'a', 'cat'],
['he', 'have', 'a', 'dog'],
['he', 'and', 'i', 'have', 'a', 'cat', 'and', 'a', 'dog']]
dictionary = list(enumerate(set(reduce(lambda x, y: x + y, texts))))
def vectorize(text):
vector = np.zeros(len(dictionary))
for i, word in dictionary:
num = 0
for w in text:
if w == word:
num += 1
if num:
vector[i] = num
return vector
for t in texts:
print(vectorize(t))Также идея хорошо иллюстрируется картинкой:

Это предельно наивная реализация. В реальной жизни нужно позаботиться о стоп-словах, максимальном размере словаря, эффективной структуре данных (обычно текстовые данные превращают в разреженные вектора)…
Используя алгоритмы вроде Вag of Words, мы теряем порядок слов в тексте, а значит, тексты «i have no cows» и «no, i have cows» будут идентичными после векторизации, хотя и противоположными семантически. Чтобы избежать этой проблемы, можно сделать шаг назад и изменить подход к токенизации: например, использовать N-граммы (комбинации из N последовательных терминов).
Проверим на практике
In : from sklearn.feature_extraction.text import CountVectorizer
In : vect = CountVectorizer(ngram_range=(1,1))
In : vect.fit_transform(['no i have cows', 'i have no cows']).toarray()
Out:
array([[1, 1, 1],
[1, 1, 1]], dtype=int64)
In : vect.vocabulary_
Out: {'cows': 0, 'have': 1, 'no': 2}
In : vect = CountVectorizer(ngram_range=(1,2))
In : vect.fit_transform(['no i have cows', 'i have no cows']).toarray()
Out:
array([[1, 1, 1, 0, 1, 0, 1],
[1, 1, 0, 1, 1, 1, 0]], dtype=int64)
In : vect.vocabulary_
Out:
{'cows': 0,
'have': 1,
'have cows': 2,
'have no': 3,
'no': 4,
'no cows': 5,
'no have': 6}Также отмечу, что необязательно оперировать именно словами: в некоторых случаях можно генерировать N-граммы из букв (например, такой алгоритм учтет сходство родственных слов или опечаток).
In : from scipy.spatial.distance import euclidean
In : vect = CountVectorizer(ngram_range=(3,3), analyzer='char_wb')
In : n1, n2, n3, n4 = vect.fit_transform(['иванов', 'петров', 'петренко', 'смит']).toarray()
In : euclidean(n1, n2)
Out: 3.1622776601683795
In : euclidean(n2, n3)
Out: 2.8284271247461903
In : euclidean(n3, n4)
Out: 3.4641016151377544Развитие идеи Bag of Words: слова, которые редко встречаются в корпусе (во всех рассматриваемых документах этого набора данных), но присутствуют в этом конкретном документе, могут оказаться более важными. Тогда имеет смысл повысить вес более узкотематическим словам, чтобы отделить их от общетематических. Этот подход называется TF-IDF, его уже не напишешь в десять строк, потому желающие могут ознакомиться с деталями во внешних источниках вроде wiki. Вариант по умолчанию выглядит так:


Аналоги Bag of words могут встречаться и за пределами текстовых задач: например, bag of sites в соревновании, которые мы проводим – Catch Me If You Can. Можно поискать и другие примеры – bag of apps, bag of events.

Используя такие алгоритмы, можно получить вполне рабочее решение несложной проблемы, эдакий baseline. Впрочем, для нелюбителей классики есть и более новые подходы. Самый распиаренный метод новой волны – Word2Vec, но есть и альтернативы (Glove, Fasttext…).
Word2Vec является частным случаем алгоритмов Word Embedding. Используя Word2Vec и подобные модели, мы можем не только векторизовать слова в пространство большой размерности (обычно несколько сотен), но и сравнивать их семантическую близость. Классический пример операций над векторизированными представлениями: king – man + woman = queen.

Стоит понимать, что эта модель, конечно же, не обладает пониманием слов, а просто пытается разместить вектора таким образом, чтобы слова, употребляемые в общем контексте, размещались недалеко друг от друга. Если это не учитывать, то можно придумать много курьезов: например, найти противоположность Гитлеру путем умножения соответствующего вектора на -1.
Такие модели должны обучаться на очень больших наборах данных, чтобы координаты векторов действительно отражали семантику слов. Для решения своих задач можно скачать предобученную модель, например, здесь.
Похожие методы, кстати, применяются и других областях (например, в биоинформатике). Из совсем неожиданных применений – food2vec.
Изображения
В работе с изображениями все и проще, и сложнее одновременно. Проще, потому что часто можно вообще не думать и пользоваться одной из популярных предобученных сетей; сложнее, потому что если нужно все-таки детально разобраться, то эта кроличья нора окажется чертовски глубокой. Впрочем, обо всем по порядку.
Во времена, когда GPU были слабее, а «ренессанс нейросетей» еще не случился, генерация фичей из картинок была отдельной сложной областью. Для работы с картинками нужно было работать на низком уровне, определяя, например, углы, границы областей и так далее. Опытные специалисты в компьютерном зрении могли бы провести много параллелей между более старыми подходами и нейросетевым хипстерством: в частности, сверточные слои в современных сетях очень похожи на каскады Хаара. Не будучи опытным в этом вопросе, не стану даже пытаться передать знание из публичных источников, оставлю пару ссылок на библиотеки skimage и SimpleCV и перейду сразу к нашим дням.
Часто для задач, связанных с картинками, используется какая-нибудь сверточная сеть. Можно не придумывать архитектуру и не обучать сеть с нуля, а взять предобученную state of the art сеть, веса которой можно скачать из открытых источников. Чтобы адаптировать ее под свою задачу, дата сайнтисты практикуют т.н. fine tuning: последние полносвязные слои сети «отрываются», вместо них добавляются новые, подобранные под конкретную задачу, и сеть дообучается на новых данных. Но если вы хотите просто векторизовать изображение для каких-то своих целей (например, использовать какой-то несетевой классификатор) – просто оторвите последние слои и используйте выход предыдущих слоев:
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from scipy.misc import face
import numpy as np
resnet_settings = {'include_top': False, 'weights': 'imagenet'}
resnet = ResNet50(**resnet_settings)
img = image.array_to_img(face())
# какой милый енот!
img = img.resize((224, 224))
# в реальной жизни может понадобиться внимательнее относиться к ресайзу
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
# нужно дополнительное измерение, т.к. модель рассчитана на работу с массивом изображений
features = resnet.predict(x)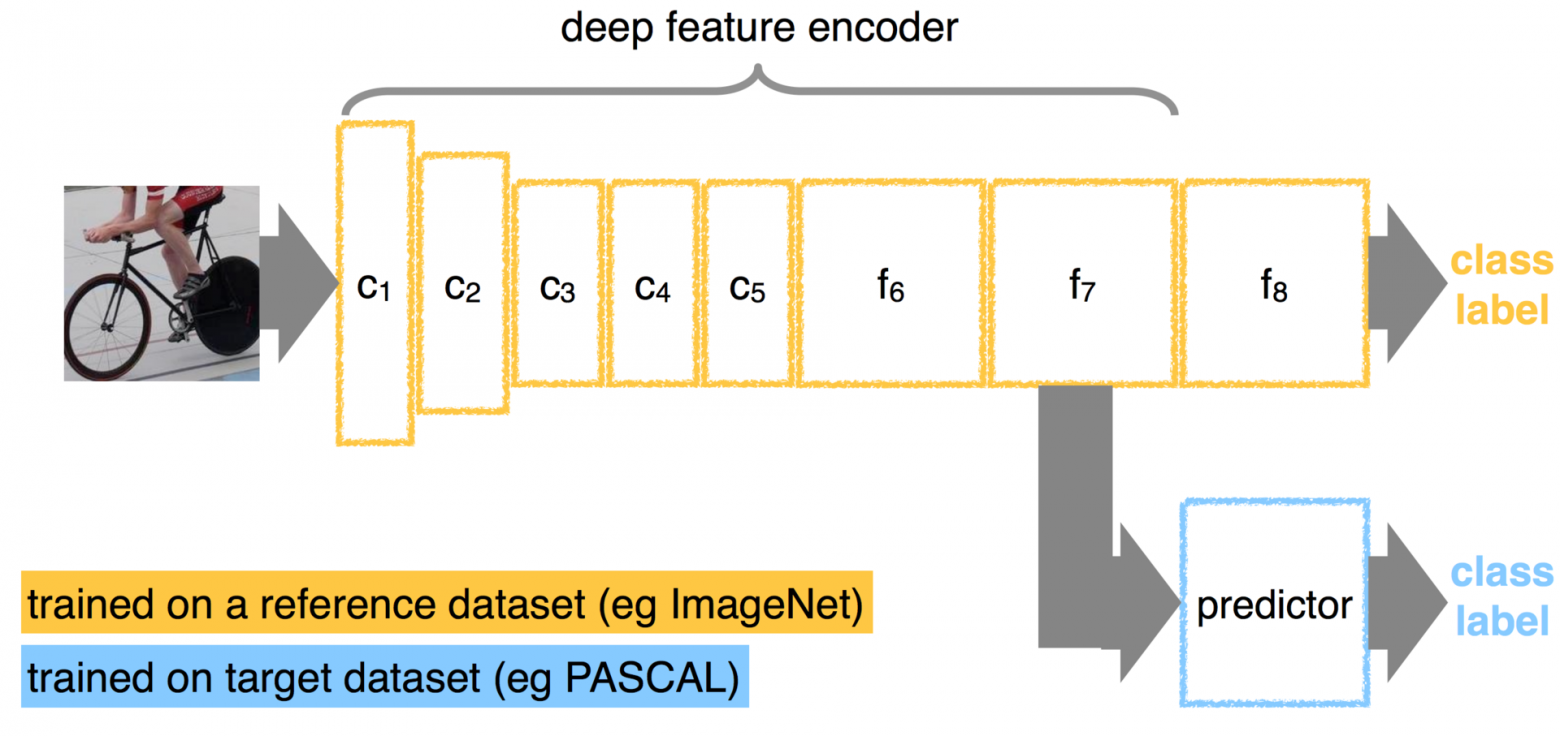
Классификатор, обученный на одном датасете и адаптированный для другого путем «отрыва» последнего слоя и добавления нового взамен
Тем не менее, не стоит зацикливаться на нейросетевых методах. Некоторые признаки, сгенерированные руками, могут оказаться полезными и в наши дни: например, предсказывая популярность объявлений об аренде квартиры, можно предположить, что светлые квартиры больше привлекают внимание, и сделать признак «среднее значение пикселя». Вдохновиться примерами можно в документации соответствующих библиотек.
Если на картинке ожидается текст, его также можно прочитать и не разворачивая своими руками сложную нейросеть: например, при помощи pytesseract.
In : import pytesseract
In : from PIL import Image
In : import requests
In : from io import BytesIO
In : img = 'http://ohscurrent.org/wp-content/uploads/2015/09/domus-01-google.jpg'
# просто случайная картинка из поиска
In : img = requests.get(img)
...: img = Image.open(BytesIO(img.content))
...: text = pytesseract.image_to_string(img)
...:
In : text
Out: 'Google'Надо понимать, что pytesseract – далеко не панацея:
# на этот раз возьмем картинку от Renthop
In : img = requests.get('https://photos.renthop.com/2/8393298_6acaf11f030217d05f3a5604b9a2f70f.jpg')
...: img = Image.open(BytesIO(img.content))
...: pytesseract.image_to_string(img)
...:
Out: 'Cunveztible to 4}»'Еще один случай, когда нейросети не помогут – извлечение признаков из метаинфорации. А ведь в EXIF может храниться много полезного: производитель и модель камеры, разрешение, использование вспышки, геокоординаты съемки, использованный для обработки софт и многое другое.
Геоданные
Географические данные не так часто попадаются в задачах, но освоить базовые приемы для работы с ними также полезно, тем более, что в этой сфере тоже хватает готовых решений.
Геоданные чаще всего представлены в виде адресов или пар «широта + долгота», т.е. точек. В зависимости от задачи могут понадобиться две обратные друг другу операции: геокодинг (восстановление точки из адреса) и обратный геокодинг (наоборот). И то, и другое осуществимо при помощи внешних API вроде Google Maps или OpenStreetMap. У разных геокодеров есть свои особенности, качество разнится от региона к региону. К счастью, есть универсальные библиотеки вроде geopy, которые выступают в роли оберток над множеством внешних сервисов.
Если данных много, легко упереться в лимиты внешних API. Да и получать информацию по HTTP – далеко не всегда оптимальное по скорости решение. Поэтому стоит иметь в виду возможность использования локальной версии OpenStreetMap.
Если данных немного, времени хватает, а желания извлекать наворченные признаки нет, то можно не заморачиваться с OpenStreetMap и воспользоваться reverse_geocoder:
In : import reverse_geocoder as revgc
In : revgc.search((df.latitude, df.longitude))
Loading formatted geocoded file...
Out:
[OrderedDict([('lat', '40.74482'),
('lon', '-73.94875'),
('name', 'Long Island City'),
('admin1', 'New York'),
('admin2', 'Queens County'),
('cc', 'US')])]Работая с геокодингом, нельзя забывать о том, что адреса могут содержать опечатки, соответственно, стоит потратить время на очистку. В координатах опечаток обычно меньше, но и с ними не все хорошо: GPS по природе данных может «шуметь», а в некоторых местах (туннели, кварталы небоскребов…) – довольно сильно. Если источник данных – мобильное устройство, стоит учесть, что в некоторых случаях геолокация определяется не по GPS, а по WiFi сетям в округе, что ведет к дырам в пространстве и телепортации: среди набора точек, описывающих путешествие по Манхеттену может внезапно оказаться одна из Чикаго.
Гипотезы о телепортации
WiFi location tracking основан на комбинации SSID и MAC-адреса, которые могут совпадать у совсем разных точек (например, федеральный провайдер стандартизировал прошивку роутеров с точностью до MAC-адреса и размещает их в разных городах). Есть и более банальные причины вроде переезда компании со своими роутерами в другой офис.
Точка обычно находится не в чистом поле, а среди инфраструктуры – здесь можно дать волю фантазии и начать придумывать признаки, применяя жизненный опыт и знание доменной области. Близость точки к метро, этажность застройки, расстояние до ближайшего магазина, количество банкоматов в радиусе – в рамках одной задачи можно придумывать десятки признаков и добывать их из разных внешних источников. Для задач вне городской инфраструктуры могут пригодиться признаки из более специфических источников: например, высота над уровнем моря.
Если две или более точек взаимосвязаны, возможно, стоит извлекать признаки из маршрута между ними. Здесь пригодятся и дистанции (стоит смотреть и на great circle distance, и на «честное» расстояние, посчитанное по дорожному графу), и количество поворотов вместе с соотношением левых и правых, и количество светофоров, развязок, мостов. Например, в одной из моих задач неплохо себя проявил признак, который я назвал «сложность дороги» – расстояние, посчитанное по графу и деленное на GCD.
Дата и время
Казалось бы, работа с датой и временем должна быть стандартизирована из-за распространенности соответствующих признаков, но подводные камни остаются.
Начнем с дней недели – их легко превратить в 7 dummy переменных при помощи one-hot кодирования. Кроме этого, полезно выделить отдельный признак для выходных.
df['dow'] = df['created'].apply(lambda x: x.date().weekday())
df['is_weekend'] = df['created'].apply(lambda x: 1 if x.date().weekday() in (5, 6) else 0)В некоторых задачах могут понадобиться дополнительные календарные признаки: например, снятие наличных денег может быть привязано к дню выдачи зарплат, а покупка проездного – к началу месяца. А по-хорошему, работая с временными данными, надо иметь под рукой календарь с государственными праздниками, аномальными погодными условиями и другими важными событиями.
Профессиональный несмешной юмор
- Что общего между китайским новым годом, нью-йорским марафоном, гей-парадом и инаугурацией Трампа?
- Их все нужно внести в календарь потенциальных аномалий.
А вот с часом (минутой, днем месяца…) все не так радужно. Если использовать час как вещественную переменную, мы немного противоречим природе данных: 0 < 23, хотя 02.01 0:00:00 > 01.01 23:00:00. Для некоторых задач это может оказаться критично. Если же кодировать их как категориальные переменные, можно наплодить кучу признаков и потерять информацию о близости: разница между 22 и 23 будет такой же, как и между 22 и 7.
Есть и более эзотерические подходы к таким данным. Например, проекция на окружность с последующим использованием двух координат.
def make_harmonic_features(value, period=24):
value *= 2 * np.pi / period
return np.cos(value), np.sin(value)Такое преобразование сохраняет дистанцию между точками, что важно для некоторых алгоритмов, основанных на расстоянии (kNN, SVM, k-means…)
In : from scipy.spatial import distance
In : euclidean(make_harmonic_features(23), make_harmonic_features(1))
Out: 0.5176380902050424
In : euclidean(make_harmonic_features(9), make_harmonic_features(11))
Out: 0.5176380902050414
In : euclidean(make_harmonic_features(9), make_harmonic_features(21))
Out: 2.0Впрочем, разницу между такими способами кодирования обычно можно уловить только в третьем знаке после запятой в метрике, не раньше.
Временные ряды, веб и прочее
Мне не довелось вдоволь поработать с временными рядами, потому я оставлю ссылку на библиотеку для автоматической генерации признаков из временных рядов и пойду дальше.
Если вы работаете с вебом, то у вас обычно есть информация про User Agent пользователя. Это кладезь информации.
Во-первых, оттуда в первую очередь нужно извлечь операционную систему. Во-вторых, сделать признак is_mobile. В-третьих, посмотреть на браузер.
Пример извлечения признаков из юзер-агента
In : ua = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/56.0.2924.76 Chrome/
...: 56.0.2924.76 Safari/537.36'
In : import user_agents
In : ua = user_agents.parse(ua)
In : ua.is_bot
Out: False
In : ua.is_mobile
Out: False
In : ua.is_pc
Out: True
In : ua.os.family
Out: 'Ubuntu'
In : ua.os.version
Out: ()
In : ua.browser.family
Out: 'Chromium'
In : ua.os.version
Out: ()
In : ua.browser.version
Out: (56, 0, 2924)Как и в других доменных областях, можно придумывать свои признаки, основываясь на догадках о природе данных. На момент написания статьи Chromium 56 был новым, а через какое-то время такая версия браузера сможет сохраниться только у тех, кто очень давно не перезагружал этот самый браузер. Почему бы в таком случае не ввести признак «отставание от свежей версии браузера»?
Кроме ОС и браузера, можно посмотреть на реферер (доступен не всегда), http_accept_language и другую метаинформацию.
Следующая по полезности информация – IP-адрес, из которого можно извлечь как минимум страну, а желательно еще город, провайдера, тип подключения (мобильное / стационарное). Нужно понимать, что бывают разнообразные прокси и устаревшие базы, так что признак может содержать шум. Гуру сетевого администрирования могут попробовать извлекать и гораздо более навороченные признаки: например, строить предположения об использовании VPN. Кстати, данные из IP-адреса неплохо комбинировать с http_accept_language: если пользователь сидит за чилийским прокси, а локаль браузера – ru_RU, что-то здесь нечисто и достойно единицы в соответствующей колонке в таблице (is_traveler_or_proxy_user).
Вообще, доменной специфики в той или иной области настолько много, что в одной голове ей не уместиться. Потому я призываю уважаемых читателей поделиться опытом и рассказать в комментариях об извлечении и генерации признаков в своей работе.
Преобразования признаков (Feature transformations)
Нормализация и изменение распределения
Монотонное преобразование признаков критично для одних алгоритмов и не оказывает влияния на другие. Кстати, это одна из причин популярности деревьев решений и всех производных алгоритмов (случайный лес, градиентный бустинг) – не все умеют/хотят возиться с преобразованиями, а эти алгоритмы устойчивы к необычным распределениям.
Бывают и сугубо инженерные причины: np.log как способ борьбы со слишком большими числами, не помещающимися в np.float64. Но это скорее исключение, чем правило; чаще все-таки вызвано желанием адаптировать датасет под требования алгоритма. Параметрические методы обычно требуют как минимум симметричного и унимодального распределения данных, что не всегда обеспечивается реальным миром. Могут быть и более строгие требования (уместно вспомнить урок про линейные модели).
Впрочем, требования к данным предъявляют не только параметрические методы: тот же метод ближайших соседей предскажет полную чушь, если признаки ненормированы: одно распределение расположено в районе нуля и не выходит за пределы (-1, 1), а другой признак – это сотни и тысячи.
Простой пример: предположим, что стоит задача предсказать стоимость квартиры по двум признакам – удаленности от центра и количеству комнат. Количество комнат редко превосходит 5, а расстояние от центра в больших городах легко может измеряться в десятках тысяч метров.
Самая простая трансформация – это Standart Scaling (она же Z-score normalization).

StandartScaling хоть и не делает распределение нормальным в строгом смысле слова…
In : from sklearn.preprocessing import StandardScaler
In : from scipy.stats import beta
In : from scipy.stats import shapiro
In : data = beta(1, 10).rvs(1000).reshape(-1, 1)
In : shapiro(data)
Out: (0.8783774375915527, 3.0409122263582326e-27)
# значение статистики, p-value
In : shapiro(StandardScaler().fit_transform(data))
Out: (0.8783774375915527, 3.0409122263582326e-27)
# с таким p-value придется отклонять нулевую гипотезу о нормальности данных… но в какой-то мере защищает от выбросов
In : data = np.array([1, 1, 0, -1, 2, 1, 2, 3, -2, 4, 100]).reshape(-1, 1).astype(np.float64)
In : StandardScaler().fit_transform(data)
Out:
array([[-0.31922662],
[-0.31922662],
[-0.35434155],
[-0.38945648],
[-0.28411169],
[-0.31922662],
[-0.28411169],
[-0.24899676],
[-0.42457141],
[-0.21388184],
[ 3.15715128]])
In : (data – data.mean()) / data.std()
Out:
array([[-0.31922662],
[-0.31922662],
[-0.35434155],
[-0.38945648],
[-0.28411169],
[-0.31922662],
[-0.28411169],
[-0.24899676],
[-0.42457141],
[-0.21388184],
[ 3.15715128]])Другой достаточно популярный вариант – MinMax Scaling, который переносит все точки на заданный отрезок (обычно (0, 1)).

In : from sklearn.preprocessing import MinMaxScaler
In : MinMaxScaler().fit_transform(data)
Out:
array([[ 0.02941176],
[ 0.02941176],
[ 0.01960784],
[ 0.00980392],
[ 0.03921569],
[ 0.02941176],
[ 0.03921569],
[ 0.04901961],
[ 0. ],
[ 0.05882353],
[ 1. ]])
In : (data – data.min()) / (data.max() – data.min())
Out:
array([[ 0.02941176],
[ 0.02941176],
[ 0.01960784],
[ 0.00980392],
[ 0.03921569],
[ 0.02941176],
[ 0.03921569],
[ 0.04901961],
[ 0. ],
[ 0.05882353],
[ 1. ]])StandartScaling и MinMax Scaling имеют похожие области применимости и часто сколько-нибудь взаимозаменимы. Впрочем, если алгоритм предполагает вычисление расстояний между точками или векторами, выбор по умолчанию – StandartScaling. Зато MinMax Scaling полезен для визуализации, чтобы перенести признаки на отрезок (0, 255).
Если мы предполагаем, что некоторые данные не распределены нормально, зато описываются логнормальным распределением, их можно легко привести к честному нормальному распределению:
In : from scipy.stats import lognorm
In : data = lognorm(s=1).rvs(1000)
In : shapiro(data)
Out: (0.05714237689971924, 0.0)
In : shapiro(np.log(data))
Out: (0.9980740547180176, 0.3150389492511749)Логнормальное распределение подходит для описания зарплат, стоимости ценных бумаг, населения городов, количества комментариев к статьям в интернете и т.п. Впрочем, для применения такого приема распределение не обязательно должно быть именно логнормальным – все распределения с тяжелым правым хвостом можно пробовать подвергнуть такому преобразованию. Кроме того, можно пробовать применять и другие похожие преобразования, ориентируясь на собственные гипотезы о том, как приблизить имеющееся распределение к нормальному. Примерами таких трансформаций являются преобразование Бокса-Кокса (логарифмирование – это частный случай трансформации Бокса-Кокса) или преобразование Йео-Джонсона, расширяющее область применимости на отрицательные числа; кроме того, можно пробовать просто добавлять константу к признаку – np.log(x + const).
В примерах выше мы работали с синтетическими данными и строго проверяли нормальность при помощи критерия Шапиро-Уилка. Давайте попробуем посмотреть на реальные данные, а для проверки на нормальность будем использовать менее формальный метод – Q-Q график. Для нормального распределения он будет выглядеть как ровная диагональная линия, и визуальные отклонения интуитивно понятны.
Q-Q график для логнормального распределения
Q-Q график для того же распределения после логарифмирования
Давайте рисовать графики!
In : import statsmodels.api as sm
# возьмем признак price из датасета Renthop и пофильтруем руками совсем экстремальные значения для наглядности
In : price = df.price[(df.price <= 20000) & (df.price > 500)]
In : price_log = np.log(price)
In : price_mm = MinMaxScaler().fit_transform(price.values.reshape(-1, 1).astype(np.float64)).flatten()
# много телодвижений, чтобы sklearn не сыпал warning-ами
In : price_z = StandardScaler().fit_transform(price.values.reshape(-1, 1).astype(np.float64)).flatten()
In : sm.qqplot(price_log, loc=price_log.mean(), scale=price_log.std()).savefig('qq_price_log.png')
In : sm.qqplot(price_mm, loc=price_mm.mean(), scale=price_mm.std()).savefig('qq_price_mm.png')
In : sm.qqplot(price_z, loc=price_z.mean(), scale=price_z.std()).savefig('qq_price_z.png')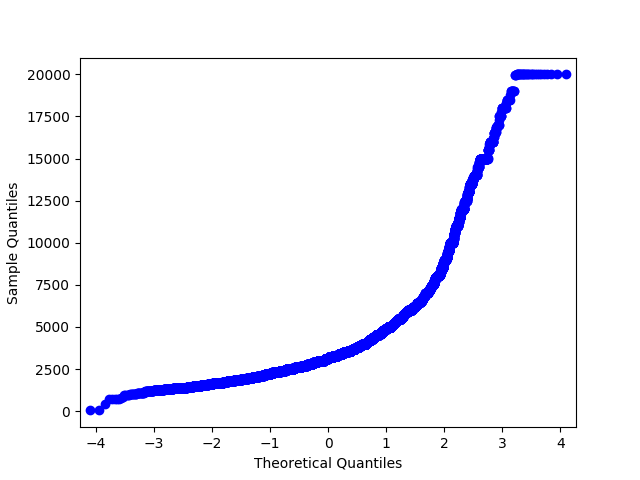
Q-Q график исходного признака

Q-Q график признака после StandartScaler. Форма не меняется
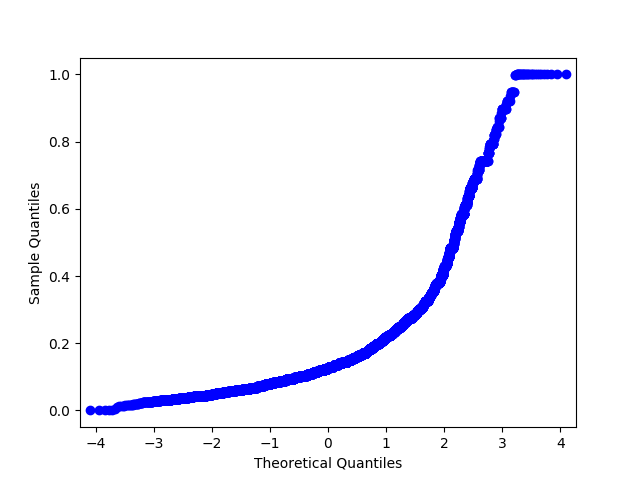
Q-Q график признака после MinMaxScaler. Форма не меняется
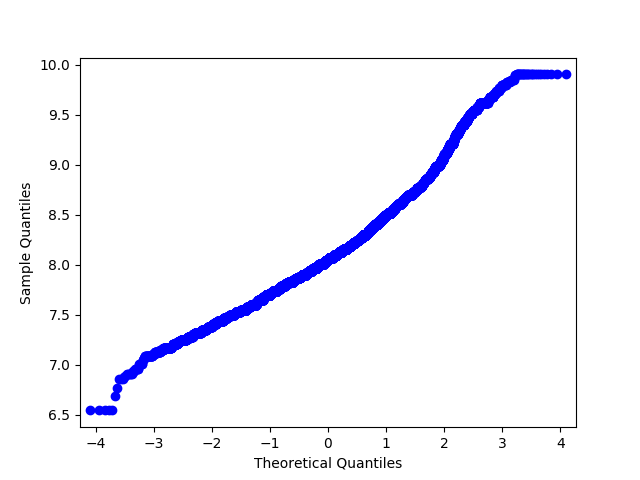
Q-Q график признака после логарифмирования. Дела пошли на поправку!
Давайте посмотрим, могут ли преобразования как-то помочь реальной модели. Я сделал небольшой скрипт, который читает данные соревнования Renthop, выбирает некоторые признаки (остальные по-диктаторски выброшены для простоты), и возвращает нам более или менее готовые данные для демонстрации.
Довольно много кода
In : from demo import get_data
In : x_data, y_data = get_data()
In : x_data.head(5)
Out:
bathrooms bedrooms price dishwasher doorman pets
10 1.5 3 8.006368 0 0 0
10000 1.0 2 8.606119 0 1 1
100004 1.0 1 7.955074 1 0 1
100007 1.0 1 8.094073 0 0 0
100013 1.0 4 8.116716 0 0 0
air_conditioning parking balcony bike ... stainless
10 0 0 0 0 ... 0
10000 0 0 0 0 ... 0
100004 0 0 0 0 ... 0
100007 0 0 0 0 ... 0
100013 0 0 0 0 ... 0
simplex public num_photos num_features listing_age room_dif
10 0 0 5 0 278 1.5
10000 0 0 11 57 290 1.0
100004 0 0 8 72 346 0.0
100007 0 0 3 22 345 0.0
100013 0 0 3 7 335 3.0
room_sum price_per_room bedrooms_share
10 4.5 666.666667 0.666667
10000 3.0 1821.666667 0.666667
100004 2.0 1425.000000 0.500000
100007 2.0 1637.500000 0.500000
100013 5.0 670.000000 0.800000
[5 rows x 46 columns]
In : x_data = x_data.values
In : from sklearn.linear_model import LogisticRegression
In : from sklearn.ensemble import RandomForestClassifier
In : from sklearn.model_selection import cross_val_score
In : from sklearn.feature_selection import SelectFromModel
In : cross_val_score(LogisticRegression(), x_data, y_data, scoring='neg_log_loss').mean()
/home/arseny/.pyenv/versions/3.6.0/lib/python3.6/site-packages/sklearn/linear_model/base.py:352: RuntimeWarning: overflow encountered in exp
np.exp(prob, prob)
# кажется, что-то пошло не так! вообще-то стоит разобраться, в чем проблема
Out: -0.68715971821885724
In : from sklearn.preprocessing import StandardScaler
In : cross_val_score(LogisticRegression(), StandardScaler().fit_transform(x_data), y_data, scoring='neg_log_loss').mean()
/home/arseny/.pyenv/versions/3.6.0/lib/python3.6/site-packages/sklearn/linear_model/base.py:352: RuntimeWarning: overflow encountered in exp
np.exp(prob, prob)
Out: -0.66985167834479187
# ого! действительно помогает!
In : from sklearn.preprocessing import MinMaxScaler
In : cross_val_score(LogisticRegression(), MinMaxScaler().fit_transform(x_data), y_data, scoring='neg_log_loss').mean()
...:
Out: -0.68522489913898188
# a на этот раз – нет :( Взаимодействия (Interactions)
Если предыдущие преобразования диктовались скорее математикой, то этот пункт снова обоснован природой данных; его можно отнести как к трансформациям, так и к созданию новых признаков.
Снова обратимся к задаче Two Sigma Connect: Rental Listing Inquires. Среди признаков в этой задаче есть количество комнат и стоимость аренды. Житейская логика подсказывает, что стоимость в пересчете на одну комнату более показательна, чем общая стоимость – значит, можно попробовать выделить такой признак.
rooms = df["bedrooms"].apply(lambda x: max(x, .5))
# избегаем деления на ноль; .5 выбран более или менее произвольно
df["price_per_bedroom"] = df["price"] / roomsНеобязательно руководствоваться жизненной логикой. Если признаков не очень много, вполне можно сгенерировать все возможные взаимодействия и потом отсеять лишние, используя одну из техник, описанных в следующем разделе. Кроме того, не все взаимодействия между признаками должны иметь хоть какой-то физический смысл: например, (часто используемые для линейных моделей)[https://habrahabr.ru/company/ods/blog/322076/] полиномиальные признаки (см. sklearn.preprocessing.PolynomialFeatures) трактовать практически невозможно.
Заполнение пропусков
Не многие алгоритмы умеют работать с пропущенными значениями «из коробки», а реальный мир часто поставляет данные с пропусками. К счастью, это одна из тех задач, для решения которых не нужно никакого творчества. Обе ключевые для анализа данных python библиотеки предоставляют простые как валенок решения: pandas.DataFrame.fillna и sklearn.preprocessing.Imputer.
Готовые библиотечные решения не прячут никакой магии за фасадом. Подходы к обработке отсутствующих значений напрашиваются на уровне здравого смысла:
- закодировать отдельным пустым значением типа
"n/a"(для категориальных переменных); - использовать наиболее вероятное значение признака (среднее или медиану для вещественных переменных, самое частое для категориальных);
- наоборот, закодировать каким-то невероятным значением (хорошо заходит для моделей, основанных на деревьях решений, т.к. позволяет сделать разделение на пропущенные и непропущенные значения);
- для упорядоченных данных (например, временных рядов) можно брать соседнее значение – следующее или предыдущее.

Удобство использования библиотечных решений иногда подсказывает воткнуть что-то вроде df = df.fillna(0) и не париться о пропусках. Но это не самое разумное решение: большая часть времени обычно уходит не на построение модели, а на подготовку данных; бездумное неявное заполнение пропусков может спрятать баг в обработке и испортить модель.
Выбор признаков (Feature selection)
Зачем вообще может понадобиться выбирать фичи? Кому-то эта идея может показаться контринтуитивной, но на самом деле есть минимум две важные причины избавляться от неважных признаков. Первая понятна всякому инженеру: чем больше данных, тем выше вычислительная сложность. Пока мы балуемся с игрушечными датасетами, размер данных – это не проблема, а для реального нагруженного продакшена лишние сотни признаков могут быть ощутимы. Другая причина – некоторые алгоритмы принимают шум (неинформативные признаки) за сигнал, переобучаясь.
Статистические подходы
Самый очевидный кандидат на отстрел – признак, у которого значение неизменно, т.е. не содержит вообще никакой информации. Если немного отойти от этого вырожденного случая, резонно предположить, что низковариативные признаки скорее хуже, чем высоковариативные. Так можно придти к идее отсекать признаки, дисперсия которых ниже определенной границы.
In : from sklearn.feature_selection import VarianceThreshold
In : from sklearn.datasets import make_classification
In : x_data_generated, y_data_generated = make_classification()
In : x_data_generated.shape
Out: (100, 20)
In : VarianceThreshold(.7).fit_transform(x_data_generated).shape
Out: (100, 19)
In : VarianceThreshold(.8).fit_transform(x_data_generated).shape
Out: (100, 18)
In : VarianceThreshold(.9).fit_transform(x_data_generated).shape
Out: (100, 15)Есть и другие способы, также основанные на классической статистике.
In : from sklearn.feature_selection import SelectKBest, f_classif
In : x_data_kbest = SelectKBest(f_classif, k=5).fit_transform(x_data_generated, y_data_generated)
In : x_data_varth = VarianceThreshold(.9).fit_transform(x_data_generated)
In : from sklearn.linear_model import LogisticRegression
In : from sklearn.model_selection import cross_val_score
In : cross_val_score(LogisticRegression(), x_data_generated, y_data_generated, scoring='neg_log_loss').mean()
Out: -0.45367136377981693
In : cross_val_score(LogisticRegression(), x_data_kbest, y_data_generated, scoring='neg_log_loss').mean()
Out: -0.35775228616521798
In : cross_val_score(LogisticRegression(), x_data_varth, y_data_generated, scoring='neg_log_loss').mean()
Out: -0.44033042718359772Видно, что отобранные фичи повысили качество классификатора. Понятно, что этот пример сугубо искусственный, тем не менее, прием достоин проверки и в реальных задачах.
Отбор с использованием моделей
Другой подход: использовать какую-то baseline модель для оценки признаков, при этом модель должна явно показывать важность использованных признаков. Обычно используются два типа моделей: какая-нибудь «деревянная» композиция (например, Random Forest) или линейная модель с Lasso регуляризацией, склонной обнулять веса слабых признаков. Логика интутивно понятна: если признаки явно бесполезны в простой модели, то не надо тянуть их и в более сложную.
Синтетический пример
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
x_data_generated, y_data_generated = make_classification()
pipe = make_pipeline(SelectFromModel(estimator=RandomForestClassifier()),
LogisticRegression())
lr = LogisticRegression()
rf = RandomForestClassifier()
print(cross_val_score(lr, x_data_generated, y_data_generated, scoring='neg_log_loss').mean())
print(cross_val_score(rf, x_data_generated, y_data_generated, scoring='neg_log_loss').mean())
print(cross_val_score(pipe, x_data_generated, y_data_generated, scoring='neg_log_loss').mean())
-0.184853179322
-0.235652626736
-0.158372952933Нельзя забывать, что это тоже не серебряная пуля — может получиться даже хуже.
Давайте вернемся к датасету Renthop.
x_data, y_data = get_data()
x_data = x_data.values
pipe1 = make_pipeline(StandardScaler(),
SelectFromModel(estimator=RandomForestClassifier()),
LogisticRegression())
pipe2 = make_pipeline(StandardScaler(),
LogisticRegression())
rf = RandomForestClassifier()
print('LR + selection: ', cross_val_score(pipe1, x_data, y_data, scoring='neg_log_loss').mean())
print('LR: ', cross_val_score(pipe2, x_data, y_data, scoring='neg_log_loss').mean())
print('RF: ', cross_val_score(rf, x_data, y_data, scoring='neg_log_loss').mean())
LR + selection: -0.714208124619
LR: -0.669572736183
# стало только хуже!
RF: -2.13486716798
Перебор
Наконец, самый надежный, но и самый вычислительно сложный способ основан на банальном переборе: обучаем модель на подмножестве «фичей», запоминаем результат, повторяем для разных подмножеств, сравниваем качество моделей. Такой подход называется Exhaustive Feature Selection.
Перебирать все комбинации – обычно слишком долго, так что можно пробовать уменьшить пространство перебора. Фиксируем небольшое число N, перебираем все комбинации по N признаков, выбираем лучшую комбинацию, потом перебираем комбинации из N+1 признаков так, что предыдущая лучшая комбинация признаков зафиксирована, а перебирается только новый признак. Таким образом можно перебирать, пока не упремся в максимально допустимое число признаков или пока качество модели не перестанет значимо расти. Этот алгоритм называется Sequential Feature Selection.
Этот же алгоритм можно развернуть: начинать с полного пространства признаков и выкидывать признаки по одному, пока это не портит качество модели или пока не достигнуто желаемое число признаков.
Время неспешного перебора!
In : selector = SequentialFeatureSelector(LogisticRegression(), scoring='neg_log_loss', verbose=2, k_features=3, forward=False, n_jobs=-1)
In : selector.fit(x_data_scaled, y_data)
In : selector.fit(x_data_scaled, y_data)
[2017-03-30 01:42:24] Features: 45/3 -- score: -0.682830838803
[2017-03-30 01:44:40] Features: 44/3 -- score: -0.682779463265
[2017-03-30 01:46:47] Features: 43/3 -- score: -0.682727480522
[2017-03-30 01:48:54] Features: 42/3 -- score: -0.682680521828
[2017-03-30 01:50:52] Features: 41/3 -- score: -0.68264297879
[2017-03-30 01:52:46] Features: 40/3 -- score: -0.682607753617
[2017-03-30 01:54:37] Features: 39/3 -- score: -0.682570678346
[2017-03-30 01:56:21] Features: 38/3 -- score: -0.682536314625
[2017-03-30 01:58:02] Features: 37/3 -- score: -0.682520258804
[2017-03-30 01:59:39] Features: 36/3 -- score: -0.68250862986
[2017-03-30 02:01:17] Features: 35/3 -- score: -0.682498213174
# "Вечерело. А старушки все падали и падали..."
...
[2017-03-30 02:21:09] Features: 10/3 -- score: -0.68657335969
[2017-03-30 02:21:18] Features: 9/3 -- score: -0.688405548594
[2017-03-30 02:21:26] Features: 8/3 -- score: -0.690213724719
[2017-03-30 02:21:32] Features: 7/3 -- score: -0.692383588303
[2017-03-30 02:21:36] Features: 6/3 -- score: -0.695321584506
[2017-03-30 02:21:40] Features: 5/3 -- score: -0.698519960477
[2017-03-30 02:21:42] Features: 4/3 -- score: -0.704095390444
[2017-03-30 02:21:44] Features: 3/3 -- score: -0.713788301404
# но улучшение не могло продолжаться вечноДомашнее задание №6
В рамках самостоятельной работы предлагается поработать c задачей регрессии на примере набора данных репозитория UCI про качество разных сортов вина. Заполните недостающий код в Jupyter notebook и выберите ответы в веб-форме, там же найдете и решение.
Актуальные и обновляемые версии демо-заданий – на английском на сайте курса, вот первое задание. Также по подписке на Patreon («Bonus Assignments» tier) доступны расширенные домашние задания по каждой теме (только на англ.).
Полезные источники
- Open Machine Learning Course. Topic 6. Feature Engineering and Feature Selection
- Kaggle Kernels
- «Feature Engineering Book»
- Статья на Хабре «Feature Engineering, о чём молчат online-курсы»
Машинное обучение позволяет компьютерам справляться с задачами, которые до недавнего времени могли решать только люди: водить автомобили, распознавать речь и переводить ее, играть в шахматы, и многое другое. Но что же именно понимается под словами «машинное обучение», и что сделало возможным современный бум машинного обучения?
Что такое машинное обучение?
Для решения каждой задачи создается модель, теоретически способная приблизиться к человеческому уровню решения данной задачи при правильных значениях параметров. Обучение этой модели – это постоянное изменение ее параметров, чтобы модель выдавала все лучшие и лучшие результаты.
Разумеется, это лишь общее описание. Как правило, вы не придумываете модель с нуля, а пользуетесь результатами многолетних исследований в этой области, поскольку создание новой модели, превосходящей существующие хотя бы на одном виде задач – это настоящее научное достижение. Методы задания целевой функции, определяющей, насколько хороши выдаваемые моделью результаты (функции потерь), также занимают целые тома исследований. То же самое относится к методам изменения параметров модели, ускорения обучения и многим другим. Даже начальная инициализация этих параметров может иметь большое значение!
В процессе обучения модель усваивает признаки, которые могут оказаться важными для решения задачи. Например, модель, отличающая изображения кошек и собак, может усвоить признак «шерсть на ушах», наличие которого скорее свойственно собакам, чем кошкам. Большинство таких признаков нельзя описать словами: вы же не сможете объяснить, как вы отличаете кошку от собаки, правда? Выделение таких признаков зачастую не менее, а иногда намного более ценно, чем решение основной задачи.
Чем машинное обучение отличается от искусственного интеллекта?
Термин «искусственный интеллект» был введен еще в 50-е годы прошлого века. К нему относится любая машина или программа, выполняющая задачи, «обычно требующие интеллекта человека». Со временем компьютеры справлялись все с новыми и новыми задачами, которые прежде требовали интеллекта человека, то есть то, что прежде считалось «искусственным интеллектом» постепенно перестало с ним ассоциироваться.
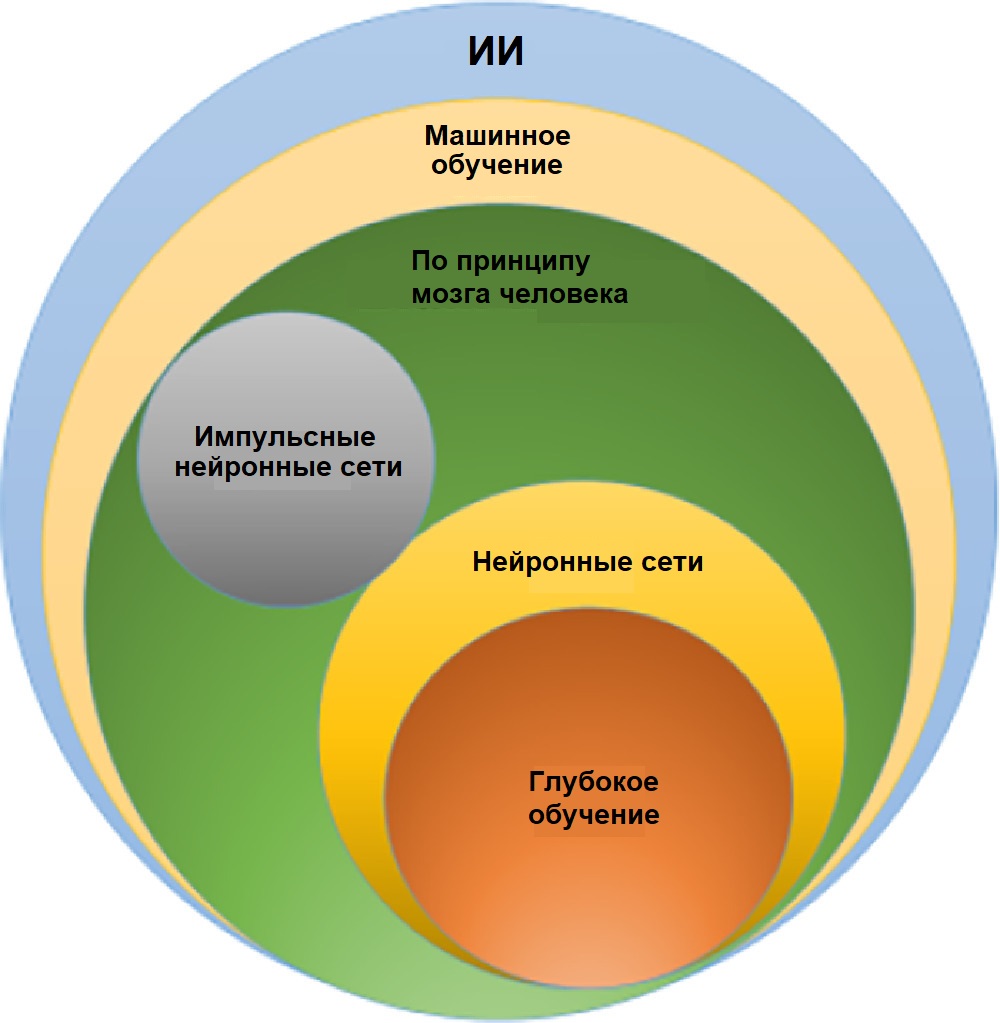
Машинное обучение – один из методов реализации приложений искусственного интеллекта, и с его помощью искусственный интеллект значительно продвинулся вперед. Но, хотя этот метод действительно очень важен, это далеко не первый значительный шаг в истории искусственного интеллекта: когда-то не менее важными казались экспертные системы, логический вывод и многое другое. Несомненно, в будущем появятся и новые технологии искусственного интеллекта, которые не будут относиться к машинному обучению.
Модели, виды и параметры машинного обучения
Самая простая модель имеет всего два параметра. Если нужно предсказать результат, линейно зависящий от входного признака, достаточно найти параметры a и b в уравнении прямой линии y=ax+b. Такая модель строится с помощью линейной регрессии. На следующем рисунке показана модель, предсказывающая «уровень счастья» человека по его собственной оценке в зависимости от уровня его дохода (красная линия):
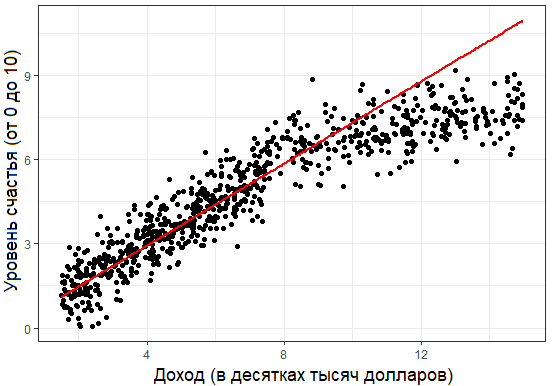
К сожалению, в реальной жизни простые линейные зависимости встречаются крайне редко. Даже на этом графике видно, что высокий уровень дохода выбивается из линейной зависимости – одних денег для счастья все-таки недостаточно. Даже полиномиальные модели, имеющие количество параметров, равное степени полинома, пригодны лишь для очень простых задач.
Современная революция в машинном обучении связана с нейронными сетями, обычно имеющими тысячи или даже миллионы параметров. Такие сети могут усваивать очень сложные признаки, необходимые для решения сложных задач. На следующем рисунке приведен пример архитектуры нейронной сети с двумя скрытыми слоями.
Хотя алгоритм обратного распространения ошибки (backropagation) был придуман довольно давно, до недавнего времени не было технических возможностей для реализации глубоких нейронных сетей, содержащих большое количество слоев. Быстрое развитие микроэлектроники привело к появлению высокопроизводительных GPU и TPU, способных обучать глубокие нейронные сети без суперкомпьютеров. Именно широкое распространение глубокого обучения стоит за тем бумом искусственного интеллекта, о котором вы слышите отовсюду.
Типы машинного обучения
Машинное обучение требует много данных. В идеале, тренировочные данные должны описывать все возможные ситуации, чтобы модель могла подготовиться ко всему. Конечно, на практике добиться этого невозможно, но нужно стараться, чтобы тренировочный набор был достаточно разнообразным.
Стратегия обучения выбирается в зависимости от поставленной задачи и имеющихся данных для обучения. Выделяют обучение с учителем (supervised learning), обучение без учителя (unsupervised learning) и обучение с подкреплением (reinforcement learning).
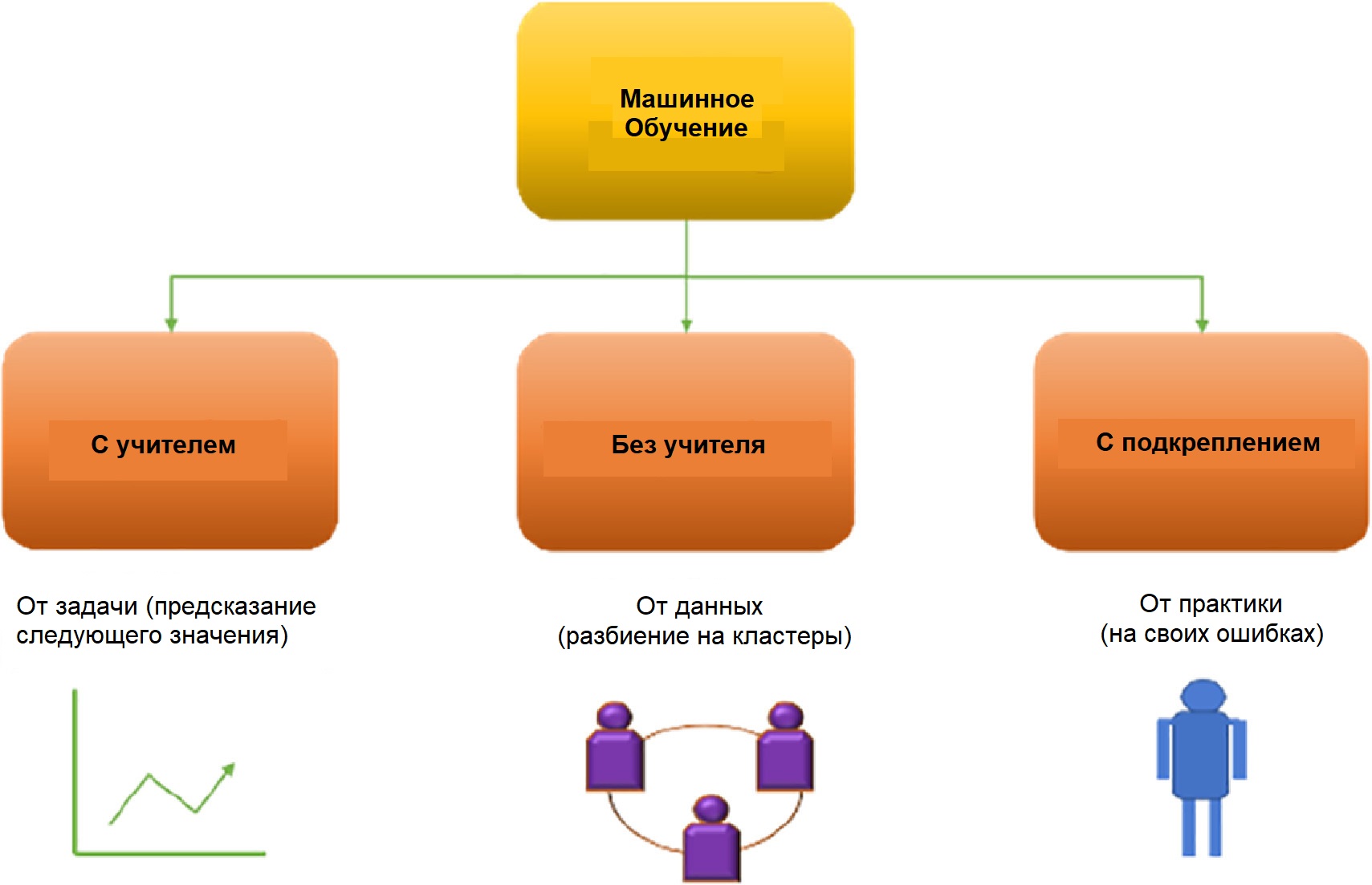
Обучение с учителем
Это обучение на примерах, при котором «учителем» называются правильные ответы, которые, в идеале, должна выдавать модель для каждого случая. Эти ответы называются метками (название происходит из задач классификации, модели которых практически всегда обучаются с учителем – там эти ответы являются метками классов), а данные с метками – размеченными.
Обучение с учителем – это обучение на примерах. Представьте, что школьнику показали несколько методов решения задач, а потом заставили решить огромное количество таких задач, предоставив правильные ответы для каждой. Если школьник решит все эти задачи, и в каждой получит правильный ответ, то можно считать, что он усвоил методы решения таких задач.
К сожалению, с моделями машинного обучения все не так просто, поскольку мы сами не знаем, какой ответ будет «правильным» для каждого случая! Ведь именно для получения этих ответов нам и нужна модель. И практически всегда нам нужно, чтобы модель хорошо усвоила зависимость результата от входных признаков, а не точно повторяла результаты тренировочного набора, который в реальной жизни может содержать и ошибочные результаты (шум). Если модель выдает верные результаты на всем тренировочном наборе, но часто ошибается на новых данных, говорят, что она переобучена на этом наборе.
Обучение без учителя
Некоторые задачи можно решить и без размеченных тренировочных данных – например, задачи кластеризации. Модель сама решает, как надо сгруппировать данные в кластеры, чтобы похожие экземпляры данных попадали в один кластер, а непохожие – не попадали.
Такую стратегию обучения, использует, например, Airbnb, объединяя в группы похожие дома, и Google News, группируя новости по их темам.
Частичное привлечение учителя
Как и предполагает название, обучение с частичным привлечение учителя (semi-supervised learning) – это смесь обучения с учителем и без него. Этот метод использует небольшое количество размеченных данных и множество данных без меток. Сначала модель обучается на размеченных данных, а затем эта частично обученная модель используется для разметки остальных данных (псевдо-разметка). Затем вся модель обучается на смеси размеченных и псевдо-размеченных данных.
Популярность такого подхода резко выросла в последнее время в связи с широким распространением генеративных состязательных сетей (GAN), использующих размеченные данные для генерации совершенно новых данных, на которых продолжается обучение модели. Если частичное привлечение учителя когда-нибудь станет не менее эффективным, чем обучение с учителем, то огромные вычислительные мощности станут более важными, чем большое количество размеченных данных.
Обучение с подкреплением
Это обучение методом проб и ошибок. Каждый раз, когда модель достигает поставленной цели, она получает «поощрение», а если не получает – «наказание». Эта стратегия обычно используется для обучения моделей, непосредственно взаимодействующих с реальным миром: моделей автоматического вождения автомобилей, игры в различные игры и т.д.
Отличный пример модели, обученной с подкреплением – нейронная сеть Deep Q от Google, победившая людей во множестве старых видеоигр. После длительного обучения модель усваивает правильную стратегию поведения, приводящую к победе.
Лучшие курсы для изучения машинного обучения
- Самый популярный курс основ машинного обучения для новичков – бесплатная серия лекций Стэнфордского университета на Coursera от легендарного эксперта в ИИ и основателя Google Brain Эндрю Ына (Andrew Ng). Недавно Эндрю Ын выпустил курс специализации в глубоком обучении, который рассматривает различные архитектуры нейронных сетей и прочие темы машинного обучения.

- Если вы предпочитаете подход «сверху вниз», при котором вы сначала запускаете обученные модели машинного обучения, и только потом углубляетесь в их внутренности, обратите внимание на курс «Практическое глубокое обучение для кодировщиков» от fast.ai. Этот курс особенно рекомендуется программистам, имеющим не менее года опыта работы на Python. Курс Эндрю Ына предоставляет обзор теоретических основ машинного обучения, а курс fast.ai построен вокруг Python’а – языка программирования, широко используемого в машинном обучении.
- Еще один курс, высоко оцениваемый не только за уровень преподавания, но и за широкий обзор рассматриваемых тем – «Введение в машинное обучение» от EdX и Колумбийского университета, хотя он и требует знания математики на университетском уровне.
- На русском языке, пожалуй, лучший курс машинного обучения предлагает факультет искусственного интеллекта GeekBrains. Этот курс занимает целых полтора года и при успешном освоении выведет вас на довольно высокий уровень, достаточный для трудоустройства.
Сферы применения машинного обучения
Машинное обучение имеет огромное количество применений, но особенно выделяются два крупных и важных направления: машинное зрение (computer vision, CV) и обработка естественного языка (natural language processing, NLP), каждое из которых объединяет множество различных задач.

Машинное зрение
Машинное зрение – это все приложения, включающие обработку изображений и видео. В частности, современные модели способны решать следующие задачи машинного зрения:
- Выделение сущностей определенных классов в изображении. Например, модель YOLO помечает рамками найденные объекты и выводит метки их классов.
- Распознавание людей по их лицам (служит для обнаружения преступников, идентификации для безопасного доступа к охраняемым объектам, введения ограничений по возрасту и т.п.)
- Медицинская диагностика. Современные модели способны распознавать многие виды заболеваний по фотографиям пациентов, особенно если к ним добавляются снимки рентгенографии и МРТ.
- Автоматическое вождение автомобиля. Эта задача состоит из многих подзадач: идентификация других автомобилей, пешеходов и прочих объектов на дороге, определение скорости и направления движения других объектов, принятие правильных решений в различных ситуациях, и так далее.
- Воздушная разведка. Современные дроны могут намного больше, чем подчиняться командам человека, передаваемым по радио. Они могут не только распознавать военную технику и направление ее передвижения, но и ее маркировку.
- Автоматическая генерация изображений – в том числе, человеческих лиц и тел.

Обработка естественного языка
Обработка естественного языка – это революция в области интерфейса между человеком и компьютером. Она включает в себя следующие задачи:
- Распознавание речи. Современные модели способны распознавать человеческую речь практически с такой же точностью, как другие люди.
- Машинный перевод с одного языка на другой. Одна из самых старых и самых известных задач искусственного интеллекта вышла на новый уровень благодаря машинному обучению.
- Анализ тональности текста. Определение эмоционального отношения автора текста к описываемым объектам или сущностям.
- Поиск ответов на вопросы. Современные поисковые системы практически всегда находят документы с ответами на заданные людьми вопросы, если они существуют.
- Выделение заданных сущностей из текста (например, поиск текста, имеющего отношение к чистоте атмосферы).
- Автоматическая генерация текста. Современные модели умеют генерировать тексты разных стилей и направлений, которые далеко не всегда можно отличить от текстов, написанных человеком.
- Синтез речи. Компьютеры уже давно не разговаривают «как роботы» – синтезированную ими речь практически невозможно отличить от человеческой.
***
Хочу подтянуть знания по математике, но не знаю, с чего начать. Что делать?
Если базовые концепции языка программирования можно достаточно быстро освоить самостоятельно, то с математикой могут возникнуть сложности. Чтобы помочь освоить математический инструментарий, «Библиотека программиста» совместно с преподавателями ВМК МГУ разработала курс по математике для Data Science, на котором вы:
- подготовитесь к сдаче вступительных экзаменов в Школу анализа данных Яндекса;
- углубитесь в математический анализ, линейную алгебру, комбинаторику, теорию вероятностей и математическую статистику;
- узнаете роль чисел, формул и функций в разработке алгоритмов машинного обучения.
- освоите специальную терминологию и сможете читать статьи по Data Science без постоянных обращений к поисковику.
Курс подойдет как начинающим специалистам, так и действующим программистам и аналитикам, которые хотят повысить свой уровень или перейти в новую область.



